An incredible amount of 181 zetabytes (1 zetabyte = 1 trillion terabytes) of data is predicted to be created in 2025, an increase of 23.13% from 2024. Pretty mind-blowing, right?
This data is essential to the growth of organizations, as it makes people’s lives easier, resolves problems in organizations, and drives innovation. However, there are a few problems. Most data is in unstructured formats such as scanned documents or handwritten papers. Extracting and using this data manually is time-consuming, error-prone, and inefficient.
Also, businesses need these raw data files and transform them into other formats to pass them on from one software to another. To do so, they need to find a solution that makes data accessible for all kinds of entities. This is where automated data parsing comes into the picture.
At this point, data parsing might feel like an abstract concept to you. This is why in the next paragraph, we will explain what data parsing is, continue with presenting the different types of data parsing, how data parsing works, and clarify why data parsing is so essential.
Let’s start.
Key Takeaways
- Data parsing transforms raw data into usable formats – It converts unstructured data (e.g., PDFs, scanned documents) into structured, machine-readable formats like JSON or XML.
- AI-powered parsing improves efficiency – Combining rule-based and learning-based approaches enables fast, accurate, and flexible data extraction from any document format.
- With AI-driven data parsing, businesses can save time, improve data accessibility, modernize outdated formats, and ensure seamless data flow between systems.
- Building vs. buying a data parser? Developing an in-house parser offers customization but requires high costs, skilled developers, ongoing maintenance, and infrastructure investment.
What is Data Parsing?
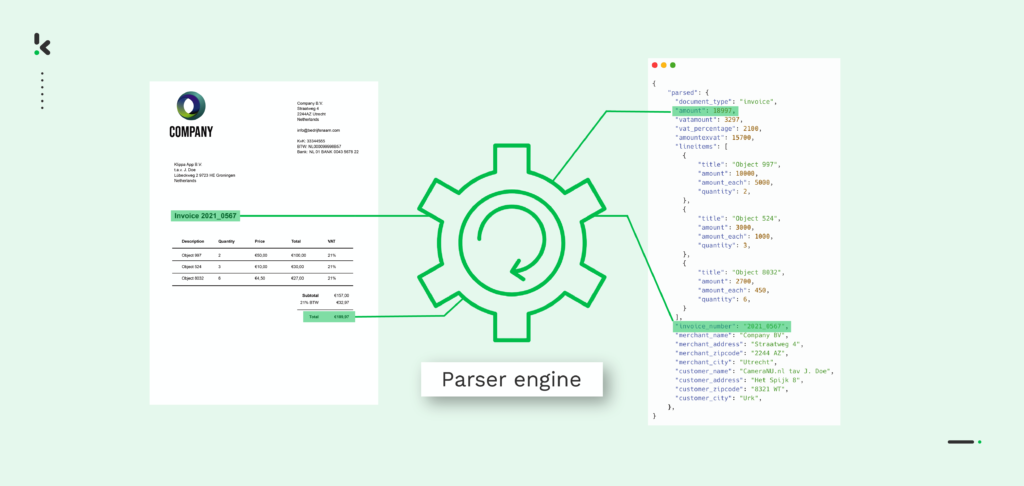
Data parsing is the process of converting data from one format to another. For example, let’s say you have a PDF file, and you need it as a JSON file. In this case, you would need a data parser that can parse raw PDF data into a machine-readable format.

In general, data parsing is applied as the next step after data has been extracted from a document. Most of the time, extracted data is in one format and needs to be converted to a different format so that it can be saved in your database or passed on to third-party software. By doing this fastly and accurately, your business can process data effortlessly while having control over the whole process.
The conversion of one file format to another is possible with the help of a subfield of AI called Natural Language Processing (NLP), in which a string of symbols, special characters, and data structures is analyzed. Based on user-defined rules, information is first structured and then organized, which gives the extracted data meaning.
Important to keep in mind is that, depending on the contextual structures of the extracted data, different data parsing approaches can be applied. Let’s have a look at how these different approaches work.
Various Types of Data Parsing
Generally, data parsing takes two different approaches: Grammar-driven data parsing and Data-driven data parsing.
Grammar-driven data parsing
As the name suggests, grammar-driven data parsing bases the parsing process on a set of formal grammar rules. This works by fragmenting sentences from unstructured data and then transforming them into a structured and easy-to-understand format.
Nonetheless, this approach has one problem: it lacks robustness. To overcome this issue, grammatical restrictions are often eased. That means that sentences that don’t fall within the scope of the usual grammar can be excluded from the data parsing analysis.
As grammar-driven data parsing has its limitations and inconsistencies, an additional way of data parsing was found. This is where data-driven data parsing comes into play.
Data-driven data parsing
In general, data-driven data parsing makes use of smart statistical parsers and modern treebanks to cover as many languages as possible. This allows you to parse conversational languages and sentences that demand high precision, even though they are unlabeled and domain-specific.
Note: A treebank improves NLP models so that AI software is able to comprehend written text. The statistical parser can make use of the NLP model to understand the possible different meanings within a sentence, and return the most likely one.
How AI-Powered Data Parsing Works
In data-driven data parsing, two approaches can be found:
- Rule-based approach: This is Suitable for structured documents like tax invoices or purchase orders. The defined rules help the user to determine which template is used as a reference for the parser to extract data from a document.
- Learning-based approach: This relies heavily on Machine Learning (ML) and Natural Language Processing (NLP). Because the model is trained with a diverse set of unstructured documents, the ability to easily recognize important fields and extract data from them is improved.
In practice, though, a combination of both rule-based and learning-based approaches is used to perform data parsing. This combination allows you to process any document with any kind of layout and doesn’t limit you to one layout only.
Step-by-Step Process of Automated Data Parsing
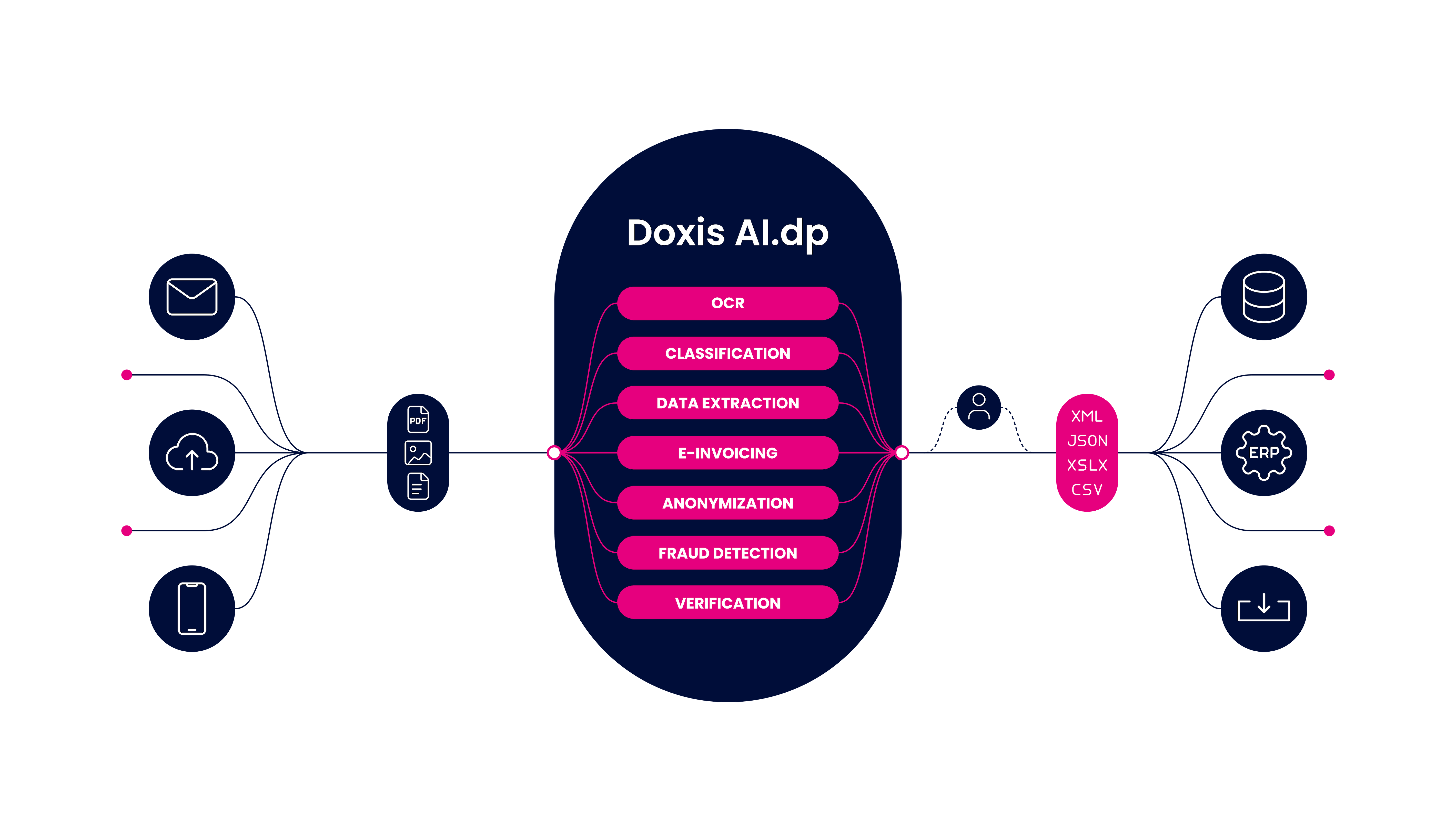
AI-powered data parsing follows a structured process to transform unstructured or semi-structured data into actionable, structured information. Let’s explore a more detailed breakdown of each step:
1. Data Acquisition: Collecting Data from Multiple Sources
The process begins with gathering raw data from various sources, such as scanned documents, emails, web pages, APIs, Databases, spreadsheets, and PDFs.
AI-driven solutions often use Optical Character Recognition (OCR) to extract text from scanned documents and images. For online data, web scraping techniques help retrieve structured information from websites and databases.
2. Preprocessing: Cleaning and Standardizing Data
Before AI can start extracting, the data must be cleaned and structured. Preprocessing ensures consistency and reduces errors because it removes noise and irrelevant data, corrects errors caused by OCR misreads, standardizes formats, and offers tokenization and segmentation for natural language processing (NLP) applications.
This step is crucial for improving the accuracy of the parsing process.
3. Parsing: Extracting Meaningful Data Using AI Models
Once the data is preprocessed, AI models analyze the structure and extract relevant information. This step varies based on the type of data:
- Text Parsing: NLP techniques identify entities (names, addresses, amounts), relationships, and key phrases in text-heavy data.
- Structured Data Parsing: AI extracts information from tables, JSON, XML, or CSV files, ensuring that data fields are mapped correctly.
- Pattern Recognition: Machine learning models detect specific patterns in documents (e.g., invoice numbers, product descriptions).
By leveraging deep learning and rule-based algorithms, AI parsing ensures high accuracy in extracting key data points.
4. Post-Processing: Validating and Refining Extracted Data
Extracted data undergoes further refinement to ensure accuracy and consistency. The data is validated against existing databases, discrepancies in financial transactions are flagged, and anomalies are detected. Additionally, data is enriched by supplementing parsed information with additional contextual data from external sources.
This ensures the final dataset is error-free, structured, and ready for integration.
5. Integration: Storing and Using Structured Data
Finally, the parsed data is formatted and integrated into business systems such as databases, Enterprise Resource Planning (ERP) systems, Customer Relationship Management (CRM) software or accounting and financial tools.
Amazing, right? Now, your business can enjoy seamless data flow across multiple platforms, reduced manual input, and improved operational efficiency.
With this in mind, let’s have a look at why businesses should consider switching to automated data parsing.
Why Businesses Are Switching to AI-Powered Data Parsing
Next to the most significant advantage of automated data parsing, being able to navigate through a tremendous amount of data, more benefits apply:
- Saving time → Automated data parsers help businesses to convert data into another format and automate the process that would otherwise be done manually. The result is that business operations run faster, and human resources can be used for more valuable tasks.
- More accessible data → Automated data parsing makes data more accessible and increases searchability. Business professionals can access all the information necessary from the huge amount of data at hand.
- Modernizing data → It can be the case that stored data is years old and, therefore, not available in modern formats. However, this data might still contain valuable information that is needed for the business. Automated data parsing can quickly change the format of this data and allow businesses to use the information effectively.
With this in mind, let’s have a look at how data parsing is used in different industries.
Use Cases of Automated Data Parsing
Automated data parsing is used in several industries to convert data trapped in unusable formats into business-ready data. For readability purposes, we will focus on four industries only, but keep in mind that this list is far from exhaustive:
- Financial Industry
- Healthcare
- Legal
- Transportation & Logistics
Financial Industry
Banks and other financial institutions are dealing with millions of customer documents, such as ID cards, bank statements, and onboarding applications. All these documents need to be analyzed, and relevant information stored in the bank’s database.
Similarly, any kind of business deals with invoices and receipts that are often manually processed and saved in different formats (PNG, PDF, etc.). This makes it very difficult to search through any data and therefore work with it efficiently.
To improve financial processes, an automated data parser can be used in the following cases:
- Automated data entry
- Customer onboarding
- Document completeness check
- KYC automation
- Automated invoice processing
- Converting PDF to Excel
- Extracting Data from PDF

Don’t worry if your case is not listed here. There are many more use cases for the financial industry.
Healthcare
The healthcare industry is often confronted with a shortage of resources, long working hours, and enormous administrative tasks. This can quickly lead to mistakes in patient records, follow-up treatments, and prescriptions, which translates into severe harm or even death of the patient.
Additionally, patient onboarding is packed with all kinds of documents, which forces healthcare employees to spend a lot of time putting data from forms into computers.
In the healthcare industry, a data parser could be useful in the following cases:

Legal
Lawyers are expensive, which means law firms definitely want them to use their time to solve cases instead of sorting through endless amounts of documents. But because lawyers receive all kinds of documents from clients in various formats, they spend a lot of time sorting through them. This makes them very inefficient and slow.
Additionally, lawyers serve several clients at the same time. Therefore, all documents must be properly organized and classified. Otherwise, it is almost impossible to keep an overview and track of the different cases.
On top of that, most customer documents entail sensitive information that needs to be protected from data breaches and fraud.
In the case of the legal industry, automated data parsing can come in handy in the following ways:
- Data collection & organization
- Document classification
- Automated data extraction
- Anonymization of information

Transportation & Logistics
Any business that sells products or services online needs to deal with a large amount of shipping and billing information. Therefore, shipping labels, packing slips, proof of delivery, etc., need to be managed.

Here, a data parser can be used in cases like:
- Automated data entry
- Compliance checks
- Invoice processing
- Document fraud detection
- Package management
After going through what data parsing is, its types, how automated data parsing is and works, and use cases, you might be wondering how to get access to a data parser. One option could be to build your own parser. But is that really a smart idea?
Should You Build Your Own Parser or Not?
To answer the question, we will walk you through the pros and cons of building your own parser. After this, you should be able to make an informed decision.
Pros of building your own parser
- Gives you more control → You are more in control and can decide how to update or maintain your data parser. On top of that, if you are dealing with very sensitive data, you might prefer not to share your information with third-party data parsers.
- Customizable according to your needs → When building your own parser, it is specifically customized for your company. That way, it helps in-house teams meet your organization’s specific parsing requirements.
Cons of building your own parser
In general, to build your own parser, you will need a team of developers who can understand and write a file parsing application. Finding developers with these necessary skills can be quite a challenge. But this is not the only difficulty. Let’s see what other cons of building your own parser apply:
- Expensive → Building your own parser is expensive, as a lot of time and resources are required. On top of that, you will have to hire and train a whole in-house team to build your custom parser.
- Staff training → You will have to train your entire staff on how to use the data parsing technology.
- Maintenance → A data parser requires regular maintenance, which means you would have to spend more time and money.
- Infrastructure → Building a data parser needs a lot of planning and its own dedicated servers. This means you might need to build or buy a powerful server that is fast enough to parse information.
For most organizations, the cons outweigh the pros simply because it is expensive and extremely difficult to find experienced people to build a parser. If that’s the case, there is no need to despair. We have another option for you. You can empower your organization with a data parser that has been built by thousands of developer hours.
Why Choose Doxis for Data Parsing?
When data accuracy, speed, and automation are critical, choosing the right data parsing solution can make all the difference. Doxis’ AI-powered data parsing stands out by delivering fast and secure data extraction, having a high-accuracy OCR, anonymizing data, integrating seamlessly with other systems, and preventing fraud.
But how does Doxis AI.dp, our AI-based OCR software, perform compared to manual processing? Because we like to let facts speak for themselves, we created the table below.
| Feature | Doxis AI-powered parsing | Manual parsing |
| Speed | Processes thousands of documents in seconds | Slow and time-consuming |
| Accuracy | AI-powered OCR ensures 99%+ accuracy | Prone to human errors |
| Scalability | Easily handles large volumes of data | Limited by workforce capacity |
| Integration | Seamless API & ERP/CRM compatibility | Requires manual data transfer |
| Security & Compliance | GDPR & ISO-certified, encrypted data processing | High risk of human error & data leaks |
| Automation Capabilities | AI-driven, fully automated workflows | Entirely manual |
| Cost Efficiency | Reduces labor costs & operational expenses | High due to labor-intensive work |
The choice is yours! Do you want to transform your data stuck in unusable formats to business-ready data? Then take the next step in automated data parsing – contact our experts for additional information or book a free demo below!
FAQ
AI-powered data parsing automates data extraction from sources like emails, PDFs, and databases. It cleans and standardizes input, then uses NLP and machine learning to identify key entities. Parsed data is validated, structured into formats like JSON or XML, and integrated into business systems, improving efficiency and accuracy.
Manual data parsing is slow, error-prone, and inefficient, leading to inaccuracies, data loss, and inconsistencies. It struggles with large volumes, requires significant human effort, and increases operational costs. Additionally, it poses security risks, as sensitive data is more vulnerable to human error and breaches. Automating parsing mitigates these risks while improving speed and accuracy.
Absolutely! Doxis AI.dp provides 50+ integrations and seamless API and SDK support, making it easy to connect with ERP, CRM, cloud storage, accounting, and workflow automation tools.
Yes, Doxis AI.dp is fully GDPR-compliant and follows strict data security and privacy regulations, including ISO 27001 and SOC 2 standards. Your documents are processed securely, with encryption and access controls in place.