
Als je ooit hebt geprobeerd om je eigen Machine Learning-modellen of algoritmen te ontwikkelen, of van plan bent om dat te gaan doen, ben je misschien een veelvoorkomend obstakel tegengekomen: het verkrijgen van voldoende gegevens die divers genoeg zijn om je model effectief te trainen.
Gelukkig bieden synthetische gegevens een oplossing voor dit probleem.
Nu AI-projecten steeds vaker voorkomen, wordt de noodzaak voor het genereren van synthetische data steeds duidelijker. Een studie van Gartner voorspelt zelfs dat in 2024 60% van de gegevens die worden gebruikt voor de ontwikkeling van AI- en analyseprojecten synthetisch zullen zijn gegenereerd. Dit benadrukt het belang van synthetische data voor het efficiënt en effectief trainen van AI-modellen.
In deze blog leggen we uit wat synthetische gegevens zijn, waarom je ze moet gebruiken, wat de voordelen zijn van het gebruik van synthetische gegevens ten opzichte van echte gegevens en wat belangrijke gebruikssituaties zijn.
Laten we beginnen!
Wat is synthetische data?
Synthetische gegevens zijn kunstmatig gegenereerde gegevens die echte gegevens nabootsen zonder gevoelige of vertrouwelijke informatie te onthullen. Bij het maken van synthetische gegevens worden statistische methoden en algoritmen voor Machine Learning gebruikt om gegevens te genereren die de verdeling, patronen en correlaties nabootsen die in echte gegevens worden gevonden.
Synthetische gegevens zijn een nuttig hulpmiddel voor het testen en valideren van modellen voor Machine Learning, omdat ze kunnen worden gebruikt om grote datasets te maken die een reeks scenario’s en randgevallen vertegenwoordigen.
Laten we verder gaan door te begrijpen waarom synthetische gegevens zo noodzakelijk zijn.
Waarom heb je synthetische data nodig?
In de huidige datagestuurde wereld zijn gegevens een waardevolle bron voor organisaties om weloverwogen beslissingen te nemen. Het verzamelen, labelen en opschonen van gegevens kan echter duur en tijdrovend zijn. Bovendien hebben bedrijven soms geen toegang tot voldoende gegevens of hebben ze te maken met privacyproblemen. Daarom kunnen synthetische gegevens essentieel zijn voor bedrijven in dergelijke situaties.
Hieronder geven we een overzicht van de belangrijkste redenen waarom je synthetische gegevens nodig hebt:
- Privacyrisico’s beperken
- Gebrek aan echte gegevens
- Moeiteloos grote hoeveelheden gegevens genereren
Privacyrisico’s beperken
Bedrijven hebben vaak synthetische gegevens nodig om privacyrisico’s te minimaliseren. Het verzamelen van gegevens uit de echte wereld kan problemen opleveren bij het voldoen aan de regelgeving voor gegevensbescherming en het beschermen van de privacy van klanten en werknemers. Dit is met name het geval bij het werken met gevoelige gegevens zoals medische of financiële dossiers. Synthetische gegevens kunnen een oplossing bieden door realistische, maar kunstmatige datasets te genereren.
Gebrek aan praktijkgegevens
Een andere situatie waarin synthetische gegevens nuttig zijn, is wanneer er een gebrek is aan gegevens uit de echte wereld. In sommige gevallen hebben bedrijven niet genoeg gegevens om een Machine Learning model effectief te trainen. Als een bedrijf bijvoorbeeld een nieuw model ontwikkelt, kan het zijn dat er niet genoeg historische gegevens zijn om het model te trainen.
Moeiteloos grote hoeveelheden data genereren
Het genereren van aanzienlijke hoeveelheden kunstmatige datasets in korte tijd is een eenvoudig proces, waardoor het een waardevolle aanwinst is voor organisaties die snel hun modellen voor Machine Learning willen verbeteren en trainen. Synthetische gegevens bieden een ideale oplossing om de beperkingen van de beperkte beschikbaarheid van gegevens te overwinnen.
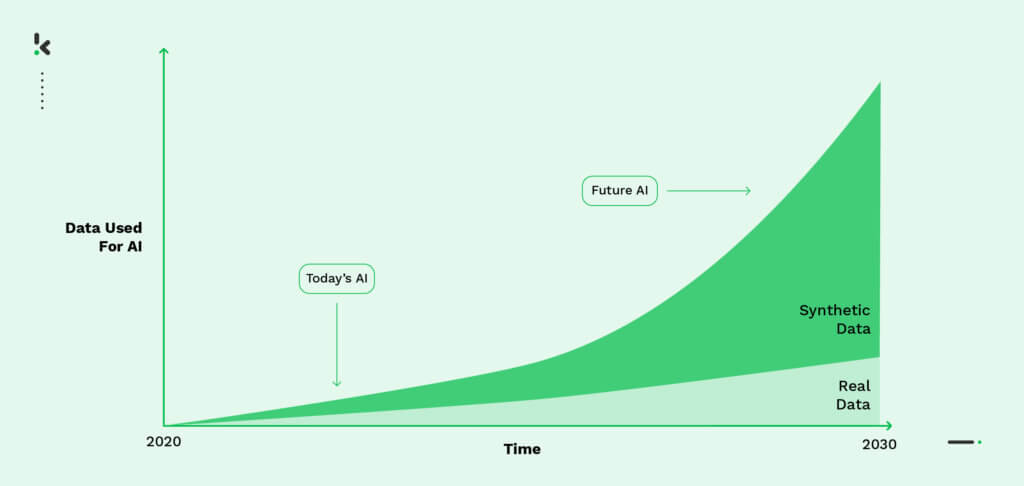
Nu je weet waarom synthetische gegevens nodig zijn, gaan we dieper in op de voordelen ervan ten opzichte van echte gegevens en de mogelijke nadelen.
Synthetische data of echte data
Als je moet kiezen welk type gegevens je moet gebruiken, is het belangrijk om zowel de voordelen als de mogelijke nadelen te begrijpen.
Laten we beginnen met de mogelijke nadelen.
De kwaliteit van synthetische data kan inferieur zijn
Synthetische gegevens kunnen van inferieure kwaliteit zijn in vergelijking met echte gegevens, vooral in complexe of multivariabele scenario’s. Algoritmen die worden gebruikt om synthetische gegevens te genereren, kunnen mogelijk niet de volledige complexiteit en nuance van echte gegevens weergeven, wat leidt tot onnauwkeurigheden en vertekeningen die van invloed kunnen zijn op de nauwkeurigheid van analyses en modellen.
Synthetische data vertegenwoordigen mogelijk niet het volledige bereik van echte data
Synthetische gegevens dekken mogelijk niet het volledige bereik van echte gegevens en missen zeldzame gebeurtenissen of datapunten met uitschieters. Dit kan leiden tot overfitting en slechte generalisatie van analyses of modellering op basis van synthetische gegevens, ondanks het nabootsen van bepaalde patronen of verdelingen.
Het gebruik van synthetische data roept ethische vragen op
Synthetische gegevens kunnen ethische bezwaren oproepen, vooral als ze echte gegevens vervangen die belangrijke beslissingen of beleid onderbouwen. Hoewel synthetische gegevens nuttig kunnen zijn bij schaarste of bij het verkrijgen van moeilijke gegevens, mogen ze echte gegevens niet vervangen wanneer deze beschikbaar en geschikt zijn om te gebruiken. De transparantie en controleerbaarheid van het genereren van synthetische gegevens kan ook moeilijk te bepalen zijn, waardoor het voor belanghebbenden moeilijker wordt om analyses of modellen op basis van synthetische gegevens te vertrouwen.
Laten we nu de voordelen van het gebruik van synthetische gegevens onderzoeken.
Kostenefficiënt
Synthetische gegevens kunnen tegen lagere kosten worden gegenereerd dan echte gegevens, wat voordelig is voor kleine tot middelgrote bedrijven die niet over het budget beschikken voor uitgebreide gegevensverzameling. Hierdoor kunnen ze geld besparen en toch effectief AI-modellen trainen.

Bescherming van privacy
Zoals eerder vermeld, worden synthetische gegevens kunstmatig gegenereerd en bevatten ze geen gevoelige informatie die mogelijk in strijd is met de regelgeving, waardoor het een veiligere optie is voor bedrijven.
Flexibiliteit en controle
Synthetische gegevens bieden meer flexibiliteit en controle over gegevens dan echte gegevens. Bedrijven kunnen synthetische datasets aanpassen aan hun specifieke behoeften, inclusief het manipuleren van variabelen en parameters om verschillende scenario’s te genereren en verschillende hypotheses te testen.
Verminderde vooroordelen
Hoewel het gebruik van synthetische gegevens soms ongewenste vertekeningen kan introduceren in datasets, kan het ook een waardevolle rol spelen bij het reduceren van vertekeningen in omgevingen die aanpassingen vereisen. Synthetische gegevens kunnen worden gegenereerd met gecontroleerde parameters en bekende kenmerken, waardoor vertekeningen in echte gegevens kunnen worden verminderd of geëlimineerd.
Bovendien kunnen synthetische datasets worden gebruikt om onevenwichtige datasets aan te pakken door een evenwichtigere verdeling van gegevens te bieden, en kunnen ze scenario’s simuleren die moeilijk vast te leggen zijn in echte omgevingen, waardoor meer diverse en representatieve gegevens voor modeltraining worden geproduceerd.
Om mogelijke nadelen van het gebruik van alleen synthetische datasets bij het trainen van AI-modellen te ondervangen, is een mogelijke oplossing om synthetische gegevens te combineren met gegevens uit de echte wereld. Dit kan leiden tot betere prestaties en robuustere modellen.
Soorten synthetische data
Na het bestuderen van de mogelijke voordelen en beperkingen van het gebruik van synthetische gegevens in vergelijking met echte gegevens, is het tijd om de verschillende soorten synthetische gegevens te verkennen:
- Synthetische tekst
- Synthetische media
- Synthetische gegevens in tabelvorm
Synthetische tekst
Synthetische tekst bootst echte tekstgegevens na, gemaakt met Natural Language Processing (NLP) technieken zoals taalmodellen en deep learning modellen. Het is nuttig voor de ontwikkeling van chatbots zoals ChatGPT, vertaalsystemen en tools voor sentimentanalyse. Daarnaast kan datavergroting worden gedaan door kunstmatige tekst toe te voegen aan bestaande datasets om de kwaliteit van modellen voor Machine Learning te verbeteren.

Synthetische media
Synthetische media zijn computergegenereerde media die lijken op echte beelden, video’s en audio, gemaakt met geavanceerde technieken zoals computergraphics en deep learning-modellen. Het heeft veel toepassingen, waaronder het creëren van content, virtuele realiteit en simulatie, met potentiële toepassingen in films, virtuele assistenten en muziekproductie. Het is een veelzijdige tool voor het oplossen van verschillende uitdagingen op verschillende gebieden.

Synthetische tabelgegevens
Synthetische gegevens in tabelvorm lijken op echte gegevens in tabelvorm, gemaakt met statistische modellen zoals beslisbomen en random forests. Het is handig voor data augmentation, data masking en data sharing, waarbij synthetische data wordt toegevoegd aan bestaande datasets om de omvang en variëteit te vergroten of om statistische eigenschappen te behouden met behoud van gevoelige informatie.
Gebruikssituaties voor synthetische data
Nu je hebt begrepen wat synthetische gegevens zijn en hoe ze verschillen van echte gegevens, gaan we een aantal belangrijke gebruikssituaties voor synthetische gegevens in verschillende sectoren verkennen, waaronder:
- Gezondheidszorg
- Financiën
- Auto-industrie
- Detailhandel
- Productie
Gezondheidszorg
In de gezondheidszorg hebben synthetische gegevens de potentie om modellen voor Machine Learning te trainen die effectief ziekten kunnen diagnosticeren en gezondheidsrisico’s kunnen detecteren. Dit kan zeer nuttig zijn in omstandigheden waarin het verkrijgen van echte patiëntgegevens een uitdaging is vanwege factoren als privacy of beschikbaarheid.
Financiën
Synthetische gegevens hebben de capaciteit om Machine Learning modellen te trainen die patronen kunnen herkennen en markttrends kunnen voorspellen. Hierdoor kunnen financiële instellingen beter geïnformeerde investeringsbeslissingen nemen en efficiënter risico’s beheren.
Auto-industrie
Door gebruik te maken van synthetische data is het mogelijk om deep learning modellen te trainen die in staat zijn om verschillende objecten op de weg, waaronder voetgangers en andere voertuigen, te identificeren en categoriseren. Dit heeft een enorm potentieel voor de ontwikkeling van zelfrijdende voertuigen die veilig door ingewikkelde omgevingen kunnen navigeren.
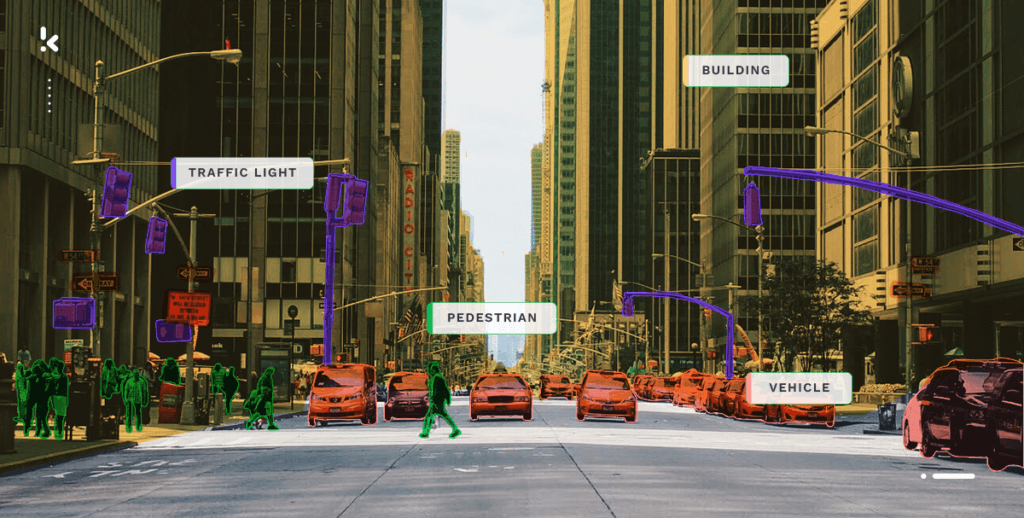
Detailhandel
Binnen de detailhandel kunnen synthetische gegevens realistische simulaties van klantgedrag en voorkeuren genereren, waardoor retailers inzichten krijgen om hun marketing- en verkoopstrategieën te optimaliseren. Synthetische gegevens kunnen bijvoorbeeld de populariteit van producten voorspellen onder specifieke demografische groepen of tijdens bepaalde perioden van het jaar.
Productie
Synthetische gegevens hebben het potentieel om Machine Learning modellen te trainen die patronen in productieprocessen kunnen herkennen en storingen in apparatuur kunnen voorspellen. Dit kan stilstand aanzienlijk verminderen en de algehele efficiëntie van fabrikanten verbeteren.
Aan de slag met synthetische gegevens

We hebben nu hopelijk bewezen dat synthetische gegevens in veel gevallen een (kosten)efficiëntere oplossing zijn dan het gebruik van echte gegevens. Als je geïnteresseerd bent in het verkennen van het potentieel van synthetische gegevens, dan is Klippa DataNorth je partner bij uitstek. Wij zijn gespecialiseerd in het genereren van hoogwaardige synthetische datasets die zijn afgestemd op je unieke behoeften, zodat je vol vertrouwen AI-modeltrainingen kunt uitvoeren.
Ons team van experts is toegewijd aan het helpen van bedrijven en organisaties bij het verbeteren van hun AI-modelprestaties door grote hoeveelheden synthetische data te leveren voor trainingsdoeleinden. Of je nu synthetische gegevens nodig hebt voor compliance of AI-model training, wij zijn er om je te helpen de voordelen van synthetische gegevens te benutten.
Onze diensten omvatten het op maat genereren van synthetische data, het labelen en annoteren van data en het valideren en testen van data. Wat je ook nodig hebt, we werken nauw met je samen om synthetische datasets te leveren die aansluiten bij je bedrijfsdoelstellingen en voldoen aan de AVG-voorschriften.
Als je klaar bent om de kracht van synthetische gegevens te benutten voor je AI-model training, neem dan vandaag nog contact op met DataNorth. Ons ervaren team is toegewijd om je te helpen succes te boeken.