Die automatische Extraktion von Dokumentendaten kann Ihr Unternehmen verändern. Der Einstieg ist recht einfach, aber es könnte eine Weile dauern, bis erkennbar wird, was die automatische Extraktion für Ihr Unternehmen leisten kann.
Müssen Sie oder Ihre Mitarbeiter Hunderte, Tausende oder sogar Millionen von Dokumenten pro Monat manuell bearbeiten? Würden Sie diesen Prozess am liebsten abschaffen? Da sind Sie nicht allein. Zum Glück gibt es eine Lösung: die automatische Datenextraktion aus Dokumenten. Dadurch wird der gesamte Prozess beschleunigt.
Sind Sie daran interessiert, wie dies funktioniert? Oder wollen Sie sich mit einem allgemein besseren Verständnis der Datenextraktion vertraut machen? Mit diesem Blog erhalten Sie ein besseres Verständnis der Bedeutung, der Techniken, des Prozesses, der Tragweite und erhalten ein Beispiel und Antwort auf die Frage: „Was ist Datenextraktion?“.
Wichtige Erkenntnisse
- Produktivitätssteigerung: Mitarbeiter konzentrieren sich auf wertschöpfende Aufgaben statt auf repetitives Abtippen.
- Kostenreduktion: Weniger Personalressourcen für Dateneingabe für kurzfristige und langfristige Einsparungen.
- Zeitgewinn: Verarbeitung von Tagen oder Wochen auf Sekunden verkürzt; Studien zeigen 40 – 75% Zeitersparnis.
- Skalierbarkeit: Für Hunderttausende oder Millionen von Dokumenten pro Monat ohne Engpässe einsetzbar.
- Schnellere Abwicklung: Ein Dokument kann in <3 Sekunden von unstrukturiert zu JSON/XML/CSV transformiert werden.
- Rechtskonform: Erfüllt alle GoBD-Anforderungen und ist DSGVO-sicher
Datenextraktion: Was bedeutet das?
Was bedeutet es also, Daten aus Dokumenten zu extrahieren? Im Grunde geht es darum, verschiedene Arten von Daten aus einer oder mehreren Informationsquellen abzurufen. Diese Quellen sind in der Regel schlecht organisiert und völlig unstrukturiert.
Die Extraktion der Daten ermöglicht es Ihnen, die Daten an anderer Stelle weiter zu verarbeiten, zu speichern und zu analysieren. Diese Art von Daten wird in der Regel dazu verwendet, die Abläufe im Unternehmen zu verbessern. Sie bilden die Grundlage für eine kritische Analyse im Rahmen des Entscheidungsprozesses.
Es gibt drei Formen der Datenextraktion. Manuell, automatisiert und „Human in the Loop“ (eine Kombination der ersten beiden).
Nachdem die Definition der Datenextraktion nun klar ist, lassen Sie uns mit der Bedeutung des Prozesses fortfahren.
Warum ist die Datenextraktion wichtig?
Stellen Sie sich vor, Sie sind eine Bank, die Hypotheken an Hauskäufer vergibt. Laut Gesetz sind Sie dazu verpflichtet, KYC-Checks durchzuführen, das Einkommen des Käufers zu registrieren und vermutlich noch vieles mehr.
Zu diesem Zweck senden die Kunden Dokumente mit diesen Informationen ein. Diese Informationen müssen in Ihrer Datenbank oder Ihrem Entscheidungsfindungssystem landen.
Leider sind die Daten unstrukturiert, was dazu führt, dass Sie ein Backoffice-Team benötigen, um das Vorliegen von Informationen auf Dokumenten zu überprüfen, wie z. B. das Gehalt auf der Gehaltsabrechnung. Darüber hinaus müssen die Informationen in Ihre digitalen Systeme eingegeben werden.
Dies ist eine kostspielige, aufwändige, langweilige und mühsame Aufgabe, was jedoch nicht unbedingt der Fall sein muss. Tatsächlich nutzen viele Unternehmen die Vorteile automatisierter Extraktionslösungen und -techniken, die KI-gestützt sind, um den Datenextraktionsprozess von Anfang bis Ende zu verwalten.
Vorteile der automatisierten Datenextraktion
Die wichtigsten Vorteile einer automatisierten Extraktionslösung sind:
- Verbesserte Genauigkeit
- Gesteigerte Mitarbeiterproduktivität
- Geringere Kosten
- Zeit sparen
- Skalierbarkeit
- Schnellere Abwicklungszeit
Verbesserte Genauigkeit
Durch die Ersetzung der manuellen durch die automatische Datenextraktion wird die Möglichkeit menschlicher Fehler drastisch verringert. Dies führt zu einer insgesamt verbesserten Genauigkeit.
Wenn die Eingabe großer Datenmengen eine tägliche Aufgabe für die meisten Ihrer Mitarbeiter ist, ist die Wahrscheinlichkeit groß, dass es zu Ungenauigkeiten und Fehlern aufgrund menschlicher Schwächen kommt. Ohne jegliche Überprüfungsschritte hat die Dateneingabe eine Fehlerquote von 4%.
Die Automatisierung des Prozesses der Datenextraktion aus Dokumenten führt zu insgesamt genaueren Daten. Eine höhere Genauigkeit führt nicht nur zu besseren Geschäftsentscheidungen, sondern ist auch für Mitarbeiter von großem Nutzen. Dies führt uns zum nächsten Vorteil.
Gesteigerte Mitarbeiterproduktivität

Wenn die manuelle Datenextraktion entfällt und durch ein automatisiertes System ersetzt wird, können Mitarbeiter mehr Zeit für wichtige Aufgaben verwenden. Einige Aufgaben können nämlich nur von Menschen erledigt werden. Lassen Sie daher Ihre Mitarbeiter diese Aufgaben erledigen und die Aufgaben, die automatisiert werden können, von einer automatisierten Datenextraktionslösung erledigen.
Zufriedenheit wird nicht nur zunehmen, weil Mitarbeiter von langweiligen Aufgaben befreit werden, sondern weil sie sich nun auf sinnvollere Aufgaben konzentrieren können. Dies wiederum führt zu einer höheren Zufriedenheit, die (langfristig) zu einer höheren Produktivität führt.
Geringere Kosten
Durch die Wahl eines Datenextraktionssystems kann Ihr Unternehmen sowohl kurz- als auch langfristig Geld sparen.
Auf kurze Sicht kann Ihr Unternehmen bereits eine Menge Geld sparen, indem es Fehler bei der manuellen Dateneingabe reduziert. Langfristig muss sich Ihr Unternehmen nicht mehr um die Skalierung und Finanzierung eines großen Teams kümmern, das die Datenanforderungen Ihres Unternehmens bewältigt. Automatisierte Systeme zur Dateneingabe und -extraktion sind daher auf dem Vormarsch.
Zeit sparen
Studien zeigen, dass intelligente Automatisierung in der Regel zu Kosteneinsparungen von 40 bis 75 % führt. Zeit ist Geld, und deshalb könnte dies eines der größten Verkaufsargumente für ein Datenextraktionssystem sein.
Skalierbarkeit
Wenn ein Unternehmen wächst, nimmt auch die Menge der eingehenden und ausgehenden Dokumente zu. Wenn die Extraktion von Daten aus Dokumenten immer noch manuell erfolgt, stapelt sich eine Menge an Dokumenten.
Dies kann durch die Umstellung auf ein automatisiertes System vermieden werden. Infolgedessen kann das Unternehmen skalieren, ohne sich Sorgen über große Datenmengen oder einen zu großen Mitarbeiterstab machen zu müssen.
Schnelle Abwicklungszeit
Durch die automatische Datenextraktion kann die Verarbeitungszeit von Tagen oder Wochen auf Sekunden verkürzt werden. Wenn ein Mensch ein Dokument manuell prüfen muss, kann nur ein Dokument pro Vorgang bearbeitet werden. Zudem können Menschen nur 8 Stunden pro Tag arbeiten.
Herausforderungen
Wenn es Vorteile gibt, muss es auch einige Herausforderungen bei der Datenextraktion geben. Zwei Herausforderungen sind:
- Die Sicherheit von sensiblen Daten kann eine große Herausforderung sein. Ein Beispiel für sensible Daten sind Finanzdaten. Daher muss die Sicherheit bei der Datenextraktion gewährleistet sein. Es ist wichtig, nur mit Softwarelösungen zu arbeiten, die nachweisen können, dass ihre Sicherheit regelmäßig getestet wird und dass sie die GDPR und andere Gesetze einhalten können.
- Eine weitere Herausforderung ist die Übereinstimmung der aus verschiedenen Quellen extrahierten Daten, wobei die Herausforderung noch größer ist, wenn diese Quellen sowohl unstrukturiert als auch strukturiert sind, da Sie sicherstellen müssen, dass diese gut zusammenarbeiten. KI-gestützte Systeme können darauf trainiert werden, Daten zu kombinieren und sie nach der Verarbeitung für den Einsatz zu optimieren.
Glücklicherweise verfügen die meisten Datenextraktionslösungen über ein erweitertes technisches Unterstützungsteam, das Sie bei der Bewältigung dieser Herausforderungen unterstützt. Lassen Sie uns nun mit den Datentypen fortfahren, die extrahiert werden können.
Die verschiedenen Arten von Daten
Daten können nach der Struktur der Quelle klassifiziert werden:
- Strukturierte Daten: Die Datenquelle hat bereits eine logische Struktur. Daher ist sie für die Extraktion bereits perfekt geeignet. Sie müssen sie vor dem Datenextraktionsprozess nicht bearbeiten oder manipulieren. Beispiele sind CSV- und XML-Dateien.
- Unstrukturierte Daten: Die meisten Daten liegen in einer unstrukturierten Form vor. Quellen für unstrukturierte Daten können zum Beispiel PDFs, gescannte Texte, Webseiten, E-Mails oder Bilder sein. Unstrukturierte Daten müssen gefiltert werden, um sie sinnvoll zu extrahieren. Beispiele hierfür sind das Entfernen von Leerzeichen, doppelten Ergebnissen und anderen Faktoren, die aus dem Dokument entfernt werden müssen.

Arten der Datenextraktionslösung
Es gibt zwei verschiedene Vorgehensweisen bei der Extraktion von Daten: die logische und die physische Extraktion.
Logische Extraktion
Die logische Extraktion ist die am häufigsten verwendete Technik. Sie kann in zwei Untertypen unterteilt werden:
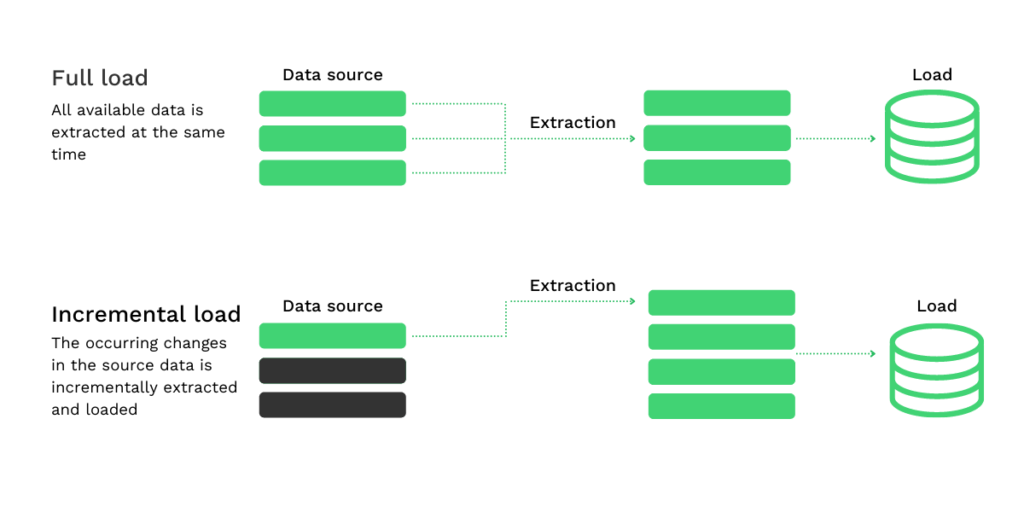
- Vollständige Extraktion: Alle Daten werden gleichzeitig vollständig extrahiert, ohne dass zusätzliche (techno)logische Informationen benötigt werden. Die vollständige Extraktion ist eine Methode, die verwendet wird, wenn die Daten zum ersten Mal extrahiert und geladen werden müssen. Sie spiegelt die Daten wider, die zu diesem Zeitpunkt im Ausgangssystem verfügbar sind.
- Stufenweise Extraktion: Seit der letzten erfolgreichen Datenextraktion (angegeben durch einen entsprechenden Zeitstempel) werden die auftretenden Änderungen in den Ausgangsdaten nachverfolgt. Diese Änderungen werden dann schrittweise extrahiert und geladen.
Physische Extraktion
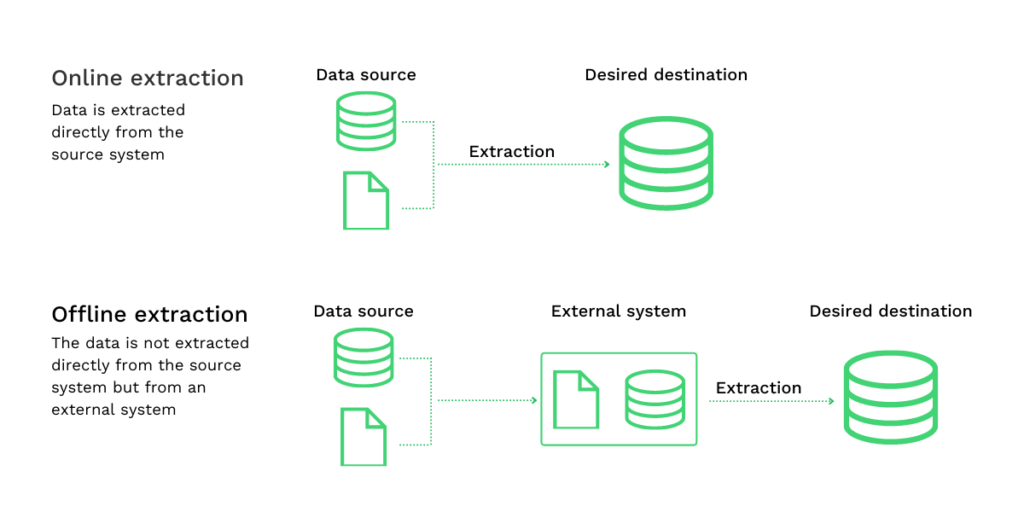
Wenn die Extraktion von Daten aus veralteten oder eingeschränkten Datenspeichersystemen mittels logischer Extraktion schwierig ist, ist die Anwendung physischer Extraktionstechniken die einzige Möglichkeit, diese Daten zu gewinnen. Die physische Extraktion kann in zwei Arten unterteilt werden:
- Online Extraktion: Es besteht eine direkte Verbindung zwischen dem Ursprungssystem und dem Endarchiv. Bei der Methode der Online-Extraktion sind die extrahierten Daten wesentlich strukturierter als die Ursprungsdaten.
- Offline Extraktion: Die eigentliche Datenextraktion findet außerhalb des Ausgangssystems statt. Bei Offline-Extraktionsprozessen werden die Daten entweder selbst strukturiert oder sie werden durch Extraktionsroutinen strukturiert.
Kategorien der Datenextraktionslösungen
Datenextraktionslösungen extrahieren automatisch Daten aus der Datenbank. Die Art des Dienstes und der Zweck sind sehr wichtige Parameter. Um zu verstehen, welche Kategorie von Software für Ihr Unternehmen am besten geeignet ist, müssen Sie die Unterschiede zwischen den drei Kategorien kennen:
- Batch Processing Systeme: Dies kann für Unternehmen interessant sein, die Daten von einem Standort an einen anderen übertragen müssen, wobei jedoch öffter mal Probleme auftreten. Herausforderungen können vor allem die Daten sein, die in veralteter Form gespeichert sind. Die Batchverarbeitung kann auch für Unternehmen hilfreich sein, die Daten vor Ort oder in einer geschlossenen Umgebung übertragen wollen.
- Open-Source-Tools: Sie werden von Unternehmen mit kleinem Budget bevorzugt. Sie können Open-Source-Software erwerben, um bereitgestellte Daten zu replizieren oder Daten zu extrahieren. Open-Source-Tools sind für kleinere Unternehmen meist ausreichend.
- Cloudbasierte Tools: Die meisten der heute verfügbaren Extraktionslösungen sind cloudbasiert. Cloudbasierte Lösungen zeichnen sich durch eine schnelle und zuverlässige Datenextraktion aus. Durch den Einsatz von cloudbasierten Lösungen müssen sich die Unternehmen nicht mehr um die Einhaltung von Vorschriften und Sicherheitsfragen kümmern. Außerdem entfallen die durch die Batchverarbeitung verursachten Zeitverzögerungen.
Heutzutage gibt es viele cloudbasierte Lösungen auf dem Markt. Eine von ihnen ist Doxis AI.dp. Doxis ist auf die Datenextraktion aus unstrukturierten Dokumenten spezialisiert und kann Ihnen helfen, unstrukturierte Dokumente in strukturierte Daten zu verwandeln.
Beispiel der Datenextraktion
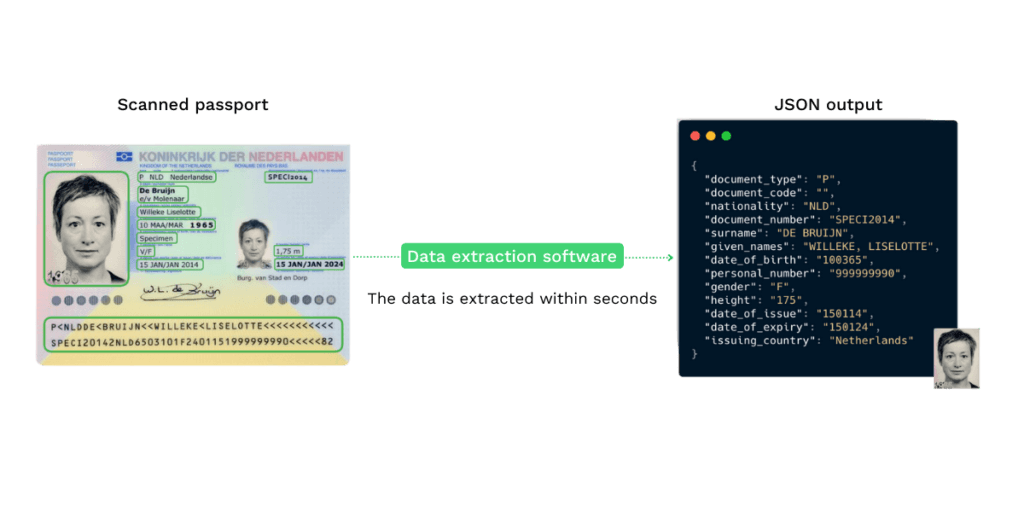
Lassen Sie uns also sehen, was eine Extraktionslösung für Sie tun kann. Wir nehmen einen Reisepass als Beispiel.
Nehmen wir an, Ihr Kunde hat diesen Pass während eines KYC-Prozesses hochgeladen und Sie verwenden eine Datenextraktionssoftware, um die benötigten Informationen zu erhalten. Zum Beispiel den vollständigen Namen, die Dokumentennummer und die MRZ.
Innerhalb von 3 Sekunden ist das System in der Lage, das unstrukturierte Bild in strukturierte Daten umzuwandeln, wie in der rechten Abbildung unten dargestellt.
Die cloudbasierte Extraktionslösung von Doxis
Doxis ist ein Unternehmen für intelligente Dokumentenverarbeitung. Die Software, die wir entwickeln, dient der Automatisierung von Geschäftsprozessen, die Dokumente betreffen. Unsere Lösungen helfen, die Produktivität und Effizienz zu steigern sowie Kosten und menschliche Fehler zu reduzieren.
Doxis bietet eine umfassende, cloudbasierte Lösung für die Extraktion von Dokumentendaten, mit der Unternehmen jede Art von Dokument innerhalb von Sekunden automatisch verarbeiten können.
Wie funktioniert der Extraktionsprozess aus unstrukturierten Dokumenten?
Wie wird eigentlich die Datenextraktion durchgeführt? Der Prozess der Datenextraktion aus einem Dokument lässt sich kurz in ein paar Schritten erklären. Der beschriebene Prozess ist die Vorgehensweise der Extraktion bei Doxis.
1. Hochladen des Dokuments
Zunächst muss das Papierdokument in ein digitales Dokument umgewandelt werden. In der Regel geschieht dies durch Einscannen des Dokuments mit einem Smartphone. Dies kann auch durch Hochladen einer Datei in das System geschehen. Die Eingabe kann in verschiedenen Formaten erfolgen, z. B. JPG, PDF, PNG, TXT und mehr.
2. Bild zu TXT
Jetzt, wo das Hochladen abgeschlossen ist, kann die eigentliche Datenextraktion beginnen. Das einzige Problem ist, dass der Computer noch nicht lesen kann, was auf dem Dokument oder Bild steht. Daher muss es in eine TXT-Datei umgewandelt werden. Zu diesem Zweck kommt die OCR-Technologie (Optical Character Recognition) zum Einsatz. Mit dieser Technologie werden alle Daten aus dem Dokument extrahiert, sie sind jedoch noch nicht strukturiert.
3. Zu JSON parsen
Im letzten Schritt wird ein Parser benötigt, um den Text der Datei zu lesen und zu verstehen. Der Parser wandelt die TXT-Datei in eine strukturierte JSON-Datei um. Nach Abschluss der Konvertierung können die Daten problemlos in der Datenbank verarbeitet werden. Neben JSON sind auch andere Ausgaben wie XML, XLSX und CSV möglich. Unsere OCR-API ist da sehr flexibel.
4. Überprüfung der extrahierten Daten mit Drittquellen
Optional können wir die extrahierten Daten mit Drittquellen abgleichen. Dabei kann es sich um Ihre eigene Datenbank handeln, aber auch um Datenbanken der Handelskammern und Anti-Geldwäsche-Listen. Dadurch wird sichergestellt, dass die Datenqualität gut ist und den Vorschriften entspricht.
Datenextraktion API
Die oben beschriebene Datenextraktionslösung wird von Unternehmen auf der ganzen Welt und in verschiedenen Branchen eingesetzt. Beispiele für Branchen sind Finanzdienstleistungen (z. B. bei KYC-Prozessen), Einzelhandel (z. B. Treuekampagnen), Buchhaltung, Zoll und Gesundheitswesen.
Natürlich könnten Sie versuchen, eine komplette Extraktionspipeline selbst zu erstellen, dies ist jedoch kompliziert und zeitaufwendig. Auch die Wartung ist kostspielig, und oft ist der ROI für den Aufbau einer solchen Pipeline im Vergleich zur Nutzung eines bestehenden Dienstes sehr schlecht.
Daher ist die Implementierung einer Drittanbieter-API für die Datenextraktion aus Dokumenten eine gute Wahl. Durch unsere API kann die Lösung in jede bestehende Software integriert werden. Daher können die Daten direkt in die Software extrahiert werden.
Nehmen Sie Kontakt mit unseren Spezialisten auf
Wenn Sie nach einer Möglichkeit suchen, Ihre Produktivität zu steigern, die Genauigkeit zu verbessern, eine Menge Zeit zu sparen, Skalierbarkeit zu ermöglichen und Kosten zu senken, ist die Extraktionslösung von Doxis die richtige Wahl für Sie.
Möchten Sie mehr über den Extraktionsprozess, die Technik und die Methode erfahren, die wir verwenden? Setzen Sie sich mit einem unserer Experten in Verbindung, oder vereinbaren Sie eine kostenlose Demo über das unten stehende Formular.
FAQ – Häufig gestellte Fragen
1. Was bedeutet Datenextraktion?
Datenextraktion ist der Prozess, Informationen aus strukturierten oder unstrukturierten Quellen wie Dokumenten, Bildern, PDFs oder E‑Mails zu erfassen. Die extrahierten Daten werden anschließend verarbeitet, gespeichert und zur Analyse genutzt.
2. Welche Formen der Datenextraktion gibt es?
Es gibt drei Formen: manuelle Extraktion, automatisierte Extraktion und „Human in the Loop“ – eine Kombination aus automatisierter Technik mit menschlicher Kontrolle.
3. Warum ist Datenextraktion wichtig für Unternehmen?
Sie erleichtert die Verarbeitung großer Dokumentenmengen, verbessert die Genauigkeit, unterstützt fundierte Entscheidungen und erhöht die Produktivität durch Reduzierung manueller Prozesse.
4. Welche Vorteile bietet eine automatisierte Datenextraktion?
Höhere Genauigkeit, gesteigerte Produktivität, geringere Kosten, Zeitersparnis, bessere Skalierbarkeit und kürzere Bearbeitungszeiten.
5. Welche Herausforderungen gibt es bei der Datenextraktion?
Wichtige Herausforderungen sind die Sicherheit sensibler Daten sowie die Übereinstimmung von Daten aus unterschiedlichen Quellen. Hier helfen geprüfte, DSGVO‑konforme Systeme.
6. Welche Arten von Daten können extrahiert werden?
Strukturierte Daten wie CSV‑ und XML‑Dateien sowie unstrukturierte Daten wie PDFs, gescannte Texte, Webseiten, E‑Mails oder Bilder.
7. Welche Techniken werden bei der Datenextraktion eingesetzt?
Zu den Techniken gehören logische Extraktion (vollständig oder stufenweise) und physische Extraktion (online oder offline).
8. Welche Kategorien von Datenextraktionslösungen gibt es?
Batch Processing Systeme, Open‑Source‑Tools und cloudbasierte Lösungen wie Doxis AI.dp.
9. Wie funktioniert die Datenextraktion mit Doxis AI.dp?
Der Prozess umfasst das Hochladen des Dokuments, die OCR‑Umwandlung von Bild zu TXT, das Parsen zu JSON/XML/CSV, optionalen Abgleich mit Drittquellen und die Integration über die Datenextraktions‑API.
10. In welchen Branchen wird Doxis AI.dp eingesetzt?
Typische Einsatzfelder sind Finanzdienstleistungen (KYC), Einzelhandel, Buchhaltung, Zoll und Gesundheitswesen.