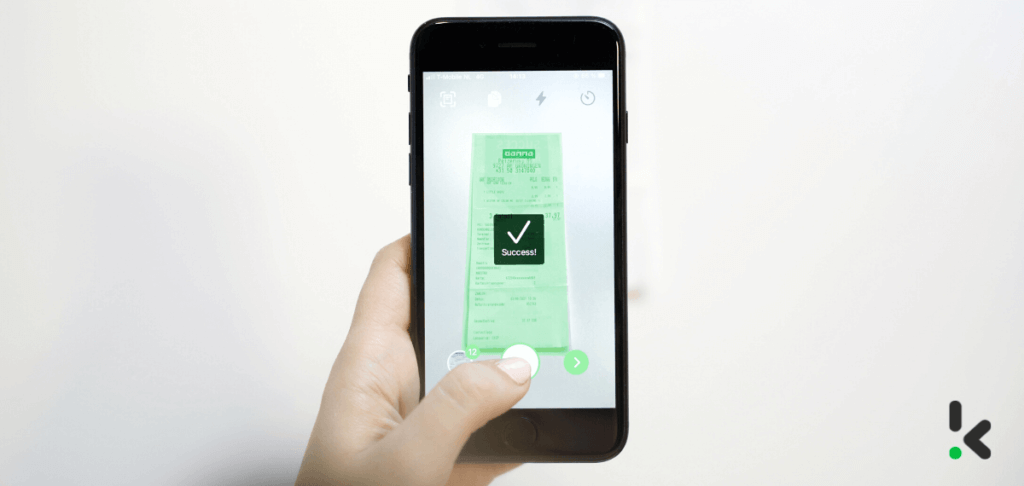
By now, you must have heard about the word OCR, but it might be unclear how it can add value to your business. In simple terms, it is known as text recognition. Businesses often use OCR to capture data from receipts, extract data from documents, and read license plates.
So what is OCR? OCR is a technology that constantly evolves and transforms various industries by reducing manual processes through automation. Today you can find a variety of vendors providing OCR software and even more advanced solutions such as Intelligent Document Processing (IDP). But why is it getting more adoption from industries such as banking, retail, travel, legal, and healthcare?
Here in this blog, you will find everything you need to know about OCR. We will cover what it is, how it works, its use cases, its benefits, and how you can get started. Now, let’s get into it!
What is Optical Character Recognition (OCR)?
Optical Character Recognition (OCR) is a technology that helps users extract text from images or scanned documents and transforms that text into a format that the computer can read.
This is handy when data is needed for further processing, such as in bookkeeping, expense management, loyalty marketing campaigns, or identity proofing.
In essence, you can cut back manual document processes by using OCR software to recognize letters, words, line items, phrases, and patterns.
Often we see OCR solutions such as Zonal OCR coupled with Artificial Intelligence (AI) and Machine Learning (ML) to automate certain processes and increase the accuracy of data extraction.
For optimal text recognition, it is required to dedicate time and train the OCR technology by feeding it with a lot of data. Over time it gets better in terms of accuracy and document coverage.
Now that we have covered what it is, the next step is to walk you through how OCR works.
How Does OCR work?
OCR works like the human capability to read a text and recognize patterns and characters. Normally, humans would read the text and then extract the necessary information by manually entering the data into a system, datafile, or database.
OCR does this a bit differently. The technology enhances the quality of a scanned text or an image and follows several steps to extract data that has been captured. The difference is that manual work takes more time and is more prone to human errors.
Let’s take a detailed look at the following steps of the OCR process:
- Step 1: Image pre-processing
- Step 2: Segmentation
- Step 3: Character recognition
- Step 4: Post-processing of the output
Step 1: Image Pre-processing
For the data extraction to be accurate, the quality of the image must be enhanced through AI image processing. The process of enhancing images is also known as the image pre-processing phase. The clearer and better the image or the scanned document, the more accurate the data output.
In the pre-processing step, the OCR engine automatically looks for errors and corrects problems. The techniques often utilized to enhance the images or scanned documents include:
- De-skew – The process in which a photo or a scanned document is straightened and the angle corrected.

- Binarization – The process in which an image or a scanned document is converted to black and white. Binarization enables a more accurate way to separate text from the background.

- Zoning – Also known as layout analysis, used to identify columns, rows, blocks, captions, paragraphs, tables, and other elements.
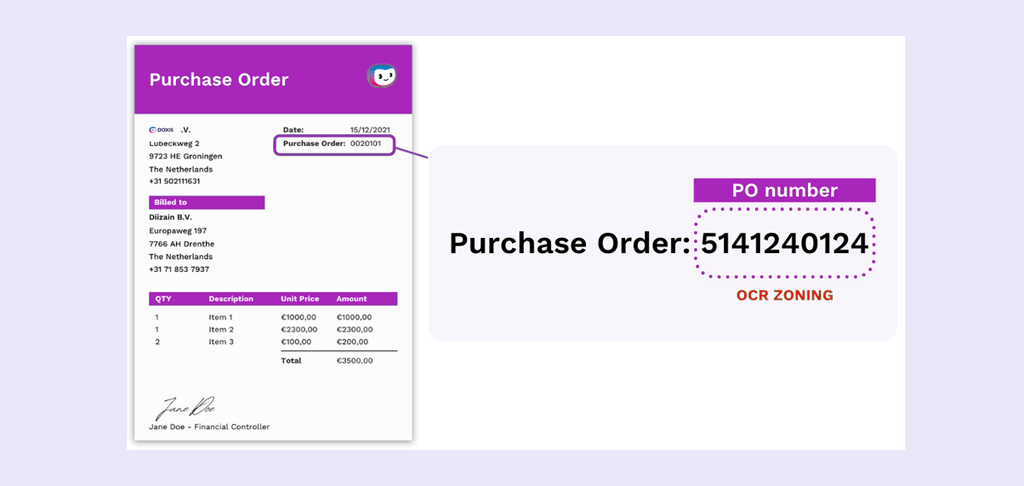
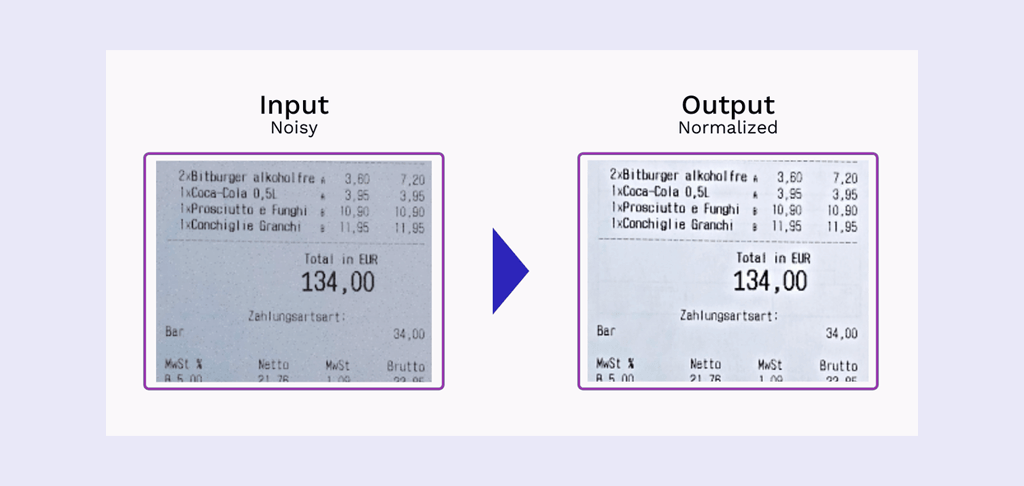
- Normalization – The process of reducing noise by adjusting the pixels’ intensity value to the surrounding pixels’ average values.
Step 2: Segmentation
Segmentation is the process of recognizing one line of text at a time. Segmentation involves the following steps:
- Word and text line detection – Refers to the identification of the text lines and the words that belong to them.

- Script recognition – The process of identifying the script based on documents, pages, text lines, paragraphs, words, and characters.

Step 3: Character Recognition
In this step, a picture or document is broken down into parts, sections, or zones. After the separation is done, the characters within them are recognized.
Two approaches are invoked in the character recognition step:
- Matrix matching – The process in which each character is compared with a library of character matrices. The OCR model completes a pixel-by-pixel comparison to label an image of a character to the corresponding character.
- Feature recognition – The process of recognizing text patterns and features of characters from images. For instance, a character’s size, height, shape, lines, and structure are compared with those in the existing library.
Step 4: Post-processing of the Output
This step is all about the techniques and algorithms that improve data extraction accuracy for the most optimal result. First, the data is detected and then fixed if necessary.
The extracted data is compared against a vocabulary or library of characters for grammar checks and contextual considerations to complete the post-processing phase.
While traditional OCR is exceptionally beneficial in converting images to machine-readable text and valuable data, it also has a few limitations. We will cover the most important ones next.
Limitations of Template-based OCR
Traditional OCR was never meant to be created as a dynamic data extraction solution. It was initially invented for blind people to convert printed characters into speech. Later, the technology was utilized to read and recognize black text against a white background. Hence, OCR doesn’t come without a few challenges.
Here are the five main limitations of traditional OCR:
Dependent on Input Quality
The text recognition and extraction quality directly depend on the image input quality fed to the engine. For instance, the accuracy drops drastically when the character height is below 20 pixels.
Reliant on Templates and Rules
Traditional OCR requires templates and rules to perform. Strict rules must be set up by programming the engine to capture data from the correct fields and lines. Therefore, it cannot cope with the diversity of documents and struggles with unstructured ones.
Lack of Automation
As a result of being reliant on templates and rules, traditional OCR lacks many automation possibilities. For instance, if you want to extract structured data from invoices, each specific data field would require a new rule. And as you know, invoices come in various styles and formats, leading to many, many rules.
Adding more rules would mean more data and resources needed to spend on training the OCR engine. There will always be more rules that need to be set up with the conventional approach, so this can become a serious bottleneck.
Expensive
As more rules and algorithms are required to be developed to increase accuracy, traditional OCR can become very expensive. In addition to that, creating these rules and algorithms does not always guarantee a high-quality output as it also depends on the image input quality.
Copes Poorly with a High Document Variety
With traditional OCR, the output is often highly accurate when documents are simple and come in with few variations. However, many businesses need to process various documents within their workflows.
The higher the document variety, the more challenging it becomes. Because the traditional OCR engine is trained with templates, it cannot keep up with a high document variety.
All in all, we can conclude that traditional OCR is not perfect. But don’t let this discourage you. As the market gets more demanding each year regarding requirements and features, OCR has taken multiple leaps forward to match that demand.
Let’s have a look at more advanced OCR technology.
The Next Generation of OCR technology
The next generation of OCR technology is already here. It is often powered by both Machine Learning and AI, which enables organizations to achieve what they could not with template-based OCR: automation. This revolutionizing technology is also known as Intelligent Document Processing (IDP).
IDP can deliver results beyond human capabilities when efficiency and time are considered. It makes sense of data, categorizes, organizes, and converts the data automatically for the user, all of this within seconds.
One of the major advancements is that it’s not restricted to templates or rules like its conventional precedent. This makes AI-powered OCR software more scalable and affordable for businesses.
Let’s take a closer look at the roles of Machine Learning and AI in modern OCR solutions.
The Machine Learning Approach
OCR software embedded with Machine Learning (ML) can be trained to recognize patterns and the meaning of content through a set of rules. This can be done through supervised learning, unsupervised learning, or combining these two training methods.
Next, we will explain these methods with an example (we will try to keep it as easy as possible).
Supervised Learning
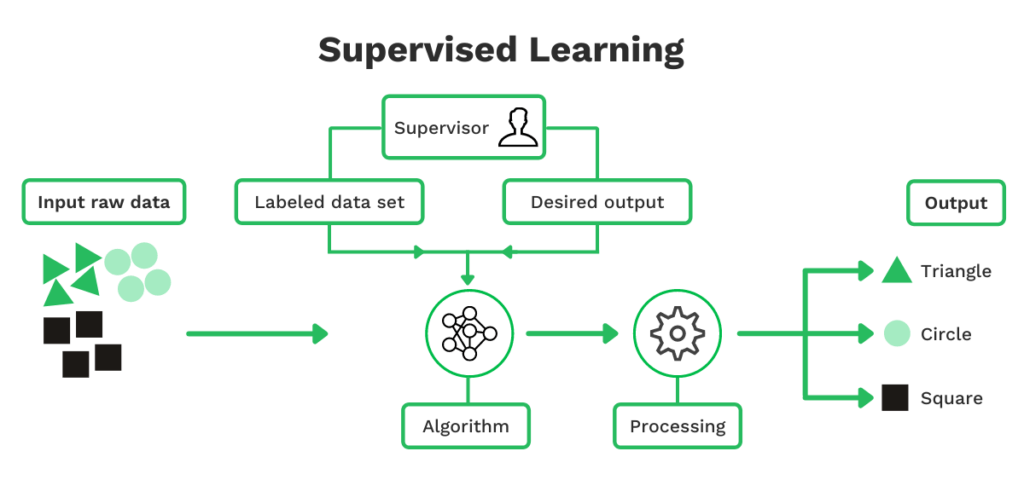
Supervised learning in ML refers to using labeled data sets to train algorithms that classify data and predict outcomes with high accuracy. The model needs to be fed with a large amount of input data to achieve this.
For instance, if you would like to predict if an email is spam and put it in a category, you need to feed the engine with enough spam emails. With enough data, the model can recognize and predict the category and thus classify an email correctly.
A similar approach applies to predicting the location of the price of line items or the merchant name on receipts.
Unsupervised Learning
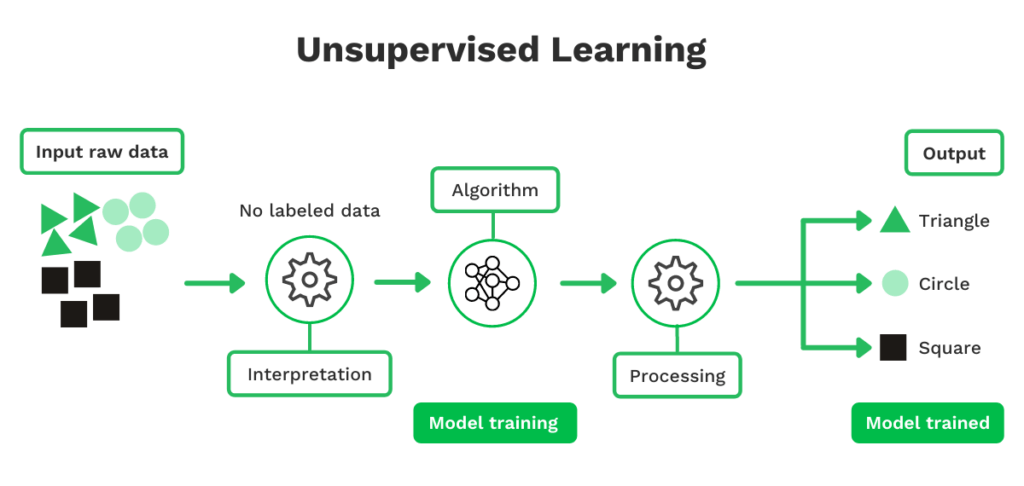
Unsupervised learning is, in essence, similar to supervised learning. The difference is that unsupervised learning uses unlabeled instead of labeled data. This approach is more useful when common properties are hard to identify within a data set, which gives the model more freedom.
Even though labels for data points are not defined, the actual data points remain. Therefore, the model can recognize patterns by observing the input data. To put it simply, unsupervised learning can replicate the human capabilities to adapt and learn.
For example, if your business needs to process receipts, you would need to feed the unsupervised learning model with many receipts. The machine learning model then interprets the input data and makes interpretations of similarities.
Let’s say that it is able to define the merchant name and total amount (i.e. the data points) around the exact location on the receipts. The model then takes this information to predict whether the next document is a receipt or not based on similarities.
Semi-supervised Learning
Like the name suggests input data is both labeled and unlabeled in semi-supervised learning. Often it is used to tackle data extraction issues when dealing with high volumes of data.
As semi-supervised learning combines the best of both, it helps tackle the challenges in both approaches; classification, time, costs, and high volumes of data.
It is ideally used for cases where a small number of training data can bring noteworthy results in terms of accuracy (e.g. classification of identity documents).
How do you know which machine learning approach to choose from? The answer is simple; you don’t need to. Especially when many vendors provide out-of-the-box OCR solutions. Now the role of machine learning is explained, we cover the role of AI next.
AI for Automation
With AI embedded into the OCR software, the solution can constantly adapt and learn to recognize the data more accurately. It can create a deep understanding of semantics and widen the range of supported languages, formats, layouts, and document types.
What AI does is it allows the OCR software or system to analyze all available data, find correlations, and create an information-rich knowledge base. The knowledge base that AI creates can adapt over time, which can help with the progression of data extraction accuracy.
The best part of AI is that it replicates human capabilities to scan and understand the key insights with high speed and accuracy.
Whatever your business case is, an OCR solution powered by AI can help you make the data work for you.
Since we got ML and AI covered, let’s look at the benefits when both are embedded in the OCR solution.
Benefits Beyond Conventional OCR
Beyond conventional character recognition, advanced OCR solutions can do much more. To give you an idea of how advantageous it is to use this technology in your document processing workflow, we have listed the following list of benefits below:
Digitize documents within seconds – With OCR software, your organization can go paperless and have information extracted from documents in a digitalized format such as PDF, JSON, CSV, XML, etc. This process can be done within a few seconds.
Faster implementation time – More advanced OCR solutions are not solely reliant on rules and templates. Hence, it takes less time to train the engine and implement the technology.
Scalability – The next generation of OCR cloud solutions offers scalability, which its conventional predecessor falls significantly behind. While it is possible to scale with template-based OCR, it can quickly become too expensive for businesses.
Higher accuracy – While conventional OCR has a data extraction accuracy of 60% to 85%, many more advanced solutions embedded with AI and Machine Learning can get up to 99%. While manual data extraction yields an accuracy of 90%-95%, it is way slower and inefficient for many businesses.
Reduction of manual entry mistakes – Errors often happen when people work on tedious and repetitive tasks, such as manual data entry. OCR can automate these tasks, thereby reducing human error and manual data entry mistakes. With AI and Machine Learning, the error rate can be reduced even further.
Faster turnaround time – Traditional document processing workflows often have many slow, cumbersome tasks that create expensive bottlenecks. Manually verifying and extracting data can take 10-20 minutes per document, while traditional OCR can do that in less than half the time. IDP, however, can do that within 15 seconds, which equals 98% of the time saved.
Cost reduction – As AI-powered OCR enables faster turnaround times and automates data entry and other document tasks, the overhead is significantly lowered. This leads us to one of the main benefits for organizations: cost reduction. With manual document processing, costs per document can range anywhere from €4-6. Traditional OCR can reduce the cost per document to €1-2 and IDP to less than €0.50.
Fraud detection – Businesses lose enormous amounts of money to document fraud each year. More advanced OCR can help tackle this issue with fraud detection through image and EXIF analysis. It can save you from losing capital to both internal and external fraud.
Enhanced customer experience – There are many business cases where AI-embedded OCR helps enhance customer experience. For instance, when banks onboard new customers, the technology makes the onboarding process smoother and more agile through mobile integration.
Comparison between Document Processing Methods
We have covered multiple benefits of the next generation of OCR technologies. But there is still a wide range of methods and solutions to process documents, and finding the right one can be overwhelming. To make your life easier, we created a comparison table of different methods.
To conclude, OCR technology can bring many benefits to businesses. However, more advanced technologies such as IDP perform way better than traditional solutions. Of course, no solution is perfect, which is why OCR technology is constantly improving to overcome certain limitations.
Now that we covered the main benefits, it’s time to go through some of the most common use cases.
What is OCR Used For?
By default, any high-volume repetitive task that includes document processing can be automated with AI-powered OCR software. We will highlight a few use cases below to inspire you to start using an OCR solution for similar procedures within your organization:
- Receipt OCR for loyalty programs
- Data extraction from IDs for customer onboarding
- Automated invoice processing for accounts payable
- Automating document completeness checks
Receipt OCR for Loyalty Programs
Loyalty programs exist in many shapes and sizes. Most of them involve some kind of points-based campaign or cashback promotion. Customers have to send in their receipt to the retailer and, in return, they receive a reward for buying the product.
As you can imagine, such programs usually involve a lot of back office work as the proof of purchase (receipts, invoices, etc.) needs to be checked, the client database to be updated, and the loyalty points or cashback to be determined and granted.
In such a case, receipt OCR via a scanning solution is optimal for taking over the tedious and error-prone back-office tasks.
Organizations that need to verify whether the consumers actually bought the products in the loyalty campaign, no longer need to check the receipts manually. OCR can scan the line items from receipts and verify whether the products have been bought within the period of the campaign.
Data fields that can be extracted:
- Language on receipt
- Country of origin
- Merchant name
- Method of payment
- VAT amounts and percentages
- Currency
- Total amount
- Purchase date
- Line items
- And many more fields
Some OCR vendors, such as Doxis, can also help organizations to prevent fraud by providing duplicate detection based on image hashing. With early detection of fraud attempts, loss of time and money are minimized.
Data Extraction from IDs for Customer Onboarding
Organizations in the financial industry, such as banks, have to verify their customers’ identities to make sure that these customers are who they claim to be when doing customer onboarding.
This process is also known as the Know Your Customer (KYC) process. Verifying the identity of customers and entering data into multiple systems manually for cross-validation can be inefficient and time-consuming.
This is why OCR is utilized in the process: to speed up the turnaround time and increase the intake of new customers. With OCR software, financial institutions can simply scan and extract data from IDs automatically within a few seconds.
Data fields that can be extracted:
- Full name
- Nationality
- Date of birth
- Date of issue
- Location of issue
- Valid through
- Document number
- Social security number (SSN)
- Machine-readable zone (MRZ)
- And many more
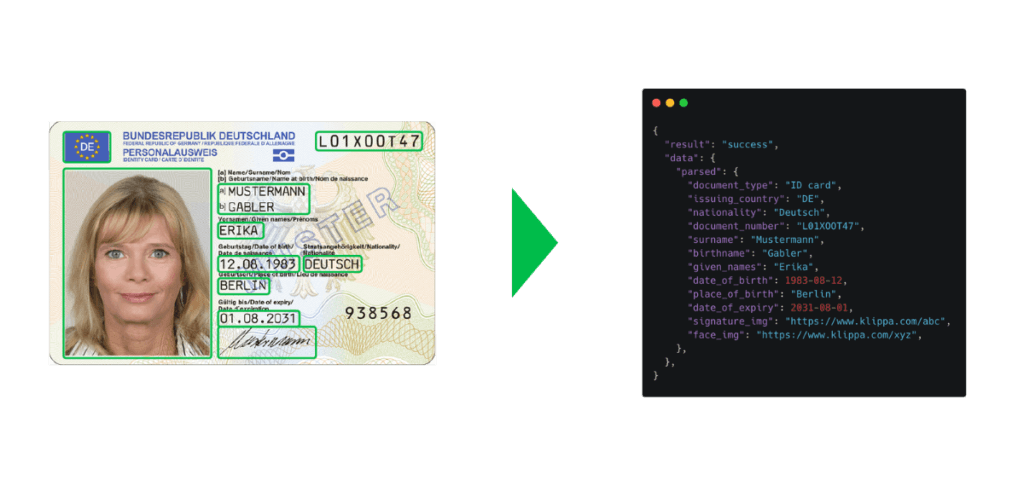
After the data is extracted, it can also be cross-checked with fraud databases or blacklists to uncover fraud attempts.
OCR technology is heavily integrated into KYC automation these days when the majority of customer onboarding happens digitally.
Automated Invoice Processing for Accounts Payable
The accounts payable (AP) department of an organization approves invoices before they are paid. This process can be dreadful. Invoices that come in need to be organized, verified, corrected, approved by the right person, paid, and finally added to the company’s bookkeeping system.
With OCR technology, companies can streamline and automate their AP workflow and eliminate manual tasks by automatically capturing data from invoices. You can simply feed the software with the invoices, and it does the rest: from digitization to sending the final output to your Enterprise Resource Planning (ERP) or bookkeeping system.
A report from MineralTree indicates that 64% of organizations with AP automation process more invoices than those without, and 23% process the same amount of invoices with lesser staff.
We have found similar numbers through our internal research. By optimizing your invoice processing for accounts payable, you decrease time spent by up to 70%, shorten turnaround time from days to minutes, minimize errors, and achieve cost savings of 70+%.
Automating Document Completeness Checks
In industries such as legal and banking, a lot of staff time is dedicated to checking document completeness to verify if they contain the information required. For instance, a legally binding contract should contain the signatures of the parties entering the agreement.
Failing the completeness check can have severe consequences and fines. Without the signatures of both parties, for example, a contract turns into a useless pile of papers, and is unenforceable by law.
This is where OCR comes into play. It takes over the task of checking for completeness and validating a document’s originality. It can detect within seconds whether signatures are set on a document and/or whether some crucial information, such as an important clause, is missing.
To give you a complete view, OCR providers such as Doxis can automate the following completeness check tasks:
- Review the number of documents
- Classify the document type
- Identify the number of pages per document
- Validating the presence of specific fields, values, lines, or components (e.g., signatures, images)
- Cross-checking data between documents with an external or internal database
It’s safe to conclude that OCR can be used for many purposes and use cases. Has it inspired you to look for automation possibilities within your organization? Then the last question is how to get started. To help you out, we will cover different ways to integrate OCR technology into your operations in the next section.
How to Start Integrating OCR?
There are several things to consider when thinking about integrating OCR into your business. Such factors can be the document type, the document processing volume per month, your organization’s resources, your use case, and so forth.
To help you, we have listed the following options:
- Integration with OCR API
- Mobile scanning solution
- End-to-end solution
Integration with OCR API
OCR API integration enables you to process documents by sending them through a mobile app, e-mail, and web application. Often this is the best choice if you already have an existing software or application that you want to integrate OCR technology into.
What an Application Programming Interface (API) does is that it allows your software or application to communicate with the OCR vendor and use their technology for your document processing.
While it may sound complicated, you can receive the data from documents back in a structured format within seconds.
Mobile Scanning Solution
Mobile scanning solutions, as the name suggests, support the use cases when organizations need an agile way to capture data. For example, your employees do not need to store receipts physically as they can take a photo of the receipt instead.
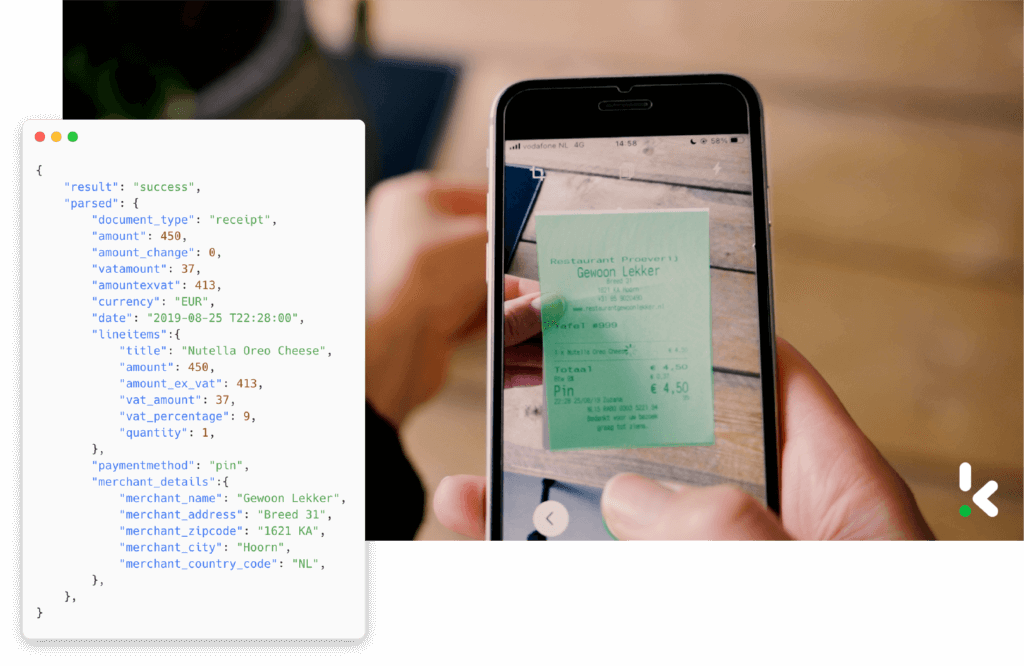
The process of going back to the office with receipts to create a reimbursement can be eliminated. This, of course, saves time and lowers the overhead costs.
To integrate the mobile scanning solution, you need a properly documented Software Development Kit (SDK).
It is very customizable, and with high-quality image pre-processing features, you can scan documents or even objects such as utility meters in harsh conditions.
An SDK is the best choice if you need to utilize an AI-powered OCR solution in your mobile application. On the other hand, an API is more suitable when you want to just upload documents via a web portal or application instead of scanning documents with a mobile device.
End-to-end Solution
With an end-to-end solution, you can get started relatively effortlessly and quickly. All you need to do is find an OCR software vendor that can help you with your business case.
For instance, an end-to-end solution like Doxis AI.dp can help businesses streamline any document processing workflows. Its cutting-edge technologies can automate data extraction, classification, conversion, anonymization, and verification.
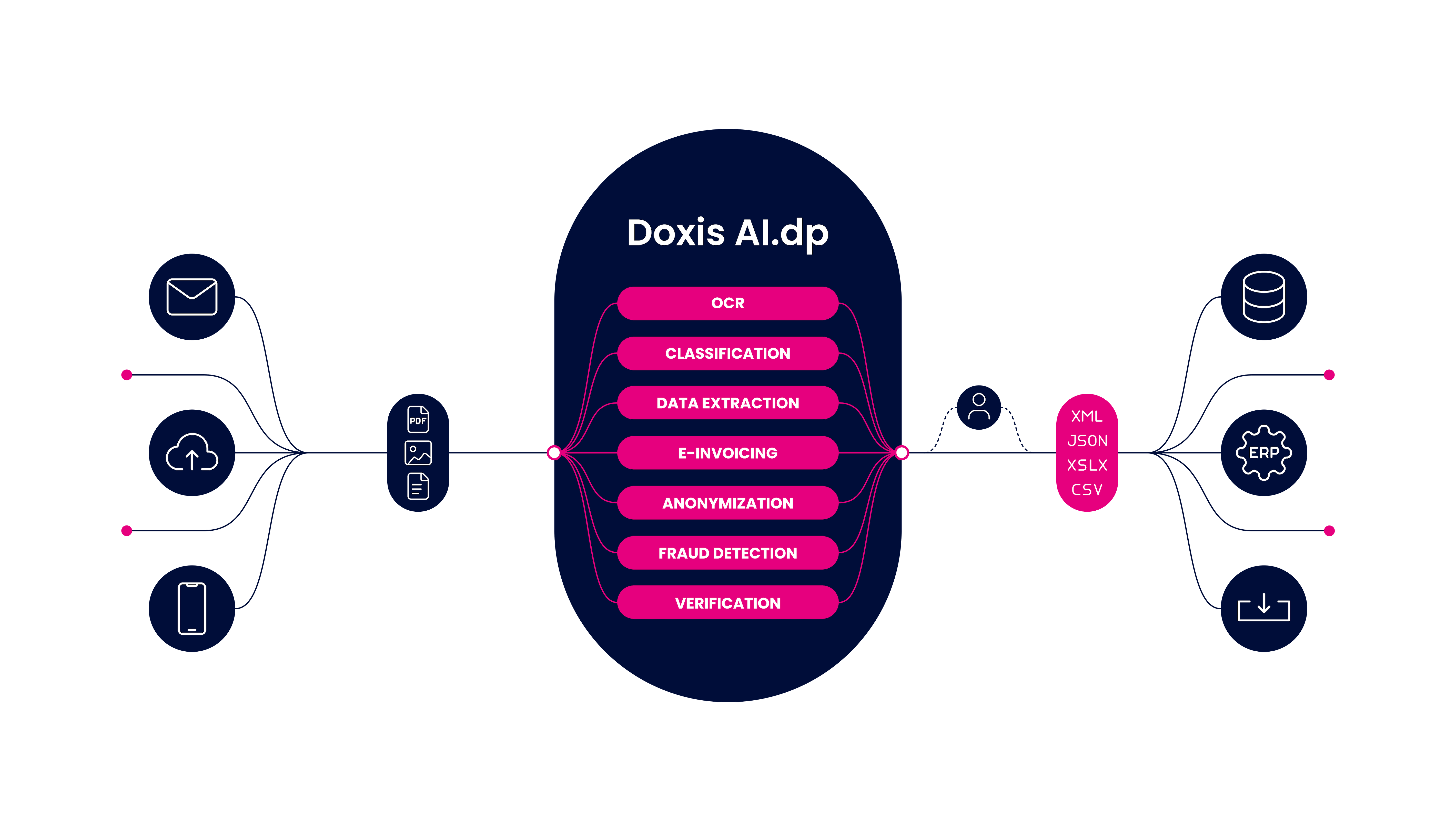
Going Beyond Traditional OCR with Doxis
Traditional OCR is becoming more obsolete than ever. Businesses need to find a way to improve the bottom line, enhance customer experience, and at the same time embed tools to increase efficiency in the organization.
This is where Doxis can help you. Whether you want to integrate OCR technology via an API, SDK, or you simply want to get started right away with an end-to-end solution, Doxis can do it all.
Partner with Doxis to make your employees the champions in document processing. Get started by filling in the demo form below!