
In today’s fast-paced business landscape, companies of all sizes are grappling with a massive influx of data. This includes a wide range of unstructured data, which refers to data that is not neatly organized in a traditional structured database format. Examples of unstructured data include emails, texts, images, videos, and more.
Recent studies suggest that up to 80% of this new data is unstructured, presenting significant challenges for businesses to effectively capture, quantify, process, and archive it. The ability to extract essential information from this data and turn that into business-ready data will determine whether businesses can gain a competitive advantage. This is where file parsing comes into play. But what is it actually?
In this blog, we will break down what file parsing is, the technologies behind it, how businesses can leverage it, and how Doxis can help you automate file parsing.
Ready? Let’s get started!
Key Takeaways
- File parsing converts unstructured files (PDFs, images, spreadsheets) into machine-readable formats (CSV, JSON, XML).
- Common parsing steps: open, read, split, process, and store data.
- Python is the most versatile language for building custom file parsers, with libraries for CSV, JSON, XML and more.
- AI-powered OCR can parse complex & scanned documents automatically.
- Doxis AI.dp combines OCR, AI, and automation to streamline file parsing workflows for businesses.
What is File Parsing?
File parsing is a technique that businesses use to extract essential information from unstructured data. It involves analyzing the content of files, such as text documents or images, to extract relevant data points and turn that into a usable format.

Often, file parsing is used by businesses in data processing to turn unstructured data, such as PDF files into business-ready formats such as CSV, XML, JSON, XLMS, and more. Efficient and accurate file parsing plays an important role in many industries and domains where data influx is high, and data processing is a critical task.
So how can businesses parse information from files? We will cover that question next.
File Parsing Methods
Let’s assume that your business receives PDF files, and you need to get the meaningful information from them stored in your database or entered into your computer system. Normally, this would be done by back-office employees who would read through the PDF file and manually copy the information into the computer system.
With a file parser, you can parse (read) through the PDF file, extract the necessary information, and export it, for example, as a JSON file in a matter of seconds. This file can then be sent and processed further into your computer system, without the need for human intervention.
These are some common examples of businesses using file parsing to extract data or convert the data from unstructured to a structured format:
- Convert images to text to reduce manual data entry
- Export data from PDF files to JSON, CSV, XML, and many other formats
- Parsing through emails to extract meaningful information
- Key-value pair extraction from documents such as invoices and receipts
- Extracting relevant data from identity documents for customer onboarding
Of course, there are many more examples where file parsing can be utilized to get the information extracted from unstructured documents. Now that you know where file parsing can be used, let’s take a look at its most essential components:
- OCR
- Machine Learning
- Programming Languages
OCR
Optical Character Recognition (OCR) is the most essential technology in file parsing as it enables the extraction of information from scanned images or documents. File parsers utilize OCR technology to convert images into text that can be read by machines. This converted text is then processed, analyzed, and transformed into structured data for further use.
Imagine having to process numerous scanned invoices and manually enter all the relevant information into an ERP or accounting system. This can be time-consuming and prone to errors. With OCR, this manual effort can be eliminated as it can extract text from scanned documents.
However, OCR may extract more information than is needed from a business perspective. This is where file parsers make a difference, as they can read and interpret the data, producing a structured file format that contains only the meaningful output for further use.
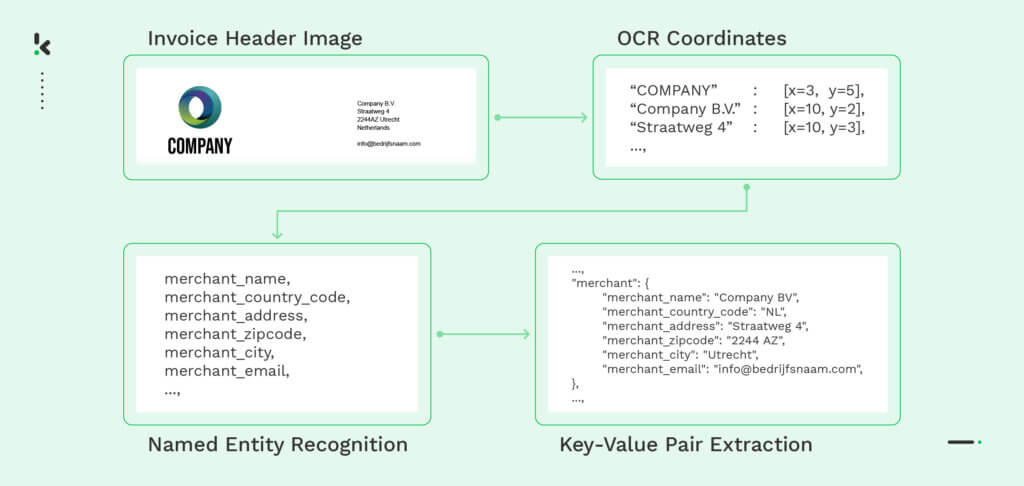
The following example demonstrates how an OCR-based file parser extracts information from an image of an invoice. Initially, the invoice is digitized using OCR, and then the necessary data fields, such as the merchant’s name and address, are identified using Named-Entity-Recognition (NER). Finally, the parser engine extracts the information into key-value pairs that can be converted into a machine-readable format, such as JSON. This process allows for efficient and accurate extraction of data from various file formats.
Machine Learning
Algorithms based on Machine Learning, which is a subset of Artificial Intelligence (AI), are employed to enhance the capabilities of file parsers in various ways. For example, machine learning algorithms can be trained to recognize specific information or patterns from documents for data extraction.
File parsers without machine learning may struggle with accurate data extraction in complex cases. In such cases, algorithms for spell-checking, data validation, or data cleansing can be used to identify and correct errors in parsed data, such as misspellings, missing values, or inconsistent data formats. Incorporating machine learning in parsers enhances accuracy and performance in data extraction and file parsing tasks.
Programming Languages
There are various programming languages that provide built-in or third-party libraries and functions that allow developers to build parsers to extract and transform information stored in files that have specific formats or data structures.
Some popular programming languages for file parsers include:
- Python
- Java
- Javascript
- Golang
- Ruby
Python is a versatile programming language known for its simplicity and readability. It has a rich ecosystem of libraries, such as CSV, JSON, XML, and binary file parsers, that make it easy to parse and manipulate files in different formats.
Java, a popular programming language, is known for its platform independence and robust support for object-oriented programming. It offers a wide range of libraries that provide extensive file parsing capabilities: Apache POI for Microsoft Office files, Jackson for JSON files, and JAXB for XML files. These libraries allow Java to be a versatile choice for file-parsing tasks.
JavaScript is a popular scripting language primarily used for web development. It has built-in JSON parsing capabilities, and also extensive libraries that enable file parsing functionality; PapaParse for CSV parsing and xml2js for XML parsing.
Go, also known as Golang, is a statically typed and compiled programming language developed by Google. Go has standard libraries that provide robust file parsing capabilities; encoding/csv for CSV parsing, encoding/json for JSON parsing, and encoding/xml for XML parsing.
Ruby is a dynamic, object-oriented programming language known for its elegant syntax and ease of use. It has built-in support for parsing text files, and also has libraries; CSV for CSV parsing, Nokogiri for XML and HTML parsing, and JSON for JSON parsing.
These are some illustrations of the numerous programming languages that can be used for creating file parsers. As you may have already realized, the selection of a programming language depends on the specific needs of the file format being parsed, performance considerations, and familiarity with the language.
Nevertheless, the widespread versatility of Python makes it a highly popular programming language in the realm of file parsing. In the following sections, we will delve into how Python is utilized to parse data from files in more detail.
How to Parse Files: Step-by-Step
File parsing is the process of reading a file’s content, breaking it into logical parts, and converting the raw data into usable structured formats. While you can parse files manually or with programming scripts, intelligent document processing platforms like Doxis AI.dp handle diverse formats (PDFs, images, spreadsheets, and more) in a fraction of the time, with higher accuracy and built‑in automation.
Step 1: Identify Your File Format
Different formats require different parsing approaches:
- Structured formats: CSV, JSON, XML – predictable layouts, clear delimiters.
- Semi-structured formats: PDFs, Word docs – text but varied layouts.
- Unstructured formats: Images, scanned docs, log files – require OCR and potentially NLP.
Automation advantage: Doxis AI.dp recognizes and parses all major file formats without manual pre-sorting.
Step 2: Open and Read the File
- Manual / code-based: Use libraries (
open()in Python,fstreamin C++), or import functions in spreadsheet software. Stream large files line‑by‑line to avoid memory overload. - Automation: Doxis ingests files directly from 100+ sources like Google Drive, Dropbox, email, ERP systems. No scripting or pre‑download required.
Step 3: Split / Tokenize the Data
- Manual: Apply delimiter-based splitting (commas, tabs, fixed-width) or regex for unstructured text.
- Automation: AI.dp detects table cells, key-value pairs, and custom data patterns using AI models, even if cell boundaries are inconsistent or text is embedded in images.
Step 4: Process and Convert to Usable Types
- Manual: Convert strings to correct data types (numbers, dates), re-format for downstream applications.
- Automation: SpendControl Applies pre‑processing, validation, and format conversion automatically, outputting JSON, CSV, XML, XLSX, or feeding data directly into ERP/accounting/BI tools.
Step 5: Store & Integrate
- Manual: Save parsed data in arrays, databases, spreadsheets, then manually upload or import into systems.
- Automation: Doxis’ Flow Builder sends parsed data instantly to apps like SAP, QuickBooks, Xero, or custom APIs with no manual handling.
Step 6: Validate and Secure
- Manual: Cross-check entries against source files, correct errors, ensure compliance manually.
- Automation: Doxis runs rule-based and AI-driven validations, fraud checks, and GDPR-compliant anonymisation before data leaves the platform.
Why Automated Parsing Beats Manual/Scripting:
- Processes thousands of files in minutes, not hours.
- Eliminates human error and copy‑paste mistakes.
- Requires no coding skills, yet offers API flexibility for developers.
- Includes extra capabilities like fraud detection and document classification, beyond basic parsing.
File Parsing in Python
As mentioned before, Python is one of the most popular choices as a file-parsing programming language. This is not only due to its versatility but also to the ease of use and the wide availability of libraries and modules. With Python’s robust string manipulation capabilities, it has become a go-to language for parsing various types of files, including text, CSV, XML, JSON, and more.
One of the key advantages of Python for parsing tasks is its extensive ecosystem of libraries. Python offers a rich set of built-in modules for file operations, regular expressions, and string manipulation, which makes parsing tasks straightforward and efficient. Additionally, there are plenty of third-party libraries providing specialized functionalities to parse specific file formats.
Moreover, Python’s easy-to-understand syntax makes it a user-friendly language for file-parsing tasks. With the right infrastructure, you are able to quickly extract, manipulate, and validate data from files with complex structures with Python parsing. Python’s multiprocessing capabilities also enable developers to parallelize parsing tasks, enhancing performance and scalability.
So if you are looking to build your own parser, Python would be our recommended programming language. Building your own Python parser, however, may take up a lot of resources (i.e. time and money) and require extensive programming knowledge, which your organization may not have. This is why we have listed some solutions in the next section that don’t require you to build your own parsers!
Automated Information Parsing from Files
Businesses that look to reduce human effort, time, and expenses can no longer afford to manually extract information from files and enter it into a computer system. With that being said, there are ways for businesses to automate file parsing using various technologies. Here are some options:
- AI-embedded OCR Software
- Web Applications
- Robots and Bots
AI-embedded OCR Software
Optical Character Recognition (OCR) software enables the scanning of documents and the extraction of text into a machine-readable format. However, to automate file parsing, it is often necessary to leverage OCR software that is embedded with AI. With such a solution, businesses can build a streamlined workflow to automatically parse information from files such as invoices, receipts, ID cards, passports, driver’s licenses, forms, and many others.
AI can help in many ways, not only in parsing but also in verifying a document’s authenticity, detecting fraud, or masking sensitive data. This is why it would be more beneficial for businesses to integrate cloud OCR software rather than developing a simple parser in-house with a lot of limitations using Python or any other programming language.
Web Applications
There are various web applications and online tools available for businesses to parse files for free. Some of the tools can automatically parse data from files such as PDFs, CSVs, Excel spreadsheets, and other common file formats. Often, users can upload their files to these web applications, which then use parsing algorithms to extract the relevant data and convert it into a usable format. Check out our free image-to-text converter, for example!
It’s important to be aware of the limitations when using these tools. They can be useful for small file parsing volumes, but there are limitations on the number of files that can be parsed with a free account, and costs can add up rapidly. Data privacy is also a significant concern. Are these free online tools truly prioritizing the security of user data, or are they primarily focused on making money quickly? While it may be prudent to avoid relying solely on these tools, it could still be worth exploring as an option.
Robots and Bots
Robots and Bots, in the context of Robotic Process Automation (RPA), are software programs that can be utilized for automated data parsing from files. Within RPA, robots or bots handle the automation of manual tasks, eliminating the need for human intervention.
One of the key advantages of using RPA robots for data parsing from files is their high level of accuracy and efficiency. RPA robots can work 24/7 without human intervention, reducing the risk of errors caused by manual data entry and increasing productivity. Moreover, they can effortlessly connect with diverse data sources, APIs, and third-party integrations, providing a significant advantage in collecting and processing data for parsing in various ways.
Why Doxis AI.dp is the Best Choice for File Parsing
Doxis AI.dp is a comprehensive AI-powered Intelligent Document Processing platform designed to handle any file type with speed, accuracy, and compliance.
It combines OCR, machine learning, real-time validation, fraud detection, and seamless integrations into one unified workflow engine, delivering accuracy above 99% for parsing structured, semi-structured, and unstructured data.
What sets Doxis apart?
- Accuracy above 99% across languages, layouts, and file types
- Fully automated workflows, from capture to output
- Seamless integrations with ERP, DMS, and accounting tools
- Advanced modules for fraud detection, data masking, and anonymization
- ISO 27001-certified and GDPR-compliant data processing
- Developer-friendly API plus an intuitive no-code interface
- Scalable to millions of files with transparent pricing
Now part of Doxis, recognised as a Leader in the Gartner® Magic Quadrant™ for Document Management, Doxis brings enterprise-grade automation to global teams, whether you’re in finance, healthcare, logistics, or government.
Ready to modernize how you process data? Schedule a free demo or contact our specialists to see how Doxis can help you automate your file parsing workflows!
FAQ
File parsing is the process of analysing a file’s content, breaking it into structured components, and converting it into formats like CSV, XML, or JSON for easier processing. In programming, it often involves tokenising text based on defined rules, converting data types, and storing results in arrays or objects.
In Python, open() is typically used to read the file, followed by libraries such as csv for comma‑separated values, json for JSON structures, or xml.etree.ElementTree for XML. For unstructured text, you might use re for regex matching, or Pandas for complex dataframes.
Doxis AI.dp performs these steps automatically for any file type, requiring no code – perfect for non‑developers, while still offering an API for programmatic access.
For CSVs, choose a parser or spreadsheet import function. In Python, use the csv library to handle headers, delimiters, and data typing. In Excel, use “Text to Columns”.
Doxis AI.dp goes beyond simple CSV parsing, it can extract tabular data from PDFs/images and deliver it as clean, validated CSV without manual splitting.
Parsing PDFs requires handling text layout and, for scanned PDFs, applying OCR. Tools like PyPDF2, Tabula, or PDF converters can extract text and tables.
Doxis AI.dp uses AI-powered OCR to extract data even from complex, mixed-content PDFs, converting results directly to structured formats that match your downstream system’s requirements.
Parsing in programming is the process of interpreting raw input (like text or code) according to a grammar or data format, and breaking it into logical units (tokens) that can be processed. It’s used in compilers, data processing scripts, and document automation.
Doxis AI.dp can parse CSV, JSON, XML, TXT, PDF, DOCX, XLSX, images (JPEG, PNG), and more, plus domain-specific formats like ID documents, invoices, purchase orders, medical forms, and shipping manifests.
Yes, especially with IDP platforms. Doxis AI.dp scales parsing to thousands of files per hour, triggers workflows on file arrival, and integrates results directly into ERP or CRM systems.