Extracting information from documents is a daily task for most organizations. To improve efficiency while performing this task, companies have turned to automation. Data extraction is now done using modern technologies, such as AI, computer vision, or natural language processing (NLP). With the help of automation, businesses reduce their document processing time and increase the accuracy of extracted data.
To improve workflow speed and efficiency, companies often use Named Entity Recognition (NER) to automate information extraction processes. NER is one of the natural language processing techniques and it can be highly beneficial to organizations seeking to maximize their automation capabilities.
In case you are not familiar with the term Named Entity Recognition, or you are not sure how to implement it, don’t worry. In this blog, we will cover what Named Entity Recognition is, and how you can build or train an NER model. Next to that, we will take a look at some of the possibilities of implementing NER using code, namely nltk and spaCy.
Let’s begin.
What is Named Entity Recognition (NER)?
Named Entity Recognition is an NLP-based technique, used to extract, identify and categorize information in text-based documents. It detects entities (i.e. parts of speech) and classifies them in a predetermined category, such as name or country code.
NER categories can be generic, indicating for example words that signify an organization, person or time. However, they can also be customized depending on a specific use case. To give you an example, the NER model can be built to recognize categories such as “patient name”, and “date of birth” on healthcare documents or “merchant name” and “purchase date” on invoices. The possibilities are endless.
To get the best, most accurate results, Named Entity Recognition requires a large understanding of math, machine learning, and image processing. However, the list doesn’t stop here. Named Entity Recognition can be based on multiple methods, so let’s delve deeper into this topic and find out the different approaches to NER.
Methods of Named Entity Recognition
As mentioned before, Named Entity Recognition can be based on multiple methods. The difference between these methods lies in the way the model has been trained to accurately identify and extract data fields.
- Dictionary-based method: In this method, a dictionary containing extensive vocabulary is used to train the NER model. A basic string-matching algorithm is used to check whether an entity present in the given text matches any item in the vocabulary.
- Rule-based method: Following this method, a predetermined set of rules is used for information extraction. These rules can be pattern-based, using the morphological pattern of the words, or context-based, using the context of the given word in the document.
- Machine learning-based method: This approach is statistical-based and involves two steps of doing NER. First and foremost, the files used for training the model go through a data annotation process. Only after this procedure, the NER model can start training on the annotated data. The second step lets the trained model annotate raw documents on its own.
- Deep learning-based method: Lastly, the deep learning-based method is the most accurate method. It is capable of understanding semantic and syntactic relationships between words in a given text but is also capable of analyzing topic-specific words.
Named Entity Recognition seems to be a great asset for extracting information accurately. But how does it actually work? Understanding the process behind this model helps businesses have a better idea of what Named Entity Recognition entails. Let’s find out what is the procedure for building and training the NER model.
How to Build and Train an NER Model
It is time to learn how to build and train an NER model from scratch. One of the most common approaches to building an NER model is using a language model, called Bidirectional Encoder Representations from Transformers, also known as BERT.
A BERT model is a pre-trained language model that can be fine-tuned and updated. This allows the pre-trained model to better understand text patterns and analyze context and meaning. It uses the NER technique at its core but offers the possibility for training and perfecting, which improves its operating accuracy.
Let’s take a look at the five necessary steps to build and train the Named Entity Recognition model, using the BERT language model:
- Data acquisition
- Input preparation for Named Entity Recognition
- Initialize hyperparameters for the NER model
- BERT model training and prediction
- Performance estimation for the Named Entity Recognition model
Data acquisition
The first step in any procedure involving deep learning-based models, such as BERT, is to feed data to the model. This way, the algorithm is able to process the given information and assimilate it. In order to become familiar with entities (i.e. names, locations, organizations, country codes), the model needs to have prior knowledge. Only then, it can recognize and differentiate entities in a context.
While a BERT model is particularly trained on sentences containing the entity of interest, for example, “person”, it can also be trained to recognize words using subwords. Let’s say we have the entity “person”. A subword for this entity would be a person’s name. With enough training, the model can recognize that every word which is the name of a person, corresponds to the entity “person”. This is why it is needed to have a lot of data.
Input Preparation for Named Entity Recognition Model
Before delving into the second step, it is important to remember that the NER model uses a specific tagging scheme, unlike other natural language processing models. The preferred tagging scheme is the IOB format, due to its ease of use. It is commonly used for tagging tokens (i.e. entities, words) in a chunking task for the NER model.
In case you were wondering, chunking is an NLP process used to identify parts of speech within a sentence. Parts of speech refer to what we know as nouns, verbs, adjectives and so on. A chunking task, therefore, is responsible for identifying these entities and labeling them accordingly.
IOB format stands for “Inside, Outside, Beginning” and goes as follows:
- “I” prefix before a tag indicates that the token is inside a chunk.
- “O” prefix indicates that a token doesn’t belong to any chunk.
- “B” prefix before a tag indicates that the respective tag is the beginning of a chunk and immediately follows another chunk without the “O” tag between them. However, if a chunk follows after an “O” prefix, the first token of the chunk takes an “I” prefix, instead of the “B”.

An alternative to the IOB tagging scheme is using existing frameworks, such as TensorFlow. In this case, utilizing pre-processor classes is needed to perform the tagging.
Initialize hyperparameters for NER Model
The third step in the process is to load the BERT language model onto the program and initialize hyperparameters. These hyperparameters represent a benchmark for the BERT model, so the training can be accurately evaluated.
To find the proper parameters, the model needs to be fine-tuned based on its performance on the data it was provided with. The annotated data is loaded onto the program, to act as tensors for training the model on a deep neural network. A deep neural network, or simply DNN, is a subset of machine learning and deep learning, which processes data in complex ways, by employing math modeling.
To improve the accuracy of entity prediction, these hyperparameters play a critical role in the model.
BERT Model Training and Predictions
After setting the hyperparameters, it is time to train the BERT model. There are two phases included in BERT model training. Firstly, setting the training guidelines, followed by the actual model training.
- Setting the training guidelines involves writing a loop based on the number of epochs. An epoch is the number of times the learning algorithm will work through the entire training data set. In this phase, it is also important to check the graphic processing units, or GPUs. These graphic processing units speed up computational processes for deep learning, therefore optimizing the model for faster training.
- The next phase is the actual model training. We now need to activate the parameters that were previously set and initialize the loss function and optimizer function. These functions help improve the performance of the model, increasing the accuracy of the output.
The loss function measures the difference between the predicted output and the actual output, while the optimizer adjusts the model’s parameters to minimize the loss function.
Essentially, the main goal is to train the model in such a way that errors are minimized and the accuracy of prediction rates is increased.
Performance Estimation for Named Entity Recognition Model
Lastly, we need to make an estimation of the model’s performance. This estimation can be done in different ways, but the most common ones are using an F1 score and relaxed match score.
- F1 score: The F1 score is an evaluation metric in ML that combines precision and recall scores. It shows how many times a model made a correct prediction across the entire dataset. This metric is only accurate if each class of the data set has the same number of samples.
- Relaxed match score: With this metric, the performance is calculated based on how many entities the model identified as the correct entity type. Let’s take a look at the following example:
Let’s say there are 3 “person” entities and 2 “location” entities in a given text. If the model identifies 4 “person entities” and 1 “location” entity instead, the performance is 75% out of 100%. The relaxed match score metric still recognizes the model as successful. Why is that? Although the exact identification was not possible, the model still recognized the 3 “person entities” accordingly, which is seen as a positive outcome.
We have just learned how to build and train a Named Entity Recognition model from scratch, using the BERT language model. The real trick lies in implementing the NER model. Let’s discover how to implement this NLP-based model using code.
Implementation of Named Entity Recognition
Using code is the preferred choice when it comes to implementing NER. While there are multiple programming languages used for this action, we will concentrate on two specific ones, namely spaCy and nltk. Both of them are Python-based and allow for advanced NLP tasks to be performed.
Named Entity Recognition Using spaCy
SpaCy is an open-source NLP library for advanced natural language processing tasks in Python. It is used for various tasks and makes use of built-in methods for Named Entity Recognition.
A SpaCy model performs well on all types of text data, but it can be fine-tuned for specific categories. Alternatively, there are several pre-trained models in spaCy that can be used to perform tasks, such as Named Entity Recognition or information extraction on specific data.
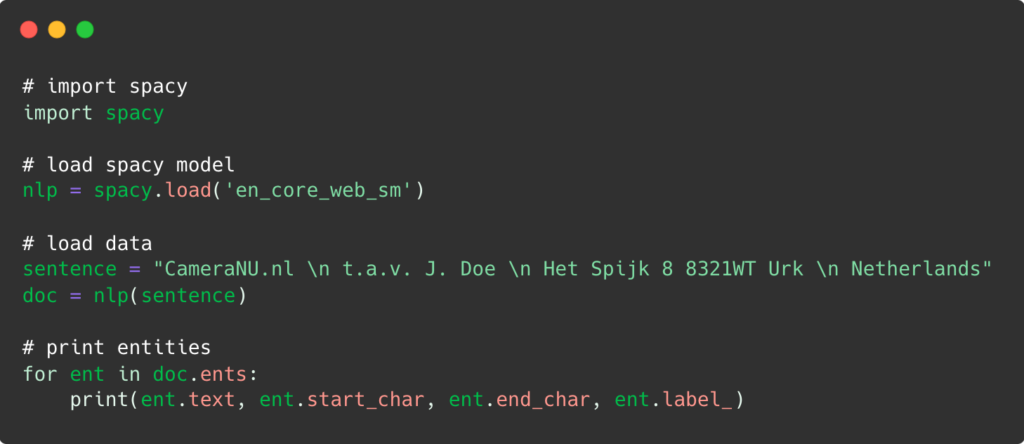
It is good to keep in mind that in order to implement NER with spaCy, it is necessary to have the latest versions of Python 3, Pip and of course, spaCy. Moreover, it is also recommended to download spaCy core pre-trained models to use them in the programs directly. Let’s start!
Firstly, we use a terminal or command prompt and type in the following command:

After which, we add the respective code:
After the Named Entity Recognition processes the given information, meaning it reads the text, identifies the entities, and categorizes them, we are given the final output:

This is as straightforward as it can get. Of course, the accuracy of the extracted and categorized data depends largely on how big the text is, as well. For that case, we can use different models, depending on the text’s size:
- En_core_web_sm – for small-sized texts
- En_core_web_md – for medium-sized texts
- En_core_web_lg – for large-sized texts
We have now seen how Named Entity Recognition can be implemented using spaCy. But what about implementing NER using another Python-based platform? Let’s find out how NER implementation looks like using nltk.
Named Entity Recognition Using nltk
Nltk is also a Python-based library that performs natural language processing tasks. These tasks vary from processing text data, modeling data or tagging parts of speech. In terms of additional configurations, it is simple and can be widely used across operating systems.
To be able to use nltk for implementing NER, it is necessary to install stable Python 3, Pip and nltk packages. Implementing named entity recognition using nltk comes in three steps.
Firstly, import nltk and download the necessary packages:

After we have all the necessary packages laid out, it is time to load the data. In this case, we have chosen a sentence that can be found on an invoice.

Lastly, the platform tokenizes the entities within the given text, finds relevant parts of speech, and delimitates words within the document. As it processes the information, the following output is generated:

We can see that using nltk to implement Named Entity Recognition is also a straightforward process, the same as spaCy. However, knowing how NER works does not add any value to organizations if they do not acknowledge its benefits. In the following section, we have highlighted some of the most important use cases where Named Entity Recognition can be of great help to organizations.
NER Use Cases
For businesses that wish to elevate their operation processes, Named Entity Recognition can be a great asset. It can help organizations perform tasks such as data parsing, therefore enabling accurate data entry automation. These are just some of the examples of how NER benefits organizations:
- Customer support: Businesses are able to improve the customer satisfaction rate and reduce response time using NER. The model differentiates complaints, questions or user requests received through chatbots, by identifying and categorizing the keywords used by customers.
- Content categorization: Content is easily classified into various categories with Named Entity Recognition. The algorithm reads the document and can instantly differentiate a blog from an email or a journal entry. This model is used for archiving digital libraries, offering movie recommendations on streaming services or online retailers.
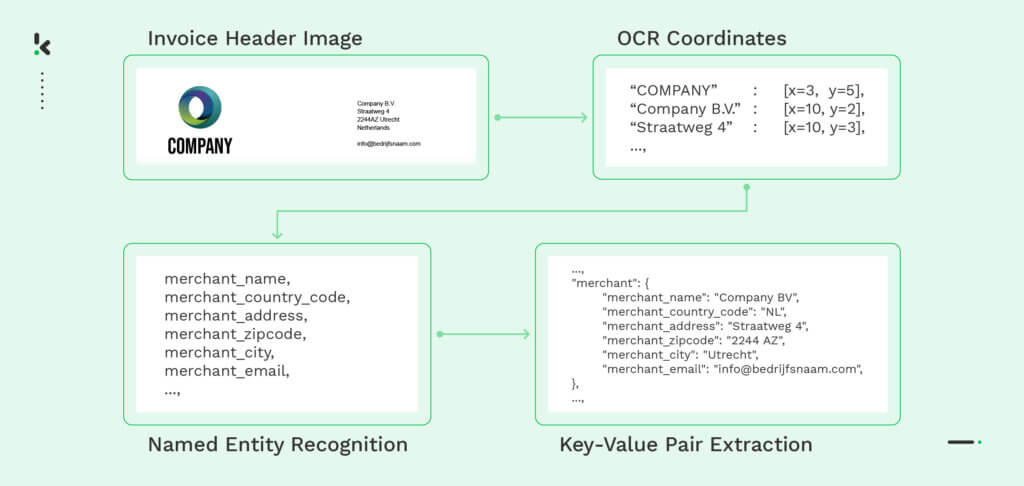
- Document classification: Named Entity Recognition is trained to differentiate multiple types of documents, such as invoices, receipts or passports. By simply identifying specific numbers or single data fields, NER categorizes the documents into different classes.
- File parsing: Instead of manually extracting data from unstructured documents, NER-powered file parsers can read the file and extract the most important information. Moreover, it is able to turn the data into a usable format for further processing.
Limitations When Building a NER Model
Building or training a Named Entity Recognition model from scratch is not impossible, as we have just learned. However, it can be an extensive process that comes with multiple limitations:
- It is expensive: Building a code from scratch can be a costly process, whether it means creating the code in-house or outsourcing it. Nonetheless, financial resources are to be spent on IT experts or outsourced code.
- It is time-consuming: Having to train, let alone build a NER model from the beginning, takes a lot of time. This process can represent a potential drawback for most companies, especially SMEs.
- Can be vulnerable to data leaks: Choosing to build and train a NER model from zero can lead to possible data breaches. If the model is not built accordingly, the algorithm can become vulnerable to scammers and data leaks.
- Lack of training data: Gathering enough training data to feed the NER model is not an easy task. Companies end up having to look for an alternative, which is usually investing large sums of money in creating synthetic data.
Instead of dealing with an extensive and rather complicated procedure of building an NER model from scratch, companies can choose an out-of-the-box solution, namely OCR software.
While there are many examples of well-performing OCR software, only a few are able to fulfill the necessary tasks that can replace Named Entity Recognition technology. Doxis AI.dp for instance, is able to capture, extract, and verify data, eliminating the need to build a brand-new code.
Doxis Alternative to Named Entity Recognition Model
Doxis AI.dp is an Intelligent Document Processing solution that uses AI to automate document-related workflows. With the help of OCR technology, companies can perform mobile document scanning, file parsing, document verification, data masking and many more.
Doxis AI.dp allows organizations to
- Process financial, legal, identity documents and many others
- Perform data extraction with up to 99% accuracy
- Minimize data-entry errors
- Prevent document fraud by verifying document authenticity
- Be compliant with data privacy regulations, as processed data is not stored in Doxis’ servers
Instead of venturing into a costly and time-consuming process, think about the option of choosing an all-in-one intelligent document processing solution.
Book a free demo below or contact us if you need any help in your NER use case!