Sicherlich haben Sie schon einmal von OCR gehört, aber vielleicht ist Ihnen nicht klar, welchen Nutzen es für Ihr Unternehmen bedeuten kann. Einfach ausgedrückt, handelt es sich um Texterkennung. Unternehmen verwenden OCR häufig, um Daten aus Quittungen zu erfassen, Daten aus Dokumenten zu extrahieren und Nummernschilder auszulesen.
Was ist also OCR? OCR ist eine Technologie, die sich ständig weiterentwickelt und verschiedene Branchen verändert, indem manuelle Prozesse durch Automatisierung reduziert werden. Heute gibt es eine Vielzahl von Anbietern, die OCR-Software und sogar noch fortschrittlichere Lösungen wie Intelligent Document Processing (IDP) anbieten.
Aber warum wird diese Technologie von Branchen wie dem Bankwesen, dem Einzelhandel, der Reisebranche, dem Rechtswesen und dem Gesundheitswesen immer mehr eingesetzt?
Hier in diesem Blog finden Sie alles, was Sie über OCR wissen müssen. Wir erläutern, was es ist, wie es funktioniert, welche Anwendungsfälle es gibt, welche Vorteile es bietet und wie Sie damit anfangen können. Also, los geht’s!
Kurzübersicht – OCR-Technologie auf den Punkt gebracht
- Zeitersparnis: OCR automatisiert die Texterfassung aus Dokumenten, wodurch manuelle Dateneingaben um bis zu 90 % reduziert werden.
- Höhere Genauigkeit: Moderne OCR-Systeme in Kombination mit KI erreichen Erkennungsraten von über 98 % – auch bei komplexen Layouts oder Scans in geringer Qualität.
- Vielseitige Einsatzmöglichkeiten: Ob Rechnungen, Quittungen, Ausweise oder Verträge – OCR extrahiert Daten aus nahezu jedem Dokumententyp.
- Mehrsprachige Erkennung: Unterstützt Dutzende Sprachen und Schriftarten, was ideal für international arbeitende Unternehmen ist.
- Nahtlose Integration: OCR-Lösungen lassen sich einfach in bestehende ERP-, Buchhaltungs- und DMS-Systeme einbinden und optimieren bestehende Workflows.
Was ist Optical Character Recognition (OCR)?
Optical Character Recognition (OCR) ist eine Technologie, die Benutzern hilft, Text aus Bildern oder gescannten Dokumenten zu extrahieren und diesen Text in ein Format umzuwandeln, das ein Computer lesen kann.
Dies ist praktisch, wenn Daten für die weitere Verarbeitung benötigt werden, z. B. in der Buchhaltung, bei der Ausgabenverwaltung, bei Marketingkampagnen zur Kundenbindung oder bei der Identitätsprüfung.
Im Wesentlichen können Sie die manuelle Bearbeitung von Dokumenten reduzieren, indem Sie OCR-Software zur Erkennung von Buchstaben, Wörtern, Zeilenpositionen, Sätzen und Mustern einsetzen.
Häufig werden OCR-Lösungen mit künstlicher Intelligenz (KI) und Machine Learning (ML) kombiniert, um bestimmte Prozesse zu automatisieren und die Genauigkeit der Datenextraktion zu erhöhen.
Für die optimale Texterkennung ist es erforderlich, Zeit zu investieren und die OCR-Technologie zu trainieren, indem man sie mit einer großen Anzahl von Daten füttert. Mit der Zeit verbessert sich dann die Genauigkeit und die Dokumentenabdeckung.
Nachdem wir nun erklärt haben, was OCR ist, wollen wir im nächsten Schritt erläutern, wie OCR funktioniert.
Wie funktioniert OCR?
OCR funktioniert wie die menschliche Fähigkeit, einen Text zu lesen und Muster und Zeichen zu erkennen. Normalerweise lesen Menschen einen Text und extrahieren dann die erforderlichen Informationen, indem sie die Daten manuell in ein System, eine Datei oder eine Datenbank eingeben.
OCR macht das ein bisschen anders. Die Technologie verbessert die Qualität eines gescannten Textes oder Bildes und extrahiert in mehreren Schritten die erfassten Daten. Der Unterschied ist, dass die manuelle Arbeit mehr Zeit in Anspruch nimmt und anfälliger für menschliche Fehler ist.
Schauen wir uns die folgenden Schritte des OCR-Prozesses im Detail an:
- Schritt 1: Vorverarbeitung von Bildern
- Schritt 2: Segmentierung
- Schritt 3: Zeichenerkennung
- Schritt 4: Nachbearbeitung des Outputs
Schritt 1: Vorverarbeitung von Bildern
Damit die Datenextraktion genau ist, muss die Qualität des Bildes verbessert werden. Der Prozess der Bildverbesserung wird auch als Bildvorverarbeitungsphase bezeichnet. Je klarer und besser das Bild oder das gescannte Dokument ist, desto genauer ist die Datenausgabe.
In der Vorverarbeitungsphase sucht die OCR-Engine automatisch nach Fehlern und korrigiert die Probleme. Zu den Techniken, die häufig zur Verbesserung der Bilder oder gescannten Dokumente eingesetzt werden, gehören:
- Ausrichten – Der Prozess, bei dem ein Foto oder ein gescanntes Dokument begradigt und der Winkel korrigiert wird.

- Binarisierung – Der Prozess, bei dem ein Bild oder ein gescanntes Dokument in Schwarz-Weiß umgewandelt wird. Die Binarisierung ermöglicht eine genauere Trennung von Text und Hintergrund.

- Zoning – Auch bekannt als Layout-Analyse, um Spalten, Zeilen, Blöcke, Überschriften, Absätze, Tabellen und andere Elemente zu identifizieren.

- Normalisierung – Der Prozess der Rauschreduzierung durch Angleichung der Intensitätswerte der Pixel an die Durchschnittswerte der umliegenden Pixel.
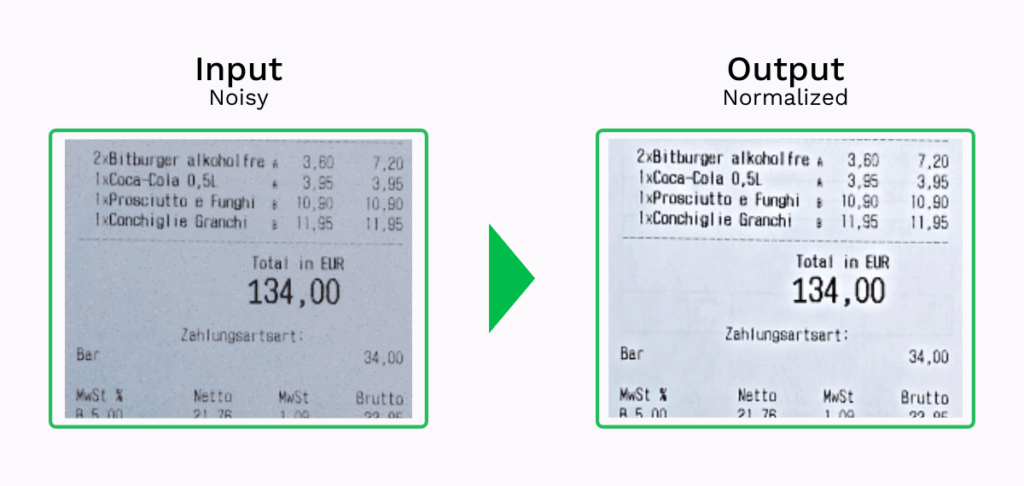
Schritt 2: Segmentierung
Bei der Segmentierung wird eine Textzeile nach der anderen erkannt. Die Segmentierung umfasst die folgenden Schritte:

- Schrifterkennung – Der Prozess der Identifizierung der Schrift auf der Grundlage von Dokumenten, Seiten, Textzeilen, Absätzen, Wörtern und Zeichen.

Schritt 3: Zeichenerkennung
In diesem Schritt wird ein Bild oder ein Dokument in Teile, Abschnitte oder Zonen aufgeteilt. Nach der Trennung werden die darin enthaltenen Zeichen erkannt.
Bei der Zeichenerkennung werden zwei Ansätze angewandt:
- Matrixabgleich – Der Prozess, bei dem jedes Zeichen mit einer Bibliothek von Zeichenmatrizen verglichen wird. Das OCR-Modell führt einen Pixel-für-Pixel-Vergleich durch, um ein Bild eines Zeichens dem entsprechenden Zeichen zuzuordnen.

- Merkmalserkennung – Der Prozess der Erkennung von Textmustern und Merkmalen von Zeichen aus Bildern. Zum Beispiel werden Größe, Höhe, Form, Linien und Struktur eines Zeichens mit denen in der vorhandenen Bibliothek verglichen.
Schritt 4: Nachbearbeitung des Outputs
In diesem Schritt geht es um die Techniken und Algorithmen, die die Genauigkeit der Datenextraktion verbessern, um ein optimales Ergebnis zu erzielen. Zunächst werden die Daten erkannt und dann bei Bedarf korrigiert.
Die extrahierten Daten werden mit einem Vokabular oder einer Zeichenbibliothek verglichen, um Grammatikprüfungen und kontextbezogene Überlegungen durchzuführen und so die Nachbearbeitungsphase abzuschließen.
Obwohl herkömmliche OCR bei der Umwandlung von Bildern in maschinenlesbaren Text und wertvolle Daten außerordentlich vorteilhaft ist, hat sie auch einige Einschränkungen. Die wichtigsten werden wir im Folgenden behandeln.
Einschränkungen der vorlagenbasierten OCR
Herkömmliche OCR war nie als Lösung für eine dynamische Datenextraktion gedacht. Sie wurde ursprünglich für Blinde erfunden, um gedruckte Zeichen in Sprache umzuwandeln. Später wurde die Technologie genutzt, um schwarzen Text auf weißem Hintergrund zu lesen und zu erkennen. Daher bringt OCR einige Herausforderungen mit sich.
Hier sind die fünf wichtigsten Einschränkungen herkömmlicher OCR:
Abhängig von der Qualität des Inputs
Die Qualität der Texterkennung und -extraktion hängt direkt von der Qualität der Bildeingabe ab, mit der das System versorgt wird. Zum Beispiel sinkt die Genauigkeit drastisch, wenn die Zeichenhöhe unter 20 Pixel liegt.
Vorlagen- und regelbasiert
Für die herkömmliche OCR sind Vorlagen und Regeln erforderlich. Strenge Regeln müssen aufgestellt werden, indem die Engine so programmiert wird, dass sie Daten aus den richtigen Feldern und Zeilen erfasst. Daher kann sie die Vielfalt der Dokumente nicht bewältigen und hat mit unstrukturierten Dokumenten zu kämpfen.
Fehlende Automatisierung
Da herkömmliche OCR auf Vorlagen und Regeln angewiesen ist, fehlen ihr viele Automatisierungsmöglichkeiten. Wenn Sie zum Beispiel strukturierte Daten aus Rechnungen extrahieren möchten, würde jedes spezifische Datenfeld eine neue Regel erfordern. Und wie Sie wissen, gibt es Rechnungen in verschiedenen Stilen und Formaten, was zu vielen, vielen Regeln führen würde.
Das Hinzufügen weiterer Regeln würde bedeuten, dass mehr Daten und Ressourcen für das Training der OCR-Engine benötigt werden. Beim konventionellen Ansatz müssen immer mehr Regeln aufgestellt werden, so dass dies zu einem ernsthaften Problem werden kann.
Kostspielig
Da mehr Regeln und Algorithmen entwickelt werden müssen, um Genauigkeit zu erhöhen, kann herkömmliche OCR sehr teuer werden. Hinzu kommt, dass die Erstellung dieser Regeln und Algorithmen nicht immer hochwertige Ausgaben garantiert, da sie auch von der Qualität der Bildeingabe abhängt.
Kommt mit hoher Dokumentenvielfalt schlecht zurecht
Bei herkömmlicher OCR ist die Ausgabe oft sehr genau, wenn es sich um einfache Dokumente mit wenigen Abweichungen handelt. Viele Unternehmen müssen jedoch verschiedene Dokumente in ihren Arbeitsabläufen verarbeiten.
Je größer die Dokumentenvielfalt, desto schwieriger wird es. Da die herkömmliche OCR-Engine mit Vorlagen trainiert wird, kann sie mit einer hohen Dokumentenvielfalt nicht Schritt halten.
Alles in allem können wir also feststellen, dass herkömmliche OCR nicht perfekt ist. Aber lassen Sie sich davon nicht entmutigen. Da der Markt jedes Jahr anspruchsvoller wird, was die Anforderungen und Funktionen angeht, hat OCR mehrere Sprünge nach vorne gemacht, um dieser Nachfrage gerecht zu werden.
Werfen wir einen Blick auf die fortgeschrittene OCR-Technologie.
Die nächste Generation der OCR-Technologie
Die nächste Generation der OCR-Technologie ist bereits da. Sie wird häufig durch Machine Learning und KI unterstützt und ermöglicht Unternehmen das, was sie mit vorlagenbasierter OCR nicht erreichen konnten: Automatisierung. Diese revolutionäre Technologie ist auch als Intelligent Document Processing (IDP) bekannt.
IDP kann Ergebnisse liefern, die menschliche Fähigkeiten übertreffen, wenn Effizienz und Zeit berücksichtigt werden. Sie versteht Daten, kategorisiert, organisiert und konvertiert sie automatisch für den Benutzer, und das alles innerhalb von Sekunden.
Eine der wichtigsten Neuerungen ist, dass die Software nicht an Vorlagen oder Regeln gebunden ist wie ihre konventionellen Vorgänger. Das macht die KI-gestützte OCR-Software skalierbarer und erschwinglicher für Unternehmen.
Werfen wir einen genaueren Blick auf die Rolle des Machine Learning und der KI in modernen OCR-Lösungen.
Der Ansatz des Machine Learning
OCR-Software, die in Machine Learning (ML) eingebettet ist, kann so trainiert werden, dass sie Muster und die Bedeutung von Inhalten anhand einer Reihe von Regeln erkennt. Dies kann durch unüberwachtes Lernen, überwachtes Lernen oder durch eine Kombination dieser beiden Trainingsmethoden geschehen.
Im Folgenden werden wir diese Methoden anhand eines Beispiels erklären (wir werden versuchen, es so einfach wie möglich zu halten).
Überwachtes Lernen
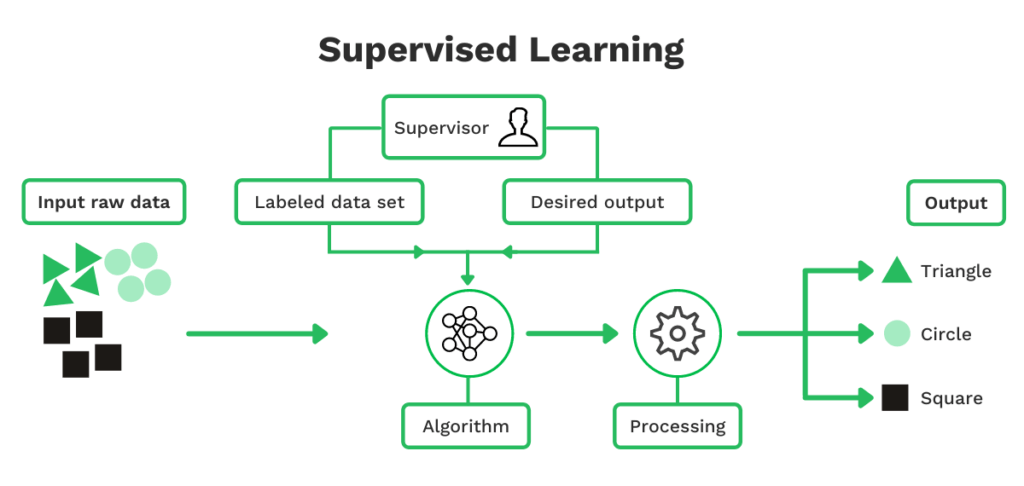
Überwachtes Lernen in ML bezieht sich auf die Verwendung von markierten Datensätzen zum Trainieren von Algorithmen, die Daten klassifizieren und Ergebnisse mit hoher Genauigkeit vorhersagen. Um dies zu erreichen, muss das Modell mit einer großen Menge an Eingabedaten gefüttert werden.
Wenn Sie z. B. vorhersagen möchten, ob eine E-Mail Spam ist, und sie in eine Kategorie einordnen möchten, müssen Sie die Engine mit genügend Spam-E-Mails füttern. Mit genügend Daten kann das Modell die Kategorie erkennen und vorhersagen und somit eine E-Mail richtig klassifizieren.
Ein ähnlicher Ansatz gilt für die Vorhersage der Position des Preises von Einzelposten oder des Händlernamens auf Quittungen.
Unbeaufsichtigtes Lernen
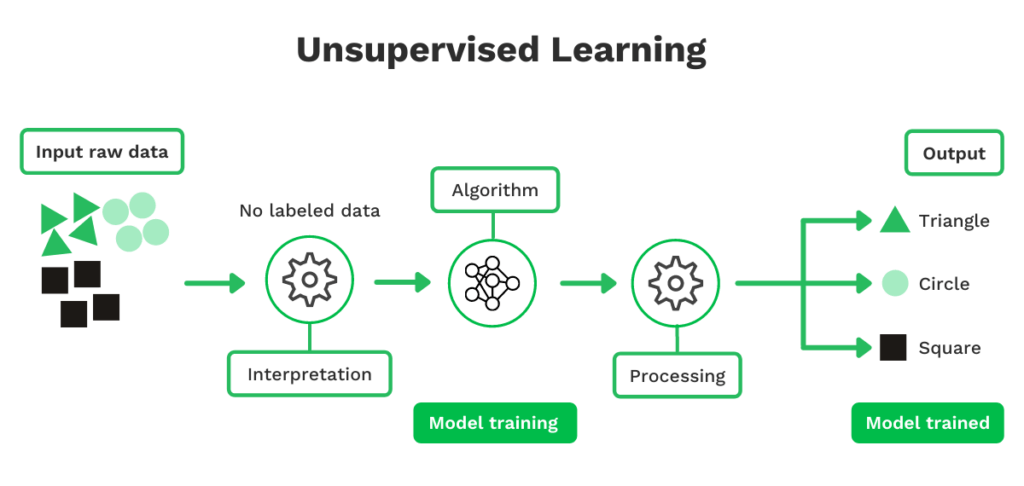
Unbeaufsichtigtes Lernen ist im Grunde genommen ähnlich wie beaufsichtigtes Lernen. Der Unterschied besteht darin, dass beim unbeaufsichtigten Lernen nicht beschriftete Daten verwendet werden, sondern solche, die unbeschriftet sind. Dieser Ansatz ist nützlicher, wenn gemeinsame Eigenschaften innerhalb eines Datensatzes schwer zu identifizieren sind, was dem Modell mehr Freiheit gibt.
Auch wenn die Bezeichnungen für die Datenpunkte nicht definiert sind, bleiben die eigentlichen Datenpunkte erhalten. Daher kann das Modell durch Beobachtung der Eingabedaten Muster erkennen. Vereinfacht gesagt, kann unbeaufsichtigtes Lernen die menschlichen Fähigkeiten zur Anpassung und zum Lernen nachahmen.
Wenn Ihr Unternehmen zum Beispiel Quittungen verarbeiten muss, müssen Sie das Modell für unbeaufsichtigtes Lernen mit vielen Quittungen füttern. Das maschinelle Lernmodell interpretiert dann die Eingabedaten und stellt Ähnlichkeiten fest.
Nehmen wir an, dass es in der Lage ist, den Namen des Händlers und den Gesamtbetrag (d. h. die Datenpunkte) um die genaue Position auf den Quittungen zu definieren. Das Modell nutzt dann diese Informationen, um anhand von Ähnlichkeiten vorherzusagen, ob das nächste Dokument ein Beleg ist oder nicht.
Semi-überwachtes Lernen
Wie der Name schon sagt, sind die Eingabedaten beim semi-überwachten Lernen sowohl beschriftet als auch unbeschriftet. Häufig wird dieses Verfahren verwendet, um Probleme bei der Datenextraktion zu lösen, wenn große Datenmengen verarbeitet werden.
Da semi-überwachtes Lernen das Beste aus beiden Ansätzen kombiniert, hilft es, die Herausforderungen beider Ansätze zu bewältigen: Klassifizierung, Zeit, Kosten und große Datenmengen.
Dies ist ideal für Fälle, in denen eine kleine Anzahl von Trainingsdaten bemerkenswerte Ergebnisse in Bezug auf die Genauigkeit bringen kann (z.B. Klassifizierung von Identitätsdokumenten).
Woher wissen Sie, welchen Ansatz des maschinellen Lernens Sie wählen sollen? Die Antwort ist einfach: Sie müssen es gar nicht wissen. Vor allem, wenn viele Anbieter sofort einsatzbereite OCR-Lösungen anbieten. Nachdem die Rolle des Machine Learning erläutert wurde, befassen wir uns nun mit der Rolle der KI.
KI für Automatisierung
Mit der in die OCR-Software eingebetteten KI kann sich die Lösung ständig anpassen und lernen, Daten genauer zu erkennen. Sie kann ein tiefes Verständnis der Semantik entwickeln und die Palette der unterstützten Sprachen, Formate, Layouts und Dokumenttypen erweitern.
KI ermöglicht es der OCR-Software oder dem OCR-System, alle verfügbaren Daten zu analysieren, Korrelationen zu finden und eine informationsreiche Wissensbasis zu erstellen. Die von der KI erstellte Wissensdatenbank kann im Laufe der Zeit angepasst werden, was die Genauigkeit der Datenextraktion verbessern kann.
Das Beste an der KI ist, dass sie die menschlichen Fähigkeiten nachahmt, um die wichtigsten Erkenntnisse mit hoher Geschwindigkeit und Genauigkeit zu erfassen und zu verstehen.
Was auch immer Ihr Geschäftszweck ist, eine OCR-Lösung mit KI kann Ihnen dabei helfen, die Daten für sich arbeiten zu lassen.
Nachdem wir uns mit ML und KI beschäftigt haben, wollen wir uns nun die Vorteile ansehen, die sich ergeben, wenn beide in die OCR-Lösung eingebettet sind.
Vorteile über die herkömmliche OCR hinaus
Über die herkömmliche Charakter Recognition hinaus können fortschrittliche OCR-Lösungen noch viel mehr leisten. Um Ihnen eine Vorstellung davon zu geben, wie vorteilhaft es ist, diese Technologie in Ihrem Dokumentenverarbeitungs-Workflow einzusetzen, haben wir die folgende Vorteilsliste zusammengestellt:
Digitalisierung von Dokumenten in Sekundenschnelle – Mit OCR-Software kann Ihr Unternehmen papierlos arbeiten und Daten aus Dokumenten in einem digitalisierten Format wie PDF, JSON, CSV, XML usw. extrahieren. Dieser Prozess kann innerhalb weniger Sekunden durchgeführt werden.
Kürzere Implementierungszeit – Fortschrittlichere OCR-Lösungen sind nicht nur auf Regeln und Vorlagen angewiesen. Daher ist der Zeitaufwand für die Schulung der Engine und die Implementierung der Technologie geringer.
Skalierbarkeit – Die nächste Generation von OCR-Cloud-Lösungen bietet Skalierbarkeit, hinter der ihre herkömmlichen Vorgänger deutlich zurückbleiben. Eine Skalierung mit vorlagenbasierter OCR ist zwar möglich, kann aber für Unternehmen schnell zu teuer werden.
Höhere Genauigkeit – Während herkömmliche OCR eine Datenextraktionsgenauigkeit von 60 % bis 85 % aufweist, können viele fortschrittlichere Lösungen mit KI und Machine Learning bis zu 99 % erreichen. Die manuelle Datenextraktion liefert zwar eine Genauigkeit von 90-95 %, ist aber für viele Unternehmen viel langsamer und ineffizienter.
Verringerung der Fehler der manuellen Dateneingabe – Bei langwierigen und sich wiederholenden Aufgaben, wie der manuellen Dateneingabe, kommt es häufig zu Fehlern. OCR kann diese Aufgaben automatisieren und so menschliche Fehler und manuelle Dateneingabefehler reduzieren. Mit KI und Machine Learning kann die Fehlerquote sogar noch weiter reduziert werden.
Schnellere Durchlaufzeiten – Herkömmliche Dokumentenverarbeitungs-Workflows haben oft viele langsame, umständliche Aufgaben, die zu teuren Engpässen führen. Das manuelle Überprüfen und Extrahieren von Daten kann 10-20 Minuten pro Dokument in Anspruch nehmen, während herkömmliche OCR dies in weniger als der Hälfte der Zeit erledigen kann. IDP hingegen kann dies innerhalb von 15 Sekunden erledigen, was 98 % der eingesparten Zeit entspricht.
Kostenreduzierung – Da KI-gestützte OCR schnellere Durchlaufzeiten ermöglicht, mühsame Aufgaben automatisiert und Fehler bei der Dateneingabe minimiert, werden die Gemeinkosten erheblich gesenkt. Dies führt uns zu einem der Hauptvorteile für Unternehmen: Kostenreduzierung. Bei der manuellen Verarbeitung von Dokumenten können die Kosten pro Dokument zwischen 4 und 6 € liegen. Mit herkömmlicher OCR können die Kosten pro Dokument auf 1 bis 2 Euro und mit IDP auf weniger als 0,50 Euro gesenkt werden.
Betrugserkennung – Unternehmen verlieren jedes Jahr enorme Summen durch Dokumentenbetrug. Fortschrittlichere OCR kann dazu beitragen, dieses Problem mit der Betrugserkennung durch Bild- und EXIF-Analyse anzugehen. Dies kann Sie davor bewahren, Kapital durch internen und externen Betrug zu verlieren.
Verbessertes Kundenerlebnis – Es gibt viele Geschäftsfälle, in denen KI-eingebettete OCR zur Verbesserung des Kundenerlebnisses beiträgt. Wenn Banken beispielsweise neue Kunden aufnehmen, macht die Technologie den Onboarding-Prozess durch die mobile Integration reibungsloser und flexibler.
Vergleich zwischen Dokumentenverarbeitungsmethoden
Nun haben wir über die zahlreichen Vorteile der nächsten Generation von OCR-Technologien berichtet. Es gibt jedoch immer noch eine Vielzahl unterschiedlicher Methoden und Lösungen für die Verarbeitung von Dokumenten, und die Suche nach der richtigen Methode kann überwältigend sein. Um Ihnen das Leben zu erleichtern, haben wir eine Vergleichstabelle der verschiedenen Methoden erstellt.
| Manuell | Traditionelle OCR | IDP | |
|---|---|---|---|
| Implementierungszeit | Keine | Langsam | Schnell |
| Durchlaufzeit | 10 bis 20 Minuten | < 5 Minuten | < 15 Sekunden |
| Durchschnittliche Genauigkeit | 60 – 95% | 60 – 85% | Bis zu 99% |
| Kosten pro Dokument | 4 – 6€ | 1 – 2€ | < 0,50€ |
| Technologie | Menschen | OCR | OCR, KI, ML |
| Skalierbarkeit | Keine | Schwierig | Einfach |
Zusammenfassend lässt sich sagen, dass OCR-Technologie Unternehmen viele Vorteile bringen kann. Fortschrittlichere Technologien wie IDP sind jedoch weitaus leistungsfähiger als herkömmliche Lösungen. Natürlich ist keine Lösung perfekt, und deshalb wird die OCR-Technologie ständig verbessert, um bestimmte Einschränkungen zu überwinden.
Nachdem wir nun die wesentlichen Vorteile behandelt haben, ist es an der Zeit, einige der häufigsten Anwendungsfälle zu erläutern.
Wofür wird OCR genutzt?
Standardmäßig kann jede sich wiederholende Aufgabe, die Dokumentenverarbeitung beinhaltet, mit KI-gestützter OCR-Software automatisiert werden. Im Folgenden stellen wir einige Anwendungsfälle vor, um Sie zu inspirieren, eine OCR-Lösung für ähnliche Verfahren in Ihrem Unternehmen einzusetzen:
- Beleg OCR für Treueprogramme
- Datenextraktion aus Personalausweisen für das Kunden-Onboarding
- Automatisierte Rechnungsverarbeitung für die Kreditorenbuchhaltung
- Automatisierung der Vollständigkeitsprüfung von Dokumenten
Beleg OCR für Treueprogramme
Treueprogramme gibt es in vielen Formen und Größen. Bei den meisten handelt es sich um eine Art von punktebasierter Kampagne oder Cashback-Aktion. Die Kunden müssen ihre Quittung an den Einzelhändler schicken und erhalten im Gegenzug eine Prämie für den Kauf des Produkts.
Wie Sie sich vorstellen können, sind solche Programme in der Regel mit viel Back-Office-Arbeit verbunden, da die Kaufbelege (Quittungen, Rechnungen usw.) geprüft, die Kundendatenbank aktualisiert und die Treuepunkte oder Cashback-Punkte ermittelt und gewährt werden müssen.
In einem solchen Fall ist OCR von Belegen über eine Scanlösung optimal, um die mühsamen und fehleranfälligen Back-Office-Aufgaben zu übernehmen.
Unternehmen, die überprüfen müssen, ob Verbraucher die Produkte im Rahmen der Treueaktion tatsächlich gekauft haben, müssen die Quittungen nicht mehr manuell prüfen. OCR kann die Einzelposten von Quittungen scannen und überprüfen, ob die Produkte innerhalb des Kampagnenzeitraums gekauft wurden.
Datenfelder, die extrahiert werden können:
- Sprache der Quittung
- Herkunftsland
- Name des Händlers
- Art der Zahlung
- Mehrwertsteuerbeträge und -prozentsätze
- Währung
- Gesamtbetrag
- Kaufdatum
- Einzelposten
- Und viele weitere
Einige OCR-Anbieter, wie z. B. Doxis, können Unternehmen auch bei der Betrugsprävention helfen, indem sie eine auf Bild-Hashing basierende Duplikaterkennung anbieten. Durch die frühzeitige Erkennung von Betrugsversuchen wird der Verlust von Zeit und Geld minimiert.
Datenextraktion aus Personalausweisen für das Kunden-Onboarding
Unternehmen in der Finanzbranche, wie z. B. Banken, müssen die Identität ihrer Kunden überprüfen, um sicherzustellen, dass diese Kunden auch die sind, die sie vorgeben zu sein, wenn sie in das System aufgenommen werden.
Dieser Prozess wird auch als Know Your Customer (KYC) Prozess bezeichnet. Die Überprüfung der Identität von Kunden und die manuelle Eingabe von Daten in mehrere Systeme zur Kreuzvalidierung kann ineffizient und zeitaufwändig sein.
Aus diesem Grund wird OCR in diesem Prozess eingesetzt: um die Bearbeitungszeit zu verkürzen und die Anzahl der Neukunden zu erhöhen. Mit OCR-Software können Finanzinstitute einfach scannen und innerhalb weniger Sekunden automatisch Daten aus Ausweisen extrahieren.
Datenfelder, die extrahiert werden können:
- Vollständiger Name
- Nationalität
- Geburtsdatum
- Ausgabedatum
- Ort der Ausgabe
- Gültig bis
- Dokumentnummer
- Sozialversicherungsnummer
- Maschinenlesbare Zone (MRZ)
- Und viele weiter
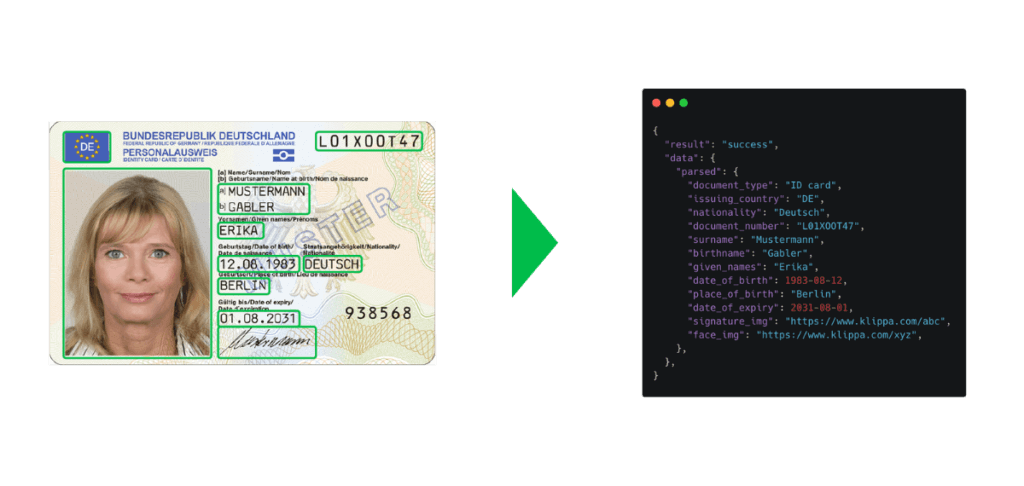
Nachdem die Daten extrahiert wurden, können sie auch mit Betrugsdatenbanken oder schwarzen Listen abgeglichen werden, um Betrugsversuche aufzudecken.
OCR-Technologie ist heutzutage stark in die KYC-Automatisierung integriert, da der Großteil des Kunden-Onboarding digital erfolgt. Das folgende Video veranschaulicht einen solchen Prozess.
Automatisierte Rechnungsverarbeitung für die Kreditorenbuchhaltung
Die Kreditorenbuchhaltung eines Unternehmens genehmigt die Rechnungen, bevor sie bezahlt werden. Dieser Prozess kann sehr mühsam sein. Eingehende Rechnungen müssen organisiert, überprüft, korrigiert, von der richtigen Person genehmigt, bezahlt und schließlich in das Buchhaltungssystem des Unternehmens aufgenommen werden.
Mit der OCR-Technologie können Unternehmen ihre Arbeitsabläufe in der Kreditorenbuchhaltung rationalisieren und automatisieren und manuelle Aufgaben eliminieren, indem sie die Daten von Rechnungen automatisch erfassen. Sie können die Software einfach mit den Rechnungen füttern, und sie erledigt den Rest: von der Digitalisierung bis zum Senden der endgültigen Ausgabe an Ihr Enterprise Resource Planning (ERP) oder Buchhaltungssystem.
Aus einem Bericht von MineralTree geht hervor, dass 64 % der Unternehmen mit automatisierter Kreditorenbuchhaltung mehr Rechnungen bearbeiten als Unternehmen ohne Automatisierung, und 23 % bearbeiten die gleiche Menge an Rechnungen mit weniger Personal.
Wir haben bei unseren internen Untersuchungen ähnliche Zahlen gefunden. Durch die Automatisierung Ihrer Rechnungsverarbeitung für die Kreditorenbuchhaltung verringern Sie den Zeitaufwand um bis zu 70 %, verkürzen die Durchlaufzeit von Tagen auf Minuten, minimieren Fehler und erzielen Kosteneinsparungen von 70+ %.
Automatisierung der Vollständigkeitsprüfung von Dokumenten
In Branchen wie dem Rechtswesen und dem Bankwesen verbringen Mitarbeiter viel Zeit damit, Vollständigkeit von Dokumenten zu prüfen, um sicherzustellen, dass sie die erforderlichen Informationen enthalten. So sollte beispielsweise ein rechtsverbindlicher Vertrag die Unterschriften beider Vertragsparteien enthalten.

Wird die Vollständigkeitsprüfung nicht bestanden, kann dies schwerwiegende Folgen und Geldstrafen nach sich ziehen. Ohne die Unterschriften beider Parteien wird ein Vertrag beispielsweise zu einem nutzlosen Stapel Papier und ist rechtlich nicht durchsetzbar.
An dieser Stelle kommt OCR ins Spiel. Sie übernimmt die Aufgabe, die Vollständigkeit zu prüfen und die Originalität eines Dokuments zu validieren. Sie kann innerhalb von Sekunden erkennen, ob Unterschriften auf einem Dokument gesetzt sind und/oder ob eine entscheidende Information, z. B. eine wichtige Klausel, fehlt.
Um Ihnen einen vollständigen Überblick zu verschaffen, können OCR-Anbieter wie Doxis die folgenden Aufgaben der Vollständigkeitsprüfung automatisieren:
- Überprüfung der Anzahl der Dokumente
- Klassifizierung der Dokumentenart
- Identifizieren Sie die Anzahl der Seiten pro Dokument
- Validierung des Vorliegens bestimmter Felder, Werte, Zeilen oder Komponenten (z. B. Unterschriften, Bilder)
- Abgleich von Daten zwischen Dokumenten mit einer externen oder internen Datenbank
Man kann mit Sicherheit sagen, dass OCR für viele Zwecke und Anwendungsfälle eingesetzt werden kann. Hat dies Sie dazu inspiriert, nach Automatisierungsmöglichkeiten in Ihrem Unternehmen zu suchen? Dann stellt sich nur noch die Frage, wie Sie damit beginnen können. Um Ihnen dabei zu helfen, werden wir im nächsten Abschnitt verschiedene Möglichkeiten zur Integration der OCR-Technologie in Ihren Betrieb vorstellen.
Wie beginnen Sie mit der Integration von OCR?
Bei der Integration von OCR in Ihr Unternehmen sind mehrere Faktoren zu berücksichtigen. Solche Faktoren können der Dokumententyp, das monatliche Dokumentverarbeitungsvolumen, Ressourcen Ihres Unternehmens, Ihr Anwendungsfall usw. sein.
Um Ihnen zu helfen, haben wir die folgenden Optionen aufgelistet:
- Integration mit OCR-API
- Mobile Scanning-Lösung
- End-to-End-Lösung
Integration mit OCR-API
Mit der OCR-API-Integration können Sie Dokumente verarbeiten, indem Sie sie über eine mobile App, E-Mail und Webanwendung versenden. Dies ist oft die beste Wahl, wenn Sie bereits eine bestehende Software oder Anwendung haben, in die Sie die OCR-Technologie integrieren möchten.
Eine API (Application Programming Interface) ermöglicht es Ihrer Software oder Anwendung, mit dem OCR-Anbieter zu kommunizieren und dessen Technologie für Ihre Dokumentenverarbeitung zu nutzen.
Auch wenn es kompliziert klingt, können Sie die Daten aus den Dokumenten innerhalb von Sekunden in einem strukturierten Format zurückerhalten.
Mobile Scanning-Lösung
Mobile Scanning-Lösungen unterstützen, wie der Name schon sagt, die Anwendungsfälle, in denen Unternehmen eine flexible Methode zur Datenerfassung benötigen. So müssen Ihre Mitarbeiter beispielsweise keine Quittungen physisch aufbewahren, da sie stattdessen ein Foto der Quittung machen können.
Es ist nicht mehr nötig, mit Belegen ins Büro zu gehen, um eine Erstattung zu beantragen. Das spart natürlich Zeit und senkt die Gemeinkosten.
Für die Integration der mobilen Scanlösung benötigen Sie ein gut dokumentiertes Software Development Kit (SDK).
SDKs können sich gut anpassen, und mit den hochwertigen Bildvorverarbeitungsfunktionen können Sie Dokumente oder sogar Objekte wie Stromzähler unter schwierigen Bedingungen scannen.
SDK ist die beste Wahl, wenn Sie eine KI-gestützte OCR-Lösung in Ihrer mobilen Anwendung nutzen möchten. Andererseits ist eine API besser geeignet, wenn Sie Dokumente nur über ein Webportal oder eine Anwendung hochladen möchten, anstatt sie mit einem mobilen Gerät zu scannen.
End-to-end Lösung
Mit einer End-to-End-Lösung können Sie relativ mühelos und schnell loslegen. Sie müssen nur einen OCR-Softwareanbieter finden, der Ihnen bei Ihrem Geschäftsvorhaben helfen kann.
So kann eine End-to-End-Lösung wie Doxis AI.dp Unternehmen dabei helfen, die Arbeitsabläufe bei der Dokumentenverarbeitung zu optimieren. Seine innovativen Technologien können die Datenextraktion, Klassifizierung, Konvertierung, Anonymisierung und Überprüfung automatisieren.
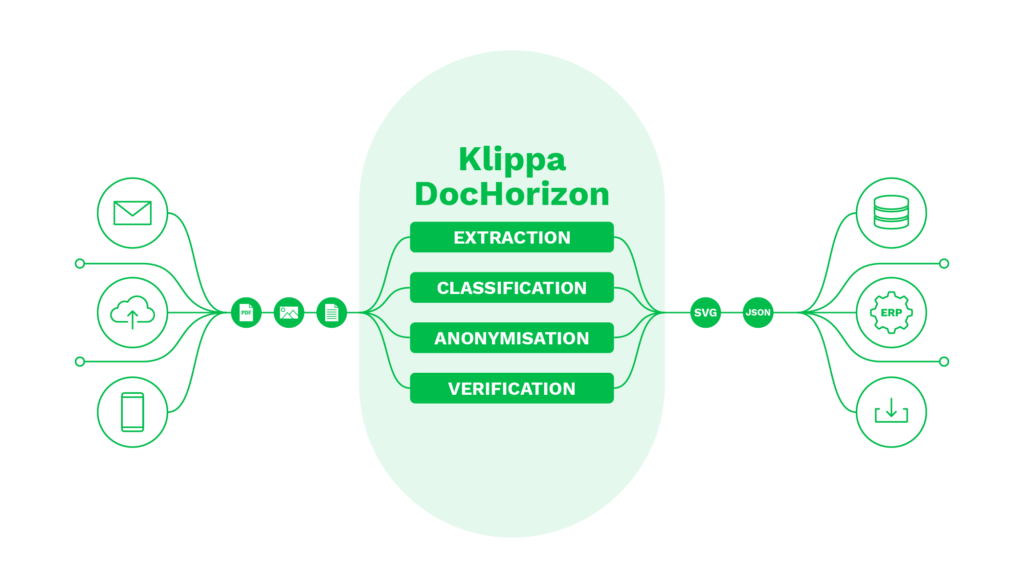
Mehr als nur traditionelle OCR – Intelligente Dokumentenverarbeitung mit Doxis
Die klassische OCR-Technologie reicht heute nicht mehr aus. Unternehmen benötigen intelligentere Lösungen, um Daten effizient zu extrahieren, das Kundenerlebnis zu optimieren und die Prozesseffizienz nachhaltig zu steigern.
Mit Doxis erhalten Sie mehr als nur OCR – unsere KI-gestützten Lösungen bieten:
- API & SDK-Integration für maximale Flexibilität
- End-to-End-Lösungen für eine sofortige Implementierung
- Automatisierte Dokumentenverarbeitung zur Reduzierung manueller Arbeit
Starten Sie mit Doxis und machen Sie Ihr Team zu Champions der digitalen Dokumentenverarbeitung – Fordern Sie jetzt eine Demo an!
FAQ zur OCR-Technologie
OCR (Optical Character Recognition) ist eine Technologie zur automatischen Texterkennung in Bildern oder gescannten Dokumenten. Sie wandelt gedruckten oder handschriftlichen Text in maschinenlesbare Formate um, indem sie Zeichen erkennt und digital verarbeitet.
OCR wird für die Automatisierung von Rechnungen, Belegen, Identitätsdokumenten und Verträgen eingesetzt. Unternehmen nutzen es zur schnellen Erfassung, Verarbeitung und Archivierung von Dokumenten in verschiedenen Branchen.
Traditionelle OCR-Systeme sind oft ungenau bei schlechter Bildqualität, stark layoutabhängig und erfordern manuelle Anpassungen. Sie sind weniger flexibel und schwer skalierbar bei einer großen Vielfalt an Dokumenten.
Moderne OCR nutzt künstliche Intelligenz und maschinelles Lernen, um verschiedene Schriftarten, Layouts und Dokumententypen automatisch zu erkennen. Sie ist flexibler, genauer und benötigt weniger manuelle Eingriffe.
OCR reduziert manuelle Dateneingaben, beschleunigt die Dokumentenverarbeitung und minimiert Fehler. Unternehmen profitieren von effizienteren Abläufen, Kosteneinsparungen und einer besseren Datenverfügbarkeit.
Die Integration kann über eine OCR-API für bestehende Systeme, mobile Scanning-Apps oder eine End-to-End-Lösung erfolgen. Unternehmen können so schnell und effizient Dokumente digitalisieren und verarbeiten.