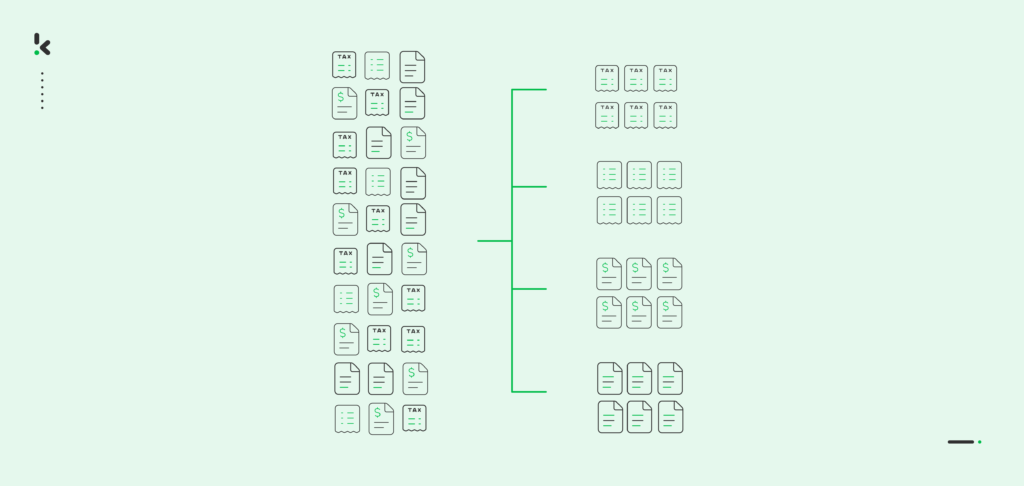
Organisaties hebben dagelijks te maken met grote hoeveelheden documenten, documenten die variëren in type, inhoud of belang. Het nauwkeurig classificeren van deze bestanden kan al snel frustrerend worden, vooral als dit handmatig gebeurt.
Sommige medewerkers zijn verantwoordelijk voor het handmatig ordenen van documenten op basis van deze labels. Dit kost tijd en in het ergste geval raken de bestanden verloren omdat ze onjuist zijn gecategoriseerd.
Dankzij de snelle ontwikkeling van AI technologie besteden werknemers echter niet langer buitensporig veel tijd aan het labelen van documenten en worden deze taken overgelaten aan slimme software.
In deze blog leggen we uit wat documentclassificatie is, leer je meer over het automatiseren ervan en vind je een kant-en-klare oplossing voor het classificeren van je bedrijfsdocumenten. Laten we beginnen!
Key Takeaways
- Documentclassificatie automatiseert bestandsorganisatie, waardoor zoekopdrachten sneller verlopen en workflows efficiënter worden.
- AI-gebaseerde technologieën zoals OCR en Machine Learning stellen bedrijven in staat om documenten nauwkeurig te categoriseren zonder handmatige inspanning.
- Het automatiseren van classificatie vermindert fouten, zorgt voor compliance en verbetert de gegevensbeveiliging, waardoor het essentieel is voor moderne bedrijven.
- Geautomatiseerde software voor documentclassificatie biedt een snelle, vooraf getrainde oplossing voor efficiënt sorteren, waardoor handmatige inspanningen en fouten worden verminderd.
Wat is documentclassificatie?
Documentclassificatie, of documentcategorisatie, is het proces van het labelen en sorteren van documenten in categorieën zodat ze makkelijker te vinden, te beheren en te analyseren zijn. Het doel is om bestanden nauwkeurig te ordenen, zodat je sneller kunt vinden wat je zoekt.
Hoewel het classificeren van documenten op zichzelf een belangrijke taak is, maakt het ook deel uit van een veel groter geheel, namelijk intelligente documentverwerking. Daarom is het sorteren van deze bestanden slechts een van de vele acties die geautomatiseerd kunnen worden om de workflows van documentverwerking te verbeteren.
Het classificeren van documenten kan gedaan worden aan de hand van twee factoren, namelijk tekstclassificatie en visuele classificatie. Sommige van deze factoren zijn terug te vinden in zoekmachines in het echte leven, waardoor gebruikers zonder veel moeite kunnen vinden wat ze zoeken.
Om beter te begrijpen hoe documentclassificatie kan plaatsvinden, is het nodig om een stap terug te doen en eerst het technische proces achter geautomatiseerde documentclassificatie te analyseren.
Soorten documentclassificatie
Zoals eerder vermeld, worden documenten geclassificeerd op basis van hun inhoud, of dat nu tekst of afbeeldingen zijn. Voor elk type documentclassificatie kun je verschillende methoden ontdekken die worden gebruikt om de specifieke inhoud te detecteren en te analyseren.
1. Tekstclassificatie
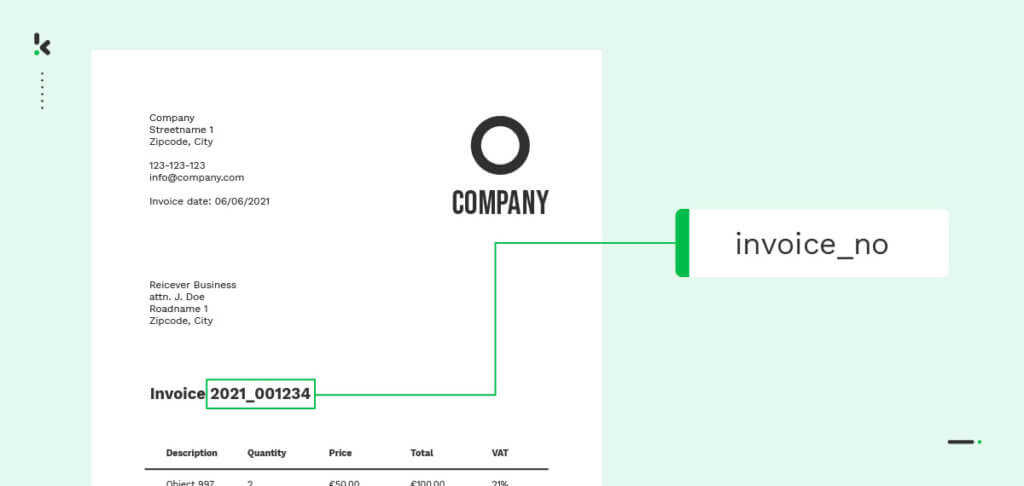
Tekstclassificatie sorteert en verwerkt informatie uit verschillende soorten documenten. Omdat bedrijven voor hun dagelijkse werkzaamheden afhankelijk zijn van bestanden met veel tekst, is tekstclassificatie een belangrijk onderdeel geworden van veel softwareproviders, waaronder OCR-software, om de organisatie en efficiëntie te verbeteren.
Dus hoe werkt tekstclassificatie? Tekstclassificatie van documenten maakt vaak gebruik van technologieën zoals OCR en NLP, die onder de technologie machine learning vallen.
Optical Character Recognition (OCR):
OCR is een technologie die je helpt tekst te extraheren uit afbeeldingen of gescande documenten en deze om te zetten in een machinaal leesbaar formaat. Vaak wordt deze technologie gecombineerd met kunstmatige intelligentie (AI) en machine learning (ML) om een hoge nauwkeurigheid bij het extraheren van gegevens te bereiken.
Natural Language Processing (NLP):
NLP is een complexere techniek, die verantwoordelijk is voor het verder analyseren van de geëxtraheerde gegevens en het begrijpen van de semantiek van de tekst. NLP maakt het voor computers mogelijk om menselijke taal in een specifieke context te begrijpen, waardoor een zeer nauwkeurig gegevensextractieproces van hoge kwaliteit ontstaat.
Om een document automatisch te classificeren, moet eerst OCR worden gebruikt om informatie te extraheren en NLP om de inhoud van de informatie te begrijpen.
2. Visuele classificatie
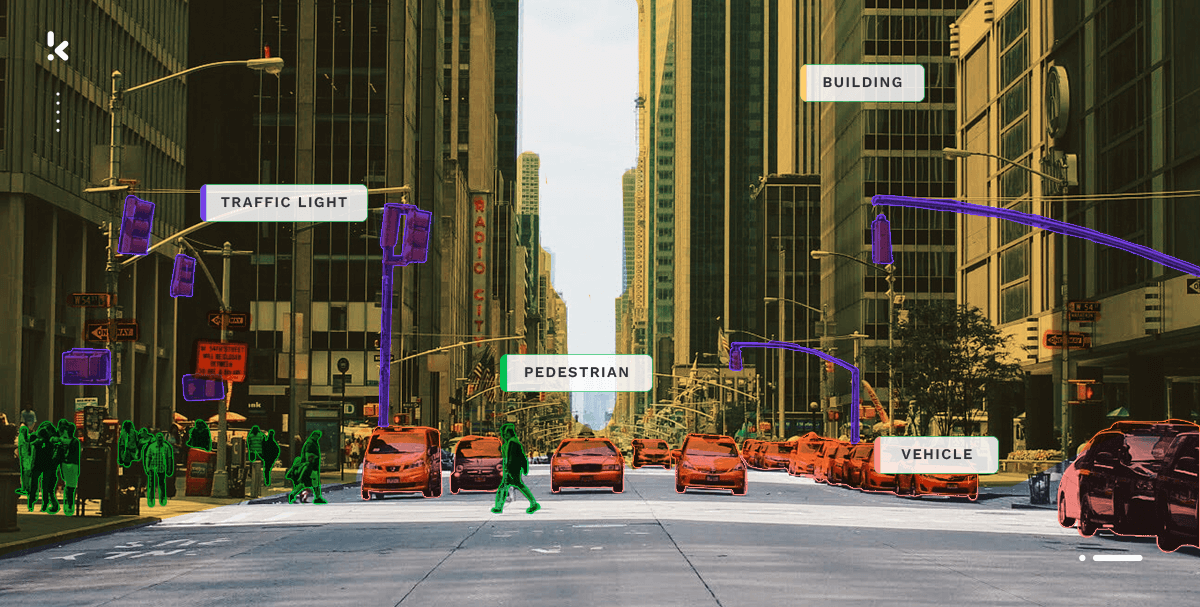
Bij visuele classificatie ligt de nadruk op de visuele structuur van documenten. Afbeeldingen en video’s in een document worden gedetecteerd door de pixels te analyseren die het visuele beeld creëren en vervolgens de inhoud ervan te bepalen. De identificatie en classificatie van afbeeldingen wordt gedaan met behulp van technologieën zoals computer vision en objectdetectie.
Computer Vision:
Computer Vision is een AI-gestuurde technologie die objecten op stilstaande beelden of video’s kan herkennen. Je kunt het gebruiken om objecten in een afbeelding, hun locatie in het document of de actie die in de visuele inhoud wordt weergegeven te detecteren. Computer vision helpt je bij het classificeren van afbeeldingen door filter- en zoekopties toe te passen.
Object Detection:
Objectdetectie wordt toegepast in bedrijfsomgevingen die grote hoeveelheden visuele gegevens moeten beheren en waar classificatie op grotere schaal plaatsvindt. Objectdetectie is bijvoorbeeld verspreid over logistieke afdelingen, magazijnen en voorraden, waar het scannen van barcodes of QR-codes deel uitmaakt van de dagelijkse werkzaamheden.
Nu je bekend bent met de technologieën die worden gebruikt om tekst- en visuele classificatie te verbeteren, gaan we dieper in op het onderwerp en ontdekken we de methoden die worden gebruikt bij geautomatiseerde documentclassificatie.
Methoden voor geautomatiseerde documentclassificatie
Geautomatiseerde classificatie van documenten wordt bereikt met Machine Learning. Het maakt voornamelijk gebruik van NLP, waarvoor grote hoeveelheden gegevens nodig zijn om op te trainen, om patronen in documenten met hoge nauwkeurigheid te detecteren en te definiëren.
Om het model te trainen, voeden we het met reeds bestaande gegevens, die al profiteren van vooraf bepaalde categorieën en sets van kenmerken. Hierdoor kan het model statistische verbanden tussen woorden en zinnen leren.
Machine learning classificeerders verzamelen trainingsdatasets, bijvoorbeeld artikelen, essays of andere tekst die gebruikt kan worden om trefwoorden te extraheren en categorieën te definiëren waar het model op kan leren. Er zijn echter meerdere methoden om documenten te classificeren met behulp van machine learning, die we in de volgende paragraaf zullen behandelen.
Supervised documentclassificatie
Bij supervised documentclassificatie lever je zelf de input, wat betekent dat je het model traint op documenten die al een label hebben. Daarom wordt de classificatie gedaan door de relatie tussen het nieuwe document en de gelabelde historische gegevens te evalueren.
Je geeft het model bijvoorbeeld facturen, kassabonnen en bankafschriften om op te leren. Het model zal goed werk leveren bij het herkennen en classificeren van dit soort documenten. Maar als je het model identiteitsdocumenten laat classificeren, zal dit resulteren in een mislukte poging. Het model kon geen relatie vinden tussen de nieuwe documenten, zoals de identiteitsdocumenten, en de historisch gelabelde gegevens, zoals facturen of bonnetjes, dus werd de classificatie uiteindelijk onnauwkeurig.
Voordelen
- Het is een nauwkeurige classificatie van documenten
- De resultaten zijn eenvoudig te evalueren
Nadelen
- Het vereist een grote trainingsdataset
- Het kan tijdrovend en duur zijn om een grote hoeveelheid gegevens of de trainingsset te labelen
Unsupervised documentclassificatie
Voor unsupervised documentclassificatie is geen trainingsdataset nodig om op te leren. Het heeft als doel documenten te sorteren door hun inhoud te analyseren en verschillen tussen hen te vinden. Het model maakt vervolgens clusters, of categorieën, waarin de gesorteerde documenten worden geplaatst. Hoewel sommige documenten overeenkomsten kunnen delen, zijn de categorieën onbekend voor het model, waardoor er ruimte is voor onzekerheid in de kwaliteit van de classificatie.
Voordelen
- Er is geen gelabelde trainingsdataset nodig
- Het is sneller en goedkoper in gebruik omdat labelen niet nodig is
Nadelen
- Het is moeilijker te evalueren
- Het is minder nauwkeurig dan de supervised methode
Semi-supervised documentclassificatie
Semi-supervised documentclassificatie bestaat uit een combinatie van supervised en unsupervised classificatie. Het gebruikt zowel gelabelde als ongelabelde trainingsdatasets, waardoor de prestaties van beide classificatiemethoden worden verbeterd, maar geen van beide wordt geperfectioneerd.
Voordelen
- Verbetert de nauwkeurigheid van beide classificatiemethoden
- Er zijn niet zoveel trainingsgegevens nodig als bij supervised classificatie
Nadelen
- Het is moeilijker te implementeren dan zowel de supervised als de unsupervised methode
- Het kan minder nauwkeurig zijn dan een volledig supervised classificatie
Nu we hebben geleerd over de verschillende classificatiemethoden die machine learning gebruiken, zullen we bekijken hoe het proces van documentclassificatie automatiseren er eigenlijk uitziet.
Hoe kun je automatisch documenten classificeren?
Automatische classificatie van documenten maakt gebruik van Deep Learning (een onderdeel van Machine Learning) methoden om bestanden te sorteren in verschillende categorieën, zonder menselijke input. Voor dit proces volg je een eenvoudig proces van drie stappen, dat als volgt verloopt:
1. Verzamel een dataset
Om het classificatiemodel te trainen, moet je eerst de gegevens voorbereiden. Dit betekent dat je minstens 20 datapunten per label moet verzamelen, oftewel 20 documenten per categorie. Dit verhoogt de nauwkeurigheid van de uitvoer, waardoor je een kwalitatief eindresultaat krijgt. Het algoritme categoriseert de uitvoer op basis van de specifieke gegevens waarop het getraind is.
Als je bijvoorbeeld alleen facturen wilt classificeren, zou het logisch zijn om het model te trainen op meerdere facturen. Als je echter een ander documenttype wilt classificeren, bijvoorbeeld een kassabon, kan het model moeite hebben om de gewenste documenten nauwkeurig te classificeren.
2. Train het model
Deze stap kan tijdrovend en duur worden, afhankelijk van de gekozen classificatiemethode, zoals supervised, unsupervised of semi-supervised. Hoewel het in feite een extra taak is, is het noodzakelijk om de meest nauwkeurige resultaten te krijgen.
3. Evalueer de resultaten
Het vergelijken van de resultaten met de verwachtingen is een essentiële procedure om ervoor te zorgen dat het model presteert zoals bedoeld. Dit kan worden gedaan door de resultaten van de classificatie te vergelijken met een al eerder geprepareerd document, waardoor een nauwkeurige weergave in de vergelijking wordt gegarandeerd.
Om dit proces echt te begrijpen, moet je alle tijd nemen die je nodig hebt. Als je het model overhaast onnauwkeurige gegevens geeft of niet genoeg datapunten, maak je het jezelf op de lange termijn alleen maar moeilijker. Door te vertragen en deze procedure echt te begrijpen, krijg je de beste resultaten van je inspanningen op het gebied van documentclassificatie.
Wil je een snellere manier?
In plaats van je eigen model te bouwen en te trainen, kun je Doxis AI.dp gebruiken, een AI-gestuurd platform om document workflows te automatiseren, dat documenten automatisch classificeert zonder handmatig werk.
Probeer het nu met €25 gratis credits om moeiteloze documentclassificatie te ervaren.
We begrijpen dat je niet helemaal zeker weet of het implementeren van automatische gegevensclassificatie voordelig is voor de behoeften van je bedrijf of niet. Laat ons daarom wat licht werpen op enkele van de voordelen die automatische classificatie van documenten voor je bedrijf kan opleveren.
De voordelen van documentcategorisatie voor bedrijven
Door documenten automatisch te categoriseren, kan je organisatie de dagelijkse bedrijfsprocessen vlotter uitvoeren. Enkele voordelen van het implementeren van deze praktijk zijn:
- Het bespaart je bedrijf tijd en middelen: Automatische documentclassificatie organiseert en analyseert grote hoeveelheden documenten, waardoor je een aanzienlijke hoeveelheid tijd en financiële middelen bespaart.
- Het helpt je bij het identificeren van frauduleuze documenten: Het automatisch classificeren van documenten betekent ook het identificeren van frauduleuze documenten door anomalieën of menselijke fouten in deze bestanden. Automatisering helpt dus bij het terugdringen van documentfraude in je organisatie, zoals factuurfraude.
- Het helpt het sorteren van documenten te automatiseren: Het handmatig classificeren van documenten kan gemakkelijk verwarrend worden, waardoor je gaat twijfelen over welk label je eraan moet geven, met fouten en onnauwkeurige beslissingen tot gevolg. Automatische classificatie lost dit probleem op door de documenten te sorteren of zelfs te indexeren op basis van categorieën die jij en je team vooraf hebben bepaald.
Deze voordelen klinken in het begin misschien niet impactvol, maar ze kunnen een groot verschil maken in de manier waarop je zaken doet. Laten we, om dit te begrijpen en het grotere plaatje te zien, enkele praktijkvoorbeelden van automatische documentclassificatie bespreken.
Praktijkvoorbeelden en toepassingen voor documentclassificatie
De theorie achter documentclassificatie kennen is niet genoeg om het gebruik ervan echt te begrijpen. Laten we een aantal gebruikssituaties bespreken waarbij geautomatiseerde classificatie van documenten een positieve invloed heeft op jouw bedrijf:
Spam detectie in e-mails
Geautomatiseerde software voor documentclassificatie helpt bij het identificeren van e-mails die in de categorie spam vallen. Deze bevatten meestal onnatuurlijk klinkende tekst, grammaticafouten of spelfouten, die verdacht zijn in vergelijking met normale e-mails. Met behulp van documentclassificatie worden de e-mails die deze selectiecriteria hebben, verzameld in de bijbehorende spam-inbox, zodat jouw bedrijf beschermd blijft tegen gevaarlijke links of ongevraagde e-mails.
Feedback van klanten verwerken
Door de betekenis en toon van de tekst te analyseren, waarvan we ontdekten dat dit met behulp van NLP gebeurt, kun je positieve feedback scheiden van constructieve feedback. Daarom krijgt jouw organisatie betere toegang tot suggesties die gericht zijn op het verbeteren van bedrijfsprocessen, waardoor je betere diensten kunt leveren aan je klanten.
Vergemakkelijken van klantenservice
Met behulp van documentclassificatie kunnen medewerkers van de klantenservice eenvoudig claims, terugbetalingen, vragen of andere opmerkingen scheiden op basis van de tekst. Dit verbetert de efficiëntie van de workflow, doordat de bijbehorende opmerkingen naar de betreffende afdelingen worden gestuurd.
Digitalisering van documenten
Jouw bedrijf kan meerdere soorten documenten verwerken, bijvoorbeeld facturen, kassabonnen of contracten. Als je software voor het scannen van documenten gebruikt om het document te scannen, te digitaliseren en te labelen via classificatie, stroomlijn je je processen aanzienlijk.
Jouw bedrijf verdient software die alle bovenstaande toepassingen, en meer, mogelijk maakt. Doxis AI.dp helpt je elke documentverwerkingsworkflow te automatiseren, inclusief documentclassificatie, en biedt je organisatie voordelen waarvan je lang kunt profiteren.
Automatiseer meer dan alleen je documentclassificatie met Doxis
Doxis AI.dp is een intelligente documentverwerkingsoplossing, aangedreven door AI, gericht op het stroomlijnen van de dagelijkse bedrijfsvoering op schaal. Het helpt je niet alleen bij het nauwkeurig classificeren van documenten, maar helpt je bedrijf ook op andere gebieden:
- Gegevensvelden extraheren uit een groot aantal documenttypen met behulp van zeer nauwkeurige OCR
- Gegevens en afbeeldingen automatisch anonimiseren voor maximale naleving van de privacyregels
- Documenten converteren naar het gewenste formaat, zoals CSV, XML, JSON of PDF
- Profiteer van naadloze integratie met bestaande softwareoplossingen via SDK of API
- Voorkom fraude in jouw organisatie met geautomatiseerde documentverificatie
- Classificeren en categoriseren van een groot aantal documenttypes
- Documenten verwerken op basis van specifieke gegevensvelden
- Maak gebruik van een AI-platform voor end-to-end documentverwerking en -automatisering
Met Doxis AI.dp is je bedrijf klaar voor succes. Als je geïnteresseerd bent in meer inzicht in ons product, neem dan contact op met onze experts of boek een demo hieronder!
FAQ
Als je bedrijf dagelijks grote hoeveelheden documenten verwerkt en worstelt met handmatige organisatie, verloren bestanden of traag terugvinden, dan kan geautomatiseerde documentclassificatie tijd besparen, fouten verminderen en de naleving verbeteren.
Ja, veel AI-classificatietools ondersteunen meertalige documentverwerking, inclusief OCR- en NLP-mogelijkheden voor het extraheren en analyseren van tekst in verschillende talen.
Veel AI-gebaseerde classificatiesystemen, zoals Doxis, bieden automatische redactie en anonimisering, waardoor privacy compliance en gegevensbeveiliging gegarandeerd zijn zonder handmatige tussenkomst.
Je kunt AI-gestuurde classificatiesoftware testen met een gratis proefversie of met vooraf getrainde oplossingen zoals Doxis AI.dp, die nu €25 gratis krediet biedt om te beginnen..
Ja, Doxis AI.dp is volledig AVG-compliant en volgt strenge regels voor gegevensbeveiliging en privacy, waaronder ISO 27001, HIPAA en SOC 2 normen. Je documenten worden veilig verwerkt, met versleuteling en toegangscontroles.