
¿Estás investigando si deberías usar Tesseract o no? Tesseract es la solución de OCR de código abierto preferida por la mayoría de las organizaciones, ya que es de uso gratuito, muy conocida y tiene muchos casos de uso.
Aunque es de uso gratuito, no siempre es la mejor opción. Muchos motores de OCR han sobrepasado la calidad de reconocimiento de imágenes de Tesseract con tecnologías de IA y ofrecen una configuración más sencilla y un reconocimiento de archivos ya entrenado.
Entonces, ¿sigue teniendo sentido utilizar Tesseract OCR?
En este blog, explicaremos qué es Tesseract, cómo funciona y si Tesseract es la opción adecuada para tu caso de uso. Empecemos.
¿Qué es Tesseract?
Tesseract es un motor OCR de código abierto que extrae texto impreso o escrito de las imágenes. Fue desarrollado originalmente por Hewlett-Packard, y su desarrollo fue adquirido después por Google. Por eso se conoce ahora como “Google Tesseract OCR”.
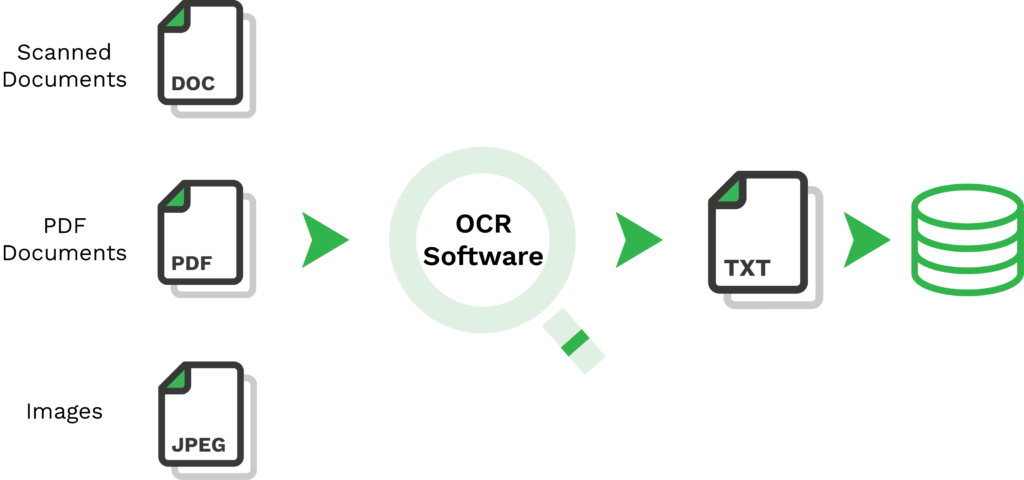
Pero, ¿qué es un OCR de código abierto? Simplemente significa que está disponible para que todo el mundo lo utilice libremente, ya sea directamente o mediante una interfaz de programación de aplicaciones (API). Con Tesseract OCR, los usuarios pueden extraer texto de las imágenes con un reconocimiento eficaz de patrones de caracteres y en línea del motor de OCR.
En la actualidad, Tesseract ya es capaz de reconocer más de 100 idiomas “out of the box”. La versión más reciente de Tesseract (4.0) cuenta con una integración de IA a través de la Red Neuronal LSTM para detectar y reconocer mejor el contenido del texto de diferentes tamaños.
Uno de los aspectos principales de Tesseract es que es compatible con muchos lenguajes de programación y estructuras que utilizan wrappers como Pytesseract, también conocido como Python-Tesseract. Veamos de cerca esta conexión entre Tesseract OCR y Python.
Software OCR de código abierto en Python
Pytesseract no es sólo OCR en Python, software de código abierto, o una biblioteca de Python, sino que también sirve como un wrapper para el motor Tesseract OCR de Google. Lo que hace es envolver el código Python alrededor del Tesseract OCR, asegurando la compatibilidad y la capacidad de operar con diferentes estructuras de software.

Hay que tener en cuenta que existen otras bibliotecas y wrappers de OCR en Python que se pueden combinar con Tesseract, como por ejemplo:
- PYOCR – permite más opciones para la detección de oraciones, dígitos y palabras
- Textract – permite la extracción de datos PDF para archivos y paquetes de gran tamaño
- OpenCV – biblioteca de código abierto de funciones de programación centradas en Computer Vision (CV) en tiempo real
- Leptonica – permite funciones de procesamiento de imágenes y aplicaciones de análisis de imágenes con su biblioteca de imágenes
- Pillow – otra biblioteca de imágenes de Python, que permite abrir, manipular y guardar una amplia lista de formatos de archivos de imágenes
Ahora que hemos explicado qué es Tesseract y cuál es su conexión con Python, veamos los pasos del proceso de OCR de Tesseract.
Las fases del proceso Tesseract OCR
Para ayudarte a entender cómo es normalmente el proceso de Tesseract OCR, lo hemos divido en los siguientes pasos:
- Solicitud API – Sólo se puede acceder a Tesseract OCR a través de la integración de API. Una vez establecida la conexión entre tu solución y la de Tesseract, puedes enviar solicitudes de API desde tu solución al motor de OCR de Tesseract.
- Imagen inicial – Con una solicitud API, puedes enviar tu imagen inicial para la extracción de texto.
- Pre-procesamiento de la imagen – Antes de la extracción de datos, las funciones de pre-procesamiento de la imagen del motor OCR de Tesseract entran en acción. Este paso existe para asegurar que la calidad de la imagen sea lo más alta posible para lograr una extracción de datos precisa. A menudo, OpenCV se combina con Tesseract para aumentar la calidad de la imagen antes de la extracción de datos.
- Extracción de datos – Junto con series de datos entrenados y Leptonica u OpenCV, el motor OCR de Tesseract procesa la imagen y extrae los datos.
- Conversión de texto – Como los datos (texto) han sido extraídos de la información ingresada, ahora pueden ser convertidos a cualquier formato que Tesseract soporte, incluyendo PDF, texto simple, HTML, TSV y XML.
- Respuesta API – Una vez que la información está lista, tu solución recibirá una respuesta API con la información finalizada.
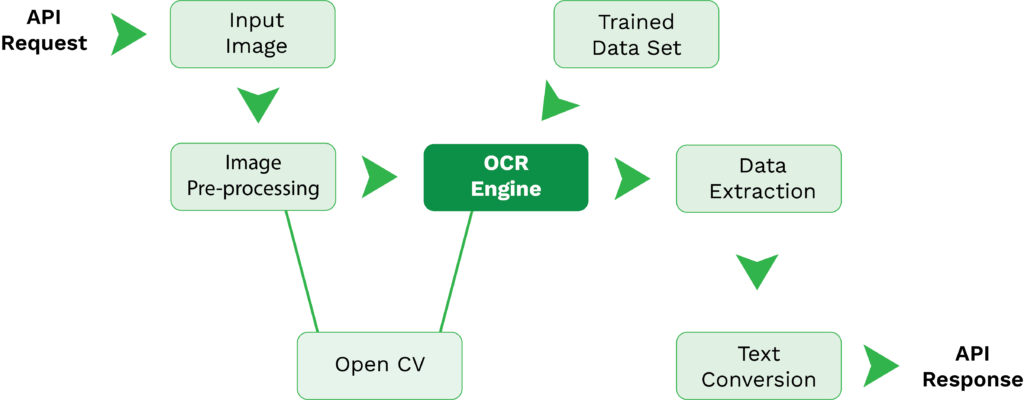
Para tener este flujo de OCR establecido, se requerirá conocimiento y tiempo para construir todas las conexiones relevantes de API. Además, necesitarás encontrar los componentes necesarios, como bibliotecas y wrappers, y realizar una codificación exhaustiva. Esto depende sobre todo de tu caso de uso y de la aplicación del OCR.
Como ya se ha dicho, Tesseract se suele emparejar con OpenCV para mejorar la calidad de la imagen que se introduce según los estándares actuales. Veamos con más detalle cómo funciona esto.
Mejora del procesamiento de imágenes mediante la combinación de OpenCV y Tesseract
Para entender por qué se combina a menudo OpenCV con Tesseract OCR, debemos explicar el término computer vision. Computer vision es un subcampo de la Inteligencia Artificial (IA) que hace posible que los ordenadores y softwares vean, observen y le den sentido a las imágenes digitales, a los vídeos o a otros elementos visuales. ¿Pero qué tiene que ver con OpenCV?
OpenCV es una biblioteca de código abierto de funciones de computer vision que puede mejorar la extracción de datos de motores OCR como el de Tesseract. Para ello, podrías utilizar la biblioteca OpenCV para integrar las siguientes funciones en la solución OCR:
- Detección de objetos – le permite a la solución detectar una variedad de objetos
- Redes neuronales profundas (DNN) – permiten que la solución clasifique las imágenes
- Procesamiento de imágenes – le permite a la solución procesar mejor las imágenes introducidas con diversas técnicas, como la detección de bordes, la manipulación de píxeles, la corrección de la alineación, etc.
Sin OpenCV, Tesseract no es tan sofisticado como se esperaría de las soluciones de OCR actuales, ya que muchas de ellas aplican diversas tecnologías de IA.
Ahora que sabes que el OCR de Tesseract se puede mejorar con otras bibliotecas de funciones de programación como OpenCV, vamos a echar un vistazo más de cerca a uno de los wrappers de Tesseract más utilizados en Python: PyTesseract.
¿Cómo funciona (Py)Tesseract?
Hasta ahora, sabemos que Pytesseract es un wrapper para el OCR Tesseract de Google en Python con características adicionales que Tesseract por sí solo no tiene. Entonces, ¿cuáles son estas características y cómo funcionan?
Pytesseract puede ser utilizado como un guión independiente para Tesseract que le permite imprimir el texto que ha reconocido en lugar de convertirlo en un archivo. Pytesseract puede leer todos las imágenes que son compatibles con las bibliotecas de imágenes como Leptonica y Pillow, incluyendo JPEG, PNG, GIF, BMP, TIFF, y muchos otros. Por lo tanto, a menudo se utiliza en casos de uso de OCR de imagen a texto en Python.
El modo en el que funciona Pytesseract es convirtiendo el texto y los elementos gráficos de una imagen escaneada en un mapa de bits. Este mapa de bits es simplemente una construcción de puntos blancos y negros. Como con cualquier OCR, la imagen pasa por la fase de pre-procesamiento para hacer ajustes de brillo y contraste antes que se puedan extraer los datos y se conviertan.

El framework Pytesseract está optimizado para una mejor detección del lenguaje, lo que beneficia también al OCR Tesseract de Google. Además, este sistema es excelente para detectar las fuentes utilizadas y la orientación del texto en la imágen que se introduce. Por ejemplo, puede proporcionar una cifra de confianza de la orientación para garantizar la detección de la misma. Sin embargo, una de sus características más importantes es que puede ofrecerte la información del cuadro delimitador del OCR.
Familiarizarte con las características y el modo de trabajo del Pytesseract Python OCR es agradable, pero no te proporciona ningún detalle sobre cómo utilizar el Tesseract OCR de Google. ¡Hablemos de eso a continuación!
Casos de uso de OCR en Python con Tesseract
Si tienes una empresa que procesa documentos de clientes, proveedores, socios o empleados, es probable que puedas mejorar tu proceso de trabajo con Tesseract OCR. A continuación hemos enumerado algunos de los casos de uso en los que se puede aplicar Python OCR.
- Entrada de datos automatizada – a menudo los embotellamientos son causados por tareas tediosas como la entrada de datos. Con el OCR, puedes eliminar la entrada manual de datos y reducir los costos hasta un 70%.
- Incorporación digital de clientes – OCR puede ser muy útil para extraer información personal de los documentos de identidad. Con OCR, puedes ofrecerle a tus clientes una solución de incorporación al sistema sin necesidad de un proceso administrativo en el mostrador.
- Compensación automatizada de recibos para campañas de fidelización – ¿Qué ocurre si tienes una gran campaña de fidelización con una gran cantidad de recibos que verificar? En primer lugar, debes extraer los datos a tu base de datos antes de la validación. Tesseract puede ayudarte con esto.
- Procesamiento automatizado de facturas de cuentas por pagar – Los procesos de cuentas por pagar pasan por muchas etapas y siempre comienzan con la introducción manual de datos. Con la tecnología OCR, puedes reducir el tiempo de respuesta y los costos gracias a la extracción automatizada de datos de las facturas.
- Almacenamiento digital – Puede tomar mucho tiempo encontrar información en un archivo impreso. El almacenamiento digital con OCR tiene muchas ventajas para las organizaciones, como el ahorro de costos, el cumplimiento del GDPR y un mejor acceso a los datos.
- Extracción de datos VIN – Escribir manualmente los números de identificación de vehículos (VIN) en papel o formularios no suele ser la forma más eficiente de procesarlos. Extraer el VIN con Tesseract OCR es sencillo y puede potenciar tus operaciones de forma significativa.
No te preocupes si tu caso de uso no fue descrito aquí. En general, Tesseract puede mejorar muchos flujos de trabajo relacionados con los documentos como cualquier otra solución de OCR en Python. Sin embargo, una cosa a tener en cuenta es que no es una solución “out-of-the-box”.
Esto significa que para cada uno de los casos de uso mencionados anteriormente, es necesario combinar varias API y utilizar una variedad de wrappers de Python y bibliotecas de funciones para programar. Además, es necesario entrenar el motor OCR con una cantidad sustancial de datos para que sea compatible con tu caso de uso, lo que requiere muchos recursos, tanto de tiempo como de dinero.
Cómo entrenar a Tesseract para que procese tus archivos
En los casos en que Tesseract no es compatible con tus necesidades de extracción de datos, tienes que entrenar al motor OCR tú mismo. Esto significa que necesitarías tener miles de imágenes o documentos de ejemplo con anotaciones para entrenar al Tesseract OCR. A esto se le llama “datos de entrenamiento”.
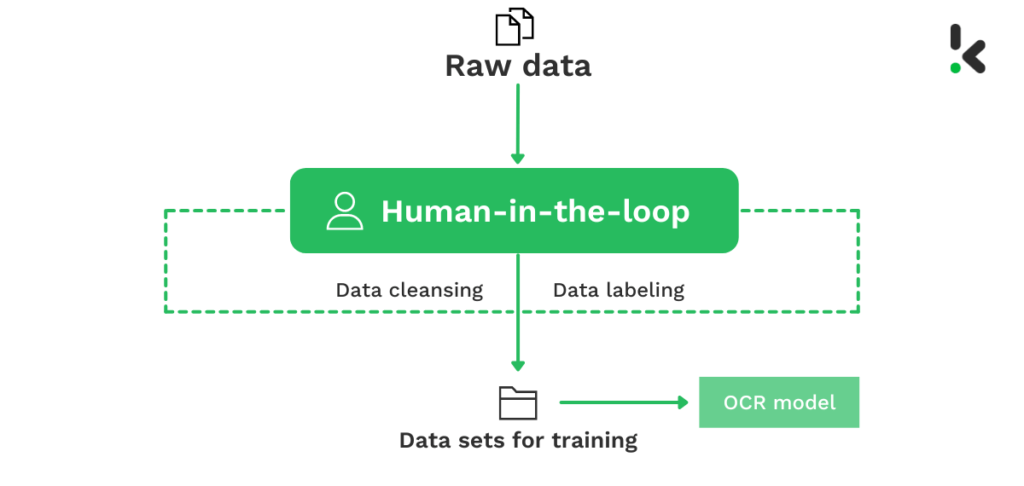
No todas las organizaciones disponen de datos de entrenamiento. Adquirir datos de entrenamiento puede costarle a tu organización una suma considerable de dinero. Y si tuvieras que anotar los datos tú mismo, te costaría tanto tiempo como dinero.
Estas suelen ser las principales razones por las que muchas organizaciones prefieren optar por una solución que ya ofrece opciones listas para usar. No obstante, existen otras razones que deben tenerse en cuenta antes de precipitarte a utilizar un OCR de código abierto como el Tesseract de Google.
Limitaciones de Tesseract
Tesseract OCR puede ser de gran utilidad en muchos casos de uso. Sin embargo, como cualquier otra solución de código abierto, siempre hay que tener en cuenta algunos inconvenientes. En esta sección, explicaremos estas limitaciones una por una:
- Tesseract no es tan preciso como otras soluciones más avanzadas que incorporan la IA
- Tesseract es propenso a cometer errores si la separación del primer plano y el fondo de la imagen no es sustancial
- Se necesita una gran cantidad de recursos y tiempo para desarrollar tu propia solución utilizando Tesseract OCR
- Tesseract no es compatible con todos los formatos de archivo por sí mismo
- Tesseract no reconoce la escritura a mano
- La calidad de la imagen tiene que alcanzar un determinado valor de puntos por pulgada (DPI) para que funcione
- Tesseract tiene que desarrollarse más y necesita de la integración con la IA para poder automatizar ciertos procesos de los documentos (por ejemplo, la verificación, la validación comparativa, etc.)
- Tesseract no tiene una interfaz gráfica de usuario (GUI), lo que significa que hay que conectarlo a la GUI existente o desarrollar una.
- El desarrollo adicional te hará perder tiempo y dinero.
En general, si tu caso de uso OCR es simple y tienes conocimientos internos sobre cómo desarrollar soluciones OCR usando Python, entonces Tesseract de Google puede ser una solución adecuada para ti.
Sin embargo, si necesitas una solución de OCR más precisa que permita la escalabilidad o que funcione de forma inmediata, entonces Tesseract no es lo más adecuado para ti. Aunque su uso es gratuito, las alternativas pagadas suelen ser más sencillas y pueden llegar a ser más económicas que usar Tesseract. Otras razones por las que puede que no sea la opción más adecuada para ti:
- Largo tiempo de configuración
- Necesidad de establecer conexiones con sistemas ERP o de contabilidad
- Falta de apoyo para tu caso de uso
- Falta de datos de entrenamiento
- Falta de conocimientos internos sobre OCR en Python
La alternativa perfecta a Tesseract OCR: Doxis AI.dp
Doxis AI.dp se considera la siguiente generación de tecnología OCR. Con más de diez mil horas de desarrollo, esta solución ha sido pulida para satisfacer a clientes en múltiples industrias.
AI.dp no sólo puede convertir imágenes a texto mejor que Tesseract OCR, sino que también puede clasificar, validar y enmascarar datos automáticamente utilizando tecnologías de IA.
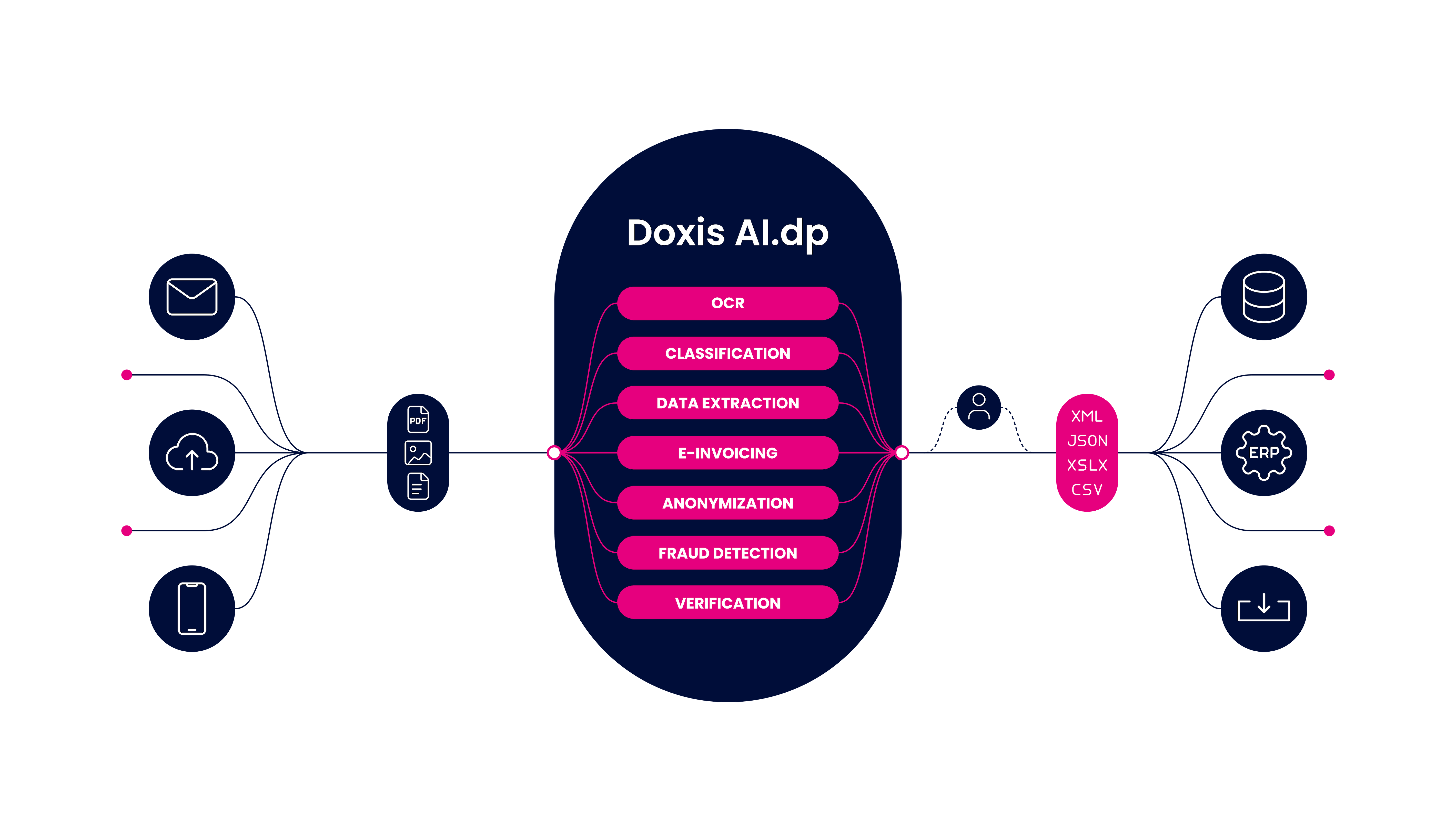
¿Por qué deberías considerar el uso de AI.dp en lugar de Tesseract OCR? Los beneficios de usar Doxis AI.dp sobre Tesseract incluyen:
- Gran variedad de tipos de documentos compatibles – Actualmente existen opciones para capturar datos de documentos como pasaportes, recibos, facturas, documentos de identidad, licencias de conducir y muchos otros en varios idiomas.
- Escalabilidad – AI.dp no está limitado por plantillas o archivos determinados, lo que permite que tu organización amplíe las operaciones de OCR.
- Equipo de incorporación especializado – Permite una incorporación rápida y segura para que puedas empezar a trabajar lo antes posible
- Mayor precisión de OCR – Con las tecnologías de IA, la precisión de OCR es mayor, ya que la solución aprende constantemente y no se limita a ninguna plantilla o regla estricta
- Automatización del flujo de trabajo de documentos – AI.dp puede automatizar cualquier flujo de trabajo relacionado a documentos, ayudándote a eliminar tareas repetitivas como el archivado manual, la entrada de datos manual y la validación de datos
- Escaneado móvil – Lleva a tu negocio a otro nivel permitiéndole a tu organización o a tus clientes hacer OCR de imágenes con dispositivos móviles usando las soluciones de escaneado móvil de AI.dp
- Solución personalizada – Si necesitas una solución personalizada adaptada a tu caso de uso, el equipo de desarrollo experto de Doxis puede ayudarte a construirla
En general, AI.dp es compatible con muchos más casos de uso inmediatos que el Tesseract OCR de Google. Si tu organización tiene un caso de uso más complejo o quiere tener una solución “plug-and-play” implementada, AI.dp es la mejor alternativa a Tesseract para ti.
Programa una demostración utilizando el formulario de abajo para ver cómo funciona nuestra solución. En caso de que tengas preguntas importantes que aún no hayan sido respondidas, no dudes en ponerte en contacto con nuestros expertos.