Data is gold in today’s data-driven environment, and without care, it’s easy to feel overwhelmed by the endless streams of information in your business. Most likely, like many other businesses, you are faced with the challenge of transforming the daily influx of information from varying sources into valuable insights. Emails, letters, and internal documents pile up and create a maze that demands navigation, extraction, and analysis.
The question then becomes, how to make sense of it all? The secret lies in automated data extraction. In this blog, we will guide you through the ins and outs of data extraction, explaining how it works, and outlining the benefits of automating this process. Read on!
What is Data Extraction?
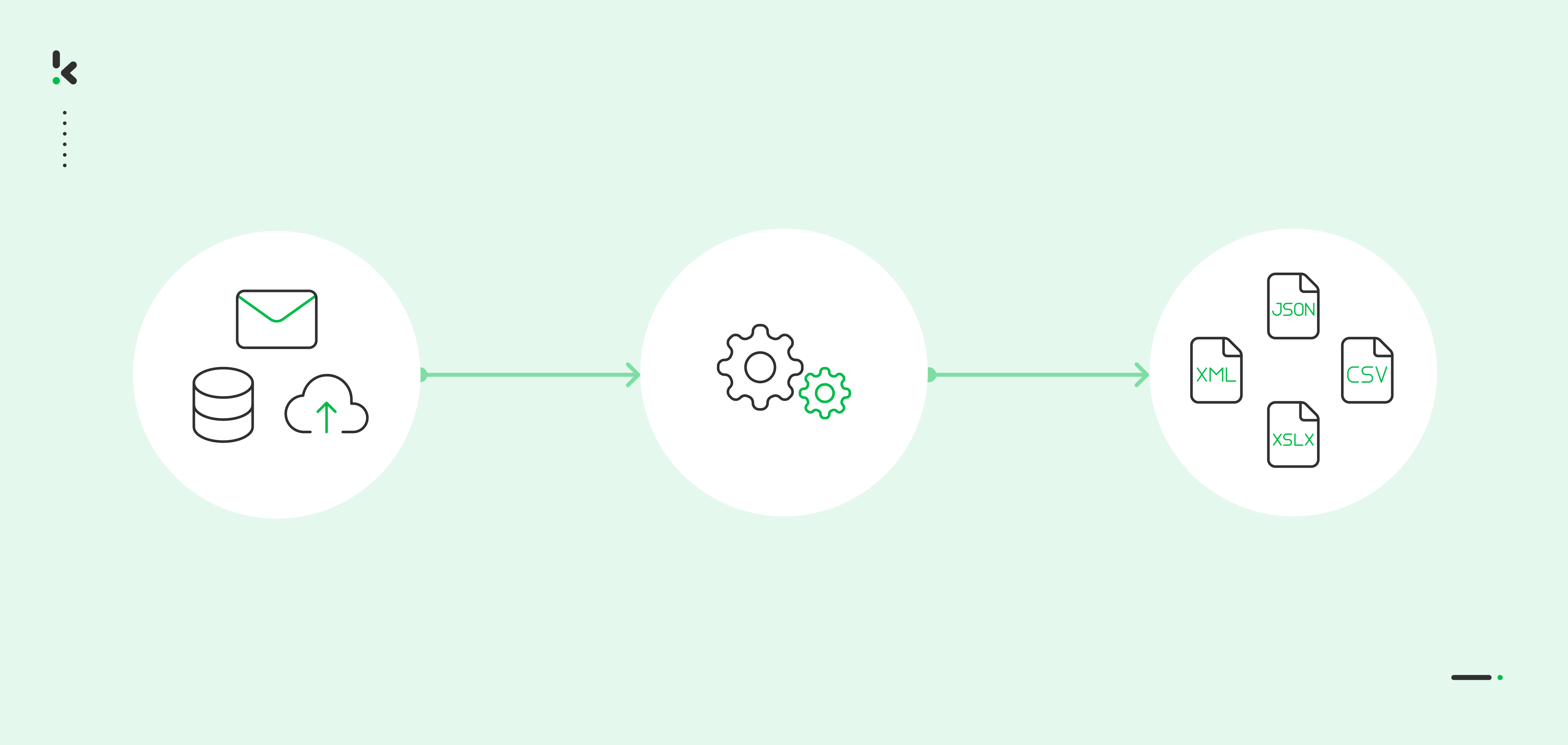
Data extraction refers to the process of gathering and processing structured and unstructured data from a range of sources (eg. databases, emails, or APIs), and transforming it into a preferred machine-readable format such as JSON, CSV, and XML. The data can then be processed and used in the software of choice.
This makes data extraction an essential first step in the Extract/Transform/Load (ETL) process, which is widely employed in business intelligence and data warehousing. Efficient and reliable data extraction is the cornerstone for accurate and well-prepared business information analysis, enabling you to derive useful insights and access your data effectively.
Types of Data in the Data Extraction Process
To help you understand data extraction better, let’s take a closer look into the most common sources of data and what makes each of them unique.
- Structured data: Structured data refers to highly organized and formatted information with a clear, predefined data model. Examples include data in SQL databases, Excel spreadsheets, and CSV files.
- Unstructured data: Unstructured data, on the other hand, has no predefined data model and does not conform to a rigid structure. Examples include emails, PDF documents, and multimedia content.
- Physical sources: They encompass various types of physical documents such as paper documents, printed reports, invoices, receipts, purchase orders, and other manually created sources.
- Digital sources: Digital sources refer to data generated or stored in digital formats. Digital sources can include databases, digital documents, multimedia files, and any data that is electronically generated, processed, and stored.

The different types of data and sources determine the most effective data management and extraction processes. The nature of the data and its source influences the methods used for extraction, analysis, and utilization in various applications.
Now we have established what the different types of data are, we can dive into the role data extraction plays within and outside of the ETL process.
Data Extraction and ETL
The ETL process is a common method for integrating, transforming, and storing data from multiple sources for analytical purposes. It ensures your data is consistent, accurate, and ready to reveal meaningful insights. Here’s a breakdown of how it works:
- Extract: In the ETL process, data extraction involves retrieving data from source systems which include databases, applications, files, or other repositories. This phase identifies and pulls the relevant data needed for analysis or reporting.
- Transform: After the extraction, the data may transform to ensure it conforms to the desired structure, format, or quality standards. Transformations can include data cleansing, aggregation, enrichment, and other operations to prepare the data for analysis.
- Load: Once the data is extracted and transformed, it is loaded into a destination system, often a data warehouse or a database optimized for analytical queries. Loading involves placing the prepared data into the target system for efficient storage and retrieval.
Data Extraction without ETL
Not every organization needs data extraction to follow the ETL framework. In scenarios where immediate access to raw data is enough, and extensive transformation is unnecessary before analysis, data extraction without ETL is a suitable approach. Here’s a glimpse into how it works:
- Direct Extraction: In some cases, data extraction may occur without the intermediate transformation and loading steps of ETL. This approach involves directly pulling data from source systems and using it for immediate analysis or reporting. By implementing OCR (Optical Character Recognition), for example, it’s possible to extract data from PDFs, images, and scanned documents.
- Use of APIs (Application Programming Interfaces): Data extraction without ETL can involve direct API calls to source systems. APIs allow for structured communication between different software applications, enabling the extraction of specific data subsets. OCR technology can also be integrated into this process, extracting text or data from images or documents accessible via APIs.
- File-Based Extraction: Another method involves extracting data directly from files, such as Excel spreadsheets, CSV files, or other structured data formats. This approach is common when the data is already in a suitable format for analysis.
The approach of direct data extraction may offer simplicity and speed for certain use cases. However, it may not provide the comprehensive data integration and transformation capabilities that are typically offered by ETL processes. Choosing between ETL and direct extraction depends on your specific business goals and the purpose of data extraction.
Why is Document Data Extraction Important?
Let’s paint a picture. Imagine you’re a bank, processing mortgage applications to potential homeowners. The law requires you to perform KYC and AML checks, checking the buyer’s source of income, etc. For this, the buyers must submit a range of documents including bank statements, identity documents, proof of income, and more. This information has to land in your database, or decision-making system.
Often the data is unstructured and would require manual data processing and extraction. A person or your team member has to manually verify the submission of the document, extract the information, and upload it to a specific platform. Not only is this a time-consuming process, but it can also prove to be a tedious task error-prone, and lacks efficiency. Additionally, manual document extraction is often inaccurate and difficult to scale.
However, with automation, many of these pitfalls can be largely avoided and organizations can welcome accuracy and efficiency to their operations. With AI-powered data extraction software, for example, these processes are faster, more efficient, more accurate, and more secure, allowing businesses to comply with regulatory requirements and safeguard their organizations.
Types of Data Extraction
There are two different techniques regarding the extraction of data: logical and physical extraction. Let’s dive into both of them and explain what they mean.
Logical Extraction
Logical data extraction involves using querying and reporting tools, along with SQL queries, to efficiently retrieve targeted data from databases. When websites lack direct APIs, web scraping and parsing HTML are employed to obtain usable data for analysis without modifying the source directly.
Logical extraction can be divided into two subtypes.
- Full extraction: Retrieves all available data at once, typically used for initial data extraction and loading.
- Incremental extraction: Captures changes in the source data since the last successful extraction, and extracts only the updated information.
Physical Extraction
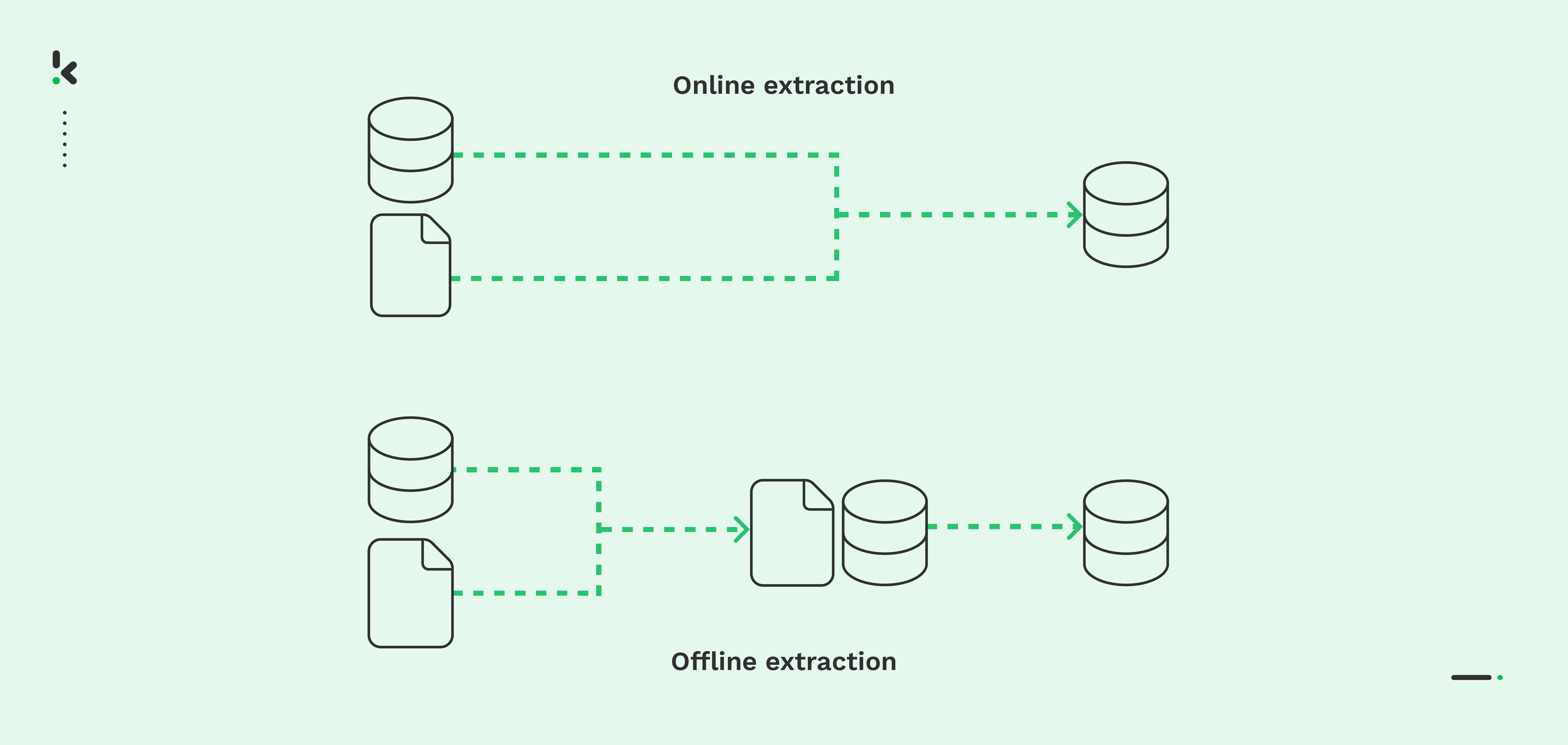
Physical extraction is a data extraction method that retrieves information from sources where logical extraction proves challenging. This technique can be categorized into two main types: online and offline extraction.
- Online extraction: There is a direct connection between the source system and the final archive. With the method of online extraction, the extracted data is more structured than the source data.
- Offline extraction: The actual data extraction takes place outside of the source system. In offline extraction processes, the data is either structured by itself or it will be structured through extraction routines.
Methods of Automated Data Extraction
So, what types of document data extraction methods can be used to automate this process? These methods are often categorized into 3 groups as they provide a different type of service and purpose.
- Batch processing tools: These can be valuable if your company needs to transfer large volumes of data from outdated sources. They simplify the management of legacy in-office data but have limitations when dealing with real-time processing of more complex data sources.
- Open-source tools: These are software solutions whose source code is available for anyone to inspect, modify, and distribute. This can be useful if your company is tech-savvy and has internal expertise to implement and customize extraction solutions to fit your specific needs.
- Cloud-based tools: These are known for their ability to swiftly and reliably extract data in large volumes, often complemented by intelligent document processing features. These tools are beneficial if your company operates with multiple document formats or sources in different languages.
Overall, cloud-based intelligent data extraction methods stand out due to their unmatched scalability and seamless integration capabilities. However, each category of data extraction tools has its unique advantages, allowing you to choose the solution that best suits your needs.
Automated Data Extraction Business Use Cases
Automated document extraction can be used in a variety of business scenarios. In this section, we will go over 6 use cases and explain how automation can help you improve these processes.
- Invoice and Receipt Processing: Automated data extraction streamlines invoice and receipt processing, collecting item details, prices, dates, and vendor info. This saves time, minimizes errors in data entry, and enhances expense tracking for accurate financial reporting.
- Email Parsing: With intelligent data extraction, you’re able to automatically parse emails to extract sender details, subject lines, dates, and specific data from emails. Businesses utilize this for streamlined communication, actionable insights, and automated workflows. For instance, automating order information extraction from emails updates inventory or customer records without manual intervention.
- PDF to Excel Extraction/Conversion: PDFs, like reports and contracts, are common document formats. Extracting data from PDFs for conversion into structured formats, like Excel sheets, improves accessibility and analysis. You can leverage this to swiftly transfer data from diverse PDFs into a standardized, analyzable format, enhancing accuracy and efficiency with large information volumes.
- Onboarding Automation: Automated data extraction facilitates seamless digital onboarding processes for both customers and employees by extracting relevant information from identity documents for KYC (Know Your Customer) purposes and HR documentation for employee onboarding. This ensures compliance while expediting the onboarding process, enhancing user experience, and reducing manual errors.
- Automated Data Entry: Data entry tasks can be automated using extraction techniques, eliminating the need for manual input of information into systems. This not only saves time but also reduces errors associated with manual data entry, leading to improved data accuracy and operational efficiency.
- Bank Statements to Excel Conversion: Converting bank statements from a PDF or other formats to Excel is valuable for financial analysis and reporting. Businesses must often analyze transactional data, reconcile accounts, or generate financial statements. Automated extraction of data from bank statements to Excel simplifies these tasks, allowing for quicker and more accurate financial analysis.
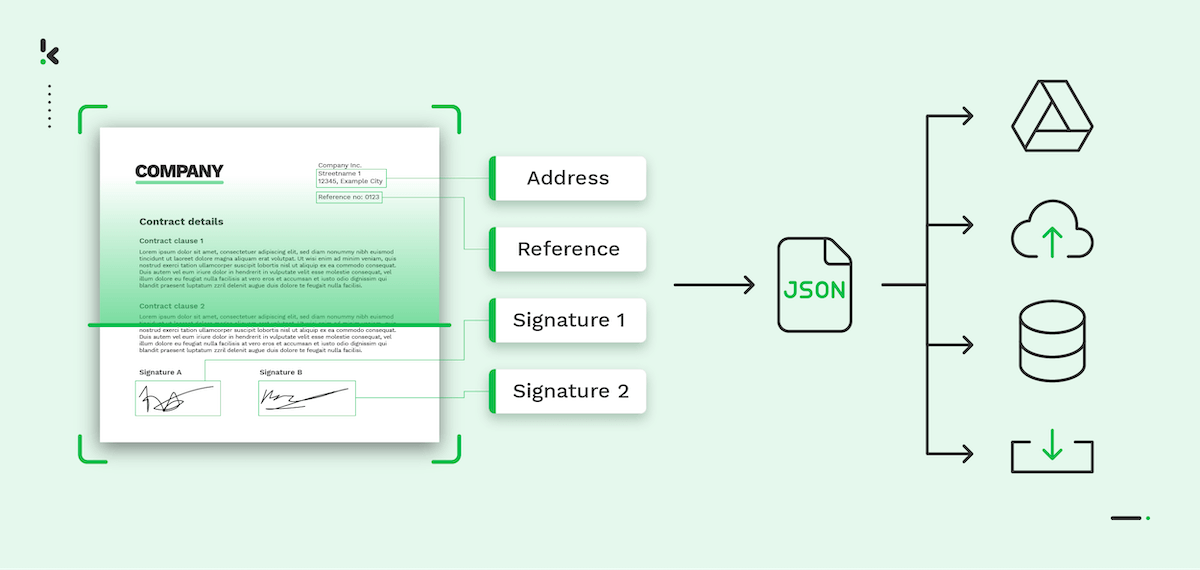
- Contract Data Extraction: Extracting key data from contracts is important for businesses to mitigate risks, optimize workflows, and make informed decisions. For example, contracts often include clauses and obligations that, if missed, can lead to costly disputes. Contract data extraction and automated processing reduce errors and lead to better decision-making.
Essentially, data extraction plays a crucial role in various business processes by automating the retrieval of valuable information from diverse sources, improving efficiency, reducing errors, and enabling better decision-making. Luckily, there is a range of ready-to-market solutions available to implement automated data extraction techniques into your business like Klippa DocHorizon.
Automate Data Extraction with Klippa DocHorizon
Klippa DocHorizon is an Intelligent Document Processing solution that takes away the burdens of manual document data extraction with the help of OCR and AI-powered technologies. With our solution, you can easily extract and process data from a wide range of documents for different purposes to enhance accuracy and efficiency.
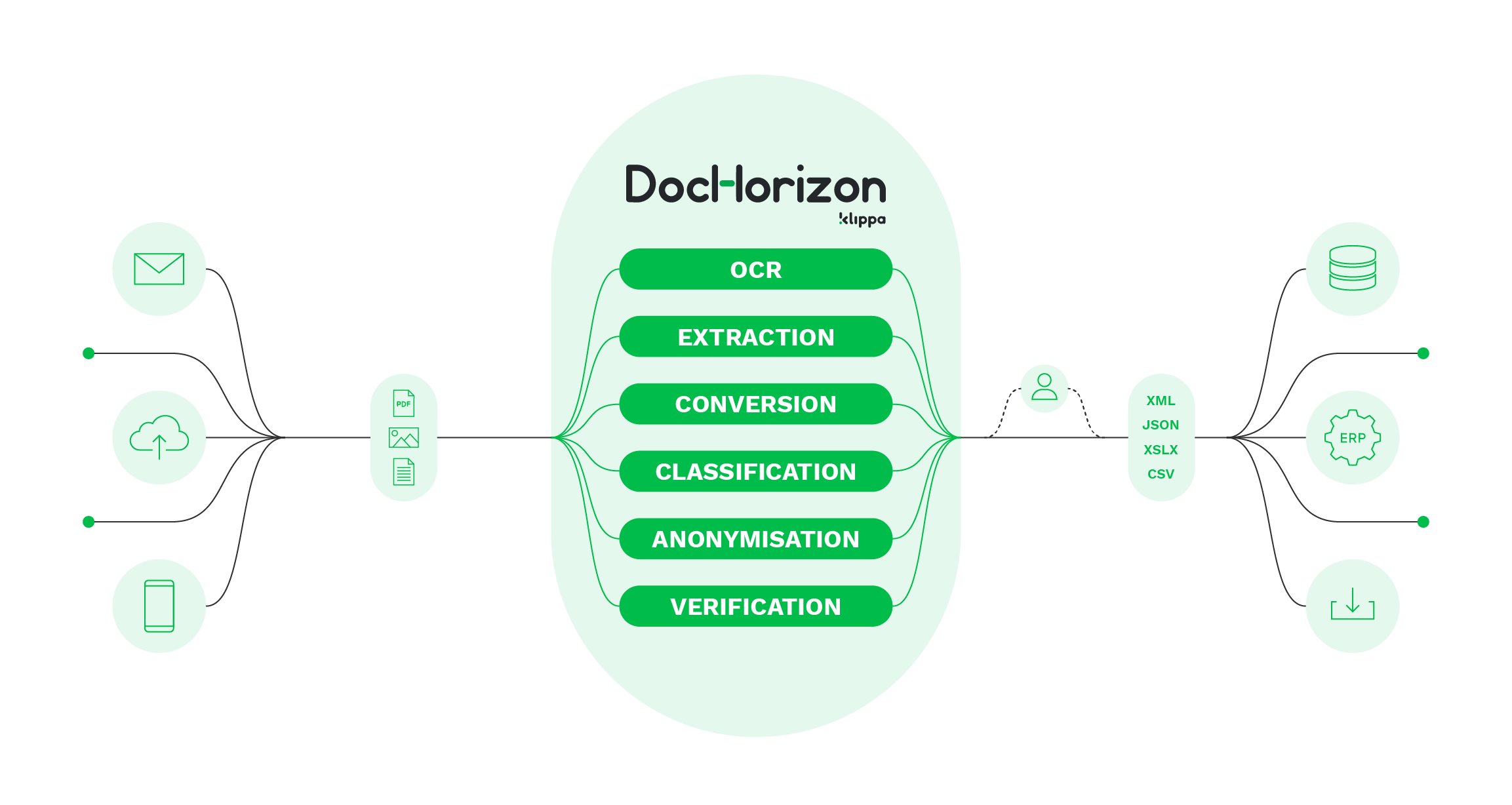
Data extraction has never been easier with Klippa DocHorizon and here’s how it works.
- Upload the document: Documents or data sources are submitted, enabling transformation into a digital format through photo, scan, or PDF uploads.
- Image to TXT: OCR technology extracts and transforms submitted image text into a TXT file, capturing all data from the document but without structural organization.
- Parsing to JSON: A parser reads and comprehends the text in the TXT file, converting it into a structured JSON file, and facilitating database processing; additionally, output options include XML, XLSX, and CSV formats.
- Verify the extracted data: We can verify the extracted data with third-party sources for example internal company databases or Chamber of Commerce databases and anti-money laundering lists.
- Seamless integration: After extraction and validation, files can easily be sent to the database or system of your choice for further processing.
In addition, with our platform, you can easily create custom workflows to process the extracted data in the manner most useful to your business. Easily convert, classify, and automate document processing workflows in your organization.
Curious to find out how Klippa’s solution can help with your data extraction? Book a free online demo below or contact one of our experts for more information!