We understand the struggles facing businesses of today to handle and process large numbers of documents, from receipts to invoices among other internal documents. Manually processing these documents opens the door to errors in data extraction as well as document fraud slipping through the cracks. In fact, a Gartner study suggests that the yearly cost of human data entry errors is almost $1 million.
For this, AI-powered Optical Character Recognition (OCR) technology, has been a game-changer for various businesses that handle data extraction from documents like receipts, invoices, or purchase orders. Using OCR for line item extraction and recognition offers a streamlined approach to handling vast amounts of data across a range of industries such as financial, retail, and more.
In this blog, we’ll delve into the details of line item extraction and recognition, and how you can extract line item data from receipts or invoices with Doxis. Let’s dive in!
Why is Line Item Recognition Useful for Businesses?
As the world steps further into the world of automation and AI, there are more and more reasons for businesses to ask how automation can help them. But how exactly can businesses leverage OCR for line item extraction? Well, here are some use cases to examine just how this can be done.
Use Cases
There are a lot of use cases for receipt and invoice line item extraction and processing. However, here are a few of the use cases we come across frequently:
- Accounts Payable Automation: Line item recognition simplifies the extraction of product details, quantities, and prices to accelerate accounts payable and receivable processes.
- Automated Expense Reporting: Businesses can automate expense management, reducing manual input and ensuring accuracy in reimbursement with OCR for line item data extraction.
- Procurement and Supplier Management: Line item extraction can be used to streamline data extraction to enhance the efficiency of tracking orders, managing suppliers, and ensuring compliance. Invoices or purchase orders can be scanned for swift extraction and processing.
- Receipt Scanning For Loyalty Programs: Line item extraction can be used to identify items frequently purchased by customers enrolled in loyalty programs. This information can help businesses tailor loyalty rewards and offers to individual customer preferences, enhancing customer retention and engagement.
- Receipt Clearing for Loyalty Campaigns: Line item extraction can be used by companies running loyalty campaigns where customers may need to submit receipts to earn rewards or points. Line item recognition enables automated receipt validation, ensuring that customers are accurately credited for their purchases.
Watch the video below to see how OCR simplifies line item recognition and makes loyalty campaigns more efficient.
Client Stories
Curious to see how it works in real life? Explore our AP automation case studies to learn how companies like yours have optimized efficiency and compliance with Doxis’ digital solutions. Read the case studies here:
- How accounting software WeClapp automates the processing of 90% of their business invoices and receipts
- How real estate software Alasco automates invoice processing and allows users to work 3x faster
- How the financial management platform Pennylane uses Doxis for invoice data extraction
How Does Line Extraction Work with OCR?
OCR technology is a powerful tool that enhances the quality of a scanned text or an image and follows several steps to extract data that has been captured. For line item extraction, OCR software enables you to scan receipts and invoices, eliminating the need for manual extraction of individual line items. This way you can better maintain accuracy, prevent fraud, and save time.
There are 2 primary approaches to OCR: Template OCR and Machine Learning OCR and they differ in their ability to extract and process line items efficiently. Template OCR is based on predetermined templates. A template-based model often requires manual intervention, which can be time-consuming and inefficient when dealing with various document formats.
AI-powered Receipt Line Item OCR, on the other hand, is a more efficient solution for line item extraction. AI-based OCR harnesses the learning capabilities to not only recognize different document types and data fields but also adapt and learn from diverse document formats, making it the ideal choice for businesses seeking automated line item extraction.
When processing a wide range of invoices and documents from an even wider range of suppliers and service providers, efficiency and optimization are very important. With Machine learning and AI-powered OCR such as Doxis AI.dp, this can be better achieved.
Let’s dive into how Doxis extracts line items from receipts and invoices.
Line Item Extraction from Receipts
Line item extraction is typically used by businesses and organizations in the retail sector and financial administration. For example, as a business in the loyalty sector, you may require your customers to submit receipts to earn rewards or points. Line item extraction and processing provide automated receipt validation, ensuring that customers earning the rewards are valid and accurate purchases.
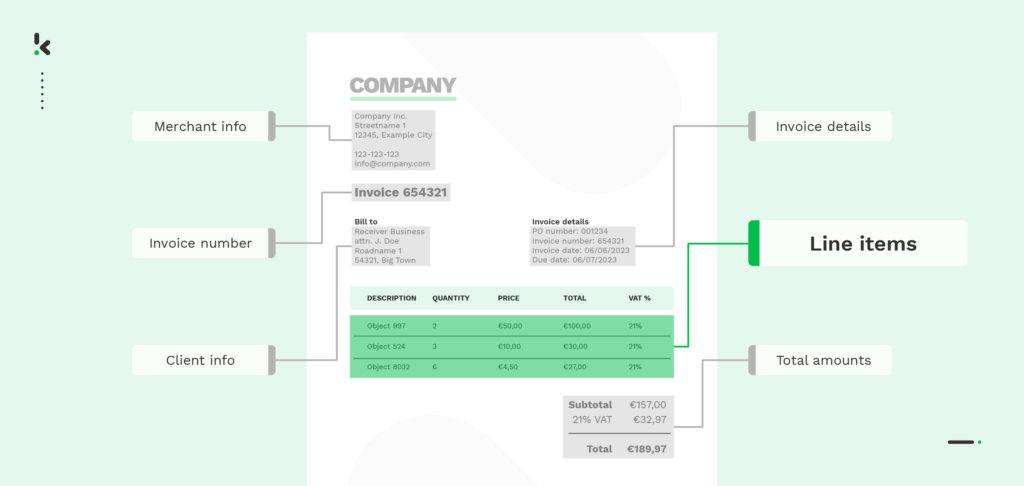
Here is how the process works. You first need a photo or copy of the receipt for processing. Once you have a photo of a receipt, it can be uploaded to the OCR API via mobile, web, FTP, or even email. Once the receipts have been received by Doxis’ OCR engine, it starts performing pattern recognition and layout analysis and identifies that the image is a receipt. Then, Doxis’ OCR software identifies and extracts text from various sections of the receipt, including the individual line items, dates, and merchant information.
Then, it segregates individual line items on the receipt, including product names, quantities, prices, and total amounts. The extracted data is converted into a machine-readable format such as JSON, CSV, XML, etc., using machine learning algorithms. This is then returned as an output from the API to process the receipt in your database or your existing software system easily.
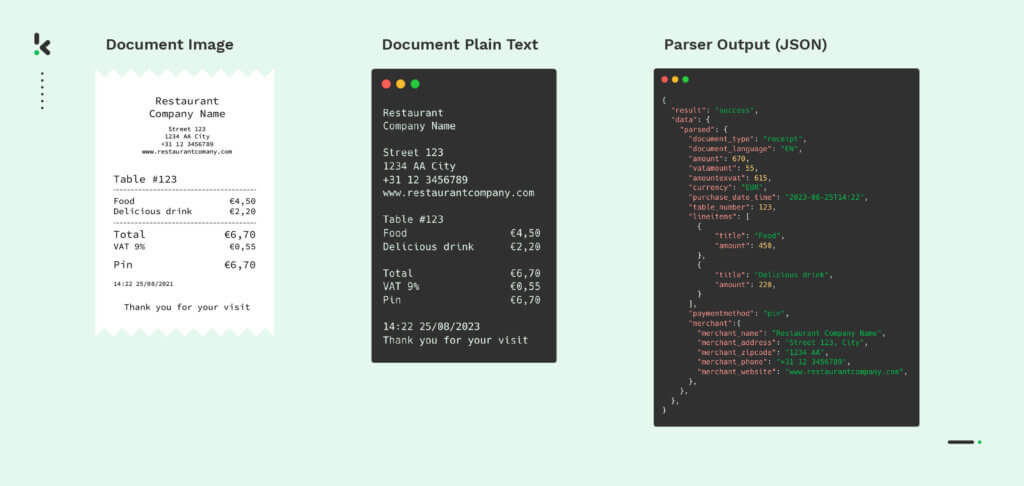
The structured data is then ready for data analytics, loyalty, expense management, and accounting purposes. With these steps, the process of line item extraction and processing is faster, more efficient, and less error-prone than the manual alternative.
Invoice Line Item Extraction
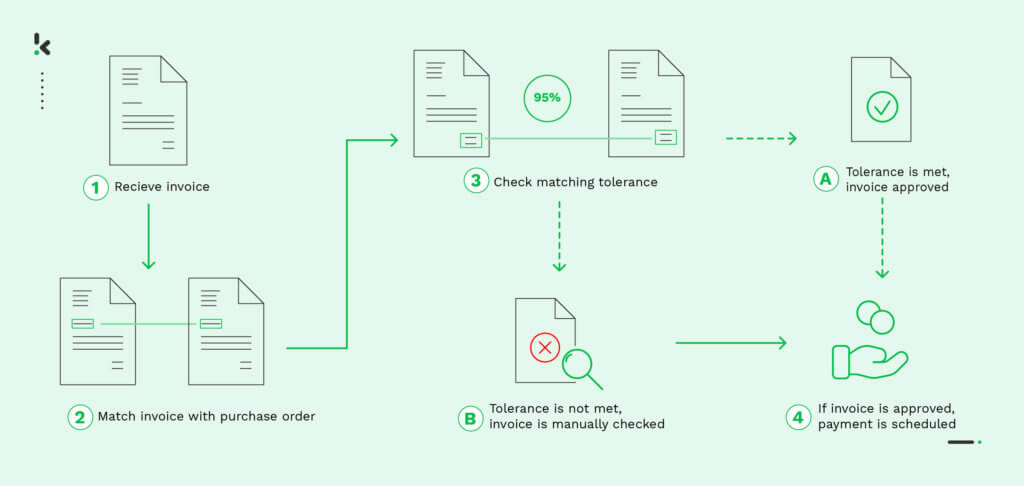
The financial sectors and professionals reap the most benefits of invoice line item extraction. For example, extracting line items accurately is crucial for tracking expenses, validating invoices, and managing accounts payable and receivable. By automating this, you can make the process more efficient, relying less on human intervention and protecting your business from fraud.
The good news is that the scanning and extracting process is quite similar to the receipt scanning process. Once you scan the image or document is scanned and identified as an invoice. After the OCR API scans the document, the relevant information including business names, amounts, phone numbers, and VAT values is highlighted and extracted.
These details are extracted and converted into a machine-readable format such as JSON, CSV, XML, etc ready for you to proceed. At this stage, you can easily process the invoices to check for document fraud through two-way matching for example. Doxis AI.dp for example is embedded with OCR technology that enables it to perform these tasks and more.
These technologies not only save time but also significantly improve accuracy, making them indispensable for businesses managing diverse supplier invoices.
The Benefits of Automated Line Item Processing
So we’ve taken you through the process of line item extraction and the way it works; let’s run through the benefits of automating line item processing.
- Accuracy: Reduce manual data entry errors with automated extraction and recognition, leading to more precise and reliable data.
- Time Efficiency: Save time and resources by automating the extraction of line items from documents, allowing employees to focus on more value-added tasks.
- Cost Savings: Decrease operational costs associated with manual data entry and improve overall efficiency.
- Save Time: Save time using automated document processing, powered by Doxis’ OCR technology, and eliminate manual input and document processing.
- Scalability: Easily scale up or down based on business needs without the need for additional manpower.
- Enhanced Customer Experience: Provide quicker and more accurate responses to customer inquiries and requests.
Potential Challenges in Line Item Extraction
While many solutions claim to offer reliable line item extraction, businesses still face several persistent challenges that often go unaddressed by competitors. Below, we explore these issues and explain how Doxis overcomes them.
1. Handling Unstructured and Inconsistent Formats
Invoices and receipts come in countless formats, layouts, and languages. Many traditional OCR solutions struggle with unstructured data, leading to extraction errors and inefficiencies.
Solution: Doxis’ AI-powered OCR adapts to various document structures using machine learning models trained on diverse datasets. Our technology recognizes different layouts, extracts relevant data fields accurately, and continuously improves through self-learning algorithms.
2. Extracting Data from Low-Quality or Handwritten Receipts
Many businesses receive faded, crumpled, or handwritten receipts, making traditional OCR solutions unreliable. Competitor solutions often fail to extract data from such documents without manual intervention.
Solution: Doxis uses advanced image preprocessing to enhance text clarity, correct distortions, and apply deep learning models that can recognize handwriting with high accuracy. This ensures reliable data extraction, even from poor-quality receipts.
3. Differentiating Between Relevant and Irrelevant Data
Many OCR systems extract too much data, including unnecessary information like footers, disclaimers, and marketing messages, cluttering databases and requiring additional manual clean-up.
Solution: Doxis’ intelligent Natural Language Processing (NLP) filters out non-essential text while accurately identifying critical data points, such as product descriptions, prices, VAT, and payment details. This ensures a cleaner, more structured output with minimal post-processing.
4. Handling Multi-Currency and Tax Variations
Companies operating globally deal with different tax rates, multi-currency receipts, and region-specific invoice formats. Many extraction tools struggle to distinguish between different tax categories or correctly convert currency values.
Solution: Doxis’ system is designed to automatically detect and classify tax types (e.g. VAT, GST) and currency formats. Our AI also supports multi-currency conversion, ensuring accurate financial reporting across international operations.
5. Seamless Integration with Existing Workflows
Many businesses hesitate to adopt new OCR solutions due to poor compatibility with their existing accounting, ERP, or expense management systems. Some competitors offer rigid platforms that require complex API configurations.
Solution: Doxis provides easy-to-implement APIs and custom integrations for platforms like SAP, QuickBooks, Xero, and other enterprise software. Our flexible approach ensures that businesses can automate workflows effortlessly without disrupting existing operations.
Seamlessly Extract Line Items Using Doxis AI.dp
Whether you’re looking to automate expense management, invoice processing, accounts payable processes, or receipt validation for loyalty campaigns, Doxis AI.dp has you covered. AI.dp is an intelligent document processing (IDP) solution that harnesses the power of OCR and various AI technologies to process a wide range of documents.
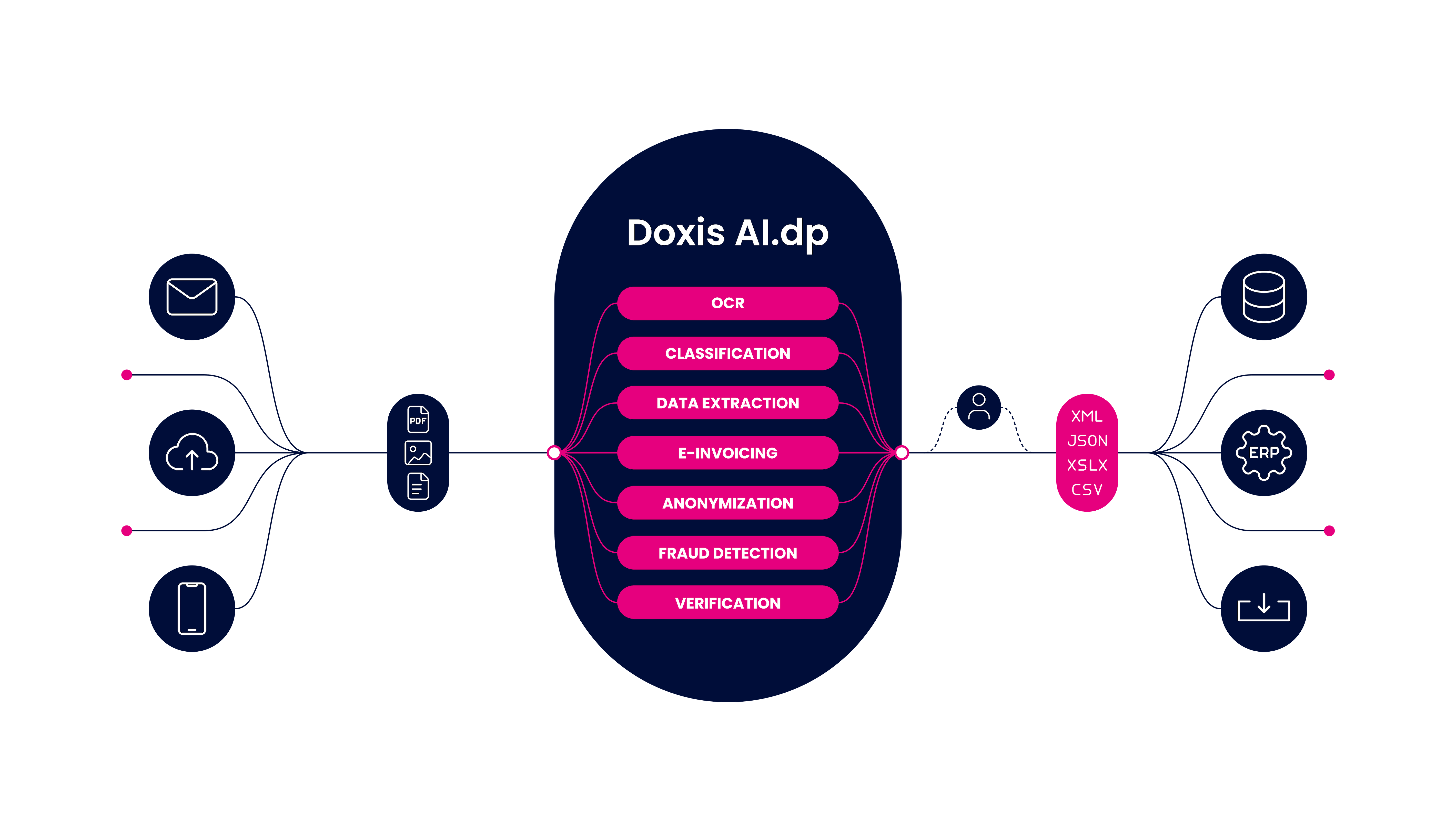
Here are the benefits of using AI.dp:
- Multi-Language Processing: Doxis AI.dp is capable of processing documents in all Latin languages. This ensures flexibility and accessibility, making it an ideal choice for businesses with diverse linguistic needs.
- Accuracy and Efficiency: AI.dp’s advanced OCR technology ensures accuracy in line item extraction and document processing. It minimizes errors, saves time, and improves overall efficiency.
- Automate Document Processing Workflow: With the AI.dp platform, easily set up workflows and automate document-related business processes.
- Streamlined Integration: Seamlessly integrate AI.dp with your existing systems, databases, and ERP solutions to enhance your workflow and maximize the benefits of automation.
- Fraud Detection: Detect document fraud with EXIF and copy-move analysis with smart AI algorithms.
Want to see how Doxis can transform your data extraction? Book a free online demo below!
FAQ
Line item extraction is the process of automatically capturing detailed item-level data from receipts, invoices, and other documents using AI-powered OCR. It helps businesses streamline financial processes, improve accuracy, and reduce manual data entry.
AI-powered OCR scans a document, recognizes structured and unstructured text, and extracts key details such as product names, quantities, prices, and tax information. Machine learning algorithms enhance accuracy by adapting to different layouts and formats.
Using AI for line item extraction offers several advantages, including:
– Faster and more accurate data extraction
– Reduced manual errors and operational costs
– Seamless integration with accounting and ERP systems
– Enhanced fraud detection and compliance.
Yes! AI-driven OCR technology is designed to recognize and extract data from a wide variety of formats, including printed and digital receipts, invoices, and multi-language documents.
Security is a top priority. OCR software solutions often include encryption, GDPR compliance, and secure cloud storage to protect sensitive financial data.
Most solutions offer APIs and integrations with popular accounting, ERP, and document management systems, making it easy to automate data extraction without disrupting your existing processes.
At Doxis, data security and privacy are top priorities. We follow strict security protocols and hold ISO 27001 and ISO 9001 certifications, reflecting our commitment to international standards for information security and quality management. Our solutions are built to comply with key regulations like GDPR and CCPA, ensuring that sensitive data is processed securely and confidentially.
To reinforce security, we conduct regular third-party penetration testing to identify and mitigate potential risks. For more details on our compliance and security measures, visit our compliance page.