Passport OCR
Automate passport processing and foolproof KYC & AML compliance with AI-powered OCR passport scanner.
Trusted by 1000+ brands worldwide
Unlock Passport OCR Functionalities
Leverage Klippa’s OCR Passport extraction to reduce operational costs. Process larger volumes of documents faster and easily scale-up with Klippa’s OCR passport reader.

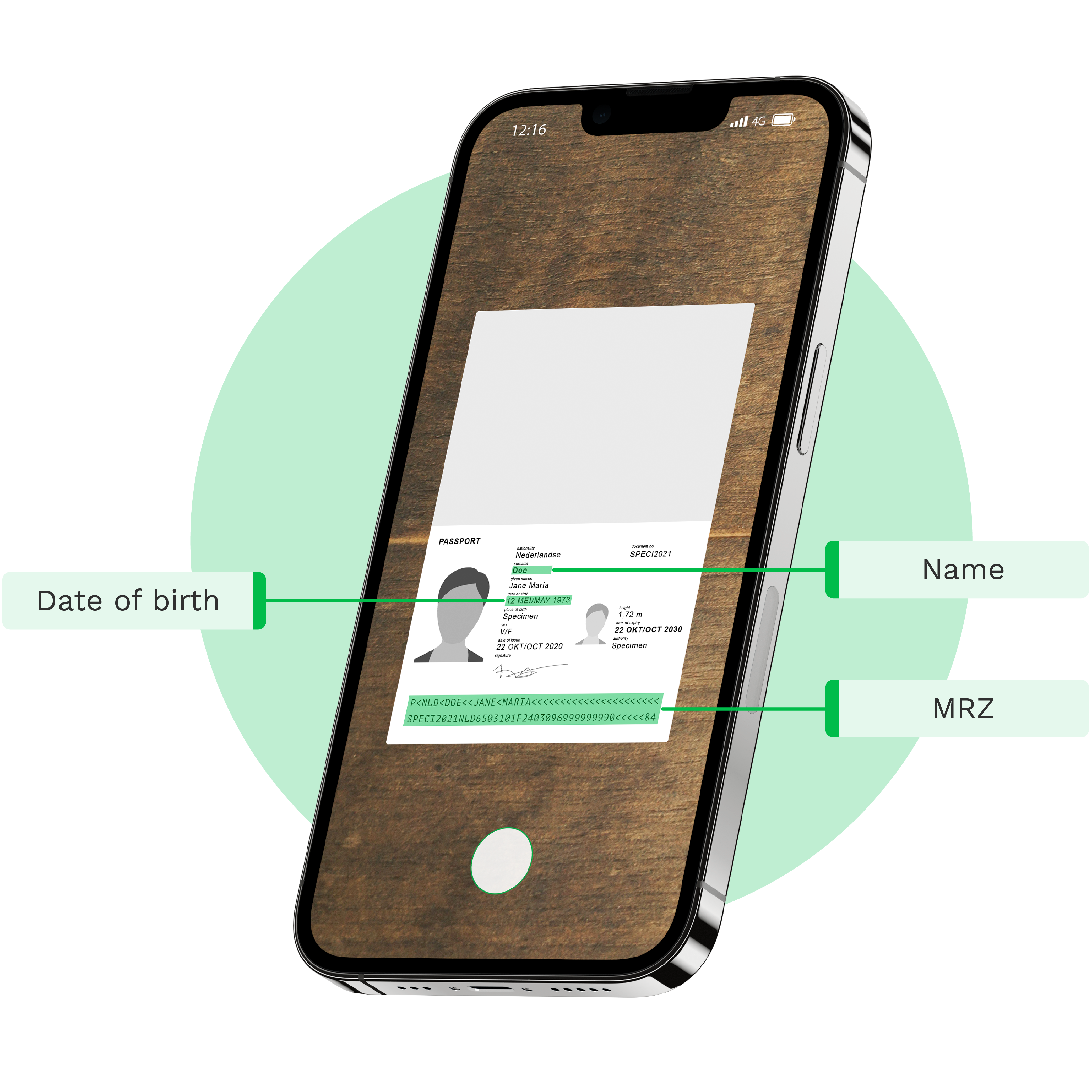
Streamline Processing withPassport OCR
Go Beyond Passport Data Extractionwith Klippa DocHorizon

Passport OCR in 3 Steps
Stay at the forefront of document processing by effortlessly integrating our Passport OCR via API or SDK. Discover how Klippa’s OCR software extracts data from passports in three simple steps.
Scan passports with a scanner SDK or upload them through our Passport OCR API
The first step is sending a passport file to our API. We support formats such as
.jpg, .jpeg, .png, .pdf, .doc, .docx, .xlsx, .heic, .webp and more. Usually, this is done from a mobile app, email, FTP, or web application.The image can be sent either cropped (without a background) or uncropped (with a background). If you send the document uncropped, our API will automatically crop the document.
To optimize the image quality, use our scanner SDK.
Transform image to TXT with OCR Passport Engine
As soon as the document has been received, it is converted to a TXT file by our OCR passport reader. At this step, all the data from the passport is extracted into a text format, but not yet structured.
Receive JSON output from the OCR Passport API
As the final step, the Klippa Parser takes the TXT which was gained from the previous step and converts it into structured JSON. The JSON is then returned as output from the Passport OCR API.
From this point on, the passport can easily be processed in the database of your company. An extra option is to extract additional data like the signature or the passport picture.
Do you want to test our solution for free?
Which Data Fields Can Be Identified with Klippa’s Passport OCR?
Below are the examples of data fields that can be extracted with OCR passport reader. The number of fields is fully customizable. Need additional passport OCR fields? Just ask!

Enjoy the Benefits of OCR Passport Scanner
Reduce Cost
Automate document processing with Klippa’s OCR for passports to reduce operational costs.
Improve Speed
Extract data from passports to simplify and speed-up KYC and onboarding.
Prevent Fraud
Detect fraud attempts, duplicates, and errors in an instant with Klippa’s AI algorithms.
Minimize Errors
Prevent errors caused by manual data entry with precise OCR passport scanner.
Implement Passport OCR in Your Workflow
Klippa provides easy integration via our platform, API, or SDK, and broad compatibility with major platforms and tools. Our well-documented solutions guarantee a hassle-free and smooth experience.
Low-Code Platform
Easily create & automate your entire document workflow on one IDP platform.
API Integration
Connect our document modules to your own application(s) via API.
Mobile Scanning SDK
Employ our SDKs to empower your mobile applications with smart scanning.
We Take Your Data Privacy & Security Seriously
We Support a Wide Range of Identity Documents
With our solutions, you can automatically extract and validate data from many different ID documents. Do you have a special request? Don’t hesitate to contact our team.
“It is extremely pleasant to work together with a party that is as ambitious as we are. The willingness and speed with which Klippa implemented specific modifications for us is impressive.”
Let’s begin!
Discover the power of Klippa’s Passport OCR, as our experts help you to revolutionize passport data extraction.
Frequently Asked Questions
How much does Passport OCR cost?Can Klippa process all types of MRZ with Passport OCR?What use cases are supported by Klippa’s passport OCR?Can Passport OCR extract passport pictures and signatures?Which passports does Klippa’s Passport OCR support?How does Klippa’s software check passport authenticity?Is Klippa passport data extraction GDPR-compliant?How can I integrate Klippa’s Passport OCR?
How much does Passport OCR cost?
The pricing structure for Klippa’s OCR passport software depends on the amount of fields and the document volume to be processed.
Get in touch with our product specialists for a quote.
Can Klippa process all types of MRZ with Passport OCR?
MRZ (Machine Readable Zone) is available in three different formats, called Type 1, Type 2 and Type 3. Klippa is able to read and process all three types of the MRZ automatically.
On passports, the Type 3 is commonly used. It contains two lines of 44 characters each that can be read using OCR. They contain characters A-Z, 0-9 and separators. The MRZ always contains a checksum to confirm the validity.
MRPs (Machine Readable Passports) are passports that can be automatically read and processed using passport OCR software. The passport parsing API captures and extracts the passport’s MRZ.
Can Passport OCR extract passport pictures and signatures?
Klippa strives to be the best in everything. Therefore, we are also able to extract the pictures and signatures from passports, next to all the normal data fields.
Extracting the pictures and signatures is optional when it comes to passport OCR and can be used for KYC use cases.
What use cases are supported by Klippa’s Passport OCR?
We can automate any process that requires validating large amounts of passports and other identity documents like ID cards, driving licenses or residence permits.
If time and quality are important factors, then we are definitely a good fit. We help our clients with automatic processing, classification and data extraction.
Passport OCR can be used for digital client onboarding, streamlining administrative processes or for KYC (Know Your Customer) compliance in many different industries.
Which passports does Klippa’s Passport OCR support?
We are on a path to support all passports worldwide. Currently, we provide support for all Latin languages. Our software is already being used by clients all over the world to process many different types of documents.
Any passport containing an MRZ can also be processed woth our OCR for passport. Check information for your country on our Global Identity Verification page.
If you have a specific case, don’t hesitate to contact us.
How does Klippa’s software check passport authenticity?
Next to normal data extraction of passport OCR, Klippa offers an API and a scanner SDK for identity validation. This solution is called Klippa Identity Verification and is used for KYC and remote customer onboarding.
It goes a step further than just the passport OCR API and actually checks the picture quality, validity of the passport and numerous other points. It also allows the comparison of two independent selfie pictures with the picture on the passport, returning a matching score to validate if they are the same person.
We assist in conducting KYC checks for various sectors such as KYC for banking, gambling, marketplaces, traveling, car rentals, healthcare and more.
Feel free to contact us if you want to know how we can help with your unique case.
Is Klippa passport data extraction GDPR-compliant?
By default, Klippa does not store any customer data. Data is always processed under a data processing agreement (DPA) and all services from Klippa are compliant with GDPR. All data transfer is done via secure SSL connections.
Our servers are ISO-certified and by default located in Amsterdam, the Netherlands. Getting a custom server on a location of choice is possible in any location worldwide.
On a regular base, our security is tested via third-party penetration testing to ensure state-of-the-art security at all times.
How can I integrate Klippa’s Passport OCR?
Our Passport OCR API can be implemented into any software, web or mobile solution that you may be using. The main source of communication is JSON, so it is independent of specific programming languages.
Our mobile SDKs have been built using native IOS (Swift) and native Android (Kotlin). This means they can be implemented into native apps, but they can also be wrapped for cross-platform languages such as Xamarin, ReactNative, Nativescript, Flutter, PhoneGap, Cordova, Ionic and more.
Klippa’s solution is made in a developer-friendly way. It is well-documented, so that developers can have all the information they need to successfully implement our API.