
The best-performing organizations are those that base their decisions on up-to-date and accurate information. Many businesses, however, struggle with their information collection, especially if the information is located in a wide variety of sources. These organizations often deal with unstructured information formats such as images or scanned documents, which makes data hard to obtain.
This is a huge problem when organizations have to process hundreds, thousands, or even millions of documents per month. Processing large amounts of unstructured documents and converting them into business-ready formats is not optimal as it’s error-prone, expensive, and inefficient.
Luckily, there are different methods to automate manual work that involves extracting information from digital or physical documents. Technologies like Optical Character Recognition (OCR) and Artificial Intelligence (AI) are often key in helping businesses extract information efficiently.
In this article, we will dive into what information extraction is, how it works, its benefits and use cases, and introduce a solution that can help your organization automate information extraction.
Let’s start!
What is information extraction?

Information extraction is the process of extracting information from unstructured formats (e.g. PNG, JPEG, PDF) and converting it into structured, editable, searchable, and machine-readable formats (e.g. JSON, CSV, XLSM). Often businesses get business-ready data by converting PDF to Excel.
Information extraction enables the consolidation of data. Multiple sources of information, usually poorly organized and completely unstructured, can be converted into useful information that can be stored or analyzed even further.
Having clear information about your organization’s operation is the foundation for doing a critical analysis of the decision-making process, service improvements, sales projections, and cost optimization, among other things.
So how can your business extract information? In general, there are three information extraction techniques for businesses:
- Manual Information Extraction
- Automated Information Extraction
- Automated Information Extraction with Human-in-the-loop
1. Manual information extraction:
Manual information extraction is the act of collecting information manually from a data source. This occurs in many business processes. In your company, for example, you might have an employee processing invoices.
The employee reads the physical or digital document and types the information into your accounts payable software. This can be a practical method when you have to extract information from just a few documents.
However, extracting information manually is repetitive, time-consuming, and error-prone, which creates unnecessary overhead costs. This is why many companies are taking advantage of automated solutions to manage the information extraction process.
2. Automated information extraction:
So, how can businesses automate information extraction? With information extraction software using technologies such as OCR and AI, businesses can automatically extract info from any type of document.
OCR, in short, is a technology that can turn an image into text. AI technologies, on the other hand, help with information recognition, document classification, and information verification. In simple terms, AI makes sense of the extracted information and recognizes data fields, such as an invoice number or total amount.
The combination of AI & OCR enables information extraction software to extract data from documents accurately and fast. With information extraction software embedded with these technologies, the process of extracting information can be done within a matter of seconds.
Let’s have a look at a third way to extract information from documents.
3. Automated information extraction with Human-in-the-loop:
Human-in-the-loop automation combines the previous two ways. Even with the most advanced technology, it is nearly impossible to extract data from documents with 100% accuracy all the time.
In some cases, 1% of information extraction mistakes can already cost businesses millions of euros. That’s why, in many cases, combining the best of humans and the best of Artificial Intelligence can yield the best results.
Let’s run a simple calculation. Say your organization processes 1,000,000 documents a month. Let’s assume that each mistake (per document), on average, costs you 100 euros. 1% of mistakes would equal 1,000,000 euros.
This is why some industries prefer to combine automation with human intelligence to minimize costly errors.
Now that you know the definition of information extraction and the methods, let’s take a closer look at the automated process with software.
How to extract information automatically?
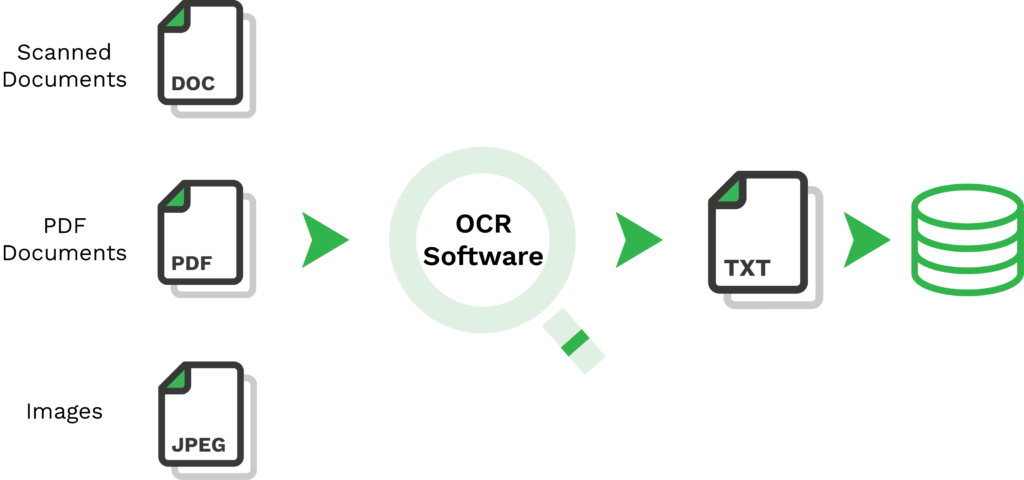
With OCR software, your organization can automatically process any document or image type within a matter of seconds. But, what does the information extraction process look like?
The process of extracting information from a document generally works as follows:
- Uploading the document – First, the unstructured document must be uploaded to the software. This can be done via web, email, computer, or mobile phone. Often, the easiest way to do so is to take a picture with a mobile device using a document scanning SDK. The input file can be sent to the software in multiple unstructured formats, such as JPG, PDF, PNG, TXT, and many others.
- Image to TXT – After the document is uploaded to the software, the actual information extraction begins. The only problem is that the computer cannot read what is on the document or picture yet. Therefore, the image has to be transformed into a TXT file using OCR.
- Information format conversion – In the final step, the information extraction software reads through the TXT file and converts the file into a structured format such as JSON, XML, and CSV. Once this is done, the information is stored in a database or passed on to another software.
Now that we know how to extract information from unstructured text documents, let’s see how it can benefit your organization.
The key benefits of automated information extraction
Many companies are taking advantage of automated information extraction solutions powered by AI for various benefits.
The main benefits of using an automated information extraction solution include:
- Improve accuracy to >95%
- Increase employee productivity by 6 hours a week
- Reduce operational costs up to 70%
- Scalability for business expansion
- Faster turnaround time
Improve accuracy to >95%

Replacing manual data entry with automated information extraction drastically decreases costly errors. Machines make fewer mistakes than humans, as they don’t get tired or distracted.
Dealing with large amounts of information manually often opens up the possibility of data entry mistakes. For example, an invoice number can easily be mistyped or overseen.
Automating the process of extracting information from documents will lead to more accurate data overall. With more accurate information, you can make better and more precise business decisions.
Increase employee productivity by six hours a week

With automated information extraction, employees can leave manual tedious tasks behind. Automation is not only faster, but employees can get more work done from your core business in the same amount of time.
In fact, a survey conducted by Smartsheet concluded that automating repetitive tasks frees up time from employees six or more hours a week. That makes a huge difference in productivity by almost a full working day.
Reduce operational costs up to 70%
One of the common reasons for companies to automate the extraction of information is money. Manual information extraction represents more employee hours or even hiring more people to perform manual tasks.
Studies show that manual information extraction usually results in a higher cost of processing, from 60% to 70% more than an automated alternative.
Scalability for business expansion
When a company is growing, the amount of incoming and outgoing documents that need to be processed and stored grows as well. Companies don’t want to increase their workforce just because they need to extract information from more documents. That would distance the company from its core business.
This can be avoided by switching to an automated solution to extract information. As a result of that, the company can scale up its business without having to worry about large volumes of documents.
Faster turnaround time
Extracting info from a document manually is limited to a single person at a time, which can lead to a long turnaround time. That can lead to papers piling up, employees or clients waiting for a response, etc. With information extraction software, turnaround times can go from days or weeks to a few seconds.
Now that we know the main benefits of automated information extraction, let’s have a look at its use cases.
Use cases of Information Extraction
There are several use cases in which information extraction makes a difference. This holds not only for large organizations but basically for any company dealing with a significant amount of documents. Chances are that you work with information sources such as invoices, receipts, ID cards, utility meters, price tags, and identity documents.
See the following list for some of the most common use cases of information extraction (the list is not exhaustive):
- Accounts Payable Automation
- Automated Client Onboarding
- PDF to Excel Extraction
- Image-to-Text Conversion
- Receipt processing for loyalty campaigns
- Data Entry Automation
- Information Extraction from PDF
- Data Collection for Cartel Damage Claims
- Signature Extraction from Documents
It is quite interesting to see how different applications of automated information extraction can maximize the profit of many industries. If you don’t see your use case here, don’t worry, there is a high chance that we can help with your specific use case.
Let’s have a look at our solution, Doxis AI.dp.
Automate information extraction with Doxis
Doxis specializes in automating information extraction for any document-related workflows. With years of dedication, Doxis AI.dp was created to help organizations around the world speed up the process of extracting information from various objects and document types.
With Doxis AI.dp, you can not only automate information extraction but also classify, convert, anonymize, and verify any document thanks to AI-embedded OCR technology. No matter what document automation challenges you face, Doxis can automate it for you.
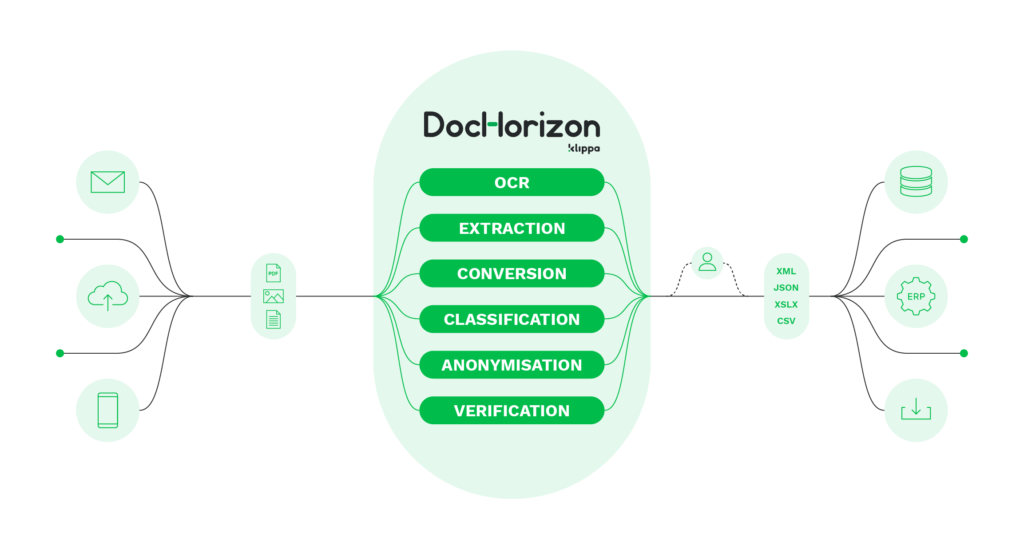
If your organization is looking for a solution to extract information from documents, AI.dp is the perfect solution for you.
Schedule a demo using the form below to see how our solution works. If you have any questions, please feel free to contact us.