
Surely, you must’ve found yourself in need of extracting customer data, financial information, or contact details from PDFs or scanned images. Optical Character Recognition (OCR) and AI technologies have taken the world by storm since they make text extraction from images a breeze. They significantly change the way your business manages data, eliminating the need for paper documents or manual extraction.
Combining the two technologies, you get an Intelligent Document Processing (IDP) solution, which makes the extraction of text from images smooth and accurate. Moreso, all processed documents are automatically classified based on their data, their authenticity is verified to prevent forgery or document fraud and all human-errors are detected and signaled.
In this blog, you will get to know how an IDP solution can help streamline text extraction from images, enhancing your business’s operational efficiency and helping you achieve great results in record time.
Let’s start!
Key Takeaways
- You can extract text from images using AI‑powered OCR to replace manual data entry
- There are 5 main methods for image‑to‑text conversion, from online tools to enterprise IDP platforms.
- Automated text extraction benefits multiple business functions, from invoice processing to compliance documentation.
- Doxis AI.dp can run end‑to‑end OCR workflows, integrating data capture, validation, and export in a few simple steps.
5 Methods to Extract Text from Images
Before diving into Doxis’ enterprise workflow, here are the most common approaches businesses use, each suited for different volumes, compliance requirements, and integration needs.
Method 1: Built‑In Platform Tools (Small Volumes / Quick Tasks)
- Google Drive + Google Docs: Upload image → Right‑click → Open with Google Docs → text appears below the image.
- Microsoft OneNote / SharePoint: Insert image → Right‑click → Copy Text from Picture.
- Best for: One‑off extractions, internal memos, small datasets.
Method 2: Document Conversion to PDF with OCR
- Convert JPG/PNG to PDF → Run through OCR‑enabled PDF readers (such as Adobe Acrobat).
- Best for: Departments already using PDF workflows; simple integration to existing archive systems.
Method 3: Mobile Capture Apps (Field Teams)
- Doxis AI.dp, Adobe Scan, Microsoft Lens, Google Lens: Capture physical documents on mobile, auto‑extract text for upload to CRM/ERP.
- Best for: Logistics checkpoints, field inspections, retail store managers.
Method 4: Web-Based OCR Converters
- Web-based converters that usually allow to: upload → choose format → download text.
- Best for: Occasional use, non‑sensitive data.
- ⚠ Not recommended for confidential or regulated information due to compliance risks.
Method 5: Enterprise OCR & IDP Platforms (High Volume / Compliance Critical)
- Solutions like Doxis AI.dp integrate OCR with business rules, data validation, fraud detection, and system integration.
- Best for: Finance, insurance, healthcare, legal, logistics, manufacturing, government, and other industries where accuracy, auditability, and integration matter.
Pro Tip for Enterprises
Low‑volume image extractions can be done with built‑in tools, but for regulated and high-volume processes, move to a secure IDP platform to integrate OCR directly into your workflows, enforce business rules, and maintain GDPR/HIPAA/ISO compliance.
Use Cases of Extracting Text from Images
Being able to automate data entry by extracting text from images gives your business a head start, regardless of the industry you’re in. Here are only some of the vast examples where extracting text from images comes in handy.
Streamlining Invoice Processing
Many invoices arrive as scanned documents or images. Extracting text from these images enables your business to automate invoice processing, facilitating quicker payments and better financial management. More so, by automatically extracting data from invoices, you can also detect any sign of invoice fraud, so your business can ensure financial transparency and ISO compliance at all times.
Improving Your Document Management
Surely, your business often needs to digitize physical documents for better organization and accessibility. Extracting text from images allows for efficient document management, making it easier to search, retrieve, and analyze information.
With an automated solution for extracting text from images, such as a document scanning software, your business significantly improves its document flow’s efficiency, for any document type, be it invoice, financial statement, or identity card.
Reducing Processing Times for Expense Management
Whether you need to manage expense reimbursements, travel expenses, or mileage tracking, extracting text from scanned receipts or expense reports is a chore. Streamlining these tasks by automatically extracting text from images will facilitate the expense management processes, allowing for easier tracking, reimbursement, and financial analysis.
No matter the use case you have or industry your business is in, opting for an IDP solution to streamline extracting text from images is beneficial. Doxis AI.dp, for instance, helps not only automate text extraction from images, but the whole flow involved in the process. Let’s find out together how to extract text from images with Doxis.
How to Extract Text from Images with Doxis
Solutions like Doxis can fully automate the process of extracting text from documents sent as images. The images can be pictures or PDFs of documents like financial documents, ID documents, and many more. From there, the software takes over handling the text extraction quickly and accurately, without manual intervention.
Let’s walk through the process step-by-step. In this example, we’ll show you how to extract text from receipts stored in Google Drive and automatically extract and convert them into a JSON format.
Step 1: Sign up on the platform
To start, sign up for free on the AI.dp Platform. Enter your email address and password, and then provide details such as your full name, company name, use case, and document volume. After completing the registration, you will receive a free credit of €25 to explore all the platform’s features and capabilities.
Once you log in, create an organization and set up a project to access our services. To extract text from receipts, enable Document Capturing – Financial and Flow Builder to begin. This setup ensures you have everything you need right from the start! If your images are other documents, you can select the appropriate model, such as the Identity Model or Generic Model.
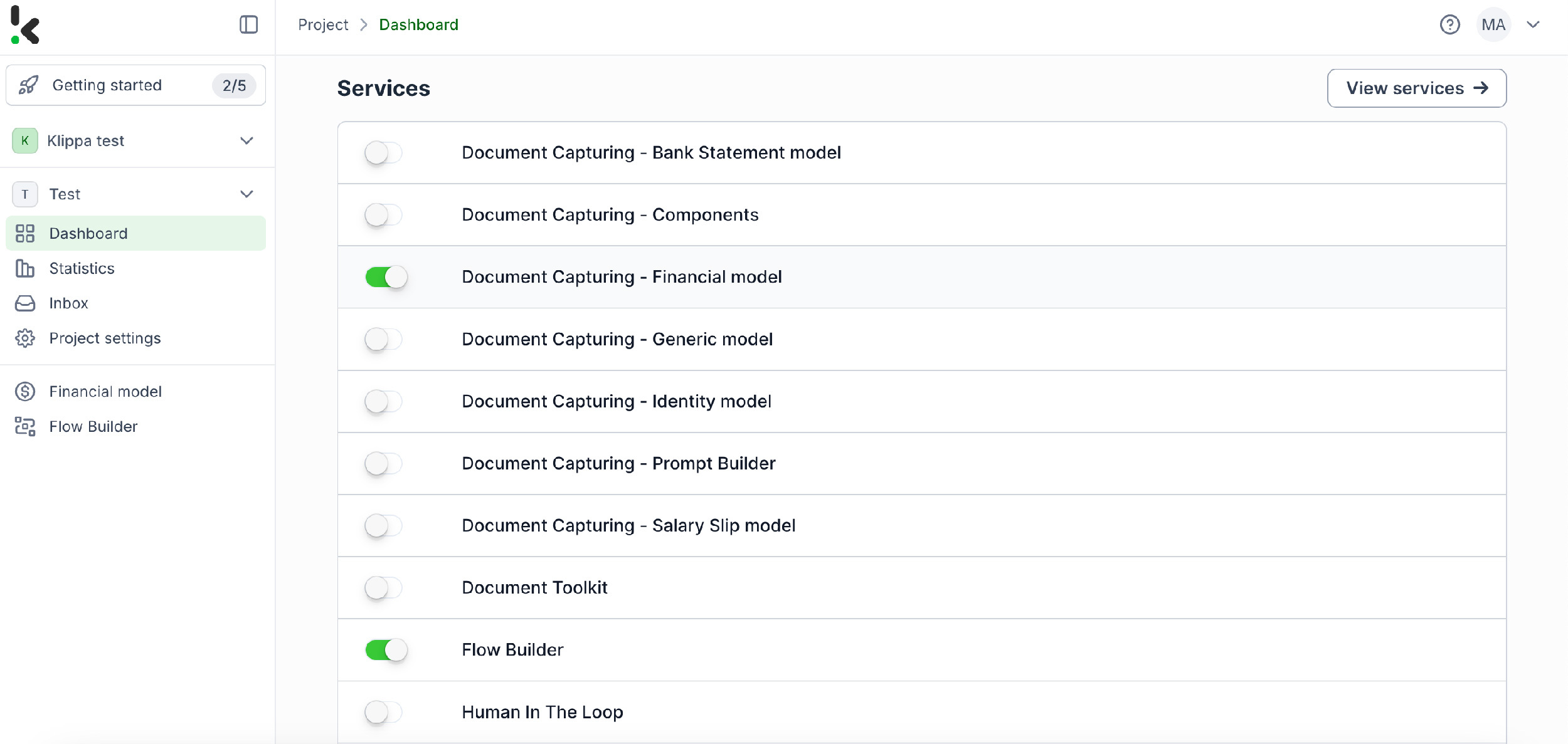
Here is a tip: This example explores how to extract text from a receipt. With Doxis AI.dp, it’s possible to extract text from any document, such as identity documents, invoices, purchase orders, bank statements, and many more. The document capturing service will need to be chosen accordingly.
Step 2: Create a preset
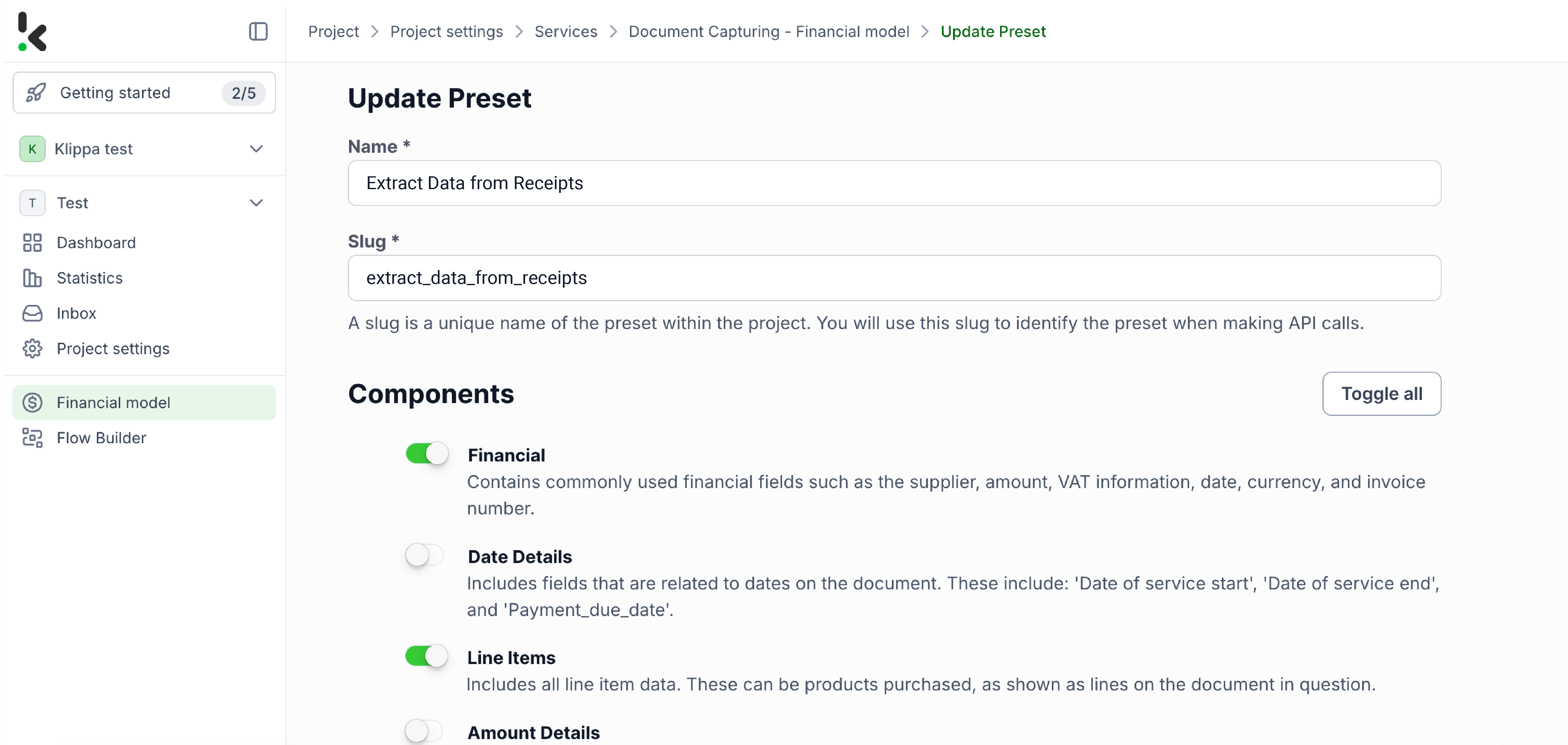
Once activated, you can create a new preset. Let’s name it “Extract Data from Receipts”. This preset lets you activate the components you need for your specific use case. For this case, you’ll enable the financial and line items components to process specific fields in your receipts, such as receipt number, merchant, date, amount, currency, and VAT information.
Here’s a tip: You can personalize the preset further according to your use case by enabling more components such as Date Details, Reference Details, Amount Details, Document Language, Payment Details, etc. You’re almost done! Click “Save” to finalize your settings, and you’ll be ready for the next step in the Flow Builder.
You’re almost done! Click “Save” to finalize your settings, and you’ll be ready for the next step in the Flow Builder.
Step 3: Select your input source
After creating your preset and enabling the Flow Builder, it’s time to build your flow. A flow is a sequence of steps that define how your receipts are processed and transferred to your output destination. In this step, we will choose Google Drive as our input source.
Click New Flow → + From scratch and assign your flow a name. We’ll name the flow “Receipt Data Extraction”.
Here’s a tip: The first step in building your flow is selecting your input source. You have many options: you can upload files directly from your device or connect to over 100 external sources, including Dropbox, Outlook, Salesforce, Zapier, OneDrive, your company’s database, or cloud storage solutions like Amazon S3 and iCloud. Make sure to place all receipts in the same folder so they can be processed in bulk if needed.
For this example, we’ll work with images of receipts such as PDFs. We’ll create a folder named “Input” in Google Drive and upload your receipt there.
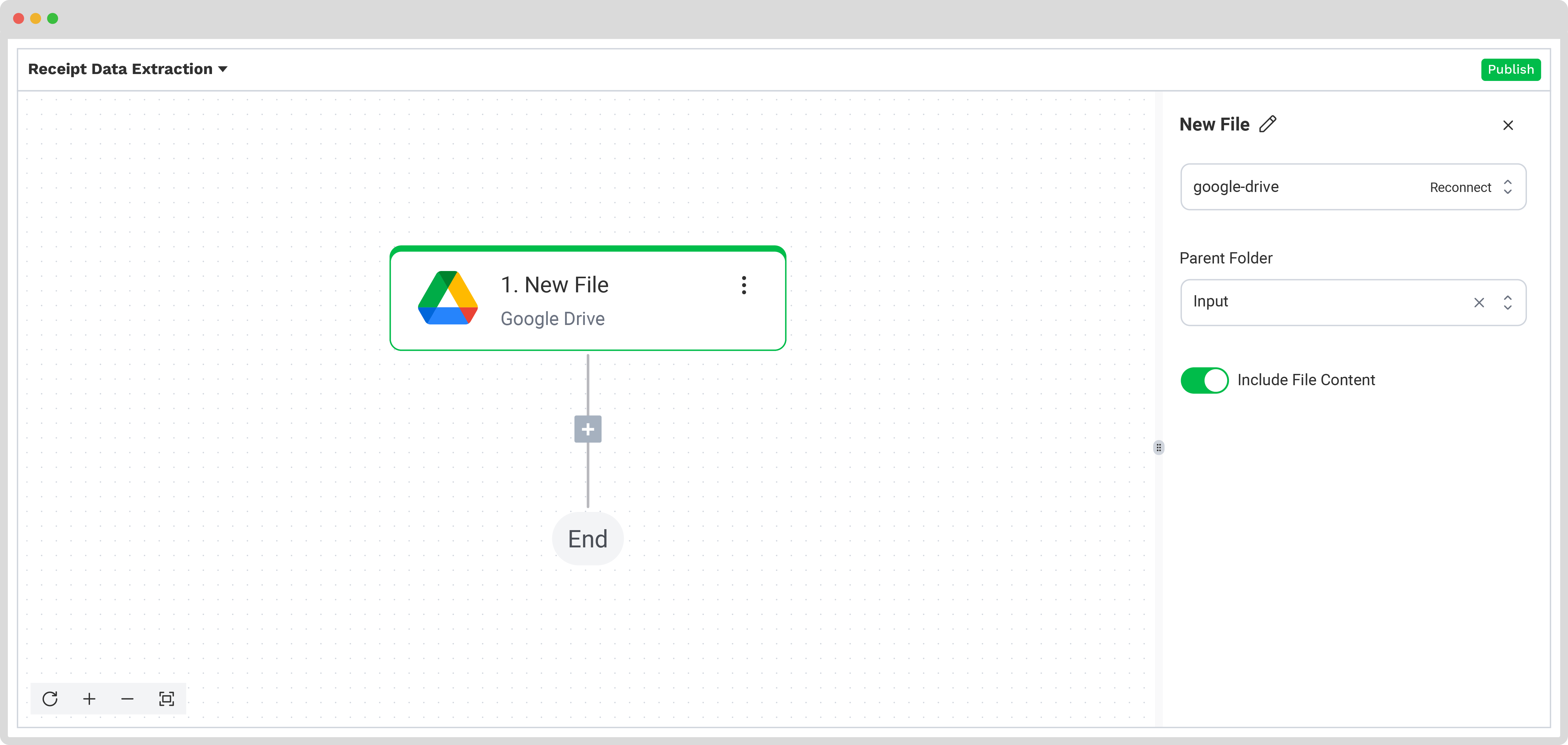
Next, choose your input source by selecting “Google Drive” and then “New File” as your trigger. This is going to start your flow. On the right side, fill out the following sections:
- Connection: You can assign any name to your connection. For instance, we’ve named ours “google-drive”. Once named, the system will prompt you to authenticate with Google.
- Parent Folder: Input
- Include File Content: Check this box to ensure file content is processed.
Test this step by clicking on Load Sample Data: remember to have at least one sample receipt in your input folder while setting up your flow.
Here’s a tip: Since the platform supports a wide range of document types to meet all business needs, you can check our comprehensive documentation to learn more.
Step 4: Capture and extract data
Now, it’s time to extract the necessary text by using the previously created preset to process all the selected data fields from the receipts in the input folder.
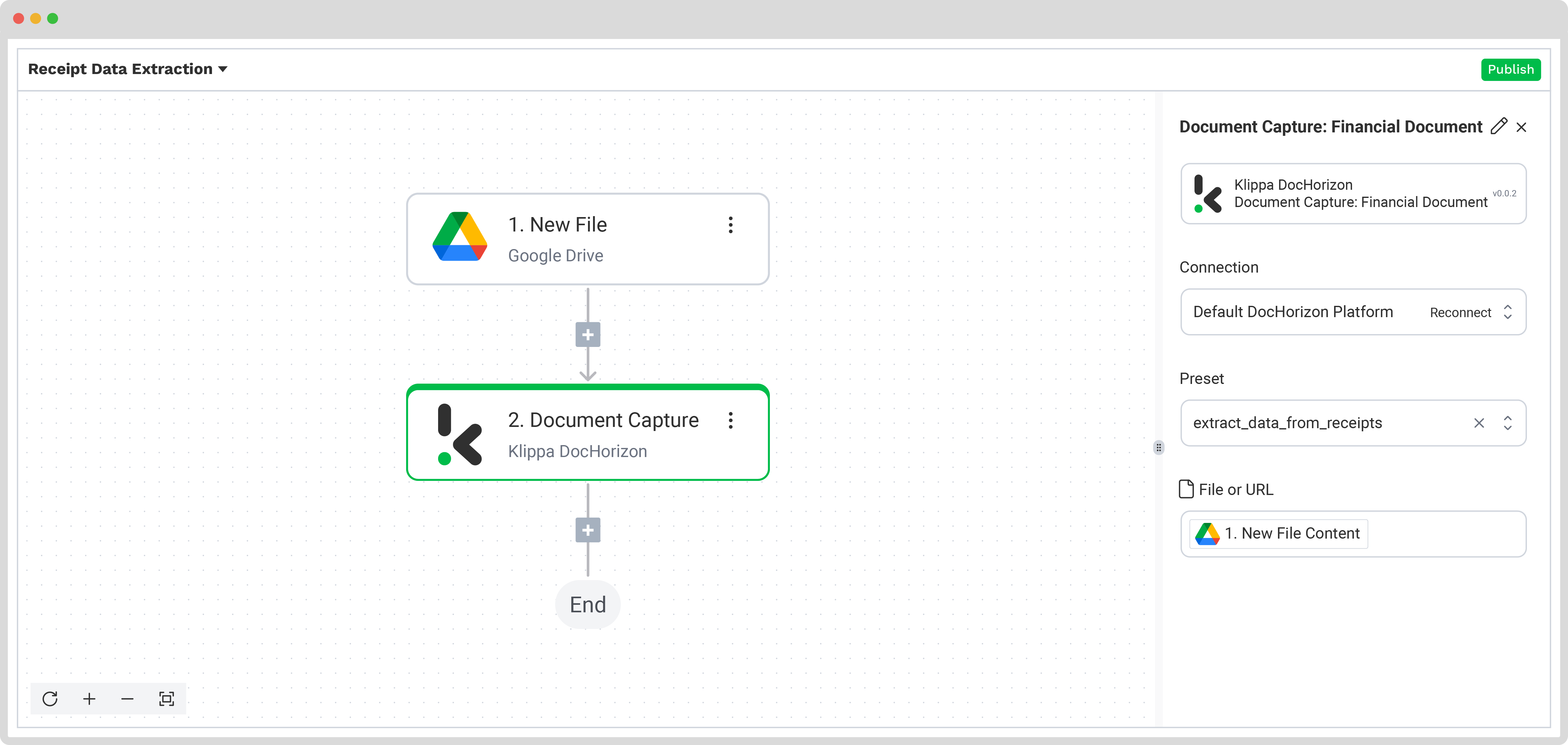
In the Flow Builder, press the + button and choose Document Capture: Financial Document.
To proceed, configure the following:
- Connection: Default AI.dp Platform
- Preset: The name of your preset (in our case “extract_data_from_receipts”)
- File or URL: New file → Content
Then, test the step to ensure everything is working correctly. Once the test is successful, you’re ready to move on to the next step: saving your results!
Step 5: Save the file
Once the receipt is processed, the final step is to choose the destination and the data format for the final output. The destination can be your database, ERP system, accounting software, or any other platform depending on your workflow. The data output format can be chosen from JSON, XML, CSV, XLSX, UBL, PDF, or TXT.
For this example, we will set the receipt number as a file name with the extracted data and save it in JSON format. We will create a new folder in Google Drive, name the output folder “Output”, and set it as a final destination for our file with the extracted data.
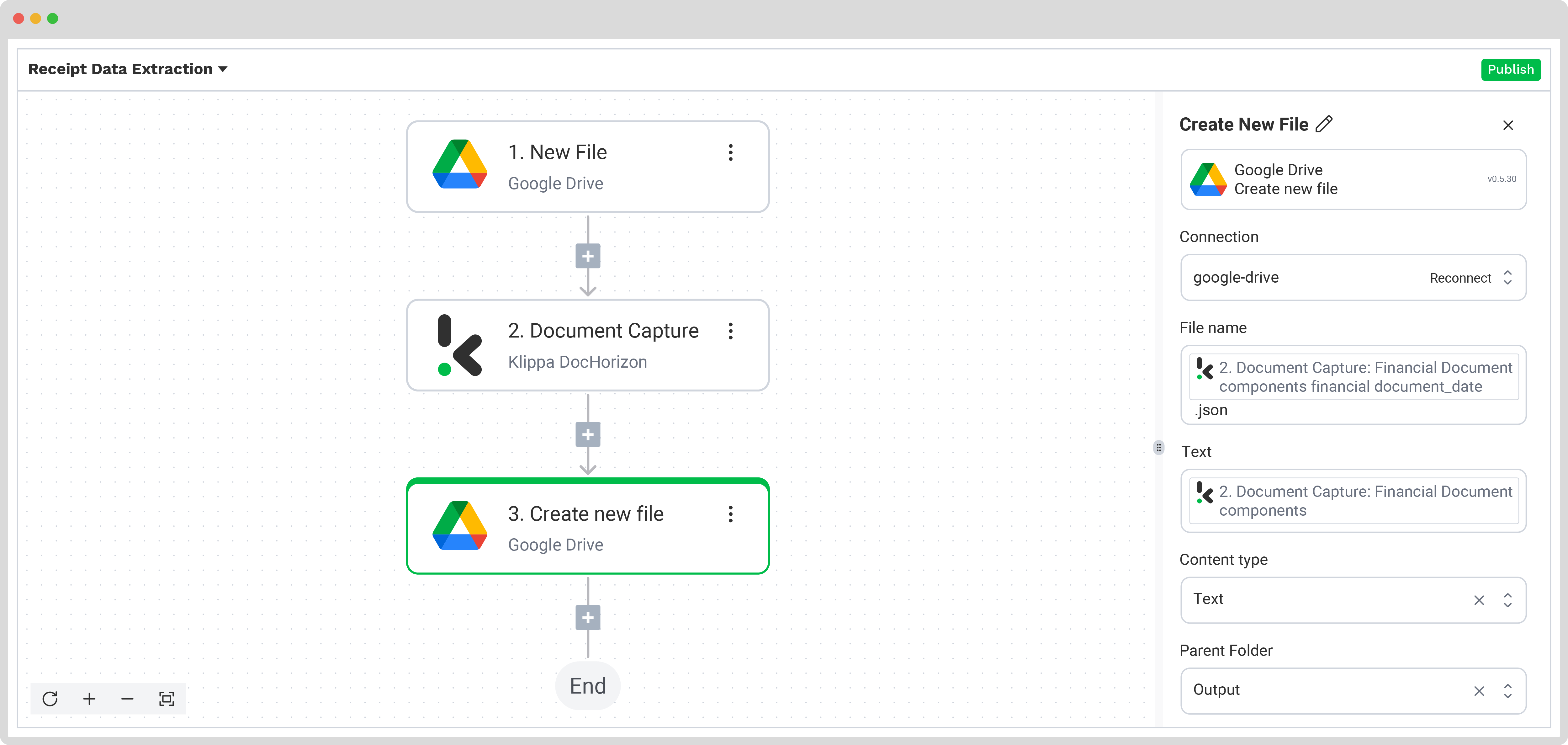
Press the + button and select Create new file → Google Drive
To proceed, configure the following:
- Connection: google-drive
- File Name: Document Capture: Financial Document → components → financial → receipt_number. Next to it, type .json
- Text: Document Capture: Financial Document → components
- Here’s a tip: Select the text you want to include in the new document. By selecting “components” you choose all the extracted elements.
- Content Type: Text
- Parent Folder: Output (the name of your output file)
Test this step by clicking the button at the right bottom, and you’re all set!
Congratulations! All the receipt data is now available in your Google Drive folder. With this setup in place, you can publish the flow, and any new receipts added to the folder will be processed automatically. That’s how you can save time while ensuring accuracy in your workflows.
And remember, if you simply don’t have time or you don’t have much technical experience, don’t worry! Feel free to reach out to us because we’d love to help you out!
Effortlessly Extract Text from Images with Doxis AI.dp
With Doxis AI.dp, extracting text from images is smooth and accurate. Our IDP platform gives you the ability to:
- Extract text from multiple document types, from invoices and receipts to contracts and resumes
- Save precious time by extracting text from images in bulk, by uploading up to 100 documents in one go
- Extract signatures and handwritten text from documents, so you can easily extract the entire text from an image
- Custom-select the text you want to extract from images, choosing specific key-value pairs
- Extract text from images from all languages based on the Latin alphabet
If you’re curious to see our Doxis AI.dp solution in action, try out our free, image-to-text converter. Be the witness of Intelligent Document Processing capabilities and discover how our software accurately extracts and processes data in no time!
Do you want to make the most out of your data and automate text extraction from images? Contact our experts for more information or directly book a free demo down below!
FAQ
The best way to extract text from images is by using AI-powered OCR solutions. Tools like Doxis AI.dp automate the process by scanning documents, recognizing key details (merchant, date, amount), and converting them into structured data.
It is difficult to convert images to text:
1. Scanned images don’t contain any text that can be selected and then extracted.
2. Often, images are not clear enough and the quality is low. Then it becomes very difficult for the OCR to read out the text.
3. Furthermore, when the format of a document differs and has variations, it becomes difficult for the OCR to detect the important fields.
Despite the difficulties, OCR software is able to extract text from images in a faster, more accurate and cheaper way than when done manually.
Yes. Doxis offers a free trial with €25 in credits, allowing you to explore the platform’s features and capabilities before deciding.
Absolutely. Doxis complies with global data privacy standards, including GDPR. Your data is encrypted, securely processed, and never shared with third parties without your consent