
Did you know that manually processing a single purchase order can cost your business between $30 and $60?
It’s not just about the money, either. Recent benchmarks show that manual cycles often drag on for 8 to 12 hours per document, creating a bottleneck that slows down your entire supply chain. From typos and lost emails to mismatched records, the risks of manual entry are high, but the cost of inaction is even higher.
But what if you could slash that time to just minutes and extract PO data automatically, no matter the layout, file type, or language?
Well, you can! With the help of modern Intelligent Document Processing (IDP), extracting data from purchase orders is faster, more accurate, and far more scalable than manual methods. In this article, we’ll walk you through what PO data extraction is, how it works, and how tools like Doxis can simplify the process.
Key Takeaways
- The best way to extract PO data is automated – Compared to manual methods, automation captures purchase order data quickly and reliably, no matter the format or volume.
- There are three main methods: manual, online tools, and automated – Manual entry offers control but lacks scalability. Online tools are easier but limited. Automation combines speed, accuracy, and scalability for long-term success.
- Doxis works across various industries – Real-world use cases from Bulthuis, Roamler, Mechan, and GLS show how Doxis’ PO extraction helps different sectors scale smarter.
- Setting up automation with Doxis is simple – From creating a preset to setting input/output flows, the process is intuitive and doesn’t require technical expertise.
What is Purchase Order Data Extraction?
A purchase order (PO) is a commercial document issued by a buyer to a supplier, confirming an intent to purchase goods or services. It typically contains details such as purchase order number, buyer/supplier details, order date, line items (product names, SKUs, quantities, unit prices), subtotals, tax, and total amount, and delivery address and payment terms.
Purchase order data extraction is the process of capturing data from a PO, whether it’s a scanned PDF, image file, or email attachment, and converting it into a structured digital format.
An important thing is the extraction method you’ll choose. For example, you can, instead of manually retyping this information into an ERP system or spreadsheet, let an automated extraction software do the work for you.
Let’s see what other methods are out there.
Methods to Extract Data from Purchase Orders
The journey of PO data extraction technology has significantly evolved over the years. To help you decide what’s best for your needs, let’s take a closer look at the pros and cons of the most popular 3 methods businesses use.
Manual data extraction
This method is often seen as the most straightforward option, especially for smaller businesses or teams with limited resources. It requires no initial investment and gives full control over the process.
However, there’s a catch: manually extracting data from purchases is incredibly time-consuming and prone to human error. The more POs you handle, the harder it becomes to keep up with the workload, and the higher the chances of mistakes.
Another minus is that it doesn’t scale well, meaning as your company grows, so will your reliance on manual labor.
Using online tools to extract data
Usually, the tools that can be found online can offer a more efficient solution for many businesses. These tools are generally easy to set up and use, accessible from anywhere with an internet connection, and can speed up the extraction process compared to manual methods.
They’re typically cost-effective, especially for smaller businesses. However, online tools often lack the customization needed for complex POs and might not always offer the accuracy you need, especially with varying formats.
Additionally, using cloud-based tools comes with some data security concerns and the possibility of disruptions if your internet connection is unstable.
Automatic extraction
The most advanced option is automated software, such as AI-powered document processing platforms. These systems can process a high volume of POs in a fraction of the time it would normally take, with accuracy that minimizes human error. Also, automated solutions are highly scalable, making them perfect for growing businesses.
It works like this: Optical Character Recognition (OCR) converts images and scanned text into machine-readable data, no matter the format. Then, machine learning and AI models classify and extract the key elements you need. No matter if it’s one document or a thousand, the process stays fast, accurate, and consistent every time.
Though the initial investment can be high, the long-term savings from reduced labor costs and improved accuracy often make it worth the price. Plus, advanced features like fraud detection and system integration help streamline the process even further.
Ultimately, choosing the right approach depends on details such as your business’s size, needs, and resources. For companies looking to scale efficiently, automated software is likely the best option, but for smaller businesses or those with simpler needs, manual methods or online tools might still do the trick.
If the automated method sparked your interest but you’re not sure how it might work, here’s a simple step-by-step guide on how to extract data from POs using our platform.
How to Automatically Extract Data from Purchase Orders
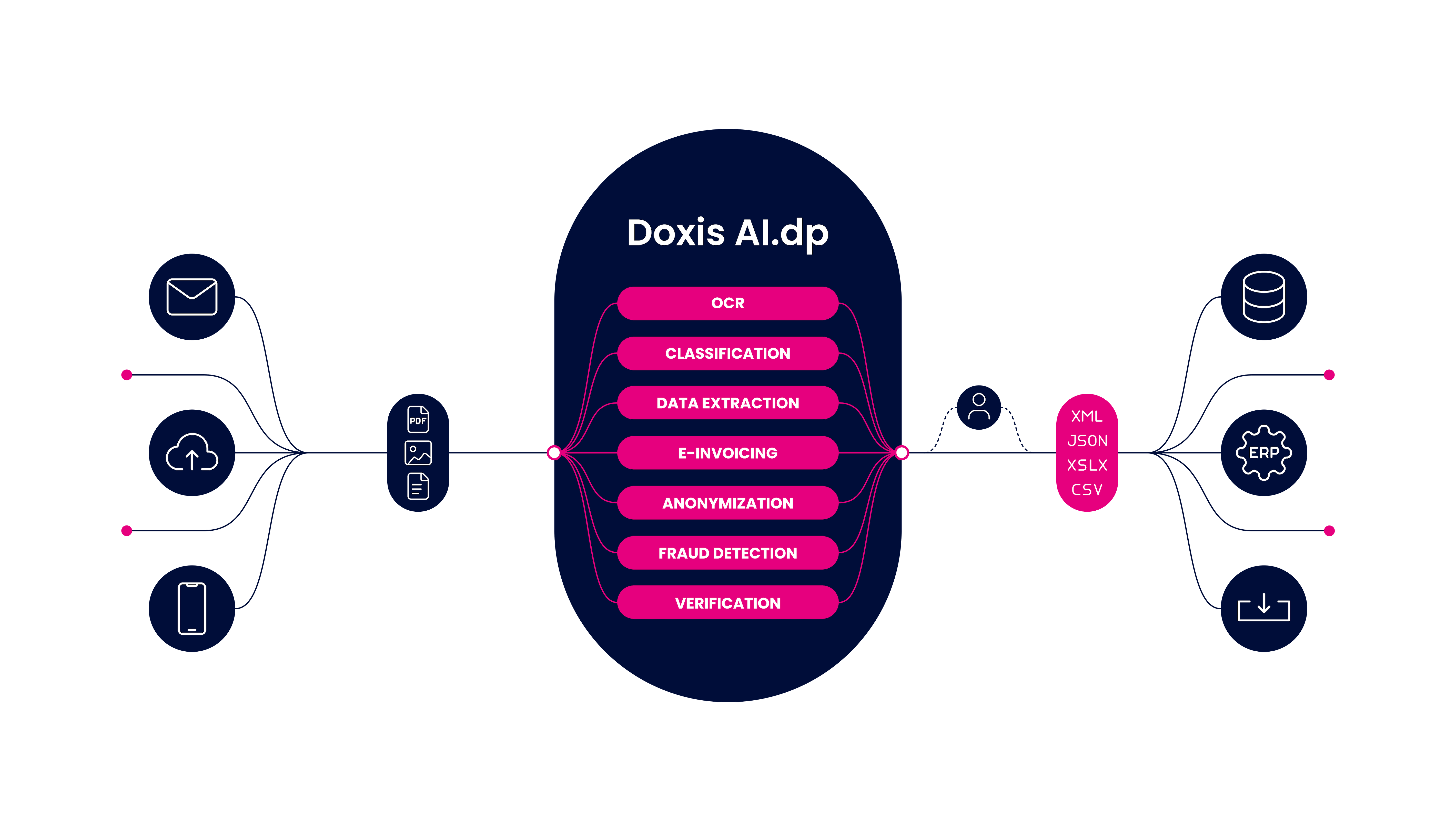
Doxis AI.dp is an Intelligent Document Processing (IDP) platform that enables you to automate all kinds of document workflows, from purchase order outsourcing to document digitization.
For this specific use case, the platform uses Purchase Order OCR, a powerful technology that automatically extracts data from purchase orders, transforming scanned documents, PDFs, or images into structured, machine-readable formats.
And the best part? You can try it out for free!
Let’s take you through the process step by step.
Let’s take you through the process step by step.
Step 1: Sign up on the platform
To get started, sign up for free on the AI.dp platform by providing your email address, password, and basic details about you and your use case. Once registered, you’ll receive €25 in free credits to explore the platform’s features and capabilities.
After signing up, create an organization within the platform and set up your first project to access the available services.
Because you want to extract data from purchase orders, enable the Document Capture: Financial Model and the Flow Builder. The Financial Model was extensively trained on thousands of documents, making it the best choice for our use case.
If you need help or you’re interested in finding out more, check out our documentation or video tutorials for additional guidance.
And just like that, you’re ready to roll with document processing!
Step 2: Create a preset
The next step is to create a document-capturing preset; a preset is a custom configuration that defines which data fields to extract from your documents, tailored to your specific needs.
Setting up a preset is easy: click on the Financial Model within the AI.dp platform, create a new preset, and name it.
The document we used as a sample was a purchase order in PDF format.
Next, select the components you want to be extracted. For this example, choose Financial, which contains commonly used financial fields like supplier details, amounts, VAT information, etc.
Additionally, enable the Line items component to extract detailed data such as purchased products and quantities from documents like invoices. This depends on your use case. Feel free to customize your preset any way it’s useful to you.
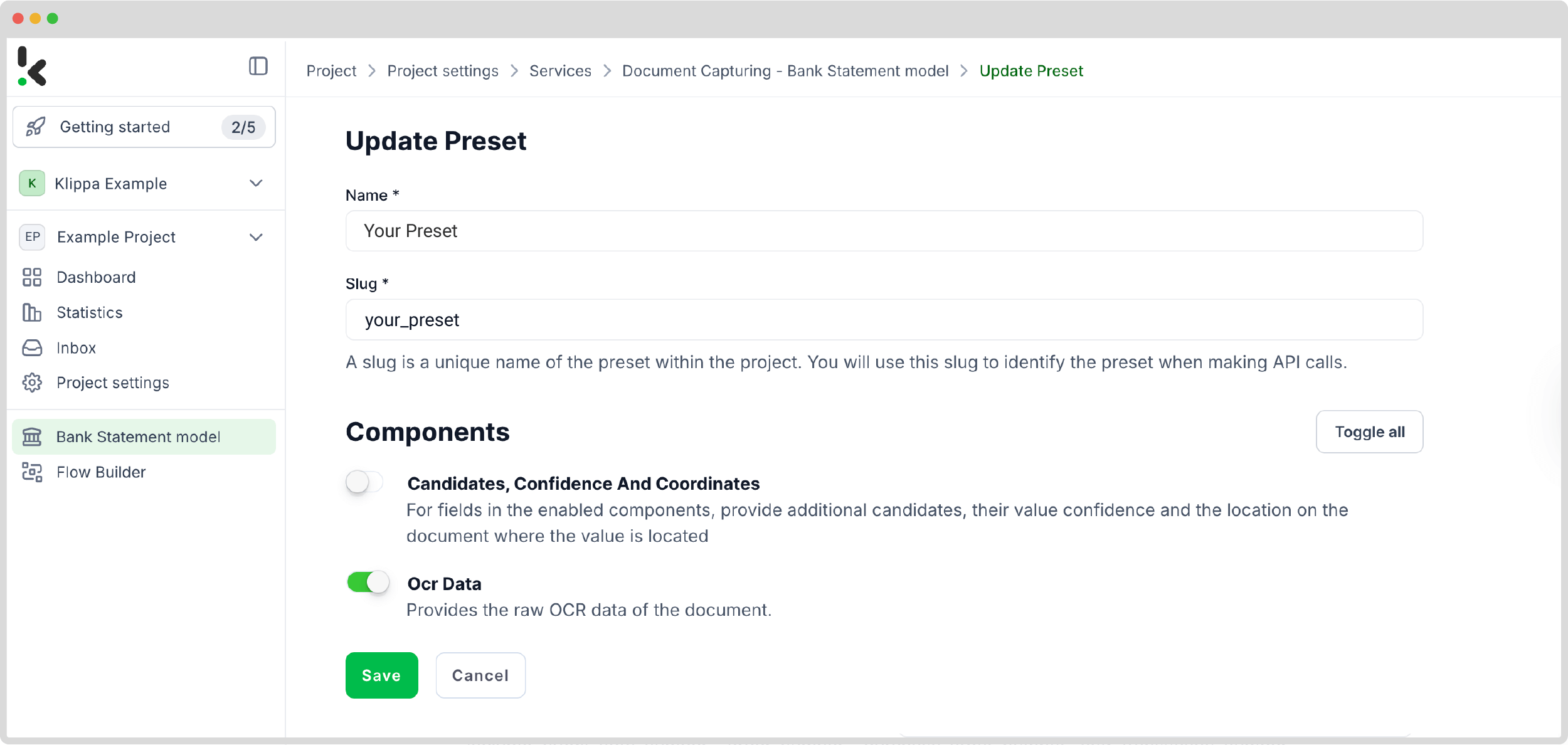
Once satisfied with the preset, click Save to finalize your settings. With your custom preset in place, you’re ready to proceed to the next step: building your flow for automated data extraction.
Step 3: Select your input source
Now that your preset is ready, let’s create a flow in the Flow Builder to automate the extraction process. In essence, a flow is a sequence of steps that define how your files are processed and how their data is extracted.
Start by navigating to the Dashboard, clicking Flow Builder, and then New Flow. You can choose to use a template or to make it from scratch. To better exemplify the flow, we selected the From Scratch option to build the flow up. Next, select a trigger for your flow; this could be a new file uploaded to Google Drive, an email attachment, or an event in your database.
For this example, let’s use Google Drive as the trigger. Select New File, connect your Google account, and choose the Parent folder where your documents are stored.
Important: Check the Include File Content box to ensure that the system processes the file’s data!
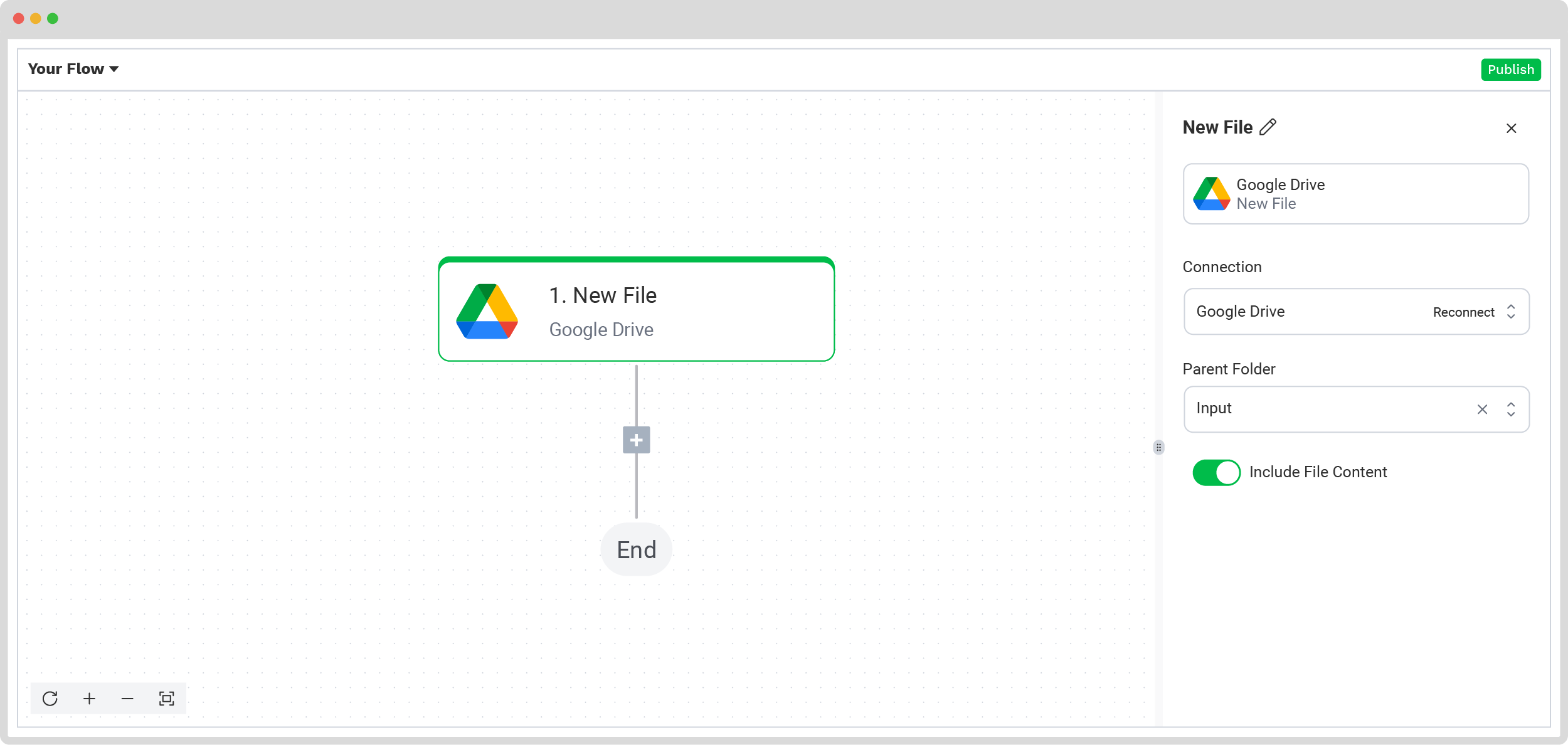
Test this step by clicking on Load Sample Data; remember to have at least one sample document in your input folder while setting up your flow.
Step 4: Capture and extract data
Next, it’s time to extract the necessary data. Add another step by clicking the + button and search for Doxis AI.dp -> Document Capture: Financial model. Connect it to AI.dp and choose the preset you created in Step 2.
Then, configure the File or URL field by selecting New File -> content. Use the data selector to define the content to be processed and run a test to ensure everything is working correctly. Once the test is successful, move on to the next step: setting up your output destination.
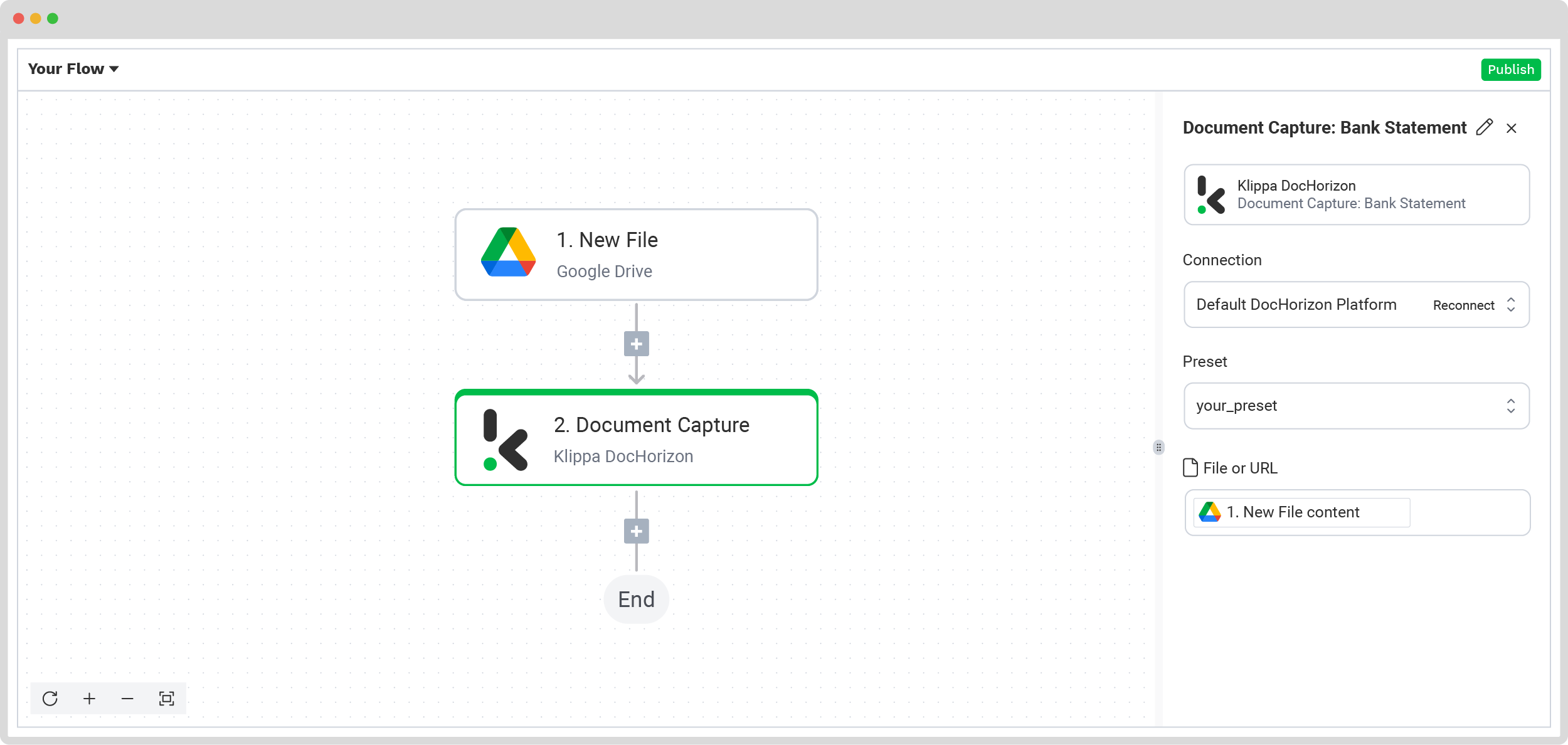
Step 5: Set up the output destination
With your flow taking shape, the final step is to define where the processed data will be sent. AI.dp allows you to store the extracted JSON data in cloud storage, integrate it with an ERP system, or send it to an accounting platform.
For this example, let’s use Google Drive as the output destination, selecting the Create New File option.
Connect your Google account and specify the file name. For convenience, let’s use the invoice number as the file’s name. Click on the box to open the Data Selector menu and navigate to Document Capture -> components -> financial -> invoice_number.
Next, choose the content to include in the file. Select all data captured by your preset by navigating to Document Capture: Financial Document -> components. Test this step to ensure the file is created correctly with all the required data.
Good to know: Once you extract the data from your documents, you will receive it in JSON format by default. But if you want your data to be compatible with other applications, you can convert it again to your desired format, such as HTML, CSV, or XLSX.

Finally, test the entire flow to confirm everything is functioning as expected.
And that’s it! Your automated flow for extracting data from PDF files is complete.
And remember: if you’re processing a high volume of documents, you don’t have to set up the flow yourself! Feel free to reach out to us because we’d love to help you out!
Key Benefits of Automating PO Data Extraction with Doxis
Manual PO processing takes time, costs money, and leaves room for errors. Doxis changes that by automating the full data extraction process, so your procurement runs faster, leaner, and more reliably. Here’s what you’ll gain:
- Time savings. No more hours spent on data entry or combing through each PO. Doxis’ automation solution can process hundreds, even thousands, of purchase orders in seconds and can eliminate the need for manual entry.
- Cost reduction. With less manual work, you spend fewer resources on processing and correcting errors. That means lower labor costs, fewer payment delays, and more efficient use of your budget.
- Improved compliance and audit trails. Every PO is processed consistently. No skipped fields. No typos. You get clean, verified data that meets internal controls and regulatory requirements. Plus, Doxis automatically creates an audit trail for every transaction.
- Scalability and flexibility. As your business grows, Doxis scales with you. There’s no need to hire more staff or overhaul your systems because our flexible solution fits seamlessly into your workflows, across departments and geographies.
Automating purchase order data extraction does more than save time. It helps businesses across industries work faster, reduce manual errors, and keep systems in sync. Let’s see in which industries this happens.
Industries That Benefit from Purchase Order Data Extraction
From retail and logistics to finance, tech, and wholesale, companies are using Doxis to streamline procurement and boost efficiency. Below, you’ll find the industries that benefit the most, with real-world examples from companies that improved their processes through Doxis’ solutions.
Manufacturing
Manufacturers process thousands of POs daily, each containing crucial details like part numbers, quantities, prices, and delivery terms. AI‑driven extraction captures these fields accurately from PDFs, scans, or emails, automating procurement workflows, feeding ERP systems, and reducing manual errors.
Even though not in the manufacturing sector, the following company automated its invoice data extraction, which is extremely relevant for manufacturing operations managing large volumes of supplier invoices.
Due to this, Bulthuis, a major Dutch distributor of truck and trailer parts, achieved faster processing, greater financial control, and improved data accuracy. With automated OCR extraction, manual workload dropped significantly, enabling real-time cost tracking and scalable financial operations across its eight national branches.
Retail
Retailers receive orders in diverse formats (PDFs, emails) from numerous vendors. Capturing data from vendor details and SKUs to quantities and pricing, automatic PO enhances inventory control, speeds up order processing, and ensures accurate supplier reconciliation.
Roamler, a leading Dutch company specializing in crowd-supported solutions, enjoys a 91% reduction in document processing time, up to 99% accuracy with the Human-in-the-Loop feature, effortless scalability across Europe, and document processing in multiple languages.
Wholesale & Distribution
Wholesalers manage high volumes of B2B orders. Accurate, fast PO extraction – validated against ERP master data – automates order intake, reduces fulfillment delays, and scales procure-to-pay operations efficiently.
Mechan, a Dutch provider of machinery for agriculture and construction, has transformed its invoice processing with Doxis’ automation. Because of this, they now enjoy smooth ERP migration, quicker approvals, improved accuracy, and a lighter administrative load.
Logistics & Shipping
Logistics providers deal with more than just purchase orders; they also manage dispatch notes, delivery manifests, and customs documents. Doxis’ intelligent OCR extracts key data from each document and cross-checks it automatically. Quantities, destinations, and shipments all line up, reducing errors and avoiding delays at customs.
GLS, one of Europe’s largest logistics companies, now runs fully automated invoice processing with Doxis. The result? Faster approvals, greater accuracy, improved financial oversight, and less operational workload.
As you can see, automating PO data extraction helps businesses in manufacturing, retail, wholesale, and logistics speed up order processing, reduce errors, and scale with ease. What used to be a messy, manual task is now a smooth, data-driven workflow.
Conclusion: Revolutionize Purchase Order Data Extraction with Doxis
Manual data extraction is yesterday’s problem. With Doxis AI.dp, you can automate the entire process – from document upload to structured data output – with speed, accuracy, and security. Whether you’re handling a handful of purchase orders or thousands, the setup stays simple and scalable. Here’s what you get:
- Saved Time: Automate data extraction with Doxis’ OCR technology, eliminating tedious manual entry and speeding up verification.
- Cut Costs: Reduce operational expenses by streamlining fraud detection and document processing.
- Tailored Outputs: Generate customized JSON files to fit your needs, making data management easy.
- Minimized Fraud Risks: Detect altered or forged bank statements instantly, protecting your business from financial crime.
- Compliance: Keep up with KYC, AML, and industry regulations while avoiding hefty fines.
- Seamless Integration: Connect Doxis AI.dp to your existing systems via API or SDK for a hassle-free experience.
At Doxis, simplicity is a core value; that’s why we are constantly improving our documentation to make it easier for you to implement and integrate our platform.
Moreover, all of Doxis’ workflows comply with HIPAA, GDPR, and ISO standards to ensure secure and reliable data processing.
Curious to find out how Doxis’ solution can help you extract data from bank statements? Contact our experts today or book a free online demo below!
FAQ
Purchase order data extraction is the process of automatically capturing fields such as supplier names, order numbers, item details, and totals from purchase orders in PDF, image, or email formats, and converting them into structured digital data for ERP or accounting systems. Updated June 2025, automated methods can reduce errors by up to 99% and cut processing time from minutes to seconds.
Modern Intelligent Document Processing solutions can handle scanned PDFs, digital PDFs, images (JPG, PNG), and email attachments, regardless of layout or language. Doxis supports multilingual purchase orders in over 15 languages.
Doxis uses Optical Character Recognition (OCR) to convert scans into text, then applies AI models to identify and extract fields like supplier details, line items, totals, and PO numbers. This achieves up to 99% accuracy across diverse file formats and layouts.
Yes. Doxis captures SKUs, product names, quantities, unit prices, and tax amounts from purchase orders and invoices, making it ideal for inventory control, procurement automation, and finance operations.
With Doxis AI.dp, you can automatically extract all key fields from a purchase order and deliver them directly into Xero.
1. Upload the purchase order: Add your PDF, scan, or email attachment to Doxis.
2. Data extraction: AI-powered OCR captures supplier details, line items, totals, and PO numbers with up to 99% accuracy.
3. Integration with Xero: Connect via Doxis’ API or Flow Builder to send data into Xero in JSON, CSV, or XLSX format.
This eliminates manual entry and ensures every PO is processed quickly, accurately, and securely, keeping Xero up to date while maintaining compliance.