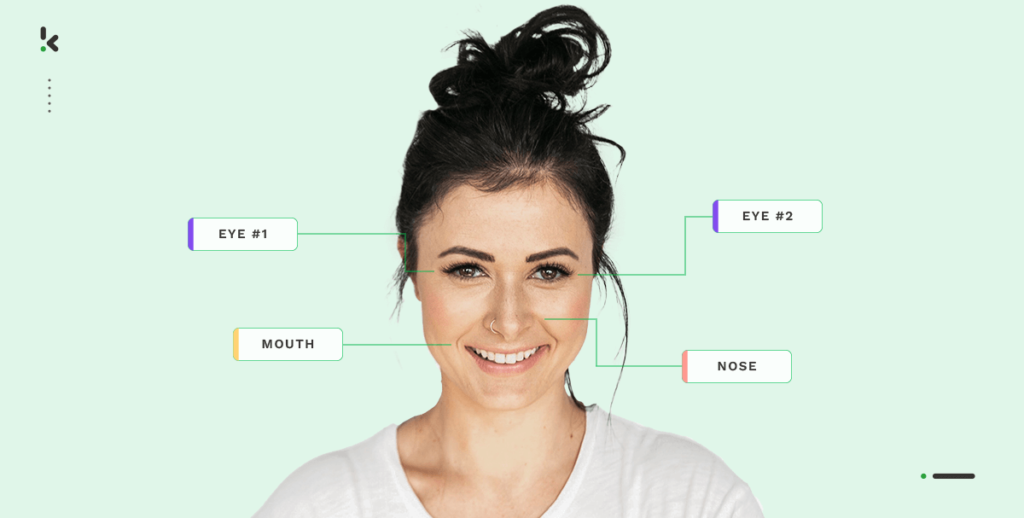
Artificial Intelligence (AI) and Machine Learning (ML) are rapidly growing technologies that enable us to invent incredible things. Think about a self-driving car or the face ID unlock feature of your smartphone. Did you ever think about how that actually works?
For a machine to be able to make the decision to not drive into the next tree, it must be trained to understand specific information. To develop such automated machines and applications, an enormous amount of training data is required. Companies can either buy training data or hire an expert team of so-called data annotators that is able to work with raw data sets.
In general, data annotation is a complex and expensive process that should be conducted by experts in order to achieve a satisfying result.
Many companies dealing with AI struggle with data annotation and don’t know where to start. Therefore, in this blog we will explain what data annotation is, which types of data annotation methods are available and then discuss why data annotation is so necessary these days.
Let’s start.
What is data annotation?
In short: Data annotation is the process of labeling data available in a video, image or text. The data is labeled, so that models can easily comprehend a given data source and recognize certain formats, objects, information, or patterns in the future.
For the model to understand and make sense of the presented images, videos and other formats, it uses computer vision. Computer vision is a subfield of Artificial Intelligence (AI) that allows software and computers to observe and make sense of digital visual input. But how does this relate to data annotation?
In order to teach computer vision to recognize objects, patterns or other information, data needs to be precisely annotated or in more technical terms, it should be equipped with an established machine learning model. This is achieved by using adequate methods and tools, including advanced resources such as a screen recorder with AI Editing, which can assist in capturing and labeling visual data efficiently.
In general, no matter if data annotation is done manually or automatically, the procedure consists of two steps:
- Labeling of data
- Quality checks and audits
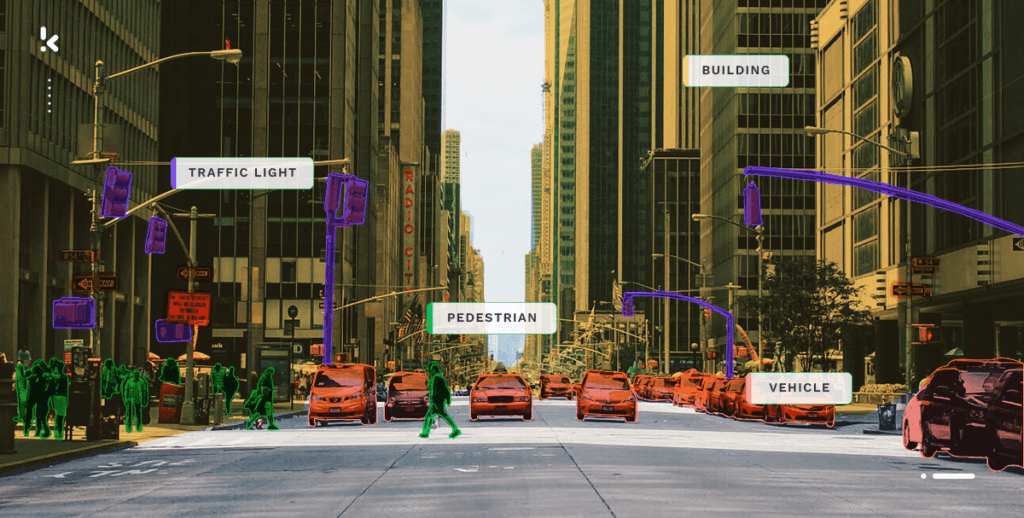
The first step of data annotation is to label data of pictures, videos, or text. In this context, data labeling means adding one or more informative labels to raw data (images, text, video, etc.), to provide context, so that a machine learning model can learn from it. Like in the visual below, traffic lights, pedestrians, vehicles, and buildings are labeled to train the model what it is.
The second step starts after the data has been labeled. Here, the annotated dataset is verified for authenticity and precision. This step is very important. Otherwise, the established model is trained with incorrect data, which can lead to costly retraining procedures.
Now that we have a general idea about data annotation, we want to take a closer look at the different types of annotation.
Types of data annotation
As previously mentioned, the data annotation process can be applied to various types of layouts. This means that different types of data annotation methods are used. For the blog’s readability, we will focus on three of the different data annotation methods. Keep in mind that this list is not exhaustive:
- Image annotation
- Video annotation
- Text annotation
Image annotation
For a wide range of applications such as computer vision, robotic vision, facial recognition and solutions that rely on AI, image annotation makes it possible to interpret images. Before this is applicable though, the AI model has to be trained with thousands of labeled images.
The training can be conducted by assigning metadata, such as identifiers, captions, and keywords to hundreds of images. With effective training, the accuracy of the AI-model increases and allows you to use it for numerous purposes (e.g., self-driving vehicles, auto-identified medical conditions).
Image annotation itself has again different types of annotation methods, such as:
- Bounding boxes → Drawing a rectangle around the object you want to annotate in a given image. The edges of the bounding box should touch the outermost pixels of the labeled image to ensure the highest possible accuracy.

- 3D cuboids → This method is very similar to annotation of bounding boxes. The only difference is that the user has to take the depth factor into account. It can be used to annotate planes or cars on an image.

- Polygons → While making use of bounding boxes or 3D cuboids, various objects might be unintentionally included in the annotated area. With the polygon tool, a line can be drawn around the specific object in the image that needs to be annotated.

- Keypoint tool → An object can be annotated by a series of points. This is often used for gesture detection or motion tracking.
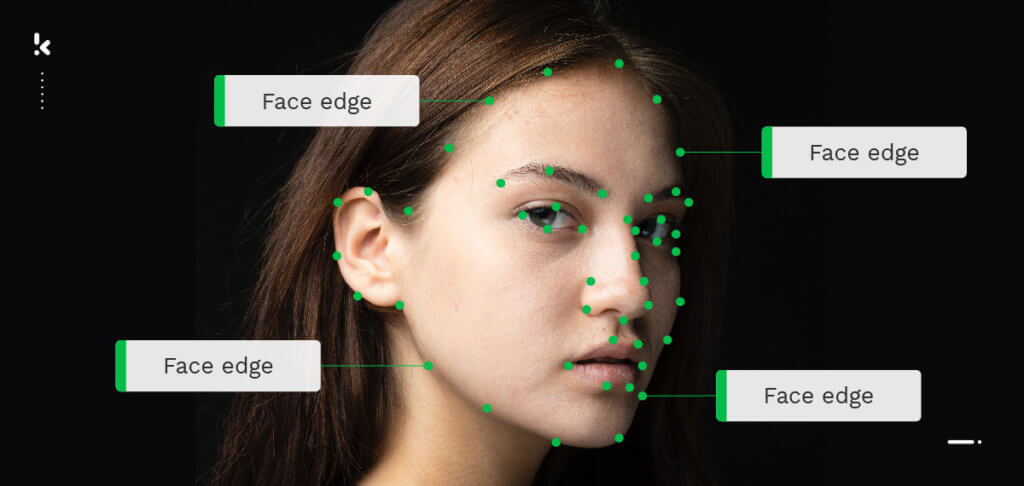
With this in mind, let’s now have a look at video annotation.
Video annotation
Video annotation is conducted on a frame-by-frame basis to make annotated objects recognizable for Machine Learning models. In general, it uses the same techniques as image annotation (e.g., bounding boxes) to detect or identify the desired objects.
This annotation method is an essential technique for computer vision tasks such as localization and object tracking, in which an algorithm can track the movement of an object. Therefore, video annotation is helpful for several industries such as the medical sector, manufacturing, and traffic management.
As the last type of data annotation, we want to talk about text annotation. Text is the most commonly used data category, as most companies depend greatly on text in various business processes.
Text annotation
Text annotation refers to adding metadata or labels to pieces of text. Let’s have a closer look at what that means.
Adding metadata
Adding metadata means providing relevant information for the learning algorithm. That way, it can prioritize and focus on certain words.
Example: “Here is the invoice (document_type) for the new computer (order) you ordered yesterday (time).”
The metadata added in the brackets provides the relevant information to the learning algorithm, ensuring that in the future it can detect the information it has been trained for.
Assigning labels
By adding labels, words can be assigned to a sentence that describes its type. A sentence can for example be described with sentiments or technicality.
Example: “The product doesn’t satisfy my needs, I want to return it.” Here, the label “unhappy” could be assigned.

This helps the algorithm to understand the sentiment and intent of a text and is closely related to named entity recognition. Let’s have a look at why that is.
Named Entity Recognition (NER)
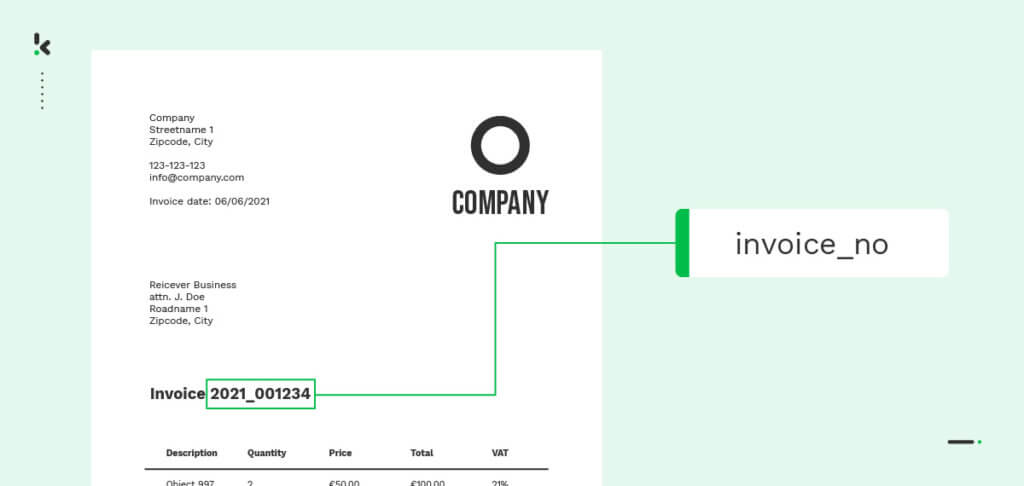
Named entity recognition is used to search for words based on their meaning. It aims to detect predefined named entities and expressions in a sentence. In general, NER is useful when extracting, classifying and categorizing information.
Let’s take the example of an invoice. By training the model to know the word “Invoice number” plus the characteristics of an invoice number (e.g., amount of digits) it can classify the document as an invoice. The same works for different words on different documents as well, which means you can use the Named Entity Recognition method to classify various documents based on data fields.
On top of that, an AI algorithm can be specifically trained to understand the sentiment and intent of a sentence, as this is very important to understand human behavior. Let’s see what that means.
Sentiment Annotation
As previously mentioned, sentiment annotation is performed by assigning labels to text that represent human emotions. For that purpose, labels such as sad, happy, frustrated, or angry are used. Then it can be used for sentiment analysis in, for example, the retail industry to understand customer satisfaction.
Intent Annotation
Intent annotation basically means that labels are assigned to sentences that express a certain intent or need. This can be very helpful for, e.g., customer service.
Let’s take a chatbot as an example. When a customer submits the sentence “I have trouble paying with my credit card” the person can immediately be directed to the financial team.
This is possible because the algorithm has been trained with hundreds of sentences that state a similar need.
Words like “trouble” express an emotion (sentiment) of the customer. On top of that, words like “credit card” were previously labeled as “paying method” or similar labels, allowing the algorithm to direct the customer to the financial department.
Before we explain why you even need data annotation, we want to dive deeper into the difference between automated data annotation and manual data annotation.
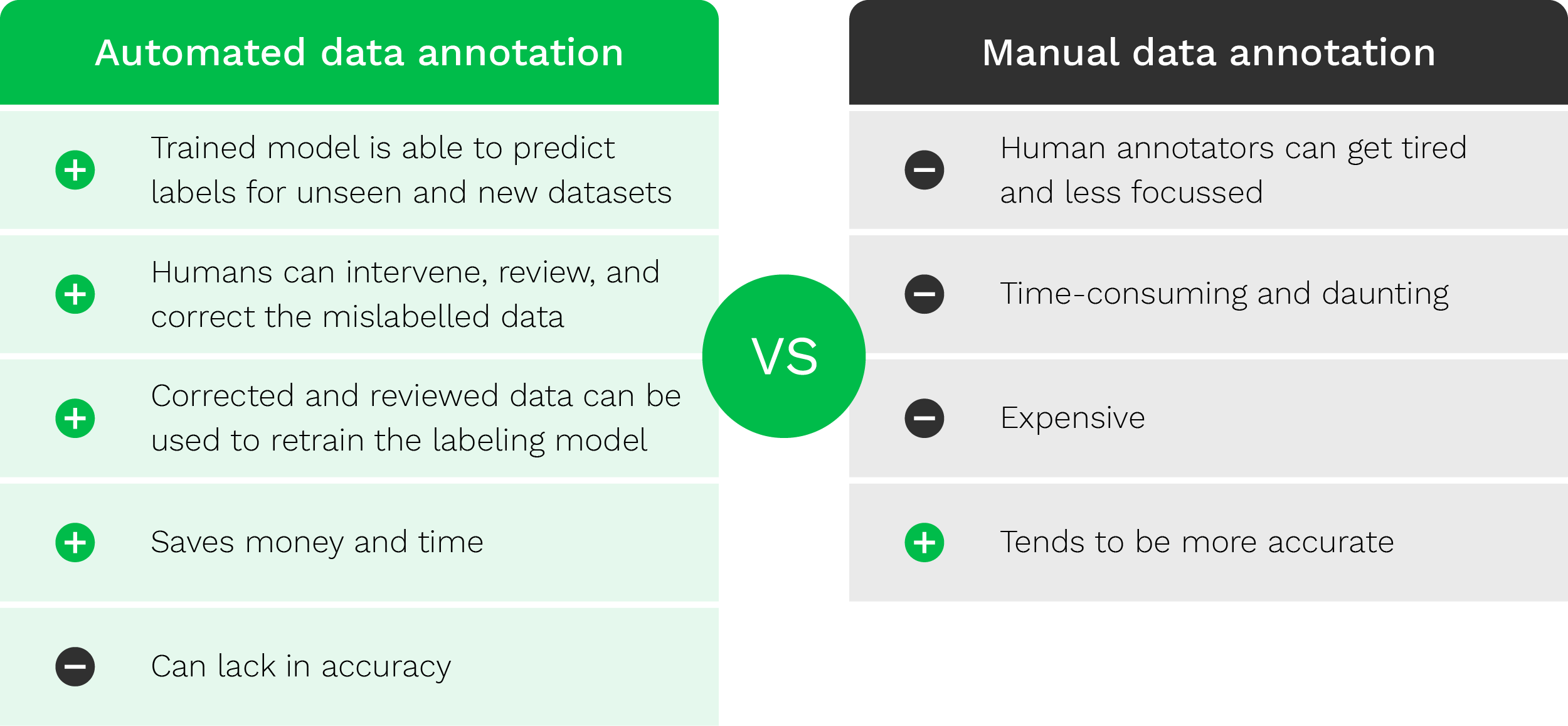
Automated data annotation vs. manual data annotation
Manual data annotation, as the name suggests, involves humans and works in the following way:
- The data annotator is provided with raw datasets (videos, images, text etc.) for annotation
- Based on specifications and the desired outcome, annotators know which method (bounding box, keypoint tool etc.) to use to annotate the relevant elements
- The data annotation expert labels all required elements manually
- After that, the dataset is ready to be used to train a model
Annotating one image can take up to 15 minutes depending on the quality of the provided document, annotation tool, and requirements. Imagine you have a project with up to 50,000 images. This means that an expert annotator spends 12,500 hours annotating these images. There needs to be a better way.
Automated data annotation
To pave the way for faster data annotation, automatic data labeling models are becoming more prominent. With automatic data labeling, AI systems take care of the data annotation process.
This works because of predefined rules and conditions set by humans. A dataset is passed through these predefined rules to validate a specific label. While this is more efficient, there is still a problem. Once data structures change frequently, laying out conditions and rules becomes difficult, which makes it almost impossible for a model to make an informed decision.
For this reason, a combined effort of human intelligence and artificial intelligence will probably yield the best result possible. With the help of human-in-the-loop automation and HITL software, the results of the AI model are consistently validated, verified, and optimized, while the model takes care of data labeling.
To give a quick overview of the difference between automated and manual data annotation, we provide the table below.
But why would you actually care about all of this? Well, there are a couple of reasons why data annotation is needed. Let’s take a look.
Why you need data annotation
Our ever-growing need for innovation makes data annotation necessary. How else will a car ever be able to drive itself? Without data annotation, every single image would be the same for machines, as they don’t have any inherent knowledge about anything in the world.
That means, without training the model of what a vehicle, the street, sidewalk, or pedestrian is, the self-driving car would just mindlessly drive into everything that crosses its way.
Similarly, many businesses train AI models to identify document types to automate categorization and data extraction processes. As many businesses deal with suppliers, let’s take invoices as an example. In order for the model to categorize the document type correctly, the characteristics of an invoice are first labeled and then fed to the algorithm.
This is not limited to invoices and can be applied to any kind of document type. For you, that means that all your document-related workflows could be optimized and relieve your team from the task of identifying and categorizing documents themselves.
With that in mind, let’s have a quick look at the key benefits of data annotation.
The key benefits of data annotation
Next to saving time and money, data annotation has a couple more benefits. These benefits are as follows:
- Higher efficiency → Data labeling allows machine learning systems to be better trained, which makes them more efficient in recognizing objects, words, sentiment, intent, etc.
- A higher degree of precision → Correct data labeling leads to more accurate data to train an algorithm. This will lead to a higher degree of data extraction accuracy in the future.
- Reduced amount of human intervention → The better the data annotation, the better the output of the AI model. Accurate output of the algorithm means that less human intervention is needed, which reduces costs and saves time.
- Scalability → This applies to automated data annotation, which allows you to scale data annotation projects to improve AI and ML models.
Well, next to benefits, every solution comes with its limitations. Therefore, to understand the bigger picture, it is important to discuss those next.
The limitations of data annotation
Even though data annotation is essential in training AI and ML models, it also has its limitations. Let’s have a look at what those are:
- AI and ML models require a massive amount of labeled data to learn. Therefore, companies have to hire a huge amount of workforce that can generate this enormous volume of labeled data. This is not only expensive but also limits the efficiency and productivity of those companies.
- Often, companies have limited access to proper tools and technology that can deliver the precise data annotation process. That means that those companies are left with inaccurate data and a slow training process of models.
- ML models are very sensitive. Even the slightest mistakes can cost companies a great deal. If the model is trained with inaccurate data, it will learn it the wrong way and hence predict data incorrectly in the future.
- A lack of process knowledge can lead to failure in complying with data security guidelines. Companies frequently have to deal with sensitive data, such as identifying faces, that need to be handled with utmost security. If data labeling is done wrong, misinformation or little mistakes can lead to terrible results.
You can see that data annotation is a sensitive procedure that can lead to wrongly trained AI models. If that happens, your self-driving car will crash into the next tree or run over an innocent pedestrian. Since we definitely don’t want that to happen, it is wise to make use of other companies that have hours of experience in annotating data.
Doxis is one of the companies that has spent thousands of hours annotating data to improve our AI-based software.
What Doxis can do for you
At Doxis, we trained our models to help companies automate document processing. With many years of training our AI-powered OCR engine, you can be sure that our software, AI.dp, works reliably and accurately. Making use of our solution means that you can save yourself from the daunting task of data annotation and still make use of all the benefits.
Doxis AI.dp
In general, Doxis AI.dp can turn any image into text. Next to that, this intelligent software can extract, classify, and verify data from all kinds of documents such as receipts, invoices, passports, and ID cards. This means that you can get any data field automatically extracted and stored in your database.
Before storing the data in your database, our Intelligent Document Processing (IDP) software is able to detect document fraud and mask sensitive data to comply with regulatory requirements.
In case you want to complement your existing software or extract data from other objects than documents, we can most certainly help you out.
Object Detection SDK
Our object detection SDK can be trained to recognize anything you need. From a utility meter to an invoice, with enough labeled datasets our data annotation team can help clients train our object detection model to recognize any object you need.
This means that you can provide your team with a solution that is reliable and allows you to capture data with the use of mobile phones.

Are you curious about our solution and want to see more? Let us show you how our software works. Simply schedule a free demo down below or contact one of our experts for more information.