Over Doxis (voorheen Klippa)
Klippa is nu Doxis, The Document Intelligence Company!
In maart 2025 is Klippa officieel gefuseerd met Doxis (voorheen SER) om samen het meest geavanceerde, AI‑first platform voor Intelligent Content Automation te creëren.
Door de bekroonde IDP‑technologie van Klippa te integreren in het Doxis‑ecosysteem, hebben we onze kernoplossingen hernoemd om deze nieuwe schaal te weerspiegelen: Klippa DocHorizon heet nu Doxis AI.dp en Klippa SpendControl heet nu Doxis SpendControl.
Vandaag staan we als één geheel, met een AI‑first platform dat content, mensen en processen samenbrengt binnen de hele organisatie.
Vertrouwd door ruim 1.000 mooie merken
Wie is Doxis?
Wij zijn The Document Intelligence Company. Wij veranderen content chaos in bruikbare inzichten, zodat teams sneller, zekerder en met meer controle kunnen werken.
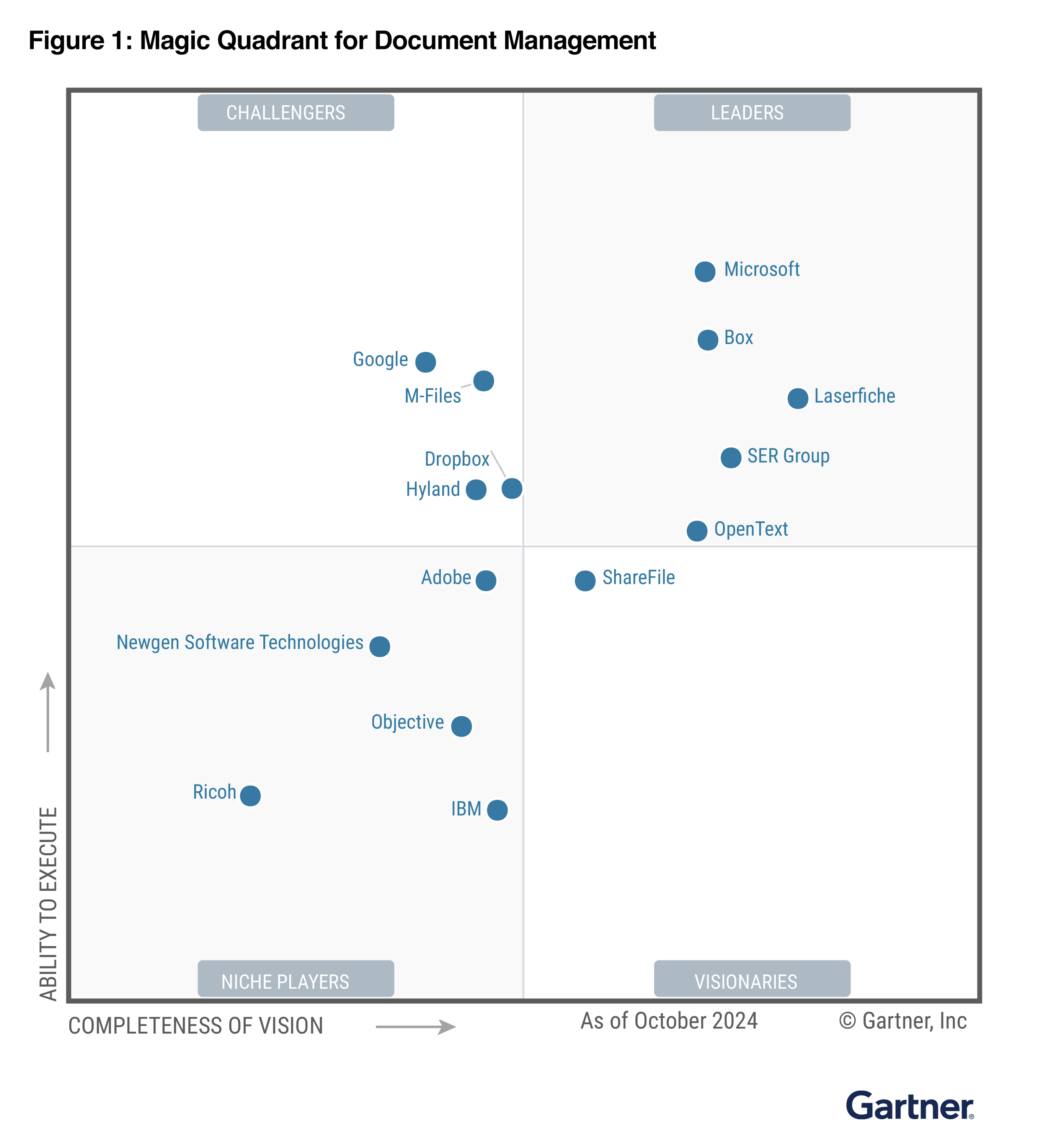
Met meer dan 3.000 klanten, 5 miljoen gebruikers en een Gartner® Magic Quadrant™ Leader‑positie in Document Management, combineren we decennia aan enterprise‑ervaring met innovatieve AI‑technologie.
Wereldwijde expertise, lokale impact
Ons verhaal wordt gedragen door een wereldwijd team van 900+ professionals met een passie voor uitmuntendheid. We combineren de kennis van 250+ interne ontwikkelaars met een customer experience‑team van 400 specialisten om jouw succes te garanderen.
3,000+
Enterprise-klanten
5M+
Dagelijkse gebruikers
900+
Werknemers wereldwijd
Wat wij doen: Intelligent Content Automation
Wij lossen de contentchaos op die bedrijven vertraagt. Ons uniforme platform, gebouwd op de enterprise‑kracht van Doxis ECM en versterkt door Doxis AI.dp, automatiseert de volledige documentlevenscyclus. Het sluit naadloos aan op toonaangevende bedrijfsapplicaties zoals SAP, Salesforce en Microsoft 365 om een echte return on information te realiseren.
Doxis AI.dp
Voorheen Klippa DocHorizon
Onze gespecialiseerde engine voor Intelligent Document Processing (IDP). Deze maakt gebruik van toonaangevende OCR en AI om te automatiseren hoe documenten worden begrepen en geverifieerd.
OCR (Optical Character Recognition): Snel en nauwkeurig tekst herkennen en data uit documenten halen.
Documentclassificatie: Documenten automatisch indelen en sorteren met AI.
Documentconversie: Documenten converteren naar en vanuit formaten zoals PDF, Word, Excel en meer.
Data‑anonimisering: Gevoelige gegevens automatisch maskeren of anonimiseren in documenten.
Fraudedetectie & Verificatie: Manipulaties, duplicaten en documenten controleren op echtheid.
Identiteitsverificatie (KYC): Automatiseer KYC‑controles en verificatie van identiteitsdocumenten.
E‑facturatie & PEPPOL: Verstuur en ontvang wereldwijd e‑facturen via PEPPOL en andere standaarden.
Doxis SpendControl
Voorheen Klippa SpendControl
De toonaangevende oplossing voor pre-accounting. Automatiseert factuurverwerking, declaraties en het beheer van bedrijfskaarten, waardoor financiële teams volledige controle en inzicht hebben.
Factuurverwerking: Automatiseer het vastleggen, extraheren en goedkeuren van facturen.
Declaratiebeheer: Dien declaraties in, verwerk en vergoed deze met slechts enkele klikken.
Goedkeuringsworkflows: Stel goedkeuringsregels in en beheer financiële workflows digitaal.
Bedrijfskaarten: Geef zakelijke creditcards uit met bestedingslimieten en volledig inzicht.
Dashboard voor uitgavenbeheer: Krijg realtime inzichten in uitgaven en budgetten.
Kilometer tracking: Bereken automatisch kilometer-declaraties via Google Maps‑integratie of handmatige invoer.
Declaratierapportage: Maak en exporteer gedetailleerde rapporten voor boekhouding of compliance.
Gedreven door waarden
Deze principes vormen de basis van onze bedrijfscultuur.
Ze bepalen onze cultuur, stimuleren onze innovatie en definiëren wat het betekent om onderdeel te zijn van het Doxis‑team.
Passie voor klantsucces
Het succes van onze klanten is ons succes. Van complexe vraagstukken tot het begeleiden van belangrijke implementaties, we werken met zorg en toewijding. Over teams en landsgrenzen heen zetten we die extra stap, gedreven door echte passie.


Experts in alles wat we doen
Expertise is de kern van de waarde die we leveren. We blijven altijd leren; voor ons betekent echte expertise streven naar uitmuntendheid, leren van fouten en elke dag verbeteren.
Vriendelijkheid
Vriendelijkheid is niet alleen een gebaar, maar een mindset. Resultaten zijn belangrijk, maar hoe we ze bereiken is minstens zo belangrijk. Empathie, geduld en respect sturen elke interactie.


Gedreven door ondernemingsgeest
We handelen met visie, moed en een ondernemende mindset. We passen ons snel aan, volgen wat werkt en transformeren wat niet werkt. Deze geest maakt van uitdagingen kansen, voor onze klanten én onze teams.
We houden van plezier
Plezier zit in ons DNA: de vreugde van problemen oplossen, doelen bereiken en grenzen verleggen. Het stimuleert prestaties, voedt creativiteit en houdt ons verbonden. Met energie en onze mascotte Doxi brengen we altijd positiviteit.
