
Si vous avez déjà tenté de développer vos propres modèles ou algorithmes de machine learning, ou si vous envisagez de le faire, vous avez peut-être rencontré un obstacle commun : acquérir suffisamment de données suffisamment diversifiées pour entraîner efficacement votre modèle.
Heureusement, les données synthétiques offrent une solution à ce problème.
À mesure que les projets d’IA deviennent plus répandus, le besoin de génération de données synthétiques devient de plus en plus évident. En fait, une étude de Gartner prévoit que d’ici 2024, 60% des données utilisées pour le développement de projets d’IA et d’analyse seront générées synthétiquement. Cela souligne l’importance des données synthétiques dans la formation des modèles d’IA de manière efficace et efficiente.
Dans ce blog, nous expliquerons les données synthétiques, pourquoi vous devez les utiliser, les avantages de l’utilisation de données synthétiques par rapport aux données du monde réel et les cas d’utilisation importants.
Commençons!
Qu’est-ce qu’une donnée synthétique ?
Les données synthétiques font référence à des données générées artificiellement qui simulent des données du monde réel sans révéler d’informations sensibles ou confidentielles. Le processus de création de données synthétiques implique l’utilisation de méthodes statistiques et d’algorithmes de machine learning pour générer des données qui imitent la distribution, les modèles et les corrélations trouvés dans les données du monde réel.
Les données synthétiques sont un outil utile pour tester et valider les modèles de machine learning, car elles peuvent être utilisées pour créer de grands ensembles de données qui représentent une gamme de scénarios et de cas limites.
Continuons en comprenant pourquoi les données synthétiques sont si nécessaires.
Pourquoi avez-vous besoin de données synthétiques ?
Dans le monde actuel axé sur les données, les données sont une ressource précieuse pour les organisations afin de prendre des décisions éclairées. Cependant, la collecte, l’étiquetage et le nettoyage des données peuvent être coûteux et prendre beaucoup de temps. En outre, les entreprises peuvent ne pas avoir accès à suffisamment de données ou faire face à des préoccupations en matière de protection de la vie privée. C’est pourquoi les données synthétiques peuvent être essentielles pour les entreprises dans de telles situations.
Ci-dessous, nous énumérons les raisons les plus importantes pour lesquelles vous avez besoin de données synthétiques:
- Atténuer les risques liés à la confidentialité des données
- Manque de données du monde réel
- Générez sans effort de grandes quantités de données
Atténuer les risques liés à la confidentialité des données
Les entreprises ont souvent besoin de données synthétiques pour minimiser les risques liés à la confidentialité des données. La collecte de données réelles peut poser des défis pour se conformer aux réglementations en matière de protection des données et préserver la vie privée des clients et des employés. C’est particulièrement le cas lorsque vous travaillez avec des données sensibles telles que des dossiers médicaux ou financiers. Les données synthétiques peuvent fournir une solution en générant des ensembles de données réalistes, mais artificiels.
Manque de données réelles
Une autre situation dans laquelle les données synthétiques sont utiles est lorsqu’il y a un manque de données du monde réel. Dans certains cas, les entreprises peuvent ne pas disposer de suffisamment de données pour former efficacement un modèle de machine learning. Par exemple, si une entreprise développe un nouveau modèle, il se peut qu’il n’y ait pas suffisamment de données historiques pour l’entraîner.
Générer sans effort de grandes quantités de données
Générer des quantités importantes d’ensembles de données artificielles sur une courte période est un processus simple, ce qui en fait un atout précieux pour les organisations qui cherchent à améliorer et à former rapidement leurs modèles de machine learning. Les données synthétiques constituent une solution idéale pour surmonter les limites de la rareté de la disponibilité des données.
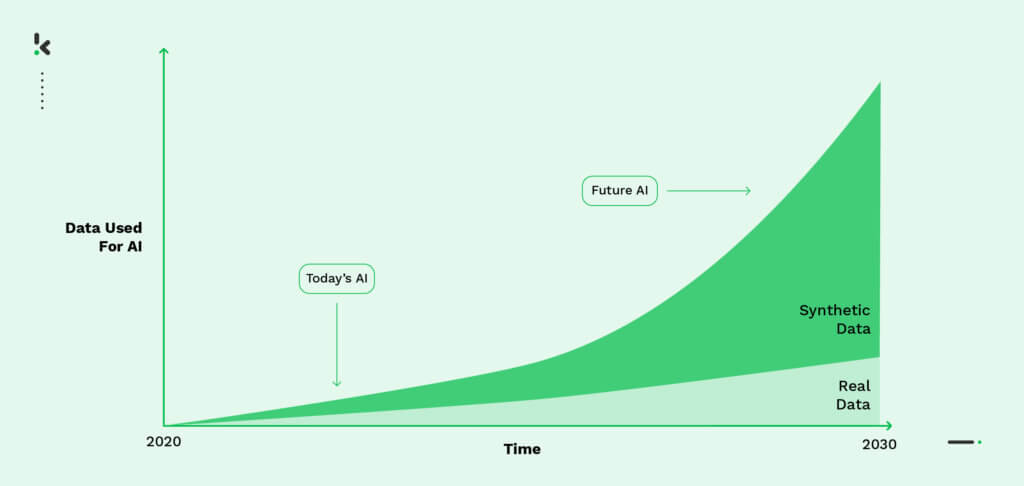
Maintenant que vous connaissez les raisons pour lesquelles les données synthétiques sont nécessaires, examinons les avantages qu’elles offrent par rapport aux données du monde réel, ainsi que les inconvénients potentiels.
Données synthétiques et données réelles
Lorsqu’il s’agit de choisir le type de données que vous devez utiliser, il est important de comprendre à la fois les avantages et les inconvénients potentiels.
Commençons par examiner les inconvénients potentiels.
La qualité des données synthétiques peut être inférieure
Les données synthétiques peuvent être de qualité inférieure aux données réelles, en particulier dans les scénarios complexes ou multivariables. Les algorithmes utilisés pour générer des données synthétiques peuvent ne pas saisir toute la complexité et les nuances des données du monde réel, ce qui entraîne des inexactitudes et des biais qui peuvent avoir un impact sur la précision de l’analyse et de la modélisation.
Les données synthétiques peuvent ne pas représenter toute la gamme des données réelles
Les données synthétiques peuvent ne pas couvrir toute la gamme des données réelles, manquer des événements rares ou des points de données aberrants. Cela peut conduire à un surajustement et à une mauvaise généralisation de l’analyse ou de la modélisation basée sur des données synthétiques, malgré l’imitation de certains modèles ou distributions.
L’utilisation de données synthétiques soulève des questions éthiques
Les données synthétiques peuvent soulever des préoccupations éthiques, surtout si elles remplacent les données du monde réel qui éclairent les décisions ou les politiques importantes. Bien que les données synthétiques puissent être utiles dans des scénarios de rareté ou d’acquisition de données difficiles, elles ne doivent pas remplacer les données réelles lorsqu’elles sont disponibles et appropriées à utiliser. La transparence et la responsabilité de la génération de données synthétiques peuvent également être difficiles à déterminer, ce qui rend plus difficile pour les parties prenantes de faire confiance à l’analyse ou à la modélisation basée sur celle-ci.
Examinons maintenant les avantages de l’utilisation de données synthétiques.
Rentabilité
Les données synthétiques peuvent être générées à un coût inférieur à celui des données réelles, ce qui profite aux petites et moyennes entreprises qui n’ont pas le budget nécessaire pour une collecte de données étendue. Cela leur permet d’économiser de l’argent tout en étant en mesure de former efficacement des modèles d’IA.

Protection de la vie privée
Comme mentionné précédemment, les données synthétiques sont générées artificiellement et ne contiennent aucune information sensible susceptible d’enfreindre la réglementation, ce qui en fait une option plus sûre pour les entreprises.
Flexibilité et contrôle
Les données synthétiques offrent plus de flexibilité et de contrôle sur les données que les données du monde réel. Les entreprises peuvent personnaliser les ensembles de données synthétiques pour répondre à leurs besoins spécifiques, notamment en manipulant des variables et des paramètres pour générer différents scénarios et tester diverses hypothèses.
Réduction des biais
Bien que l’utilisation de données synthétiques puisse parfois introduire des biais indésirables dans les ensembles de données, elle peut également jouer un rôle précieux dans la réduction des biais dans les environnements nécessitant des modifications. Les données synthétiques peuvent être générées avec des paramètres contrôlés et des caractéristiques connues, ce qui permet de réduire ou d’éliminer les biais présents dans les données du monde réel.
En outre, les ensembles de données synthétiques peuvent être utilisés pour traiter les ensembles de données déséquilibrés en fournissant une distribution plus équilibrée des données, et peuvent simuler des scénarios difficiles à capturer dans des contextes réels, produisant ainsi des données plus diversifiées et représentatives pour la formation des modèles.
Pour surmonter les inconvénients potentiels de l’utilisation exclusive d’ensembles de données synthétiques dans la formation de modèles d’IA, une solution possible consiste à combiner des données synthétiques avec des données réelles. Cela peut conduire à de meilleures performances et à des modèles plus robustes.
Types de données synthétiques
Après avoir examiné les avantages et les limites potentiels de l’utilisation de données synthétiques par rapport aux données du monde réel, il est temps d’explorer les différents types de données synthétiques:
- Texte synthétique
- Milieux synthétiques
- Données tabulaires synthétiques
Texte synthétique
Le texte synthétique imite les données textuelles du monde réel, créées avec des techniques de traitement du langage naturel (NLP) telles que les modèles de langage et les modèles d’apprentissage profond. Il est bénéfique pour le développement de chatbots tels que ChatGPT, les systèmes de traduction et les outils d’analyse des sentiments. En outre, l’augmentation des données peut être effectuée en ajoutant du texte artificiel aux ensembles de données existants pour améliorer la qualité du modèle de machine learning.

Milieux synthétiques
Les médias synthétiques sont des médias générés par ordinateur qui ressemblent à des images, des vidéos et des sons du monde réel, créés à l’aide de techniques avancées telles que l’infographie et les modèles d’apprentissage profond. Il a de nombreuses applications, notamment la création de contenu, la réalité virtuelle et la simulation, avec des utilisations potentielles dans les films, les assistants virtuels et la production musicale. C’est un outil polyvalent qui permet de résoudre divers défis dans différents domaines.

Données tabulaires synthétiques
Les données tabulaires synthétiques imitent les données du monde réel sous forme de tableau, créées avec des modèles statistiques tels que les arbres de décision et les forêts aléatoires. Il est utile pour l’augmentation des données, le masquage des données et le partage des données, où des données synthétiques sont ajoutées aux ensembles de données existants pour augmenter leur taille et leur variété ou pour conserver leurs propriétés statistiques tout en préservant les informations sensibles.
Cas d’utilisation des données synthétiques
Maintenant que vous avez acquis une compréhension de ce que sont les données synthétiques et en quoi elles diffèrent des données du monde réel, explorons quelques cas d’utilisation importants des données synthétiques pour différents secteurs, notamment:
- Santé
- Finance
- Automobile
- Vente au détail
- Fabrication
Soins de santé
Dans le domaine de la santé, les données synthétiques ont le potentiel de former des modèles de machine learning capables de diagnostiquer efficacement les maladies et de détecter les risques pour la santé. Cela peut être très bénéfique dans les circonstances où il est difficile d’obtenir des données sur les patients authentiques en raison de facteurs tels que les problèmes de confidentialité ou de disponibilité.
Finance
Les données synthétiques ont la capacité d’entraîner des modèles de machine learning capables de reconnaître des modèles et de prévoir les tendances du marché. Cela peut permettre aux institutions financières de prendre des décisions d’investissement plus éclairées et de gérer les risques plus efficacement.
Automobile
En utilisant des données synthétiques, il est possible d’entraîner des modèles d’apprentissage profond capables d’identifier et de catégoriser divers objets sur la route, y compris les piétons et autres véhicules. Cela a un immense potentiel dans le développement de véhicules autonomes qui peuvent naviguer en toute sécurité dans des environnements complexes.
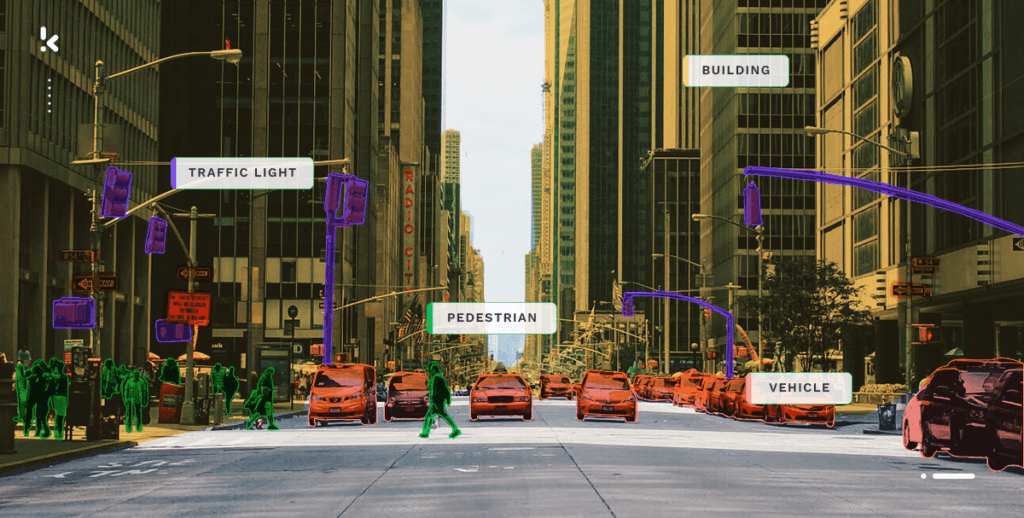
Vente au détail
Dans le secteur de la vente au détail, les données synthétiques sont capables de générer des simulations réalistes du comportement et des préférences des clients, fournissant aux détaillants des informations pour optimiser leurs stratégies de marketing et de vente. Par exemple, les données synthétiques peuvent prédire la popularité des produits parmi des groupes démographiques spécifiques ou à des périodes particulières de l’année.
Fabrication
Les données synthétiques ont le potentiel d’entraîner des modèles de machine learning capables de reconnaître des modèles dans les processus de fabrication et de prévoir les défaillances des équipements. Cela peut réduire considérablement les temps d’arrêt et améliorer l’efficacité globale des fabricants.
Commencer à utiliser les données synthétiques

Nous espérons maintenant avoir prouvé notre point de vue selon lequel les données synthétiques sont dans de nombreux cas une solution plus efficace et plus rentable que l’utilisation de données réelles. Si vous souhaitez explorer le potentiel des données synthétiques, Klippa DataNorth est votre partenaire de choix. Nous nous spécialisons dans la génération d’ensembles de données synthétiques de haute qualité adaptés à vos besoins uniques, ce qui vous permet de suivre une formation sur les modèles d’IA en toute confiance.
Notre équipe d’experts se consacre à aider les entreprises et les organisations à améliorer les performances de leurs modèles d’IA en fournissant de grands volumes de données synthétiques à des fins de formation. Que vous ayez besoin de données synthétiques pour la conformité ou d’une formation sur les modèles d’IA, nous sommes là pour vous aider à exploiter les avantages des données synthétiques.
Nos services comprennent la génération de données synthétiques personnalisées, l’étiquetage et l’annotation de données, ainsi que la validation et le test de données. Quels que soient vos besoins, nous travaillerons en étroite collaboration avec vous pour fournir des ensembles de données synthétiques qui correspondent à vos objectifs commerciaux, tout en respectant les réglementations GDPR.
Si vous êtes prêt à tirer parti de la puissance des données synthétiques pour votre formation sur les modèles d’IA, contactez DataNorth aujourd’hui. Notre équipe expérimentée est dédiée à vous aider à réussir.