
Document fraud is a persistent threat that can severely impact your business, from financial losses to reputational damage and legal consequences. In the U.S. alone, consumers reported losing over $12.5 billion to fraud in 2024, a 25 % increase from the previous year, according to the Federal Trade Commission (FTC).
“The data we’re releasing today shows that scammers’ tactics are constantly evolving”, remarked Christopher Mufarrige, Director of the FTC’s Bureau of Consumer Protection.
Fortunately, smart document fraud detection software is available, making it easier for you to remain proactive and keep your business out of harm’s way.
In this blog, we’ll break down what document fraud is, explore the most common types of fraudulent documents, and show you how top document fraud detection systems can help you spot issues early and protect your workflows.
Key Takeaways
- You can detect fraudulent documents using Intelligent Document Processing (IDP) tools powered by OCR, AI, and document fraud detection software.
- Techniques like duplicate detection, Photoshop detection, MRZ verification, and EXIF analysis help flag fake documents before they’re accepted.
- Manual review isn’t enough; advanced fraud document detection systems find tampered or suspicious files faster and more accurately.
- Tools like Doxis AI.dp let you integrate real-time document fraud detection into your workflow without slowing things down.
Watch our Document Fraud Webinar Replay to learn best practices, discover common fraud pitfalls, and see how AI-powered detection tools stop fraud before it happens.
What is Document Fraud?
Document fraud is the intentional creation, alteration, or use of false, forged, or illegitimate documents to deceive businesses, exploit verification processes, or gain unauthorized access to services. These documents can range from manipulated ID cards and edited bank statements to entirely fabricated pay stubs, utility bills, diplomas, or business registrations.
Fraudsters use fake documents for a wide range of illegal activities: from identity theft and synthetic identity creation to money laundering, loan fraud, benefit fraud, and even facilitating terrorism or illegal immigration. No sector is immune:
- Financial institutions face forged income statements to secure credit.
- Insurers receive doctored claims or medical documents.
- HR teams encounter fake diplomas and altered employment histories.
- Government services battle with manipulated IDs and residency proofs.
What makes this threat more severe today is the accessibility of AI editing tools, template farms, and fake document generators, allowing anyone to create convincing counterfeits in minutes.
The consequences? Financial losses, legal liability, regulatory penalties (for non-compliance with KYC/AML), and damage to brand trust.
In the next section, we’ll walk you through the different types of document fraud and how they show up across industries, so you know what to look out for.
Types of Document Fraud
Understanding the types of document fraud is the first step toward preventing it. Fraudsters use a wide range of tactics, from duplicating invoices to faking entire identities, all aimed at bypassing verification processes and gaining unauthorized access.
Here are the most common forms of document fraud affecting businesses today:
1. Document Forgery
Fraudsters create entirely fake documents from scratch to mimic legitimate ones, such as ID cards, utility bills, diplomas, or bank statements. These are often generated using template farms or document creation tools.
Example: A fraudster builds a synthetic identity using a completely fabricated utility bill and a fake bank statement to apply for a business loan.
Why it matters: These fakes are often high-quality and bypass visual inspections. Without AI or cross-validation tools, they’re hard to flag, putting businesses at serious financial and compliance risk.
2. Document Alteration
Instead of making a new document, fraudsters manipulate real ones: changing names, dates, balances, or photos using tools like Photoshop, Word, or Acrobat.
Example: A freelancer edits a genuine invoice, doubling the amount billed, and submits it for reimbursement.
Why it matters: Altered documents are harder to detect because most of their structure is real. Without copy-move detection or metadata analysis, these changes often go unnoticed.
3. Identity-Based Fraud (Theft & Synthetic)
This form combines identity theft and synthetic identity fraud. It involves using either stolen personal data or creating entirely new identities using real and fake details.
- Identity Theft uses authentic documents (e.g., ID cards, bank statements) stolen from real individuals.
- Synthetic Identity Fraud combines legitimate data (like a real SSN) with fabricated documents to pass verification systems.
Example: A criminal uses a real SSN with a fake passport and forged bank statement to get through a bank’s KYC process.
Why it matters: The inclusion of real data makes it difficult to detect. Legacy systems often approve these submissions unless advanced AI or behavioral analytics are applied.
4. Template Fraud
Fraudsters use editable templates downloaded from the internet, often from illegal “document mills”, to mass-produce fraudulent documents. These templates mimic real documents but allow users to quickly swap in fake names, numbers, or company branding.
Example: A fraud ring submits dozens of onboarding applications using the same pay stub template, only changing the name and salary each time.
Why it matters: These documents can look nearly identical to authentic ones. Without robust template matching or comparison tools, your system may not flag them, even when submitted in bulk.
5. Pre-Digital Document Modification
This technique involves editing a document in the physical world, by hand, and then scanning or photographing it to mask signs of tampering. The result is a digital file that appears legitimate but conceals offline manipulation.
Example: A tenant prints a real utility bill, manually changes the due date and balance, then scans and uploads it to support a rental application.
Why it matters: Since the document started as legitimate, it retains most authentic visual elements. Basic PDF scanning tools often fail to catch physical edits disguised in re-digitized formats.
6. Serial Fraud
This advanced method uses automation or scaled human efforts to exploit a known weakness repeatedly. Once a fake document passes verification one time, fraudsters replicate the format across hundreds of submissions.
Example: A fraudster discovers a specific bank statement format that bypasses your checks, then launches 100+ identical loan applications using the same structure and slight field variations.
Why it matters: Serial fraud can overwhelm your system quickly, leading to large-scale losses. Detecting it requires ongoing monitoring, clustering techniques, and document fingerprinting.
Now that we’ve covered how document fraud is committed, let’s look at the documents most commonly targeted. From IDs to bank statements, certain document types are frequent targets because of the trust and access they provide.
Common Types of Fraudulent Documents
Fraudsters tend to target high-value documents – the kinds that unlock financial services, access to property, or identity verification. Understanding which document types are most frequently forged or altered can help you prioritize detection efforts.
Here are the most commonly falsified document types:
Identity Documents (IDs, Passports, Driver’s Licenses)
Why they’re targeted: Used as primary proof of identity in KYC, onboarding, and age verification processes.
Fraud methods: Forgery, photo substitution, MRZ tampering, or altered personal data.
- Learn more about how to easily spot fake IDs.
Bank Statements
Why they’re targeted: Commonly used for verifying income, account ownership, or proof of address.
Fraud methods: Altered balances, fake institutions, fabricated transactions.
- Find out how to detect fake bank statements before they cause damage.
Pay Stubs / Payslips
Why they’re targeted: Employed to prove employment status and income in rental, loan, and credit applications.
Fraud methods: Edited salary amounts, fake company names, copied formats.
- Learn how to identify fake pay stubs without slowing down onboarding.
Invoices
Why they’re targeted: Central to B2B transactions, reimbursements, and financial audits.
Fraud methods: Duplicate invoice submission, amount inflation, fake vendor info.
- See how to catch fraudulent invoices before they’re paid.
Receipts
Why they’re targeted: Often used for cashback, loyalty points, or employee reimbursement claims.
Fraud methods: Fake receipt generation, logo manipulation, date or item changes.
- Get tips on how to spot fake receipts in seconds.
Of course, there are many more document types that fraudsters target beyond the most common ones. From utility bills and tax documents like W-2 forms to academic certificates and diplomas, nearly any document that carries trust or financial value can be forged or manipulated.
But knowing which documents are faked is only half the story. To fully understand the threat, you also need to look at where and why these frauds happen. Different industries and use cases, from banking to real estate, face unique risks that make them prime targets for document fraud.
Industries & Use Cases Most Affected by Document Fraud
Document fraud doesn’t happen in a vacuum. Fraudsters focus their efforts on industries and processes where forged paperwork gives them the biggest payoff. Knowing where these risks appear helps you strengthen defenses where they matter most.
Here are the industries and use cases most affected:
Banking & Financial Services
Banks and financial institutions are prime targets because of their reliance on documents for KYC, credit checks, and loan approvals. Fraudsters often submit forged IDs, bank statements, or payslips to bypass onboarding, exposing institutions to heavy financial and compliance risks.
Lending & Mortgages
The lending industry is especially vulnerable to mortgage fraud, where falsified documents like tax returns, pay stubs, or inflated property appraisals are used to secure loans. Fraudsters often submit fake W-2 forms or altered bank statements to appear more creditworthy than they are, creating major risks for lenders and triggering regulatory concerns.
Insurance
Insurance fraud often involves falsified claims, where medical reports, receipts, or damage assessments are manipulated to exaggerate payouts. These schemes not only cost insurers millions but also drive up premiums for legitimate policyholders.
Real Estate & Rental Applications
Landlords and property managers depend on documents like payslips and utility bills to verify affordability and identity. Fraudsters exploit this by editing or fabricating documents to secure housing, which increases the risk of defaults and costly evictions.
Employment & HR
Employers face fraud when candidates present fake diplomas, certificates, or references to secure jobs they aren’t qualified for. This kind of deception can lead to compliance issues, reputational harm, and workplace risks.
Healthcare
In healthcare, forged prescriptions, falsified medical records, and fake insurance documents are common. These not only result in financial losses but also endanger patient safety and put providers at risk of regulatory penalties.
Loyalty Programs & Retail
Retailers and brands often face loyalty fraud, where fraudsters exploit cashback or rewards programs using fake coupons or falsified receipts. While each case might seem minor, these schemes can be scaled to thousands of fraudulent redemptions, leading to significant financial losses and eroding customer trust in promotional campaigns.
As you can see, there are so many possibilities for fraud to take place across a range of industries. Let’s see how you can safeguard yourself from it!
7 Red Flags to Detect Document Fraud
Even the most convincing fake documents leave subtle clues. By knowing what to look for, your team can catch suspicious submissions before they cause damage. Here are some of the most common warning signs:
1. Inconsistent Data
Mismatched names, addresses, or dates across different parts of a document — or between multiple documents — are strong signs of tampering.
2. Formatting or Layout Errors
Fraudsters often miss small details like fonts, line spacing, or logos. If a document doesn’t match the format of authentic examples, it deserves closer inspection.
3. Missing Security Features
Official documents often include watermarks, holograms, or barcodes. If these are missing or poorly replicated, the document is likely fake.
4. Image Quality Issues
Blurry scans, pixelation, or compressed files can signal that a document was edited and re-scanned to hide traces of manipulation.
5. Metadata Discrepancies
The document’s digital fingerprints — like creation date, editing software, or version history — often reveal hidden tampering.
6. Numbers That Don’t Add Up
On bank statements, invoices, or receipts, inconsistent math or balances is a classic red flag. Fraudsters often change figures without adjusting the totals.
7. Suspicious Submission Behavior
Patterns like repeated resubmissions, documents provided at the last minute, or uploads from unusual IP addresses may indicate fraudulent intent.
Document Fraud Detection Techniques
Once you know the red flags to look out for, the next step is choosing the right techniques to uncover fraudulent documents. Broadly, these methods fall into three categories: manual, semi-automated, and AI-driven. Each has its strengths and limitations.
1. Manual Document Review
Traditionally, fraud detection has relied on human reviewers manually inspecting documents. They look for spelling errors, mismatched fonts, inconsistent numbers, or missing security features. While this can catch obvious mistakes, it is slow, costly, and highly prone to human error — especially at scale.
2. Metadata & Forensic Analysis
Documents carry hidden digital fingerprints such as creation date, editing software, or device details. Metadata analysis and forensic tools can uncover tampering that isn’t visible to the naked eye. These methods are more advanced than manual checks, but still require trained analysts and can’t handle large volumes efficiently.
3. Template & Format Matching
Fraudsters often reuse the same templates for fake IDs, invoices, or payslips. Template-matching techniques compare a submitted document against known authentic versions to detect formatting anomalies, missing features, or mismatched logos. This approach is useful but struggles when fraudsters introduce new or evolving templates.
4. Rule-Based & Database Checks
Some organizations use rules-based systems to flag inconsistencies (e.g., invoice totals not matching line items) or cross-check details against trusted databases. This works for predictable fraud patterns but lacks flexibility against novel or sophisticated attacks.
5. AI-Powered Detection
Artificial Intelligence and Machine Learning have transformed document fraud detection. By analyzing pixel-level details, metadata, and behavioral patterns, AI systems detect anomalies that humans miss. Tools like OCR (Optical Character Recognition) convert documents into structured data, making it easier to validate fields, cross-reference information, and flag inconsistencies in real time.
While these techniques are effective to a point, not all of them are created equal. Manual checks can spot obvious errors, but collapse under pressure when dealing with high document volumes. On the other hand, automated systems powered by AI and OCR bring speed, accuracy, and scalability that humans simply can’t match.
This raises a critical question: should businesses rely on manual reviews, or shift to automated document fraud detection? Let’s compare the two approaches.
Manual Fraud Detection vs AI Fraud Detection
When it comes to document fraud detection, you have two options: doing it manually or with the help of an automated document fraud detection solution.
In summary, here’s how AI fraud document detection compares to manual document verification.
| Manual Document Verification | AI Document Fraud Detection |
| Slow and error-prone: Employees manually review and compare documents item by item. This process is time-consuming, prone to human error, and not scalable for large volumes or tampered documents. | Fast and accurate: AI fraud document detection software processes high volumes in real-time with superior accuracy, instantly flagging fraudulent documents and reducing error rates. |
| Low efficiency and engagement: Tedious fraud document verification reduces employee motivation and wastes time on repetitive tasks. | Increased productivity: Frees up your team to focus on critical work. Boosts morale and speeds up operations while stopping fake documents from slipping through. |
| High operational costs: Manual processes increase overhead, especially during document overflow periods. | Reduced costs: Automation reduces time spent on reviews and cuts down on labor and compliance costs. |
Manual methods show us the limits of human review, while automation proves its power in handling scale and subtlety. But what does automated detection actually look like in practice? Modern Intelligent Document Processing (IDP) systems combine OCR, AI, and forensic checks to uncover fraud in ways humans never could. Let’s break down the most effective techniques these systems use.
How to Automatically Detect Fraudulent Documents
Modern IDP systems use a layered approach to fraud detection, analyzing everything from duplicate submissions to pixel-level inconsistencies. Below are the most effective techniques these tools use to stop fraudulent documents before they enter your workflow.
1. With Duplicate Detection
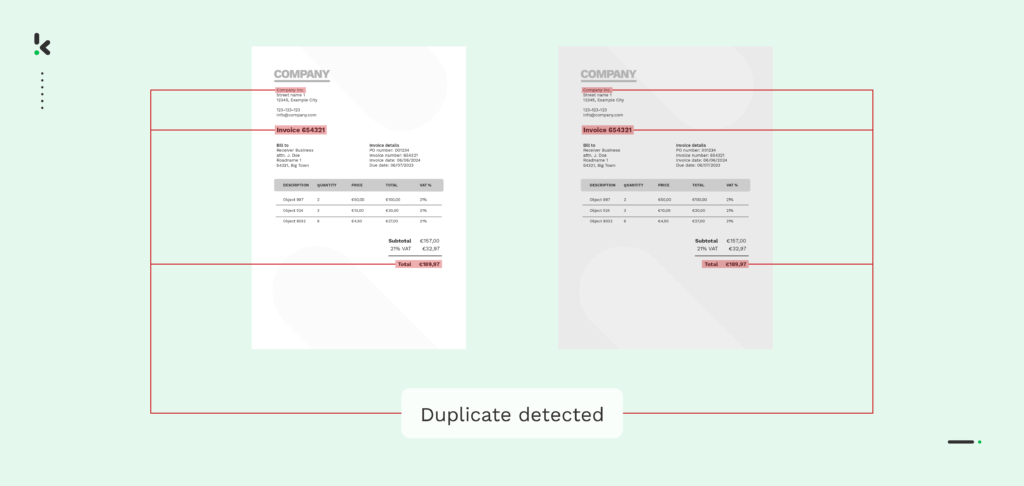
Duplicate detection is an essential step in preventing duplicate payments or double bookings, especially when it comes to reimbursing expenses, tackling spend management tasks, or receipt clearing in loyalty campaigns. With duplicate detection, each document processed is given a distinct digital fingerprint called “hash”, making it easier to detect when a duplicate has been uploaded.
For example, in the case of invoice processing, the software assigns each invoice a unique hash based on its structure, invoice number, merchant name, purchase date, and amount. If an invoice with the same details is uploaded again, it’s flagged as a duplicate, and you’re notified. This can also be applied to receipts, CVs, coupons, and other document types.
2. With Photoshop Detection
Photoshop Detection refers to different technologies that identify whether a submitted document has been digitally altered using software like Adobe Photoshop. It involves analyzing metadata, lighting, shadows, or textures not typically present in unedited photos.
Copy-move detection
Copy-move detection is like a digital detective tool for images. It hunts down areas in pictures that have been copied or changed. Copy-move detection enables IDP to analyze the documents by studying patterns and similarities. It picks up on the signs of image manipulation or fakery, flagging any suspicious sections that appear identical or altered.
Imagine yourself as a bank employee reviewing bank statements for mortgage applications. If someone tried to forge a signature by copying and pasting it onto another document, this technique would spot the duplicated signature, enabling you to decline such fraudulent loan applications instantly.
EXIF analysis
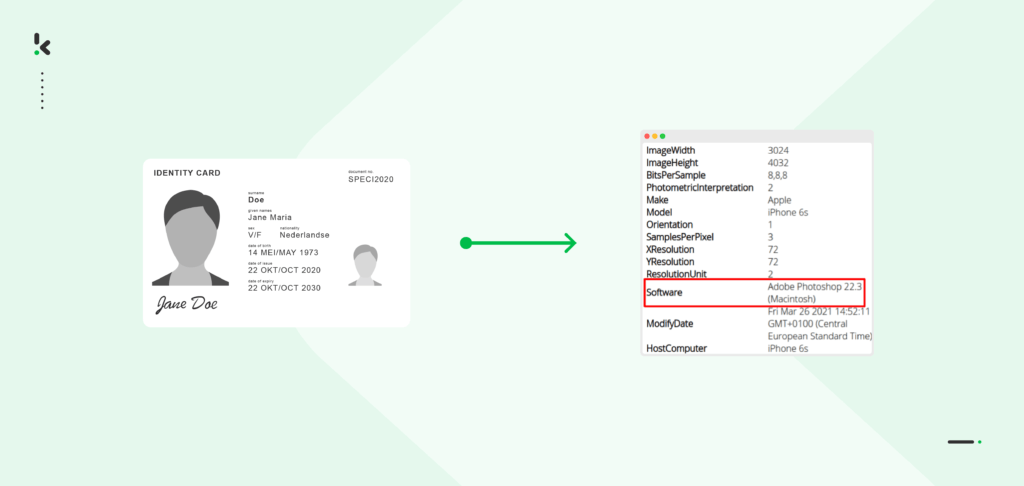
EXIF data analysis examines the metadata within digital images or PDFs to verify document authenticity. Metadata outlines basic information about a file, such as author type, creation date, usage, file size, and more. EXIF data analysis scrutinizes this metadata to analyze the creation/modification timestamps, device information, and GPS coordinates.
For example, you are a back-office employee reviewing receipts submitted for a loyalty campaign. If someone has tried to alter the details on the receipt (eg, total amount, purchase date) with software like Photoshop, EXIF data analysis will indicate the presence of the software, which could indicate tampering and photo editing. It’s a valuable tool in document fraud detection, providing insights into digital document origins and integrity.
Grayscale analysis
Grayscale analysis is a method used to analyze the intensity levels of pixels in grayscale images. This involves examining the distribution of pixel values across the image, typically ranging from black to white.
For example, you are a hiring manager presented with academic credentials for a prospective employee, and you need to verify the qualifications of this applicant through these credentials. Grayscale analysis would help you spot any changes to the pixel intensity. Did the candidate manipulate text, signatures, or logos? Greyscale analysis helps you spot that much more easily and verify the authenticity of the document.
3. With Cross-Validation
Cross-validation techniques are those that involve verifying the authenticity and integrity of a document by comparing multiple document fields or sources of information to corroborate a document’s validity.
MRZ Verification
MRZ (Machine Readable Zone) verification is a method used to ensure the accuracy and integrity of the data encoded in the Machine Readable Zone (MRZ) of identity and travel documents such as passports, visas, and ID cards. This process involves checking the digits, which are calculated and embedded within the MRZ to allow for error detection.
For example, a fraudster might attempt to alter a document without considering the complexities of the MRZ. During identity verification, the software checks the MRZ data by calculating and validating checksums. If the checksums do not match the data on the document, the document is flagged as suspicious.
Data Matching
Data matching refers to the process of comparing data from a document against trusted or already verified data sources to identify inconsistencies, discrepancies, or fraudulent entries. This technique helps validate the authenticity of the document by ensuring that the information it contains aligns with known and accurate data.
For example, when reviewing a new bank account application with a utility bill as proof of address, cross-document validation involves comparing details like name and address with other documents like identity documents, payslips, or employment contracts. Discrepancies, such as different addresses, could indicate potential fraud.
Two/Three-Way Matching

Two and three-way matching in document fraud detection involves cross-referencing information from multiple sources to verify authenticity. For example, with two-way matching, the software can automatically compare invoices with purchase orders to ensure that you’re invoiced only for the items you’ve ordered.
With three-way matching, you add an additional layer of verification by comparing the invoice, purchase order, and proof of delivery. IDP allows you to specify the data fields for comparison, alerting you to matches or discrepancies. It’s crucial for accounts payable, order management, and payment reconciliation, as it helps prevent vendor and invoice fraud.
Legal Implications and Consequences of Document Fraud
Document fraud is treated as a serious offense across jurisdictions, with penalties ranging from heavy fines to lengthy prison sentences. Businesses that fail to detect or prevent it may also face regulatory sanctions, civil liability, and significant reputational damage.
Key regulations around the world
- European Union (EU): Regulation (EU) 2020/493 created the False and Authentic Documents Online (FADO) System, allowing member states to share intelligence on fraudulent documents and strengthen cross-border detection.
- United Kingdom (UK): The Forgery and Counterfeiting Act 1981 defines forgery-related crimes, including creating, possessing, or using false documents with the intent to defraud. Convictions can carry substantial prison terms.
- United States (US): The Forgery Act criminalizes document forgery, while the False Claims Act of 1863 provides enforcement powers against fraud targeting government programs, with added whistleblower protections.
- Canada: The Criminal Code (Sections 366–368) covers forgery and “uttering forged documents,” prosecutable by indictment and punishable with fines and imprisonment.
- Australia: Both the Crimes Act 1914 and the Criminal Code Act 1995 classify document fraud as a criminal offense, with strict penalties for individuals and businesses.
- International Cooperation:
Why it matters
Legal consequences extend beyond individual fraudsters. Organizations that fail to verify documents can face regulatory action, lawsuits, and loss of consumer trust. In high-risk sectors such as banking, insurance, or real estate, inadequate safeguards can result in multi-million-dollar penalties and compliance breaches.
The laws are clear, and the consequences are severe. For organizations, the most effective way to reduce exposure is not to wait until fraud is detected, but to prevent it from entering the system in the first place.
How to Prevent Document Fraud
Prevention requires a layered approach that combines technology, policies, and people. Fraudsters are constantly evolving their tactics, so businesses need to build defenses that are proactive, adaptable, and resilient. The following strategies help organizations minimize their risk:
- Employee Training: Equip your staff with the knowledge to recognize suspicious documents, spot common red flags, and follow proper verification procedures. A well-trained team is the first line of defense.
- Strict Document Intake Policies: Accept only original digital files (e.g., PDFs) when possible, and establish clear guidelines for what types of documents are acceptable for verification.
- Use of Advanced Fraud Detection Technology: Deploy solutions powered by OCR, AI, and machine learning to detect anomalies, verify metadata, and flag forgeries that manual reviews would miss.
- Continuous Monitoring & Cross-Validation: Compare new submissions against historical records and cross-reference document details across multiple trusted sources to detect inconsistencies.
- Regular Audits & Compliance Reviews: Conduct scheduled audits to identify vulnerabilities in your onboarding or verification process, and update workflows to remain compliant with evolving regulations.
- Customer Awareness Campaigns: Educate customers on safe document handling and the risks of document fraud, helping reduce fraud attempts at the source.
Key takeaway: Preventing document fraud is not about relying on a single tool. It’s about combining technology, workflows, and training into a comprehensive strategy that fraudsters find too difficult to bypass.
Ready to put these strategies into action? Doxis AI.dp gives you the tools to detect, prevent, and stay compliant: all in one platform.
Protect Your Business from Document Fraud with Doxis
Doxis AI.dp is an advanced Intelligent Document Processing Platform that leverages technologies like OCR (Optical Character Recognition), AI, and Machine Learning to help you combat document fraud and streamline your document workflows.
- Custom Workflows: Create your unique document workflows by simply connecting any relevant AI.dp modules: data extraction, capture, classification, conversion, anonymization, verification, and more.
- Fraud Detection: Strengthen fraud detection with any of our automated fraud detection modules (we support all of the methods listed above!) for fool-proof & real-time document fraud detection before it causes your business any harm.
- Robust Identity Verification: Enhance security with our comprehensive identity verification module. This includes age verification, selfie verification, liveness detection, and NFC checks to prevent fraud and ensure user identity authenticity.
- Wide Document Support: Process and detect fraud on any document in all Latin alphabet languages, or customize data fields for extraction for any use cases.
- Integration Capabilities: Easily integrate our solutions directly on the platform, which supports over 50 data integration options, including cloud solutions, email parsing, CRM, ERP, and accounting software.
- Security & Compliance: Stay compliant and secure by default with Doxis, an ISO 27001 certified partner.
Are you ready to see how Doxis’ automated document fraud detection solution can help you? Book a free online demo below or contact one of our experts for more information!
Frequently Asked Questions
Document fraud occurs when someone alters, forges, or creates false documents to deceive or gain unauthorized access. It often involves fake IDs, pay stubs, or utility bills used in onboarding or financial applications.
Tampered documents often show signs like inconsistent fonts, altered metadata, image artifacts, or mismatched dates. AI-based tools can detect these changes more reliably than manual checks.
Common fake documents include forged IDs, falsified bank statements, doctored utility bills, and fake diplomas. These are often used to bypass identity checks or inflate financial credibility.
The best document fraud detection software depends on your specific needs, such as industry, volume, and integration requirements. That said, Doxis is a strong option if you’re looking for something reliable, secure, and easy to integrate. It’s fully GDPR-compliant, ISO-certified, and uses AI to spot tampered documents in seconds. If you’re curious how it works, we have a short webinar that walks through our fraud detection solution in detail.
These systems use OCR (Optical Character Recognition), image forensics, and metadata analysis to scan for signs of forgery, such as edits, overlays, or unusual formatting – even in low-quality scans.
AI-based fake document checkers are often more accurate than manual review because they detect subtle inconsistencies, tampering, or metadata changes that the human eye might miss.
Yes, advanced AI tools can detect forged signatures by analyzing stroke patterns and pixel consistency. They can also flag manipulated text or inserted content in scanned documents.
Industries like banking, fintech, real estate, HR, and insurance are heavily targeted, as they rely on document-based verification for compliance, onboarding, and transactions.
Look for formatting errors, blurry logos, mismatched fonts, incorrect account numbers, or metadata showing the use of editing software like Photoshop or Word.
You can use forensic tools to analyze metadata, detect digital signatures, or identify editing patterns. Cross-verification with original sources or databases also helps confirm authenticity.