
Picture this. It’s hiring season, and the flood of applications begins—hundreds, maybe even thousands pouring in. Each resume holds the potential for a new member to join your team, but here’s the catch: every single one is unique, with its own formatting quirks, style, and crucial details hidden within pages of text.
Your task? Sorting through this overload of possibilities, entering all data needed from the resume manually, and doing it all quickly, without missing a single talented candidate. It’s a daunting challenge, overwhelming and nearly impossible to tackle efficiently, until now.
Enter resume parsing, the modern way of processing documents in recruitment. This technology is like having an ally, empowering you to process, analyze data, and organize those endless resumes in the blink of an eye. But what is it, exactly? And how does it work? Let’s dive into that in this blog!
Key Takeaways
- Definition: Resume parsing automates the extraction of candidate data from formats like PDF, Word, or scanned images and structures it for ATS/HR database use.
- Core Workflow: Document reading → Section analysis → Entity extraction → Structuring → Storage/search integration.
- Types: Keyword-based (fast but limited), statistical (more accurate, requires training data), AI/ML-based (highest accuracy, context-aware).
- Key Benefits: Efficiency, searchability, scalability, consistency, bias reduction.
- Doxis Advantage: Custom fields, bulk uploads, multilingual parsing, GDPR/HIPAA/ISO compliance, easy API integration.
- Best Practice: Choose an AI/ML-based parser for high accuracy and adaptability across industries.
What is Resume Parsing?
Resume parsing or CV parsing is the automated process of extracting relevant information from resumes, making it easier to review job applications. It enables faster decision-making and lowers waiting times, benefiting applicants and HR professionals.
Resume parsing software leverages such advanced technologies as AI, machine learning, and NLP. From fetching resumes submitted via email or other file applications to integrating extracted data into your preferred software – it streamlines the entire recruitment workflow. This way, your only task is to select the right candidate.
But before we go any further, let’s consider the pros and cons of resume parsing to help you decide if it’s the right move for you.
Benefits of Resume Parsing
Resume parsing automates manual review, making candidate data instantly searchable, filterable, and comparable, improving speed, accuracy, and fairness in hiring.
Core Benefits (Industry Standard — per HR Technology best practices):
- Efficiency – Eliminates repetitive reading and manual entry; processes resumes in seconds.
- Searchability – Turns candidate data into searchable fields for quick matching.
- Scalability – Handles hundreds or thousands of resumes without bottlenecks.
- Consistency – Normalizes data formats for fair comparison.
- Fairness – Enables anonymized candidate profiles to reduce bias.
Doxis-Specific Advantages:
- Custom Fields – Extract non-standard fields using the prompt builder.
- Bulk Upload – Parse entire application batches at once via web, email, or cloud workflows.
- Multilingual Support – Handle resumes in multiple languages for global recruitment.
- Data Privacy First – Full GDPR, HIPAA, and ISO compliance ensures secure applicant data handling.
- Easy Integration – API and SDK options plug directly into any ATS or HRM system without disruption.
Cons of Resume Parsing
While resume parsing presents a wide range of advantages, it’s essential to keep these potential drawbacks in mind:
- Loss of individuality: Candidates who submit creative resumes risk being overlooked, as their creativity may only be parsed as information in your database.
- Inaccuracy: Depending on software quality, resume parsing may struggle with complex or unconventional resume formats, potentially leading to misinterpretation of data or missing important information.
- Integration Challenges: Ensuring seamless integration with existing HR systems can sometimes be complex.
When it comes to resume parsing, the pros can easily outweigh the cons. The trick? Choosing the right software to maximize benefits and tackle any drawbacks head-on.
How Resume Parsing Works
Resume parsing turns unstructured resume text from formats like PDF or Word into clean, standardized data fields your systems can instantly search, filter, and match, removing the need for manual review.
Step-by-Step Workflow:
Step 1: Document Reading
Parsing software ingests resumes from email, ATS uploads, job portals, or cloud storage.
- Formats supported: PDF, Word (.doc/.docx), scanned images (JPG/PNG)
- Uses Optical Character Recognition (OCR) to convert text from images into machine-readable form.
Step 2: Section Analysis
Natural Language Processing (NLP) detects standard sections like “Work Experience,” “Education,” “Skills” by identifying headings, layout patterns, bold text, and keywords.
Step 3: Entity Extraction
AI/ML algorithms capture key fields:
- Name, email, phone
- Job titles, companies, dates of employment
- Skills, certifications, education details
Step 4: Structuring & Cleaning
Extracted data is formatted into standardized, structured outputs such as JSON, XML, CSV.
- Data is normalized (e.g., date formats) to ensure consistency.
Step 5: Storage & Search
Structured data is sent to your Applicant Tracking System (ATS) or HR database.
- Enables fast search, filtering, and automated candidate matching against job requirements.
Result: Recruiters can shortlist candidates in minutes instead of hours, while keeping records accurate, searchable, and compliant.
Types of Resume Parsing
There are three main approaches to resume parsing, each with distinct strengths and limitations. Modern AI-based parsing delivers the highest accuracy and adaptability.
Recommendation: For scalability and accuracy across industries, choose an AI/ML-based resume parser, as offered in Doxis AI.dp, which continuously improves results and supports multilingual parsing.
How to Choose a Resume Parsing Tool?
When scouting for a resume parser, businesses should prioritize a few criteria to ensure efficiency in the hiring process.
- Accuracy: High precision in data extraction ensures reliable candidate profiles, with a target accuracy rate of at least 90%.
- Integration Capabilities: Seamless integration with existing recruitment and HR software systems.
- Customization: Option to tailor parsing criteria to your specific needs, including custom data fields and document redaction.
- Support: Robust customer support to promptly address any issues encountered.
- Bulk Upload: The possibility to upload multiple resumes simultaneously for efficient processing.
- Global Coverage: Support of different languages to facilitate international hiring efforts.
- Data Privacy Compliance: GDPR compliance is prioritized to ensure the protection of employee data within the HR department.
- Wide Format Support: Ability to parse documents in different formats such as PDFs, email attachments, or Google Drive files.
Now that you’re familiar with resume parsing and what to look at when choosing the right software, meet Doxis AI.dp. It’s your go-to for streamlining the application process with top-notch resume parsing technology.
How to Automate Resume Parsing Process with Doxis
Doxis AI.dp revolutionizes recruitment by offering features that you can customize according to your needs:
- Information extraction from resume with ocr
- Output sent in the format of choice such as CSV, XLSX, XML, and more
- Classification of resumes according to your standard
- Redaction of private information on resume
- Easy implementation into your HRM system
- Integration via OCR SDK, API, or our IDP Platform
Here is a detailed step-by-step of how resume parsing is done with Doxis.
Step 1: Sign Up to the platform
The first step is to sign up to our platform. It’s really simple, you only have to click on this link, fill in your details and create an account.
Step 2: Upload Resume
To provide resumes, you have 2 different options:
- Upload resumes to Doxis’ platform, either individually or in bulk. This can be done via mobile apps, FTP, email, or web applications.
- Set up a workflow to automatically fetch resumes from selected email addresses or Google Drive to the platform.
In this example, we have selected option 2 by choosing an input source and automating the process of retrieving a resume from an email address.
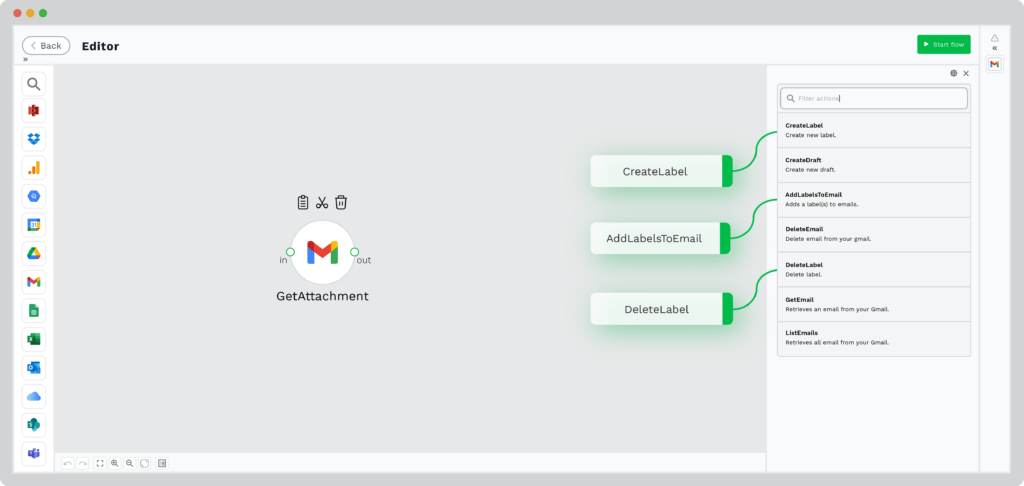
Step 3: Resume Data Extraction
Doxis’ technology is designed to automatically extract relevant fields from resumes. All you have to do is select the desired fields that you need from the resume, and Doxis extracts them for you. If there are any different fields than the standard ones that you need to extract, you can use the prompt builder to choose the specific field.
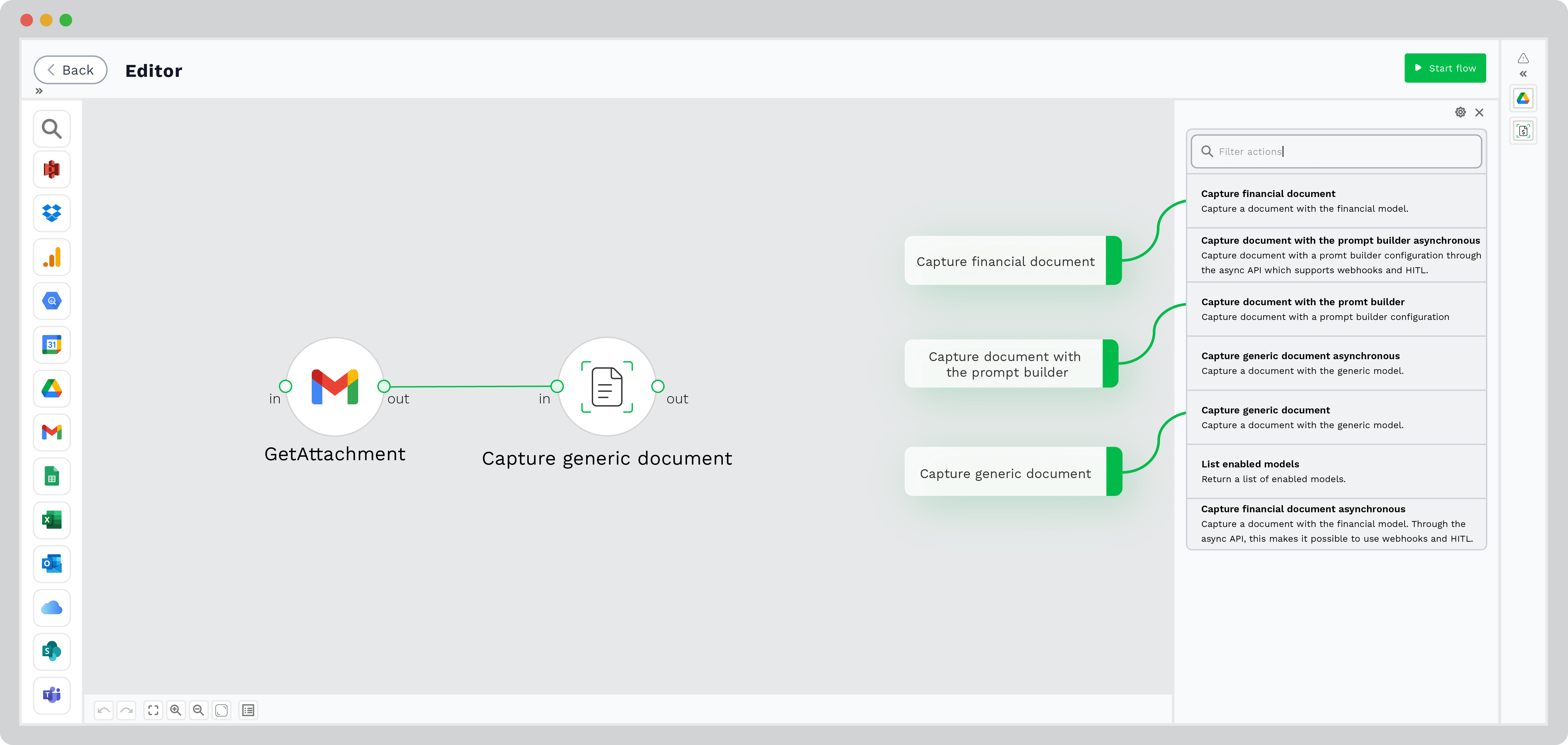
Step 4: Resume Parsing
Once all the necessary data has been collected and extracted from the resume, the next step is to convert it into the format of your choice. Our platform automates this conversion process, making it ready for use. By default, the data is converted to a JSON file. However, you can choose other formats such as XLSX, CSV, and more.
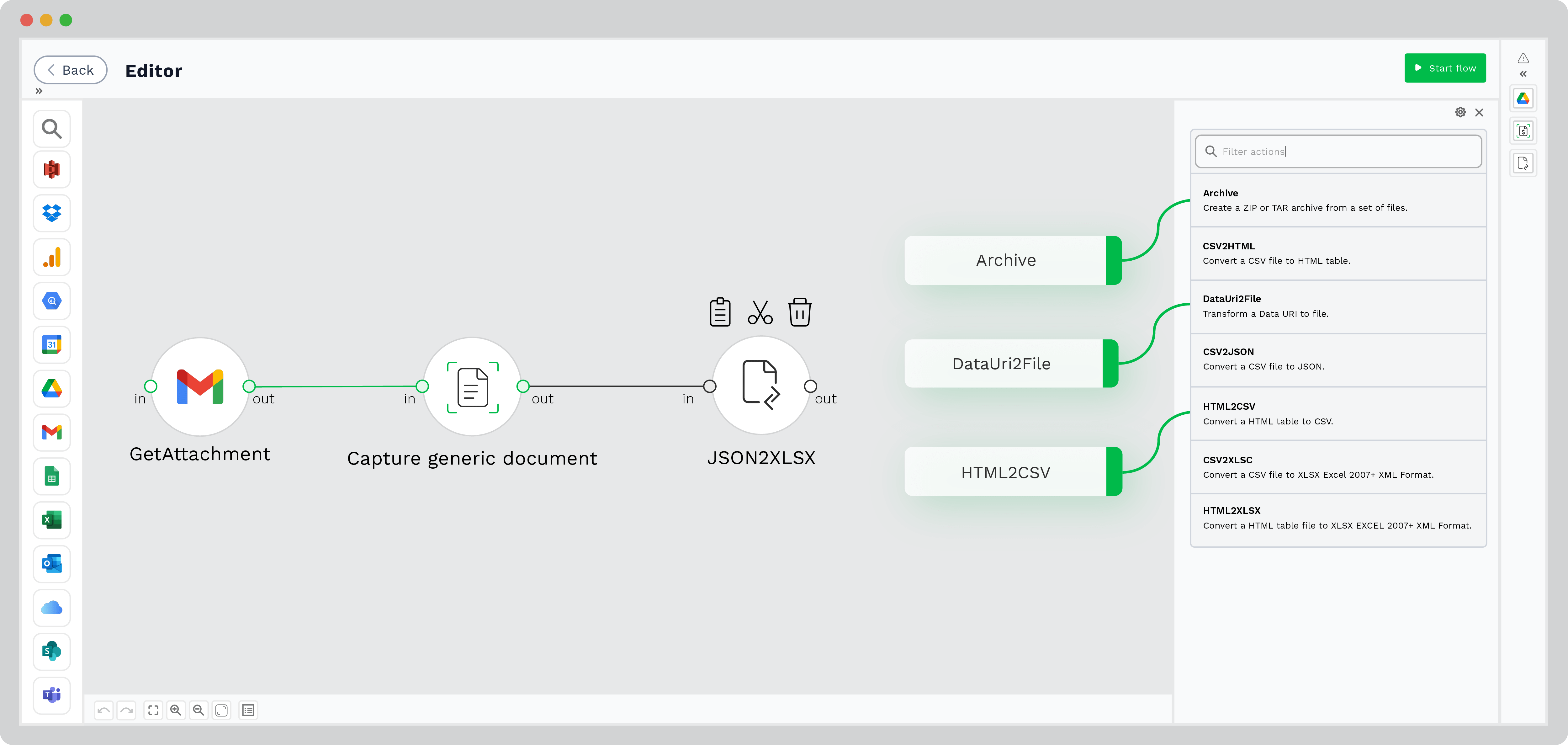
Step 5: Output to your HR system
The extracted data can be seamlessly sent into the company’s ATS or HR software, or any preferred destination to further optimize the recruitment process in the format you chose via API.
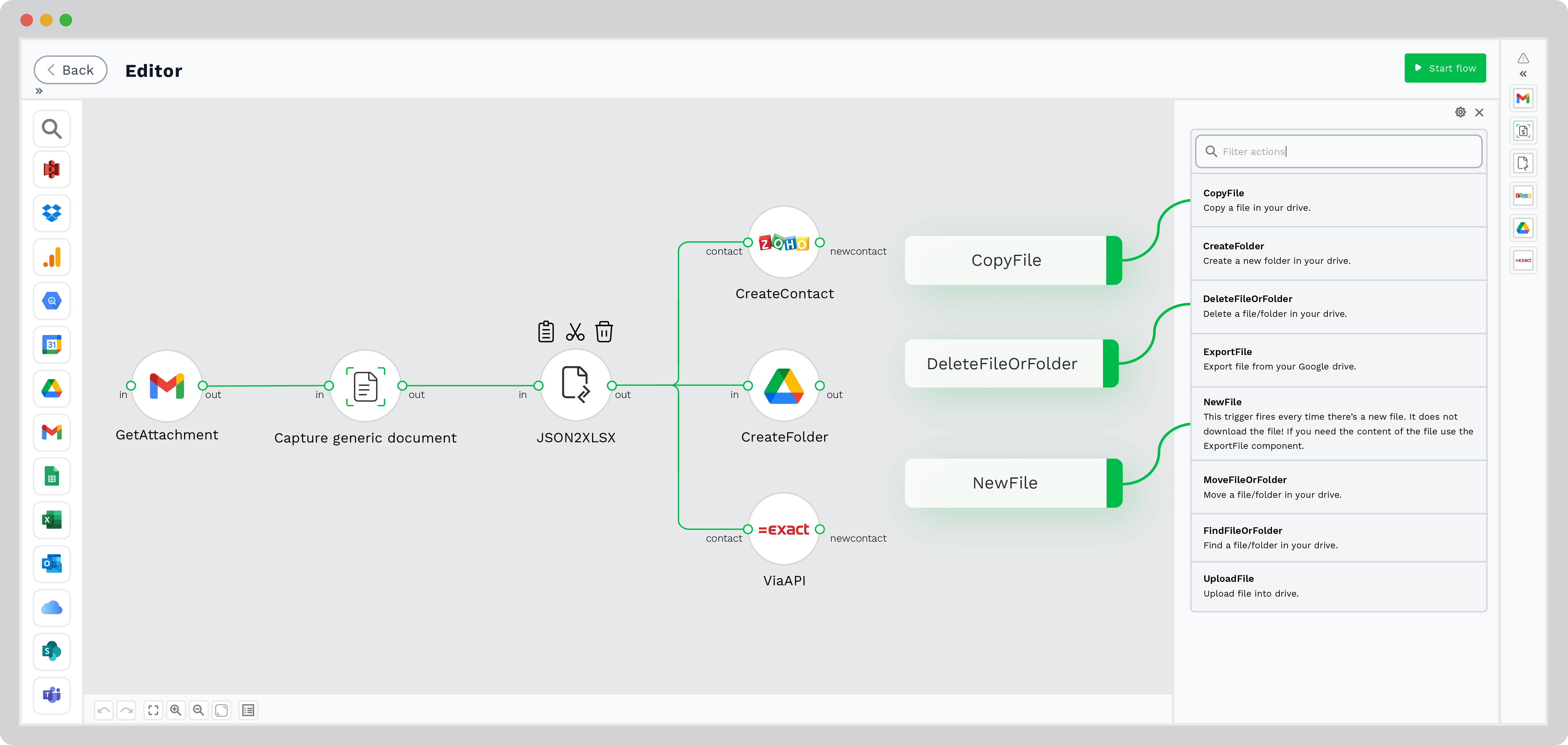
With Doxis AI.dp, the hiring process becomes a breeze for recruiters and applicants.
Conclusion
Resume parsing with Doxis AI.dp not only boosts the efficiency and fairness of the recruitment process but also ensures that businesses stay ahead in the competitive talent acquisition game. By harnessing Doxis’ resume parsing technology, companies can transform their recruitment strategy, ensuring they attract and retain the best talent for their teams.
Ready to take your recruitment process to the next level? Please contact us, or book a demo below!
FAQ
Resume parsing is the process of using software to automatically read resumes, extract key details such as contact info, skills, experience, and education, and convert them into structured data for easy searching and filtering inside Applicant Tracking Systems (ATS).
It typically involves five steps:
1. Reading resumes via OCR from various input sources.
2. Identifying sections like “Work Experience” or “Education” with NLP.
3. Extracting named entities (dates, skills, companies).
4. Structuring the data into formats like JSON, XML, or CSV.
5. Storing/searching it in ATS or HR databases for quick matching.
Efficiency, scalability, searchability, consistency, and reduced bias through data anonymization. Doxis adds advantages like custom fields, bulk uploads, multilingual parsing, and strong compliance standards.
Yes: Keyword-based parsing, Statistical parsing and AI/ML-based parsing (most accurate and adaptable)
Doxis AI.dp achieves up to 99% extraction accuracy for supported formats, with customizable field extraction and human-in-the-loop validation where needed.
Advanced AI/ML parsers can process non-standard formats, but extreme layouts may still require manual review. Doxis offers custom prompts to capture unique fields.
Through API, SDK, or the Doxis AI.dp platform, which supports direct connection to ATS, HRM systems, and cloud storage. Integration typically takes days to weeks depending on complexity.
Yes, Doxis ensures all parsing workflows meet GDPR, HIPAA, and ISO requirements, with data anonymization available for sensitive information.
Yes, resumes in multiple languages are supported for global recruitment efforts.