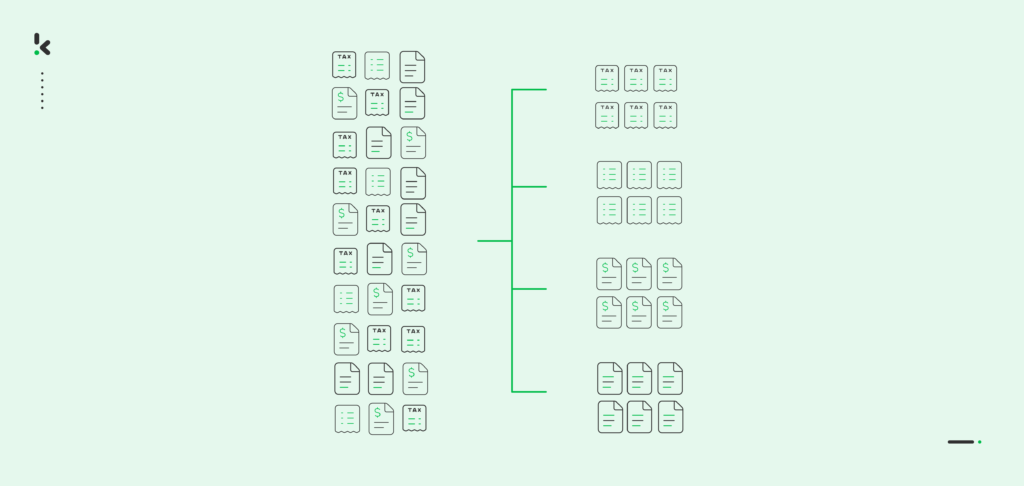
Organizations deal with large amounts of documents on a daily basis, documents which vary in type, content or importance. Ensuring an accurate classification of these files can quickly become frustrating, especially if it’s done manually.
Some of your employees are responsible for manually organizing documents based on these labels. This takes time and in worst-case scenarios, the files get lost as they are categorized inaccurately.
However, thanks to the rapid development of technology, employees no longer spend excessive time labeling documents, leaving these tasks in the hands of automation.
In this blog, you will find a thorough explanation of what document classification represents, learn about the process behind automating it and discover an out-of-the-box solution for classifying your business documents. Let’s start!
Key Takeaways
- Document classification automates file organization, making searches faster and workflows more efficient.
- AI-powered technologies like OCR and Machine Learning allow businesses to categorize documents accurately without manual effort.
- Automating classification reduces errors, ensures compliance, and enhances data security, making it essential for modern businesses.
- Automated document classification software offers a fast, pre-trained solution for efficient sorting, reducing manual effort and errors.
What is Document Classification?
Document classification, or document categorization, is the process of sorting documents into categories to make them easier to find, manage, and analyze. The goal is to organize files accurately, making searches faster and more efficient.
While classifying documents is an important task on its own, it’s also part of a much bigger automation initiative, called intelligent document processing. Therefore, sorting these files is only one of the many actions that can be automated to improve document processing workflows.
Document classification can be done using two parameters, namely text classification and visual classification. Some of these parameters can be seen in real-life search engines, allowing users to find what they are looking for without much effort.
To better understand how document categorization can take place, it is necessary to take a step back and first analyze the technical process behind automated document classification.
Types of Document Classification
As previously mentioned, documents are classified depending on their content, be it text or image. For each type of document classification, you can discover different methods used to detect and analyze the specific content, which we will discuss shortly.
1. Text Classification
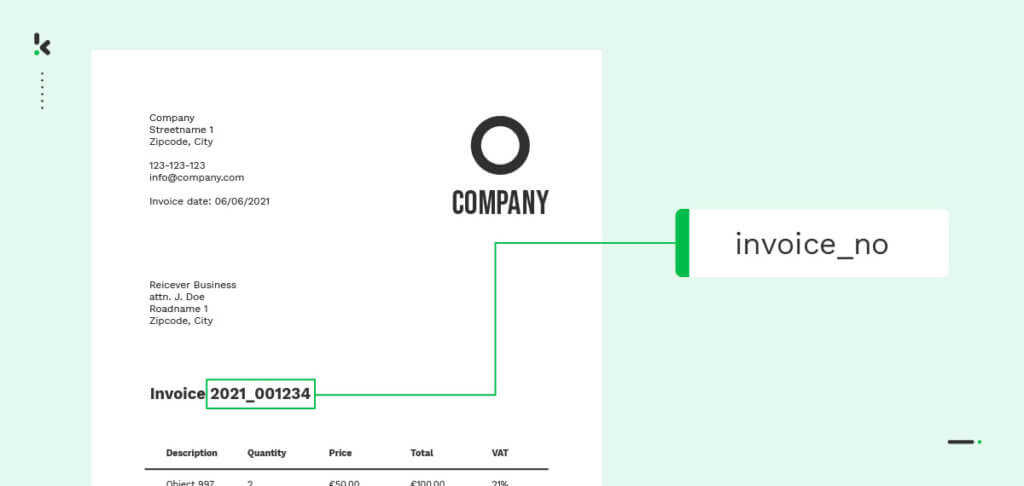
Text classification sorts and processes information from different types of documents. Since businesses rely on text-heavy files for daily operations, it has become a key feature in many software providers, including OCR software, to improve organization and efficiency.
So how does text classification work? Text classification of documents often makes use of technologies such as OCR and NLP, which fall under machine learning technology.
Optical Character Recognition (OCR):
OCR is a technology that helps you extract text from images or scanned documents and convert it into a machine-readable format. Oftentimes, this technology is paired with both Artificial Intelligence (AI) and Machine Learning (ML), to achieve high data extraction accuracy.
Natural Language Processing (NLP):
NLP is a more complex technique, responsible for further analyzing the extracted data and understanding the semantics of the text. NLP makes it possible for computers to understand human language in a specific context, creating a high-accuracy, high-quality data extraction process.
To automatically classify a document, it is required to use OCR to extract information first and NLP to understand the content of the information.
2. Image Classification
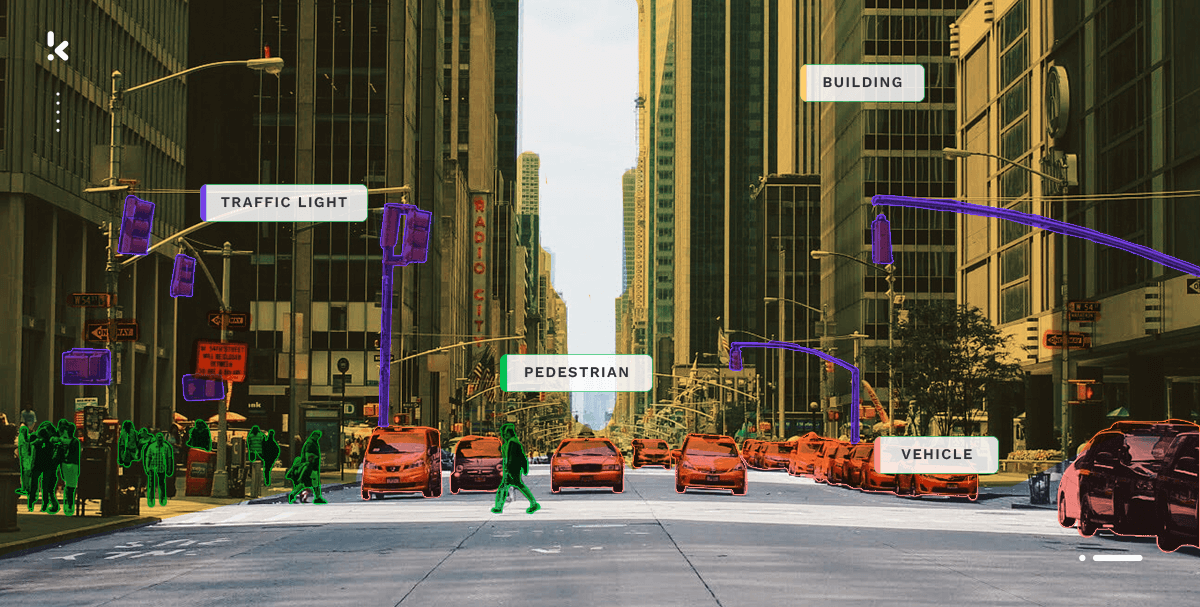
When it comes to image classification, the focus is on the visual structure of documents. Detecting images and videos in a document is done by analyzing the pixels that create the visual and then determining its content. The identification and classification of images is done by employing technologies such as Computer Vision and Object Detection.
Computer Vision:
Computer Vision is an AI-powered technology able to recognize objects on still images or videos. You can use it to detect objects within an image, their location in the document, or the action depicted in the visual content. Computer vision helps you classify images by applying filtering and searching options.
Object Detection:
Object Detection is applied in business areas that have to manage large amounts of visual data, and where classification takes place at a larger scale. For instance, object detection is spread among logistics departments, warehouses and inventories, where scanning barcodes or QR codes is part of daily operations.
Now that you have become familiar with the technologies used to enhance text and image classification, let’s delve deeper into the topic and discover the methods used in automated document classification.
Methods of Automated Document Classification
Automated classification of documents is achieved using Machine Learning. It mainly employs NLP, which requires large amounts of data to be trained on, in order to detect and define patterns in documents with high accuracy.
To train the model, we feed it pre-existing data, which already benefits from predetermined categories and sets of features. This makes it possible for the model to learn statistical connections between words and phrases.
Machine learning classifiers collect training datasets, for instance, articles, essays, or any body of text that can be used to extract keywords and define categories for the model to learn on. However, there are multiple methods of classifying documents using machine learning, which we will cover in the next section.
Supervised Document Classification
In supervised document classification, you provide the input yourself, meaning you train the model on documents that already have a label. Therefore, the classification is done by evaluating the relationship between the new document and the labeled historic data.
For example, you feed the model invoices, receipts and bank statements to learn on. The model will do a great job at recognizing and classifying these types of documents. But if you make the model classify identity documents, it will result in a failed attempt. The model could not find a relationship between the new documents, i.e. identity documents, and the historically labeled data, i.e. invoices or receipts, so the classification ended up being inaccurate.
Pros
- It is an accurate classification of documents
- It is easy to evaluate its results
Cons
- It requires a large training dataset
- It can be time-consuming and expensive to label a large amount of data or the training set
Unsupervised Document Classification
The unsupervised document classification doesn’t require a training dataset to learn on. It aims to sort documents by analyzing their content and finding differences between them. The model then creates clusters, or categories, where the sorted documents are placed. While some documents might share similarities, the categories are unknown to the model, leaving space for uncertainty in the quality of classification.
Pros
- It doesn’t require a labeled training dataset
- It is faster and cheaper to use since there is no labeling required
Cons
- It is more difficult to evaluate
- It is less accurate than the supervised method
Semi-supervised Document Classification
Semi-supervised document classification consists of a combination of the supervised and unsupervised classifications. It uses both labeled and unlabeled training datasets, improving the performance of both classification methods, but perfecting neither.
Pros
- Improves the accuracy of both classification methods
- It does not require as much training data as the supervised classification
Cons
- It is more difficult to implement than both the supervised and unsupervised methods
- It can be less accurate than a completely supervised classification
Now that we’ve learned about the different methods of classification that use machine learning, let’s see what the process of automating document classification actually looks like.
How to Automatically Classify Documents
Automatic classification of documents uses Deep Learning (a subset of Machine Learning) methods to sort files into various categories, without any human input. For this process, you follow a simple, three-step process, which goes as follows:
Step 1: Gather a dataset
To train the classification model, you will need to first go through data preparation. This means gathering at least 20 data points per label, meaning 20 documents per category. This increases the accuracy of the output, giving you a qualitative end result. The algorithm categorizes the output based on the specific data that it was trained on.
For instance, if you’d like to classify only invoices, it would only make sense to train the model on multiple invoices. However, if you want to classify a different document type, let’s say a receipt, the model might have a hard time accurately classifying your desired documents.
Step 2: Train the model
This step might become time-consuming and expensive, depending on the classification method you chose, i.e. supervised, unsupervised or semi-supervised. While it is in fact a redundant task, it is necessary in order to get the most accurate results.
Step 3: Evaluate results
Comparing the results against the expectations is an essential practice to ensure the model performs as you intended it to. This can be done by benchmarking the results of the classification against an already-predicted document, guaranteeing accurate representation in the comparison.
To truly understand this process, it is necessary to take all the time that you need. Rushing to feed the model inaccurate data or not feeding it enough data points, will only make your life harder in the long run. Slowing down and really understanding this procedure ensures you get the best results from your document classification efforts.
Want a faster way?
Instead of building and training your own model, you can use Doxis AI.dp, an AI-powered document workflow platform that automatically classifies documents without manual setup.
Try it now with €25 free credit to experience effortless document classification.
We understand if you’re not entirely sure whether or not implementing automatic data classification is beneficial for your business’s needs or not. Therefore, let us shed some light on some of the advantages that automatic classification of documents can bring to your business.
The Benefits of Document Categorization for Businesses
Automatic categorization of documents allows your organization to deploy day-to-day business processes more smoothly. Some of the benefits of implementing this practice are:
- It saves your business time and resources: Automatic document classification organizes and analyzes large amounts of documents, saving you a significant amount of time and financial resources.
- It helps you identify fraudulent documents: Classifying documents automatically also means identifying fraudulent documents through anomalies or human errors present in these files. Automation helps, therefore, reduce document fraud in your organization, such as invoice fraud.
- It helps automate document sorting: Manual classification of documents can easily become confusing, giving you second thoughts as to which label to give to them, resulting in errors and inaccurate decision-making. Automatic classification solves this issue, sorting or even indexing the documents based on categories predetermined by you and your team.
These benefits might not sound impactful in the beginning, but they can make a big difference in the way you conduct your business. To understand this matter and see the bigger picture, let’s discuss some real-life use cases of automatic document classification.
Real-life Use Cases and Document Classification Applications
Being aware of the theory behind document classification is not enough to really understand its use. Let us present some use cases where automated classification of documents positively impacts your business:
Spam Detection in Emails
Automated document classification software helps identify emails that fall in the spam category. They usually include unnatural-sounding text, grammar errors or spelling mistakes, which raise suspicion in comparison to normal emails. Using document classification, the emails that check these boxes are retrieved in the corresponding spam inbox, keeping your business clear of dangerous links or unsolicited correspondence.
Processing Customer Feedback
Analyzing the semantics and tone of the text, which we discovered is done using NLP, you can separate positive feedback from constructive one. Therefore, your organization gets better access to suggestions aiming at improving business processes, helping you deliver better services to your customers.
Facilitating Customer Support
Using document classification, customer support employees can easily separate claims, refunds, inquiries or other comments, based on the text. This improves workflow efficiency, by sending the corresponding comments to the designated departments.
Document Digitization
Your business may be handling multiple types of documents, for instance, invoices, receipts or contracts. Using document scanning software to scan the document, digitize it, and label it through classification, will streamline your processes significantly.
Your business deserves software that makes all the use cases from above, and more, possible. Such is Doxis AI.dp, which helps you automate any document processing workflow, including document classification, offering your organization the benefits of a lifetime.
Automatically Classify Documents with Doxis AI.dp
Doxis AI.dp is an intelligent document processing solution powered by AI, aimed at streamlining daily business operations at scale. It not only helps you achieve accurate document classification but also helps your business in other areas:
- Extract data fields from a multitude of document types using high-accuracy OCR
- Automatically anonymize data and images for maximum privacy regulations compliance
- Convert documents to the desired format, such as CSV, XML, JSON or PDF
- Benefit from seamless integration with existing software solutions via SDK or API
- Prevent fraud in your organization with automated document verification
- Classify and categorize a multitude of document types
- Process documents based on specific data fields
- Leverage an AI-powered platform for end-to-end document processing and automation
With Doxis AI.dp, your business is set for success. If you’re interested in getting more insight into our product, contact our experts or simply book a demo down below!
FAQ
Automated document classification software uses AI, OCR, and NLP to categorize files into predefined groups without manual sorting. Doxis AI.dp applies these technologies to classify both text and image-based documents with high accuracy.
What types of documents can be classified automatically?
AI-powered classification can handle invoices, receipts, contracts, IDs, forms, and more, regardless of format. Doxis AI.dp supports both text-heavy and visual documents, using OCR and computer vision to identify content.
Can document classification software handle multiple languages?
Yes, multilingual OCR and NLP allow software to process and classify documents in many languages. Doxis AI.dp supports global language sets, making it suitable for multinational businesses.
Is automated document classification secure for sensitive data?
Yes, leading tools comply with privacy regulations and may include redaction and anonymization. Doxis AI.dp is GDPR-compliant, ISO 27001 certified, and offers automatic anonymization to protect personal information.
Can the system classify thousands of documents at once?
Yes, AI classification systems can batch process large volumes efficiently. Doxis AI.dp enables scalable classification with bulk uploads and API-based processing.
Can classified documents be converted into other formats?
Yes, many platforms let you convert classified files into formats like CSV, XML, JSON, or PDF. Doxis AI.dp offers integrated conversion alongside classification, streamlining workflows.
Does automated document classification integrate with my existing software?
Yes, modern tools connect to ERP, CRM, accounting, and cloud storage systems. Doxis AI.dp offers 50+ integrations and API/SDK connectivity for seamless workflows.
How can document classification help detect fraud?
AI models can flag anomalies or suspicious data patterns during classification. Doxis AI.dp detects irregularities in invoices or identity documents to reduce fraud risk.
What industries benefit most from automated classification?
Any sector managing large volumes of documents (finance, logistics, healthcare, legal) can benefit. Doxis AI.dp adapts its AI models to diverse industries through configurable parameters.
How much does automated document classification software cost?
Pricing depends on volume, complexity, and feature set. Doxis AI.dp offers flexible plans, including pay‑as‑you‑go and free €25 credit for trials.