
Are you investigating whether you should use Tesseract or not? Tesseract is the go-to open-source OCR solution for most organizations as it is free to use, well-known, and has many use cases.
However, the document processing market is changing fast. According to the IDP Survey 2025, 66% of enterprises are replacing legacy Intelligent Document Processing tools with modern, AI-powered systems, and 78% already use AI in their document workflows.
In this context, while Tesseract remains popular, it increasingly belongs to the “legacy” category: powerful for basic tasks, but often surpassed in accuracy, automation, and scalability.
So does it still make sense for you to use the Tesseract OCR engine?
In this blog, we will explain what Tesseract is, how it works, and whether Tesseract is the right option for your use case. Let’s get started.
Key Takeaways
- Tesseract OCR is a free, well-known open-source solution for extracting text from images, compatible with many programming languages through wrappers like Pytesseract.
- Modern AI-powered OCR solutions surpass Tesseract in accuracy, automation, and ease of setup, often working out-of-the-box with pre-trained models.
- Tesseract requires significant manual setup, coding, and training data for complex use cases.
- Doxis AI.dp offers a plug-and-play alternative with higher accuracy, AI enrichment, mobile scanning, and scalable automation.
What is Tesseract?
Tesseract is an open-source OCR Engine that extracts printed or written text from images. It was originally developed by Hewlett-Packard, and development was later taken over by Google. This is why it is now known as “Google Tesseract OCR”.
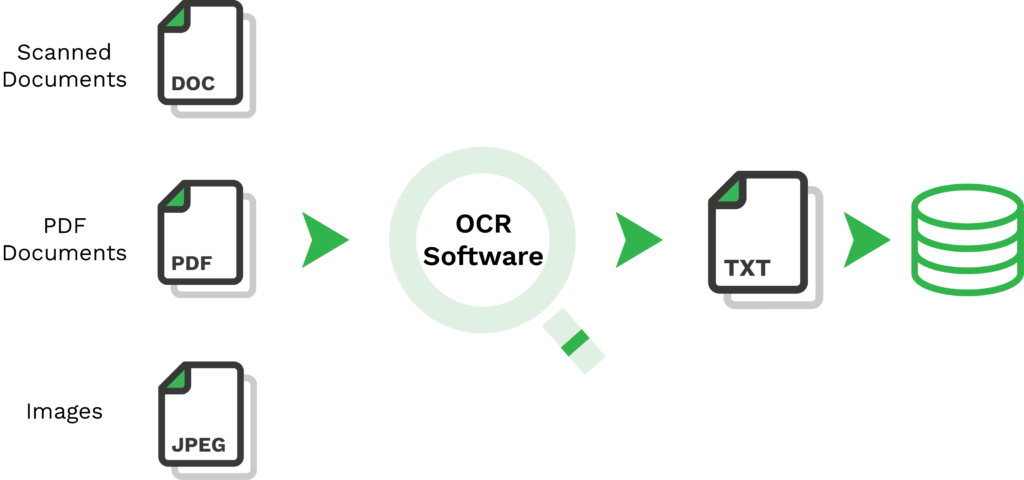
But what is an open-source OCR? It simply means that it is available for everyone to use freely, either directly or using an Application Programming Interface (API). With Tesseract OCR, users can extract text from images with efficient in-line and character pattern recognition of the OCR engine.
As of now, Tesseract already supports language recognition for more than 100 languages “out of the box”. The most recent version of Tesseract (4.0) has an AI integration through an LSTM Neural Network to detect and recognize inputs of a variety of sizes better.
One of Tesseract’s great strengths is that it is compatible with many programming languages and frameworks using wrappers such as Pytesseract, also known as Python-Tesseract. Let’s look closely at this connection between Tesseract OCR & Python.
Open Source Python OCR software
Pytesseract is not only an OCR in Python, open source software, or a Python library, but also serves as a wrapper for Google’s Tesseract OCR Engine. What it does is wrap Python code around Tesseract OCR, ensuring compatibility and the ability to operate with different software structures.

Note that there are other Python OCR libraries and wrappers that can be coupled with Tesseract, including:
- PYOCR – enables more options for sentence, digit, and word detection
- Textract – enables PDF data extraction for large files and packages
- OpenCV – open source library of programming functions focusing on real-time Computer Vision (CV)
- Leptonica – enables image processing features and image analysis applications with its imaging library
- Pillow – another Python imaging library, which supports opening, manipulating, and saving an extensive list of image file formats
Now that we have explained what Tesseract is and what its connection with Python is, let’s look at the steps in the Tesseract OCR process.
Steps in the Tesseract OCR Process
To help you understand what the Tesseract OCR process normally looks like, we have broken it down into the following steps:
- API request – Tesseract OCR can only be accessed via API integration. Once that connection between your solution and Tesseract is established, you can send API requests from your solution to the Tesseract OCR engine.
- Input Image – With an API request, you can send in your input image for text extraction.
- Image pre-processing – Before data extraction, the image pre-processing features of the Tesseract OCR engine kick in. This step exists to ensure that the image quality is as high as possible to achieve accurate data extraction results. Often, OpenCV is coupled with Tesseract to increase the image quality before data extraction.
- Data Extraction – Together with trained data sets and Leptonica or OpenCV, the Tesseract OCR engine processes the input image and extracts the data.
- Text conversion – As the data (text) has been extracted from the input, it can now be converted into a desired format that Tesseract supports, including PDF, plain text, HTML, TSV, and XML.
- API response back – Once the output is ready, your solution will get an API response back with the finalized output.
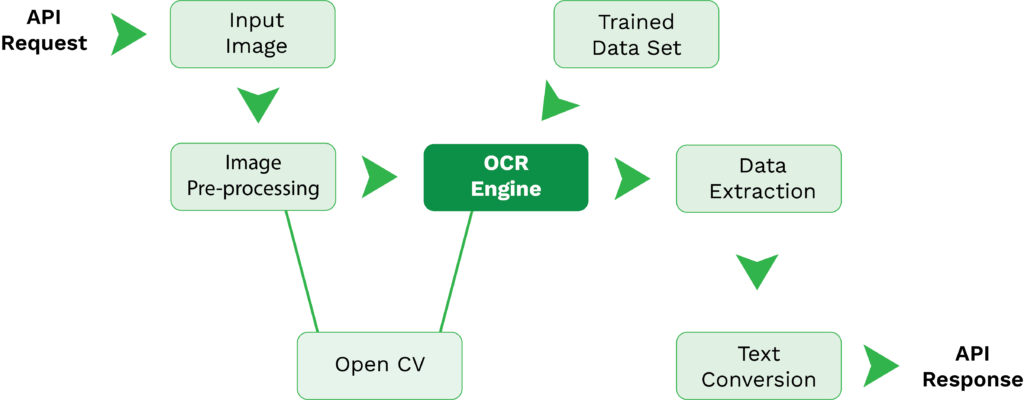
To have this OCR flow established, it will require knowledge and time to build all the relevant API connections. Furthermore, you would need to find the relevant components, such as libraries and wrappers, and do extensive coding. This depends mostly on your use case and application of OCR.
As stated earlier, Tesseract is often paired with OpenCV to enhance the input image quality to today’s standards. Let’s have a more detailed look at how this works.
Better Image Processing by combining OpenCV & Tesseract
To understand why OpenCV is often combined with Tesseract OCR, we must explain computer vision. Computer vision is a subfield of Artificial Intelligence (AI) that enables computers and software to see, observe, and make sense of digital images, videos, or other visual inputs. But what does it have to do with OpenCV?
OpenCV is an open-source library of computer vision functions that can enhance data extraction of OCR engines such as Tesseract. To do so, you could use the OpenCV library to integrate the following functions into the OCR solution:
- Object detection – enables the solution to detect a variety of objects
- Deep neural networks (DNN) – enables the solution to classify images
- Image processing – enables the solution to process input images better with various techniques such as edge detection, pixel manipulation, de-skewing, etc.
Without OpenCV, Tesseract is not as sophisticated as we would expect from today’s OCR solutions, as many of them apply various AI technologies.
Now that you know that Tesseract OCR can be improved with other libraries of programming functions, such as OpenCV, let’s take a closer look at one of the most commonly used Tesseract wrappers in Python: PyTesseract.
How Does (Py)Tesseract Work?
So far, we know that Pytesseract is a wrapper for Google’s Tesseract OCR in Python with additional functionalities that Tesseract alone does not have. So what are these functionalities, and how do they work?
Pytesseract can be used as a standalone script for Tesseract, allowing it to print recognized text instead of converting it to a file. Pytesseract can read all image files that are supported by imaging libraries such as Leptonica and Pillow, including JPEG, PNG, GIF, BMP, TIFF, and many others. Hence, it is often utilized in image-to-text Python OCR use cases.
The way Pytesseract works is that it converts the text and graphic elements of a scanned image into a bitmap. This bitmap is simply a construction of white and black dots. Like with any OCR, the image goes through the pre-processing phase for brightness and contrast adjustments before data extraction and conversion.
The Pytesseract framework is optimized for better language detection, which benefits Google’s Tesseract OCR as well. Next to that, this framework is excellent in detecting fonts used and the orientation of the text on the input image. For instance, it can provide an orientation confidence figure to ensure the detection of the orientation. However, one of its most important features is that it can provide you with the bounding box information of the OCR.
Getting acquainted with the features and how Pytesseract Python OCR works is nice, but it doesn’t provide you with any details on how to use Google’s Tesseract OCR. Let’s get into that next!
Python OCR Use Cases with Tesseract
If you are in a business that processes documents from customers, suppliers, partners, or employees, chances are that you can improve your document processing workflow with Tesseract OCR. Below, we have listed a few of the use cases in which Python OCR can be applied.
- Automated Data Entry – Bottlenecks are often caused by tedious tasks such as data entry. With OCR, you can eliminate manual data entry and reduce costs by up to 70%.
- Digital Client Onboarding – OCR can be very helpful in extracting personal information from identity documents. With OCR, you can provide your customers with a remote onboarding solution without needing an onboarding process at the front desk.
- Automated Receipt Clearing For Loyalty Campaigns – What if you have a large loyalty campaign with a significant amount of receipts to verify? First, you must extract the data into your database before validation. This is what Tesseract can help you with.
- Automated Invoice Processing for Accounts Payable – Accounts Payable processes go through many stages and always start with manual data entry. With OCR, you can reduce the turnaround time and costs with automated invoice data extraction.
- Digital Archiving – It can consume a lot of time to find a piece of information from a paper archive. Digital archiving with OCR has many benefits for organizations, including cost savings, GDPR compliance, and better access to data.
- VIN Data Extraction – Manually writing Vehicle Identification Numbers (VINs) on paper or forms is not always the most efficient way to process them. Extracting the VIN with Tesseract OCR is straightforward and can boost your operations significantly.
Don’t worry if your use case wasn’t described here. Tesseract can generally improve many document-related workflows like any other Python OCR solution. However, one thing to keep in mind is that it is not an out-of-the-box solution.
What this means is that for each of the above-mentioned use cases, you need to couple multiple APIs together, and use a variety of Python wrappers and libraries of programming functions. Additionally, you would need to train the OCR engine with a significant amount of data to support your use case, which requires tons of resources, both time and money.
Training Tesseract to Process Your Files
To achieve high accuracy for complex or specialized document types, Tesseract OCR must be manually trained with extensive annotated datasets: a process that can be costly and time-consuming compared to AI-powered solutions.
If Tesseract does not support your data extraction needs out of the box, you will need to train the OCR engine yourself. In practice, this means:
- Gathering training data — thousands of example images or documents annotated with the correct text and formatting.
- Preprocessing images — improving resolution, deskewing, adjusting brightness/contrast, and cleaning noise before training.
- Integrating via API — connecting Tesseract to your application using wrappers like Pytesseract or libraries such as OpenCV.
- Running the training process — feeding annotated datasets into Tesseract’s LSTM-based training mode to improve recognition accuracy.
- Testing and optimizing — validating results against samples and refining parameters until accuracy meets requirements.
For many organizations, the challenge starts with data availability. High-quality training data is not always accessible; acquiring it can be expensive, and annotating in-house consumes significant resources. Additionally, API setup and tuning require substantial technical expertise.
These hurdles (data scarcity, long setup times, and lack of AI-based automation) are why many companies opt for solutions that work out of the box. Alternatives like Doxis AI.dp eliminate manual training, delivering higher accuracy, fraud detection, multi-language support, and workflow automation from day one.
Limitations of Tesseract
Tesseract OCR can be very useful in many instances and use cases. However, like any other open-source solution, there are always some drawbacks to consider. In this section, we will shed light on these limitations one by one:
- Tesseract is not as accurate as more advanced solutions embedded with AI
- Tesseract is prone to errors if the separation of the foreground and background of the image is not significant
- You need a high amount of resources and time to develop your own solution using Tesseract OCR
- Tesseract doesn’t support all file formats by itself
- Tesseract doesn’t recognize handwriting
- The image quality has to reach a certain threshold of Dots per Inch (DPI) for it to work
- Tesseract has to be developed further and needs the integration of AI to be able to automate certain document processes (e.g., verification, cross-check validation, etc.)
- Tesseract doesn’t have a Graphical User Interface (GUI), which means that you have to connect it to your existing GUI or have one developed
- The additional development will set you back in time and money
Overall, if your OCR use case is simple and you have in-house knowledge of how to develop OCR solutions using Python, then Google’s Tesseract may be a sufficient solution for you.
However, if you need a more accurate OCR solution that enables scalability or works out of the box, then Tesseract is not the best fit for you. While it is free to use, paid options are often easier and might still be cheaper than using Tesseract. Other reasons why it may not be the right choice for you:
- Long setup time
- The need to establish connections to ERP or accounting systems
- Lack of support for your use case
- Lack of training data
- Lack of in-house knowledge about OCR in Python
The best alternative to Tesseract OCR: Doxis AI.dp
If you need higher accuracy, faster implementation, and AI-powered automation from day one, Doxis AI.dp is the smarter alternative to Tesseract OCR.
AI.dp can not only OCR an image to text better than Tesseract OCR, but also classify, verify, detect document fraud, and anonymize data automatically using AI technologies.
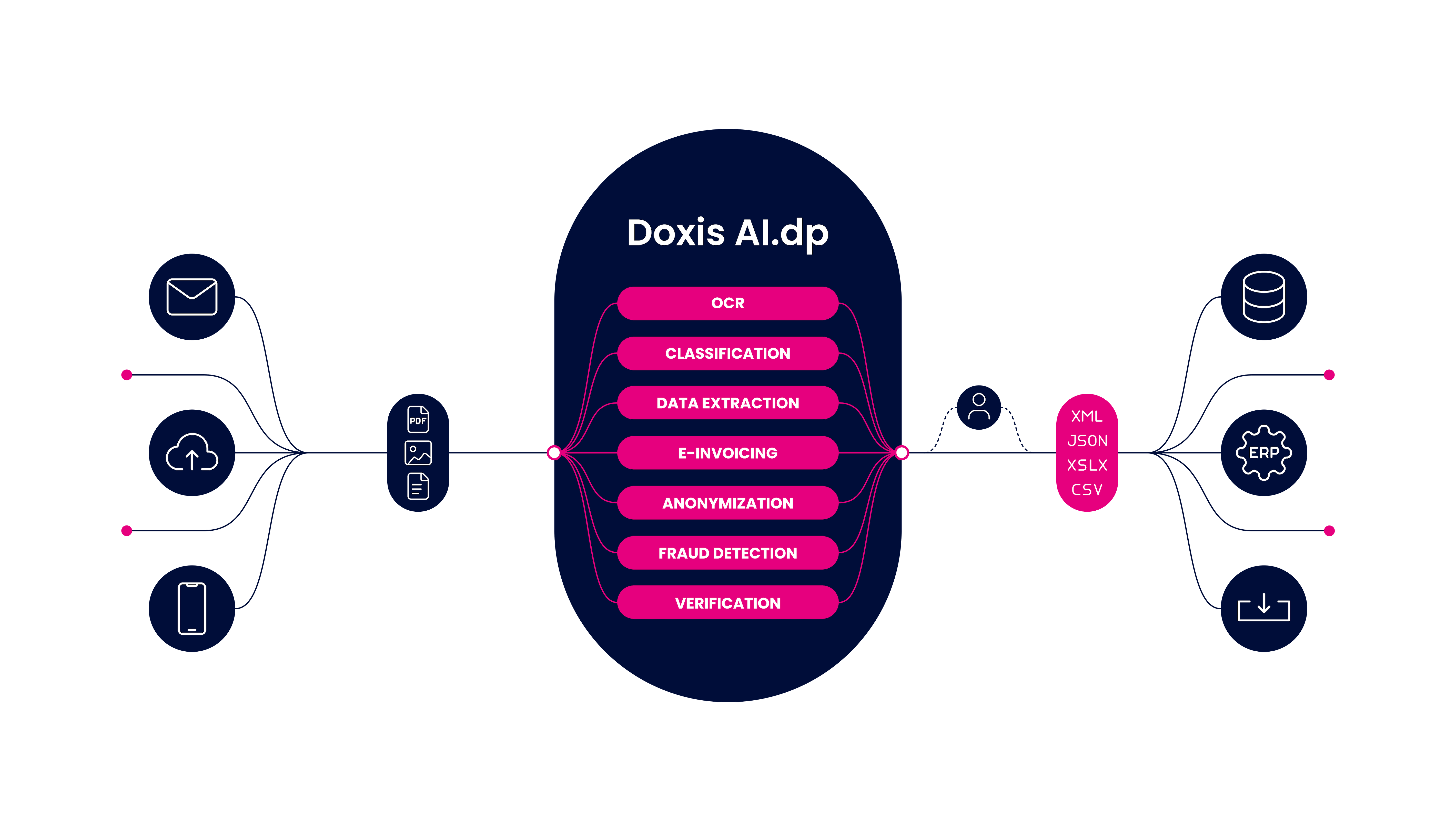
Why would you consider AI.dp over Tesseract OCR? The benefits of using Doxis AI.dp over Tesseract include:
- Scalability – AI.dp is not limited by templates or certain input files, which allows your organization to scale OCR operations
- Wide range of supported document types – Currently, there are out-of-the-box options to capture data from documents such as passports, receipts, invoices, ID cards, driver’s licenses, and many others in multiple languages
- Specialized onboarding team – Enables fast and reliable onboarding for you to get started as quickly as possible
- Higher OCR accuracy – With AI technologies, OCR accuracy is higher as the solution is constantly learning and not restricted to any templates or strict rules
- Document workflow automation – AI.dp can automate any document-related workflow, helping you eliminate repetitive tasks such as manual archiving, manual data entry, and data validation
- Mobile scanning – Take your business to another level by enabling your organization or customers to OCR images with mobile devices using AI.dp mobile scanning solutions
- Customized solution – If you need a custom solution tailored to your use case, Doxis’ experienced development team can help you build it
Overall, AI.dp supports many more use cases out of the box than Google’s Tesseract OCR. If your organization has a more complex use case or wants to have a plug-and-play solution implemented, AI.dp is the best Tesseract alternative for you.
Schedule a demo using the form below to see how our solution works. In case you have burning questions that were not answered yet, please feel free to contact our experts.
FAQ
Tesseract works best if you have technical expertise for setup and customization. Otherwise, a managed OCR solution can save significant time and resources.
Typical accuracy is 80–85% for clean, structured text. AI solutions like AI.dp reach 95–98% even with complex layouts, without extensive manual training.
No, Tesseract focuses on printed text. For handwritten forms, signatures, or notes, use an OCR engine with handwriting recognition.
Complex workflows can take weeks or months to configure. Doxis AI.dp offers pre-trained models and ready-made integrations for deployment in days.
Yes, it’s open-source with no license fees. However, the “free” cost excludes developer time, training, and maintenance. Many enterprises find the total cost of ownership lower with plug-and-play AI solutions.
Not without custom API development. AI.dp offers direct connectors and an open API for seamless integration into ERP, CRM, and other business tools.
Yes, it supports over 100 languages, but accuracy can vary with formatting, fonts, and image quality.
Not natively. It needs extra coding and tools, whereas some AI OCR platforms offer these features out of the box.
AI-powered OCR delivers faster setup, higher accuracy, automation across more use cases, and smoother integration with modern tech stacks.
The best way to experience AI.dp is through a live demo with our team. We’ll process your own documents in real time and walk you through automation workflows tailored to your business. You also receive €25 in free credits so you can test the platform yourself.