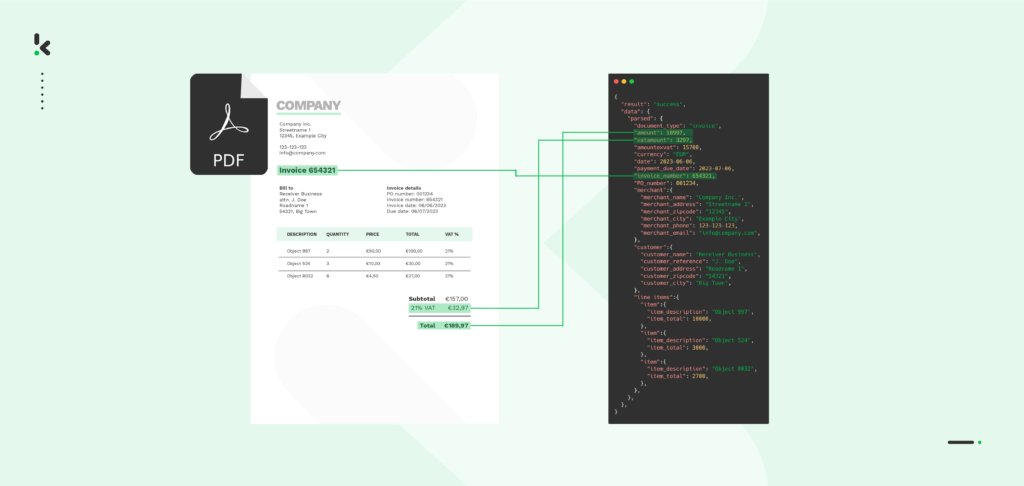
Whether your business is in the financial or retail industry or any public sector institution, you’ve probably realized that PDFs hold the most important information. However, they are designed to be human-readable, making their unstructured nature a big challenge when it comes to processing these documents with software applications.
One way to swiftly retrieve all relevant information from your PDFs is with PDF scraping. To do so, your business can opt for AI-powered platforms capable of automating PDF scraping workflows. In this blog, you will get to know the ins and outs of PDF scraping and learn how to make scraping data from PDFs part of your business processes.
Let’s start!
Key Takeaways
- PDFs contain key business data, but they’re not machine-friendly – Their unstructured format makes it hard for software to extract information automatically.
- PDF scraping transforms documents into usable data – Extract specific fields and convert them into structured formats like JSON, CSV, or Excel.
- Klippa DocHorizon automates the entire scraping process – Set up a fully customizable flow in just a few steps, no coding required.
- Exported data integrates easily with your tools – Send scraped data directly to cloud storage, ERPs, CRMs, or accounting systems with zero hassle.
What is PDF Scraping?
PDF scraping is the process of extracting data from unstructured documents in a PDF format and transforming it into a structured one, such as Excel, JSON, or XML. This technique is used to capture only selected information or data fields from a PDF.
That makes PDF scraping essential for businesses that want to make data-driven decisions. The extracted PDF data can easily be read and utilized by business software such as ERPs, CRMs, and accounting software, or major databases.
Challenges of PDF Scraping
As we just mentioned, scraping data from PDFs isn’t without its hurdles. The main challenge comes from the format’s versatility – or lack of it. PDFs contain text, images, and tables, which makes uniform data scraping a quite complex process.
Additionally, the difference in the quality of PDFs, especially when it comes to scanned documents, adds another layer of difficulty to PDF data scraping efforts. If the quality is lacking, the exported information might present errors, mistakes, or missing information.
Due to the many variations in structure, PDF scraping is most commonly done in two main ways: the good old copy-and-paste method and manual data entry. Both of these methods interfere with the document’s layout and formatting, messing up most of the information. Not to mention, it takes a large amount of time to search the document, type the information of your interest, and go on, page after page.
Thankfully, technology has a solution for it once again. Instead of wasting time, energy, and resources on scraping PDF data manually, your business can benefit from an automated solution. Let’s get more detailed on how to scrape data from a PDF with an Intelligent Document Processing platform, such as Klippa DocHorizon.
How Automated PDF Scraping Works with Klippa
Klippa DocHorizon is an intelligent document processing platform that helps your business streamline document-related workflows, such as PDF scraping. In just 5 very easy steps, you can set up a very unique flow, completely customized to your business’s needs and use case.
No complex setup. No coding.
And the best part? You can get started for free!
Here’s how it works, step by step.
Step 1: Sign up on the platform
To get started, sign up for free on the DocHorizon platform. All it takes is your email, a password, and a few basic details about your use case. Our user-friendly interface makes it easy to interact with the platform, so you don’t have to worry about any obstacles.
Once you’ve signed up, you’ll receive €25 in free credits to explore the platform’s features. These credits allow you to run real document processing tasks – no strings attached.
After signing up, create an organization within the platform and set up your first project to access the available services. Because you want to scrape data from PDF files, enable the Document Capture: Financial Model and the Flow Builder.
The Financial Model is a pre-trained extraction model optimized for invoices, so it’s perfect for this use case. If you get stuck, don’t worry – check out our documentation or video tutorials for additional guidance.
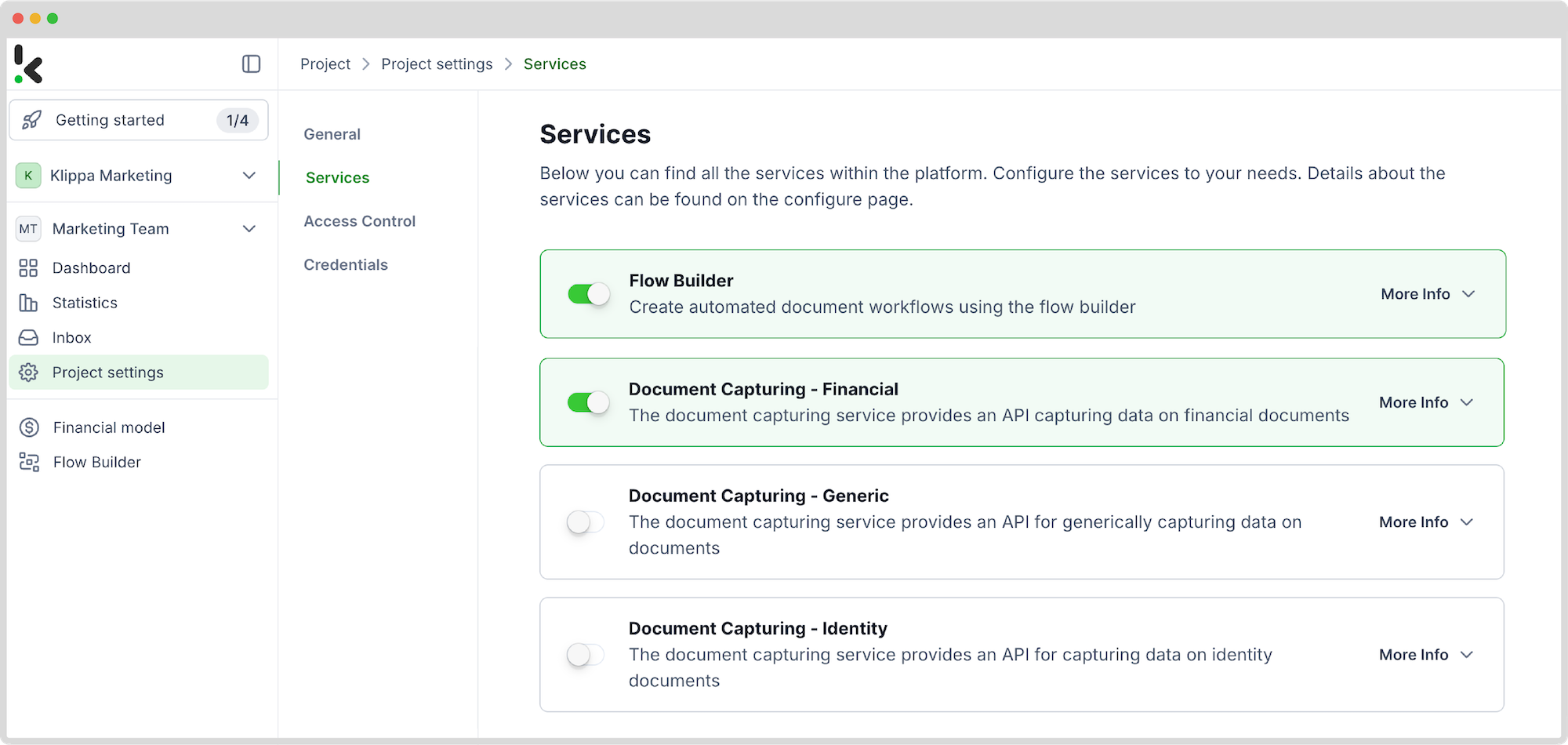
And just like that, you’re ready to roll with document processing!
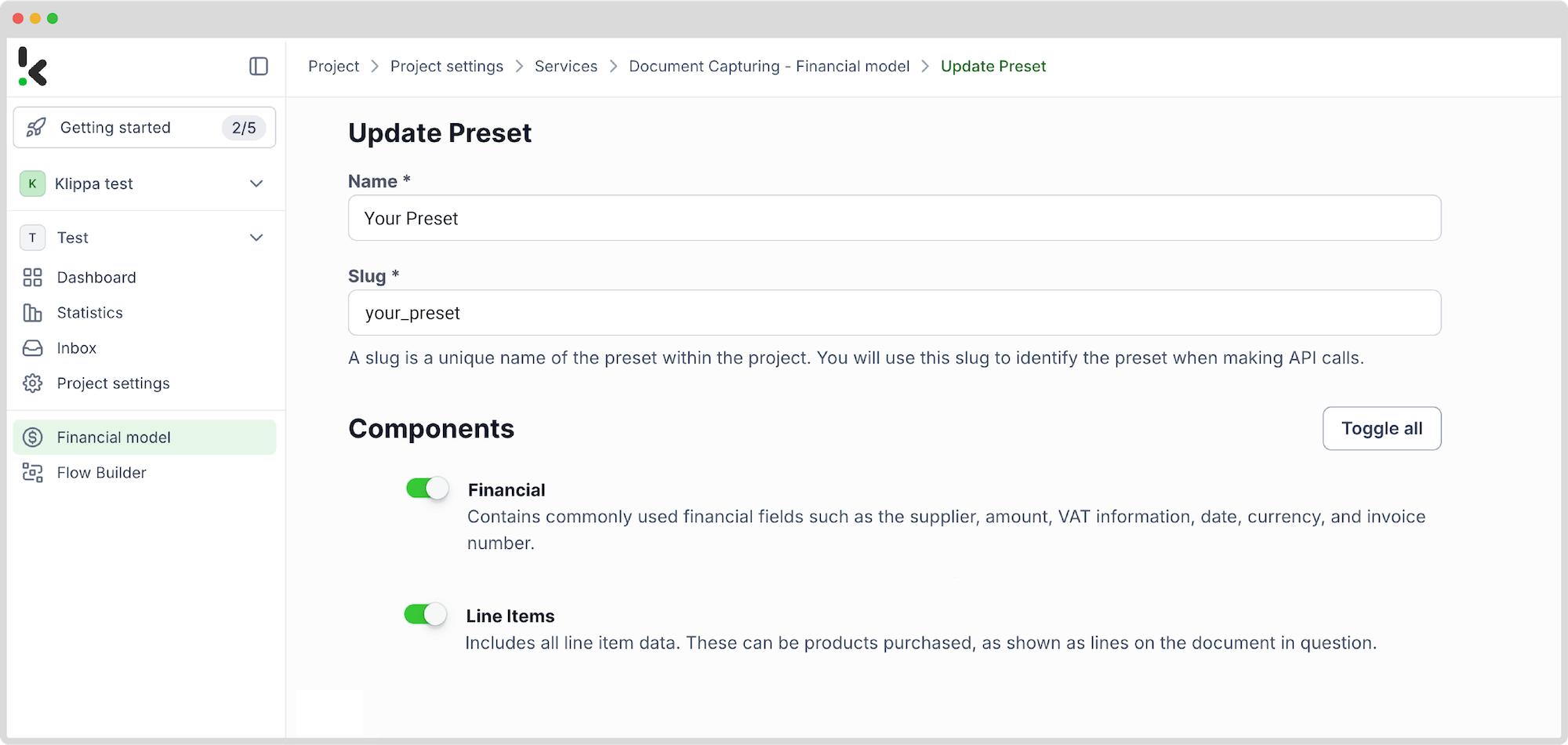
Step 2: Create a preset
Next, you’ll define exactly what kind of data you want to scrape from your PDFs by creating a preset. This is essentially a configuration that tells the platform which fields to extract from incoming documents.
Choose from multiple data fields you want to scrape and simply select them in the preset.
Setting up a preset is easy: click on the Financial Model within the DocHorizon platform, create a new preset, and name it. Choose from multiple data fields that you want to scrape and simply select them in the preset.
Once configured, click Save. This preset ensures that every PDF processed through your flow will be scraped consistently and accurately.
With your custom preset in place, you’re ready to proceed to the next step: building your flow for automated data extraction.
Step 3: Select your input source
Now that your preset is ready, let’s create a flow in the Flow Builder. A flow is a sequence of steps defining how your PDF files are processed and how their data is scraped.
Start by navigating to the Dashboard, clicking Flow Builder, and then New Flow. You can choose a ready-made template or build from scratch – for full customization, we’ll go with the + From Scratch option.
To get the flow started, you need to select the input source. With Klippa DocHorizon, you can choose from retrieving a document from your Drive, parsing it from an email attachment, or an existing application used in your business.
For this example, let’s connect to Google Drive. Select New File, connect your Google account, and choose the Parent folder where your invoices are stored.
Important: check the Include File Content box to ensure that the system reads the document data, not just the metadata.
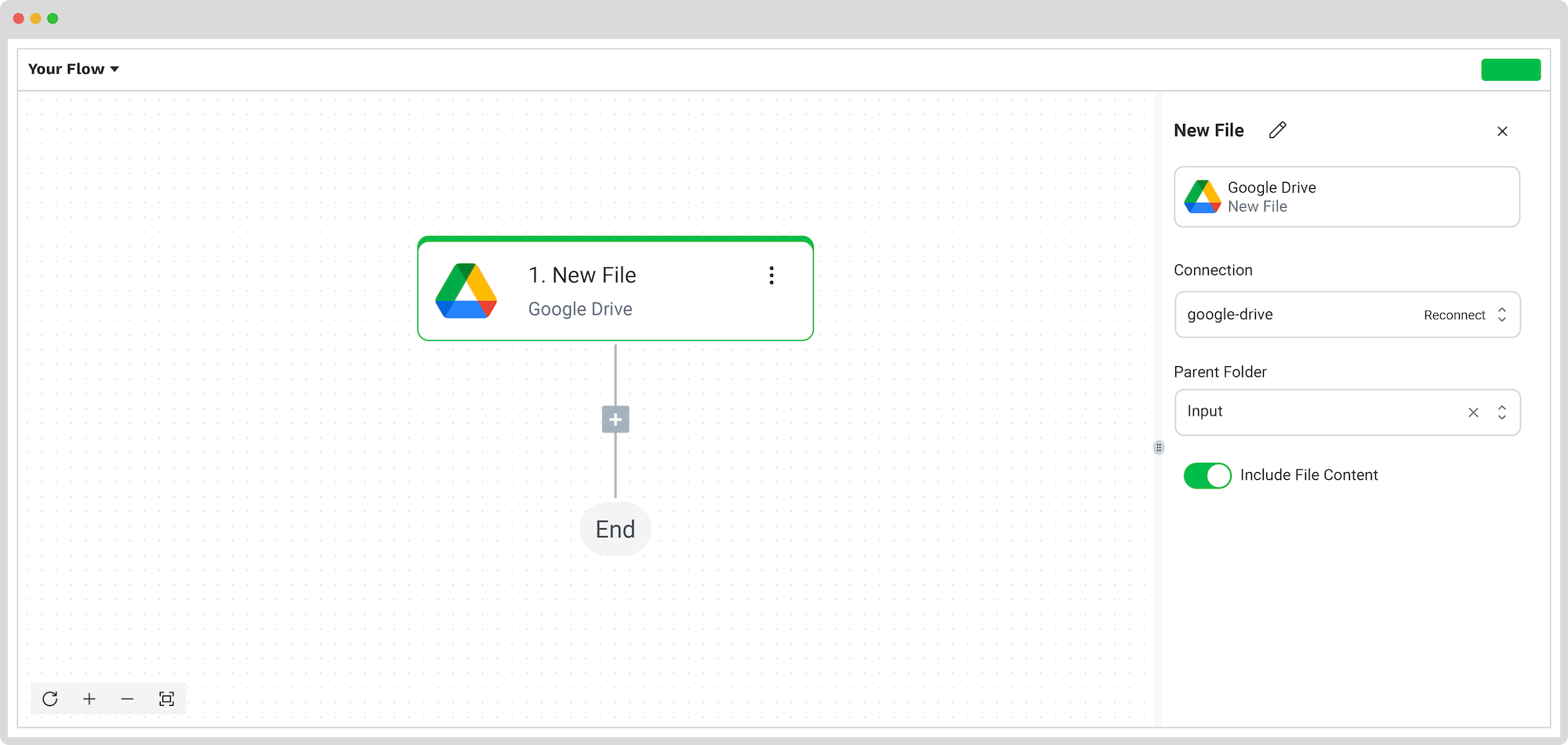
Test the input step and the following ones with a sample document to verify that everything works as expected.
Step 4: Capture and extract data
Next, it’s time to scrape data from your PDF invoices. Add another step by clicking the + button and search for Klippa DocHorizon -> Document Capture: Financial model. Connect it to DocHorizon and link it to the preset you created in Step 2.
Then, configure the flow to process the actual content of the PDF by selecting New File -> content in the File or URL section.
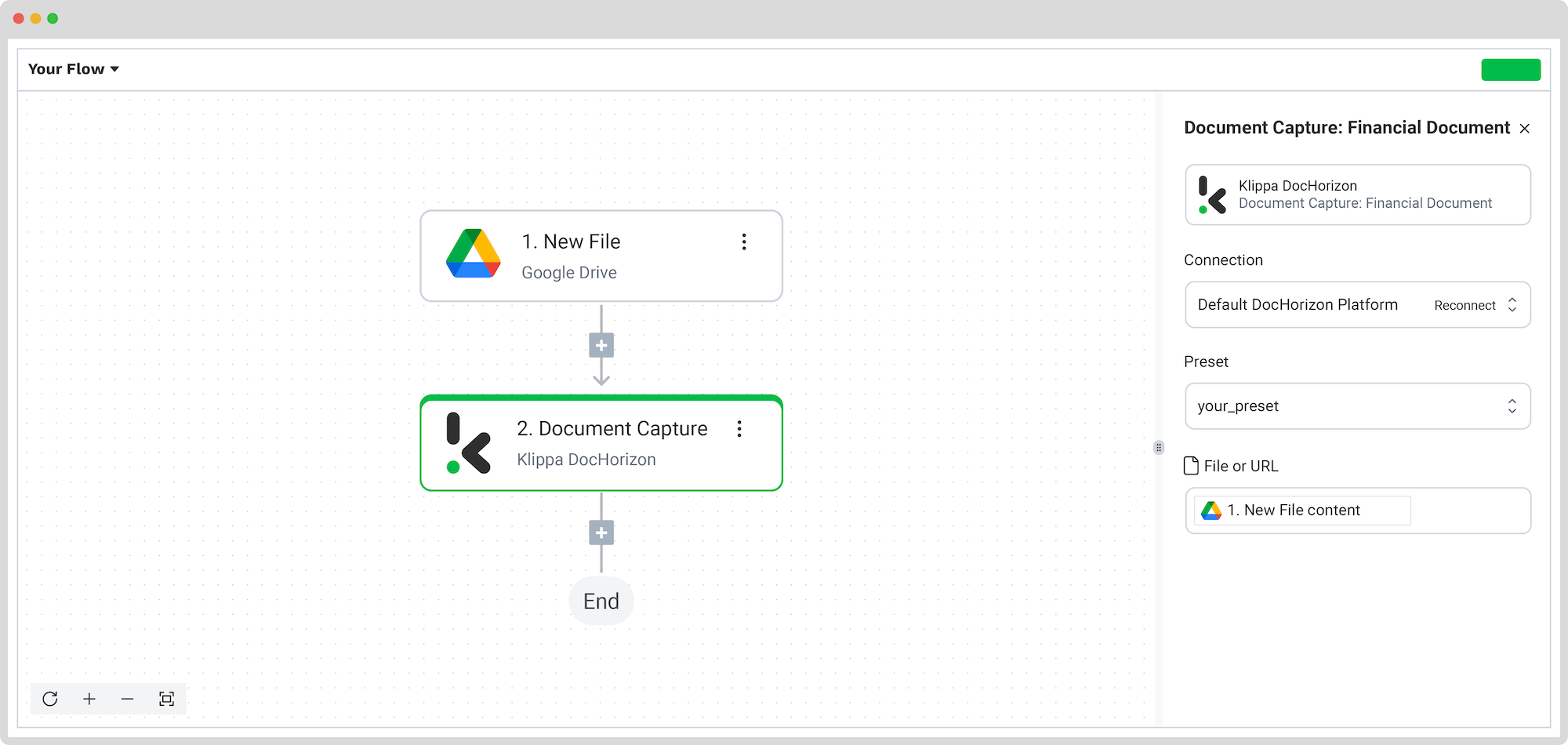
Run a quick test to confirm that Klippa is extracting the fields correctly. If you see the expected results, great! You’re ready to move on.
Step 5: Set Up the Output Destination
With your flow taking shape, the final step is to define where the processed data will be sent.
Klippa lets you export the results in flexible formats like JSON, CSV, or Excel and send them to various destinations: cloud storage (e.g., Google Drive, Dropbox), ERP systems, accounting platforms, APIs, or webhooks.
For this walkthrough, let’s use Google Drive. Choose Create New File, connect your Drive account, and give the file a dynamic name by clicking on the box to open the Data Selector menu and navigating to Document Capture -> components -> financial. From there, choose any component as the file’s name.
Then, configure the content: select the extracted components by navigating to Document Capture: Financial Document -> components and include all relevant fields.
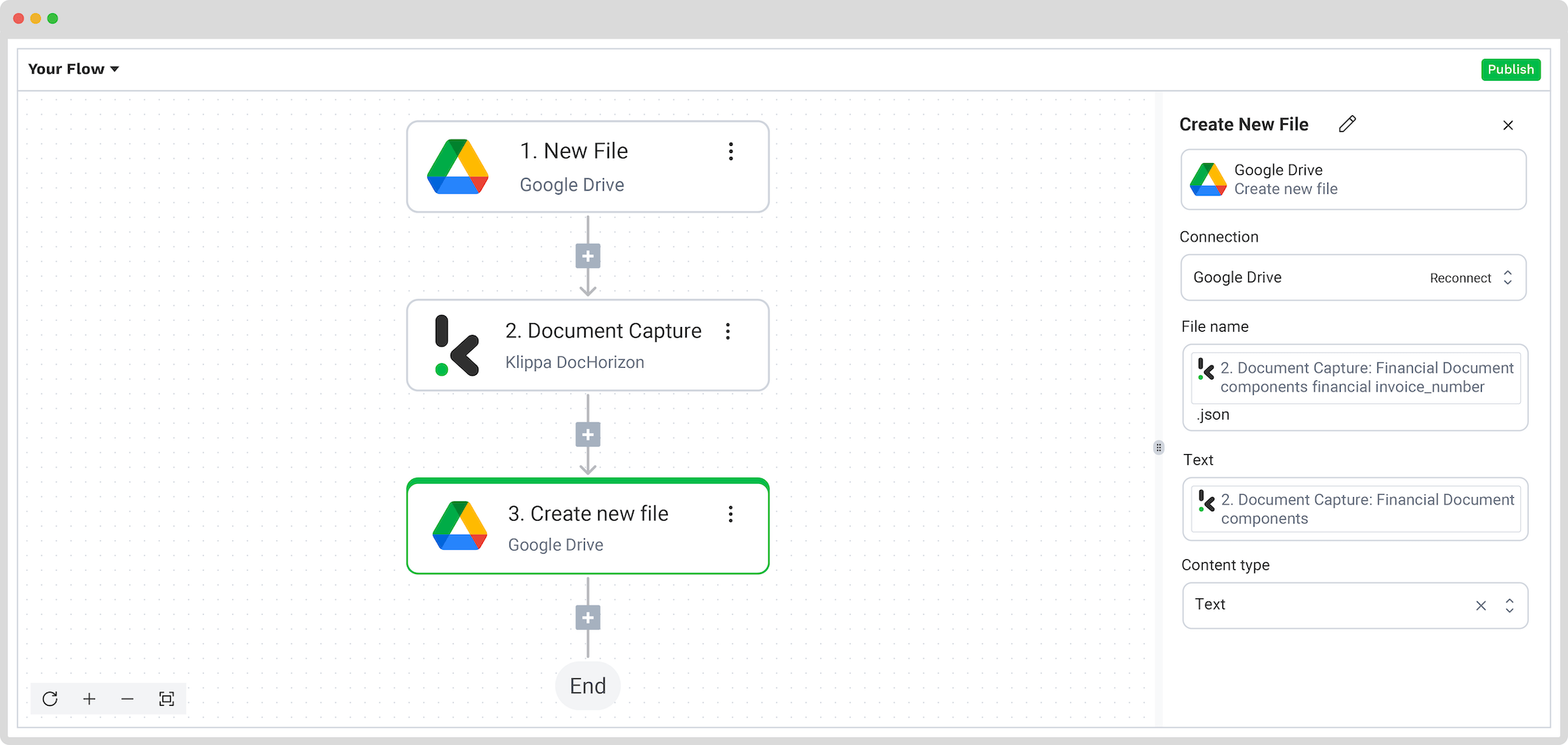
Finally, test the entire flow to confirm everything is functioning as expected.
And that was it! Once everything is set up and tested, your automated PDF scraping flow is live and ready. From now on, every new PDF dropped into your input folder will be processed, scraped, and exported without manual work.
And remember: if you’re processing a high volume of documents, you don’t have to set up the flow yourself! Feel free to reach out to us because we’d love to help you out!
Benefits of Scraping Data from PDF
Scraping PDF data, especially if it’s done automatically, brings a lot of benefits to your business:
- Improved Efficiency and Time Savings: Automating PDF scraping significantly reduces manual labor and processing time. Get accurate results in an instant and forget about the tedious process of manual data entry.
- Enhanced Accuracy and Consistency: Minimize human error and ensure data uniformity across documents. Your employees don’t need to deal with inconsistencies in reporting data or processing documents.
- Scalability and Standardization: Easily process large volumes of PDFs while maintaining data consistency. Moreover, you can process bulk PDFs, so you can ensure that all of the information corresponds to each PDF.
- Integration into Existing Systems: Export scraped data to various formats for easy integration into your current systems.
Knowing how to scrape data from PDFs can bring lots of advantages for your business, no matter the industry. Curious to learn about some real-life applications of PDF scraping? Keep reading!
Real-Life Applications of PDF Scraping
Streamlining Document Workflows in Financial Industries
Financial professionals deal with the daunting task of managing an extensive amount of documents, including bank and credit card statements, mortgage applications, and compliance paperwork.
With Klippa’s automated solution for scraping PDF files, financial institutions significantly enhance their document processing capabilities. This solution helps increase accuracy, reduce processing times, and ensure compliance with regulatory standards.
Optimizing Patient Records and Insurance Form Processing
Healthcare providers often face challenges in managing medical prescriptions and insurance forms, resulting in delays in patient care and complications in billing processes.
Klippa’s solution transforms healthcare document management by automating PDF scraping of patient records and insurance forms. This enables faster and more accurate processing of patient data, leading to better healthcare document processing and streamlined billing operations.
Enhancing Inventory and Supplier Invoice Management
Retail businesses frequently deal with complex shipping labels and supplier invoices. Not to mention, since the majority of invoices and delivery confirmations come in a digital format, it can become very easy to lose track of all incoming documents.
By implementing Klippa’s IDP platform for scraping PDF files, retailers can achieve greater accuracy and efficiency. This solution ensures that inventory levels are accurately updated, and supplier invoices are processed promptly, as well as making sure there is no sign of invoice or vendor fraud.
Streamlining Supply Chain Document Processing
In the manufacturing sector, managing supply chain documents, including purchase orders and shipping labels, can be overwhelming and eventually lead to operational delays or disruptions.
Klippa’s automated document workflow helps you streamline supply chain document management by streamlining PDF data scraping. This enables your manufacturing team to maintain smooth operational workflows, ensuring timely production and delivery.
To be able to see powerful results in your document management, it’s better to go above and beyond and automate the full PDF scraping flow, not just a part of it.
Fully Automate PDF Scraping with Klippa DocHorizon
Klippa’s solution seamlessly streamlines the PDF scraping process, soon making it a standard practice for any of your business workflows.
Regardless of your industry or use case, automating the process of scraping data from PDF with Klippa DocHorizon enhances operational efficiency and empowers you to focus on core activities. By employing our platform, you benefit from:
- Global document coverage, including documents in all Latin-alphabet languages
- Time-saving practices with our bulk-processing option
- Unlimited document support with our prompt builder
- Ensured data privacy and security through our ISO and GDPR compliance
- Ensured onboarding and maintenance support
- Automated document classification
- Up to 100% accuracy in the workflow thanks to our HITL feature
- Clear documentation and instructions
Dealing with PDF documents manually is history’s tale. Join our DocHorizon platform and fully automate your PDF scraping flow. Contact our experts for more information or book a free demo below!
FAQ
PDF scraping is the process of extracting specific data from unstructured PDF files and converting it into structured formats like JSON or Excel, essential for automating workflows and making data usable across systems.
Yes, but you’ll need an OCR (Optical Character Recognition) solution. Standard scraping won’t work on image-based content without OCR technology.
Our pre-trained models are built to recognize a wide range of document formats. Even if your PDFs vary in layout, Klippa can accurately identify and extract key fields using AI-powered components.
Security is a top priority. Klippa is fully compliant with GDPR and ISO 27001, and we use secure, encrypted servers in the EU. You stay in control of your data at all times.