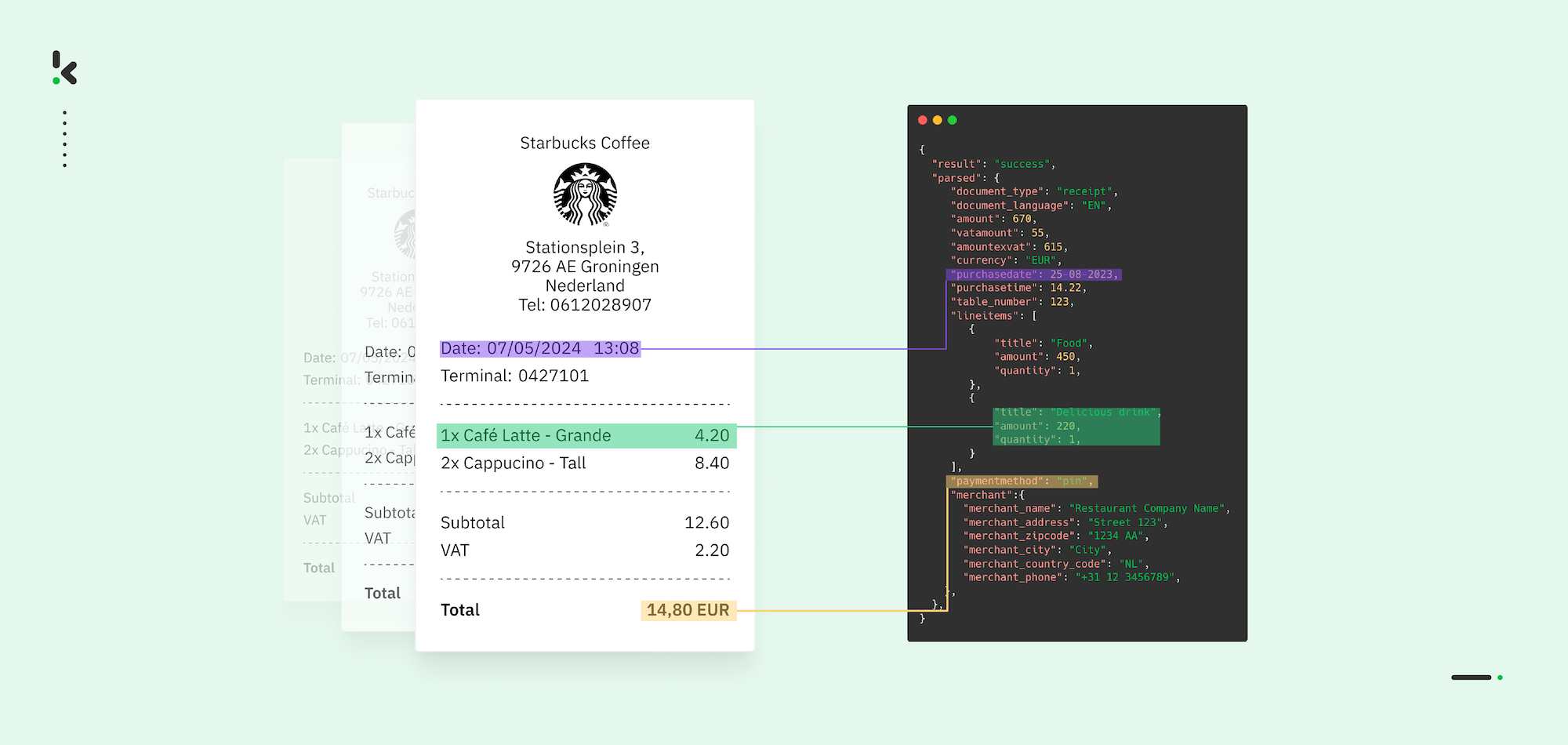
Je weet hoe frustrerend bonverwerking kan zijn als je zakelijke onkosten, boekhouding of financiële processen beheert. Papieren bonnetjes vervagen, digitale bonnetjes raken begraven in inboxen, en geen twee formaten zien er ooit hetzelfde uit. Het handmatig invoeren van deze data is saai, foutgevoelig en kost tijd die je liever aan belangrijker werk besteedt.
Maar er is een betere manier. Automatisering haalt het gedoe weg door belangrijke details direct te extraheren en nauwkeurigheid te waarborgen zonder handmatige inspanning. In deze gids laten we zien hoe data extractie uit bonnetjes werkt, welke veelvoorkomende uitdagingen bedrijven tegenkomen en hoe AI-powered oplossingen het proces kunnen transformeren.
Laten we erin duiken!
Key Takeaways
Data extractie uit bonnetjes automatiseert de omzetting van ongestructureerde bontekst naar gestructureerde, machineleesbare data voor boekhouding, compliance en analytics. Een typische workflow volgt vijf belangrijke stappen:
- Vastleggen: Scan of fotografeer een papieren bon, of upload een digitale PDF of afbeelding.
- Converteren: Gebruik Optical Character Recognition (OCR) om de tekst te lezen en te digitaliseren.
- Extraheren: Identificeer en verzamel velden zoals naam van de leverancier, datum, totalen, belastingen, kortingen en gespecificeerde aankopen.
- Structureren: Organiseer de data in formaten zoals JSON, CSV, XML of XLSX voor integratie.
- Verifiëren: Pas validatieregels toe of gebruik Human-in-the-Loop controles om compliance te waarborgen en fraude te detecteren.
Geautomatiseerde oplossingen, zoals Doxis AI.dp, combineren OCR, Artificial Intelligence en Machine Learning om met uiteenlopende formaten om te gaan, de nauwkeurigheid te verbeteren en naadloos te integreren met ERP- of boekhoudsystemen.
Wat is data extractie uit bonnetjes?
Data extractie uit bonnetjes is het proces waarbij belangrijke gegevens van bonnetjes worden geïdentificeerd en omgezet in gestructureerde, machineleesbare data die kan worden gebruikt voor boekhouding, belastingaangifte en onkostenbeheer. De gescande informatie bevat doorgaans details zoals naam van de leverancier, datum, bedrag, enzovoort.
Traditioneel vertrouwden bedrijven erop dat medewerkers deze data handmatig invoerden in spreadsheets of boekhoudsoftware. Tegenwoordig gebruiken geautomatiseerde oplossingen AI en Optical Character Recognition (OCR) om bonnetjes te scannen, fouten te corrigeren en relevante waarden te extraheren. Zodra de data is geëxtraheerd, wordt deze automatisch geformatteerd en geïntegreerd in onkostenbeheersystemen, boekhoudsoftware of tools voor belastingrapportage.
Methoden om data uit bonnetjes te extraheren
Bedrijven kunnen data uit bonnetjes extraheren met handmatige, semi-geautomatiseerde of volledig geautomatiseerde methoden. De juiste keuze hangt af van factoren zoals het volume aan bonnetjes, de variatie in formaten, de gewenste nauwkeurigheid en de beschikbare middelen.
Handmatige gegevensinvoer
Handmatige gegevensinvoer houdt in dat bondetails zoals naam van de leverancier, datum, totaalbedrag en belasting met de hand worden overgetypt in spreadsheets of boekhoudsystemen.
Voordelen:
- Geen technische setup vereist
- Lage kosten bij zeer kleine aantallen bonnetjes
Nadelen:
- Zeer tijdrovend bij hoge volumes
- Foutgevoelig, wat kan leiden tot problemen met compliance en rapportage
- Moeilijk schaalbaar voor groeiende bedrijven
Tip: Gebruik handmatige invoer alleen voor incidentele bonnetjes of als fallback wanneer geautomatiseerde systemen een document niet kunnen verwerken.
Template-based OCR
Template-based OCR (Optical Character Recognition) maakt gebruik van vooraf gedefinieerde lay-outs om bonnetjes te lezen. Het systeem scant de afbeelding, matcht die met een template en haalt data op uit specifieke posities.
Voordelen:
- Hoge nauwkeurigheid bij bonnetjes met gestandaardiseerde lay-outs
- Sneller dan handmatige invoer bij consistente formaten
Nadelen:
- Werkt niet goed bij gevarieerde of onbekende lay-outs
- Kan zich niet eenvoudig aanpassen aan nieuwe bonontwerpen zonder nieuwe templates
- Heeft moeite met handgeschreven tekst of beschadigde/zwakke prints
Tip: Template-based OCR is geschikt voor organisaties met één of twee vaste bonformaten, bijvoorbeeld interne POS-systemen.
AI-powered OCR met ML/NLP
AI-powered OCR combineert Optical Character Recognition met Machine Learning (ML) en Natural Language Processing (NLP) om data te herkennen, te classificeren en te interpreteren over verschillende formaten, talen en valuta’s heen.
Voordelen:
- Zeer flexibel bij verschillende lay-outs, lettertypen en talen
- Kan beelden van lage kwaliteit verwerken met pre-processing (cropping, de-skewing, contrastaanpassing)
- Automatiseert classificatie van velden zonder vooraf gedefinieerde templates
Nadelen:
- Vereist trainingsdata voor de beste nauwkeurigheid
- Kan hogere initiële kosten hebben dan basis-OCR tools
Tip: Kies AI-enabled OCR-tools wanneer je bonnetjes verwerkt uit meerdere bronnen met inconsistente ontwerpen, vooral in internationale omgevingen.
3. Human-in-the-Loop (HITL) validatie
Human-in-the-Loop combineert geautomatiseerde extractie met handmatige controle om de nauwkeurigheid te verifiëren, verkeerde classificaties te corrigeren en complexe uitzonderingen af te handelen.
Voordelen:
- Berekent bijna perfecte nauwkeurigheid
- Detecteert fraude of subtiele fouten die automatisering kan missen
- Biedt flexibiliteit voor onregelmatige of ongebruikelijke bonnetjes
Nadelen:
- Verhoogt de verwerkingstijd vergeleken met volledig geautomatiseerde extractie
- Vereist getraind personeel voor review
Tip: Gebruik HITL voor kritieke workflows waar fouten kunnen leiden tot problemen met compliance of financiële gevolgen, zoals belastingaudits of goedkeuring van terugbetalingen.
Inconsistente formaten, slechte beeldkwaliteit en verschillende belastingregels maken data extractie uit bonnetjes uitdagend voor de meeste bedrijven. Voor langetermijnefficiëntie kiezen veel organisaties voor een hybride aanpak: AI-powered OCR als primaire methode, ondersteund door Human-in-the-Loop validatie voor processen waar nauwkeurigheid cruciaal is.
Welke data moet je uit bonnetjes extraheren?
Bonnetjes bevatten essentiële financiële en transactionele informatie die bedrijven nodig hebben voor onkostentracking, fiscale compliance en geautomatiseerde boekhouding. Hieronder staan de belangrijkste datapunten die uit bonnetjes worden gehaald:
1. Transactiedetails
Details die bevestigen wanneer en waar een aankoop heeft plaatsgevonden.
- Datum & tijd – De exacte datum en tijd van de transactie.
- Transactie ID – Een uniek referentienummer voor tracking.
- Bedrijfsnaam – De naam van de winkel of onderneming die de bon heeft uitgegeven.
- Bedrijfslocatie – Het adres van de winkel of vestiging.
2. Aankoopinformatie
Regelitems op de bon die de aankoop beschrijven.
- Item omschrijving – Een uitsplitsing van gekochte producten of diensten.
- Hoeveelheid – Het aantal eenheden per item.
- Stukprijs – De prijs per eenheid vóór belasting.
- Totaal per item – De totale prijs per regelitem (aantal × eenheidsprijs).
3. Financiële uitsplitsing
Samenvatting van de kostenstructuur van de transactie.
- Subtotaal – Het totaal vóór belastingen, kortingen en toeslagen.
- BTW – Toegepaste btw, sales tax of andere heffingen.
- Kortingen/ promoties – Korting door acties, loyaltypunten of coupons.
- Totaal bedrag betaald – Het uiteindelijke bedrag na alle berekeningen.
- Valuta – De valuta waarin het bedrag is afgerekend.
4. Betalingsinformatie
Gegevens over hoe de transactie is betaald.
- Betaal methode – Contant, creditcard, mobiele wallet of andere betaalwijze.
- Kaartgegevens – Laatste vier cijfers van de gebruikte kaart, indien van toepassing.
- Wisselgeld – Bij contante betaling het wisselgeld dat is teruggegeven.
5. Merchant-specifieke data
Bevat branding-elementen en interne trackinggegevens.
- Bonnummer – Intern referentienummer dat door de merchant is toegewezen.
- Kassier-ID – Identificeert de medewerker die de verkoop heeft verwerkt.
- Bedrijfslogo – Gebruikt voor merkherkenning en klantbeleving.
- Bonberichten – Aangepaste teksten zoals retourbeleid, promoties of bedankbericht.
6. Digitale en machine-leesbare data
Aanvullende data die in digitale of geprinte bonnetjes is opgenomen.
- QR codes & barcodes – Links naar digitale bonnetjes of productinformatie.
- Item categoriën – Categorisering voor analytics (bijvoorbeeld boodschappen, elektronica).
- Loyaliteitsprogramma gegevens – Punten die zijn verdiend of gebruikt bij de transactie.
7. Aanvullende transactiespecifieke data
Verschilt per type aankoop.
- Ordernummer – Referentienummer voor ordertracking (bijv. in restaurants of e-commerce).
- Leveringsdetails – Verzend- of afhaalinformatie, indien van toepassing.
- Servicekosten & fooien – Extra kosten in sectoren zoals hospitality en horeca.
Belangrijkste uitdagingen bij data extractie uit bonnetjes
Data uit bonnetjes halen lijkt misschien eenvoudig, maar bedrijven lopen vaak tegen technische beperkingen aan die de nauwkeurigheid en efficiëntie beïnvloeden wanneer ze semi-geautomatiseerde of template-based oplossingen gebruiken. Dit zijn de belangrijkste uitdagingen:
- Inconsistente formats: Lay-outs, lettertypen en structuren verschillen sterk tussen merchants en locaties, waardoor flexibele AI-parsing nodig is.
- Gemengde bestandstypen: Bonnetjes kunnen geprint, als PDF, per e-mail of als foto worden aangeleverd, en elk type vraagt om een andere extractiemethode.
- Handgeschreven & moeilijk leesbare tekst: Kleine leveranciers gebruiken soms nog handgeschreven bonnetjes, die moeilijker te interpreteren zijn voor OCR.
- Vervaging of beschadiging: Thermisch papier vervaagt in de tijd en slecht afgedrukte bonnetjes hebben beeldverbetering nodig vóór extractie.
- Variatie in btw en kortingen: Verschillen in hoe belastingen en kortingen worden weergegeven, bemoeilijken consistente vastlegging van financiële data.
- Verschillen in valuta en taal: Formaat- en taalverschillen tussen landen vragen om goede lokalisatie om misinterpretatie te voorkomen.
- Verstoringen bij mobiel vastleggen: Schaduwen, hoeken en schittering bij foto’s vragen om automatische correctie om de leesbaarheid te vergroten.
- Validatiefouten: Zelfs nauwkeurige OCR kan velden verkeerd classificeren zonder geautomatiseerde checks of Human-in-the-Loop review.
Het adresseren van deze uitdagingen vereist een combinatie van AI-driven OCR, intelligente dataclassificatie en validatie-algoritmen om hoge nauwkeurigheid te bereiken over verschillende soorten bonnetjes. Al deze componenten zijn terug te vinden in IDP-platforms zoals Doxis AI.dp.
Voordelen van geautomatiseerde data extractie uit bonnetjes
Het automatiseren van data extractie uit bonnetjes vervangt trage, foutgevoelige handmatige invoer door snelle, nauwkeurige workflows. De belangrijkste voordelen zijn:
- Tijdbesparing: Verwerk grote volumes bonnetjes in seconden in plaats van uren, zodat medewerkers meer tijd hebben voor werk met hogere waarde.
- Hogere nauwkeurigheid: AI-powered OCR vermindert menselijke fouten en zorgt voor betrouwbare financiële gegevens en schonere audit-trails.
- Schaalbaarheid: Verwerk zonder moeite duizenden bonnetjes per maand zonder extra personeel of overbelasting van resources.
- Verbeterde compliance: Leg automatisch volledige belasting- en betalingsgegevens vast voor rapportage in meerdere jurisdicties.
- Kostenreductie: Verlaag operationele kosten door handmatige data-entry en validatieteams te verminderen.
- Integratieklaar: Gestructureerde data-outputs (JSON, CSV, XML, XLSX) sluiten naadloos aan op ERP-, boekhoud- en analytics-platforms.
- Fraudepreventie: Ingebouwde verificatie en duplicate detection beschermen tegen valse claims en vervalste bonnetjes.
Geautomatiseerde extractie verbetert snelheid, nauwkeurigheid en beveiliging, terwijl de kosten dalen — of je nu een kleinschalige OCR-app gebruikt of een volledig Intelligent Document Processing (IDP) platform zoals Doxis AI.dp.
Hoe je automatisch data uit bonnetjes extraheert met Doxis
AI-powered oplossingen zoals Doxis AI.dp kunnen het volledige proces van data extractie uit bonnetjes automatiseren — van aanlevering tot het boeken van gestructureerde informatie in je voorkeursysteem.
Laten we een stapsgewijs proces doorlopen om data uit een bon te extraheren met Doxis AI.dp. In ons voorbeeld verwerken we PDF-bonnetjes vanuit Google Drive als inputbron en kiezen we JSON als outputformaat.
En het beste nieuws? Je kunt het zelf gratis proberen!
Stap 1: Meld je aan op het platform
Het eerste wat je moet doen, is je gratis aanmelden op het AI.dp Platform. Vul je e-mailadres en wachtwoord in en geef vervolgens gegevens op zoals je volledige naam, bedrijfsnaam, use case en documentvolume. Zodra je dat hebt gedaan, ontvang je een gratis tegoed van €25 om alle functies en mogelijkheden van het platform te verkennen.
Na het inloggen maak je een organisatie aan en stel je een project in om toegang te krijgen tot de services. Voor ons doel – data uit bonnetjes extraheren – hoef je alleen het Financial Model en de Flow Builder in te schakelen om te beginnen. Deze setup zorgt ervoor dat je direct alles hebt wat je nodig hebt.
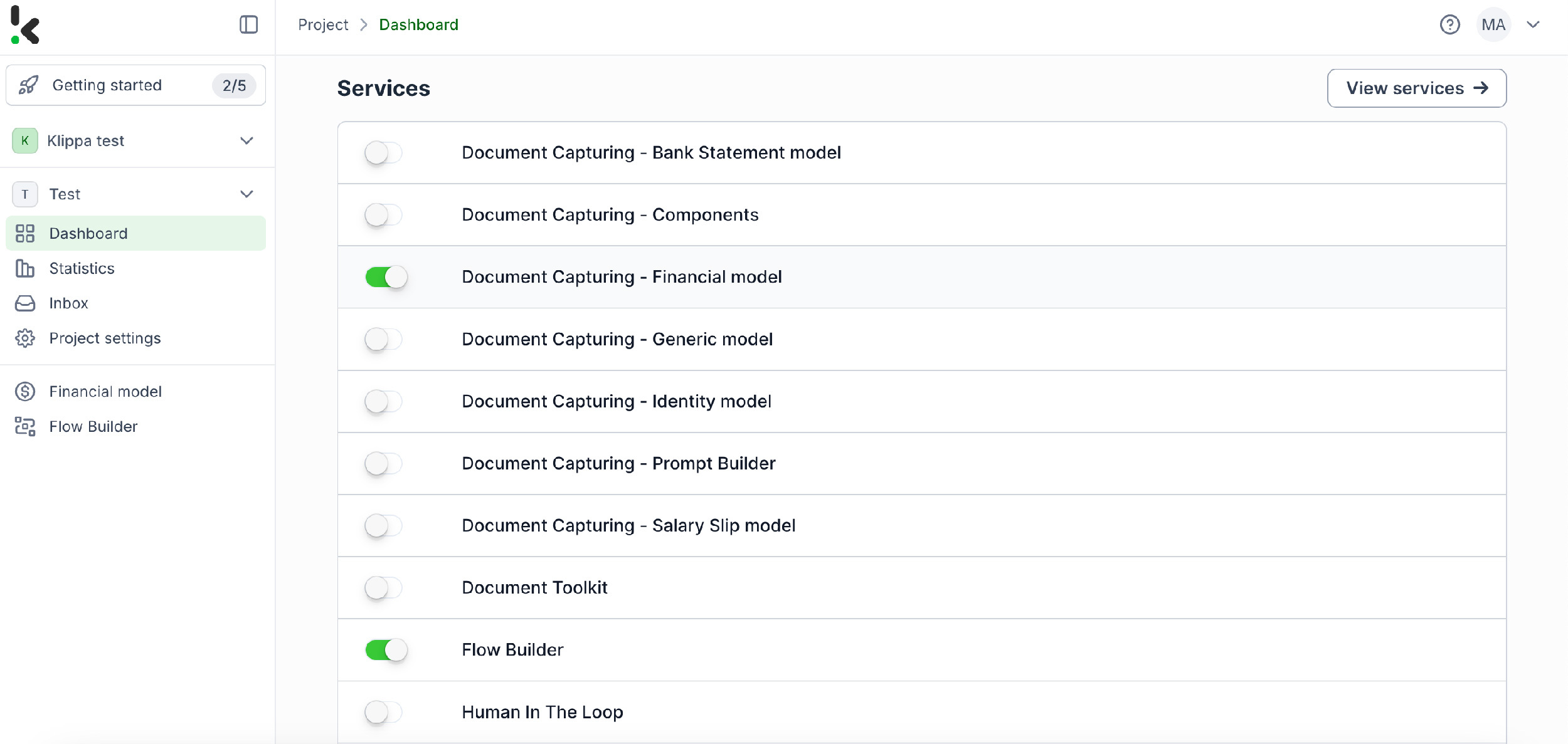
Stap 2: Maak een preset aan
Je vraagt je misschien af waarom we ervoor gekozen hebben om het Financial Model te activeren in plaats van andere opties. Het Financial Model is ontworpen om je financiële workflows te stroomlijnen door de extractie, analyse, validatie en classificatie van data te automatiseren. Het verwerkt efficiënt een breed scala aan financiële documenten, waaronder bonnetjes, facturen, inkooporders, bankafschriften en meer.
Zodra het model is geactiveerd, kun je een nieuwe preset aanmaken. Laten we deze “Extract Data from Receipts” noemen. Met deze preset kun je de componenten activeren die je nodig hebt voor jouw specifieke use case. In dit geval schakel je de componenten financial en line items in om specifieke velden in je bonnetjes te verwerken, zoals bonnummer, leverancier, datum, bedrag, valuta en btw-informatie.
Tip: Je kunt de preset verder aanpassen op basis van je use case door extra componenten in te schakelen, zoals Date Details, Reference Details, Amount Details, Document Language, Payment Details, enzovoort.
Je bent bijna klaar! Klik op “Save” om je instellingen definitief op te slaan en je bent klaar voor de volgende stap in de Flow Builder.
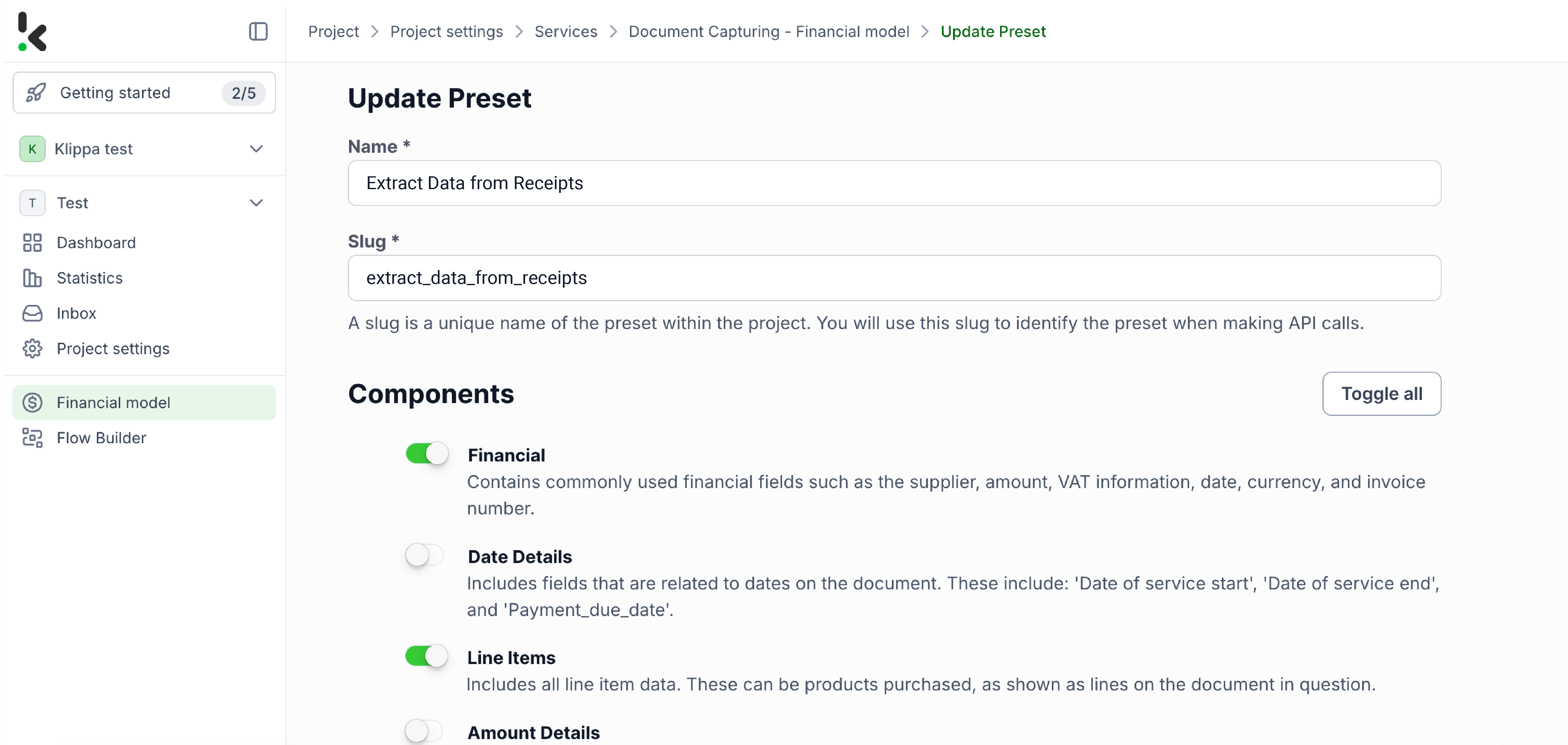
Stap 3: Kies je inputbron
Na het aanmaken van je preset en het inschakelen van de Flow Builder is het tijd om je flow te bouwen. Een flow is in essentie een reeks stappen die bepalen hoe je bonnetjes worden verwerkt en naar je outputbestemming worden gestuurd. In deze stap kiezen we Google Drive als inputbron.
Klik op New Flow → + From scratch en geef je flow een naam. We noemen de flow “Receipt Data Extraction”.
Tip: De eerste stap bij het bouwen van je flow is het selecteren van de inputbron. Je hebt meerdere opties: je kunt bestanden direct uploaden vanaf je apparaat of verbinding maken met meer dan 100 externe bronnen, waaronder Dropbox, Outlook, Salesforce, Zapier, OneDrive, de database van je bedrijf of cloudopslag zoals Amazon S3 en iCloud. Zorg ervoor dat alle bonnetjes in dezelfde map staan zodat ze indien nodig in bulk kunnen worden verwerkt.
In dit voorbeeld werken we met PDF-bonnetjes. We maken een map met de naam “Input” in Google Drive en uploaden daar je bon.
Kies vervolgens je inputbron door “Google Drive” te selecteren en daarna “New File” als trigger. Dit is wat je flow start. Vul aan de rechterkant de volgende velden in:
- Connection: Je kunt je verbinding een willekeurige naam geven. In ons voorbeeld noemen we deze “google-drive”. Zodra de naam is ingesteld, vraagt het systeem je om te authenticeren met Google.
- Parent Folder: Input
- Include File Content: Vink dit vakje aan om ervoor te zorgen dat de inhoud van het bestand wordt verwerkt.
Test deze stap door op Load Sample Data te klikken: zorg ervoor dat er minstens één voorbeeldbon in je inputmap staat terwijl je de flow instelt.
Tip: Omdat het platform een breed scala aan documenttypes ondersteunt om aan alle zakelijke behoeften te voldoen, kun je onze uitgebreide documentatie raadplegen voor meer informatie.
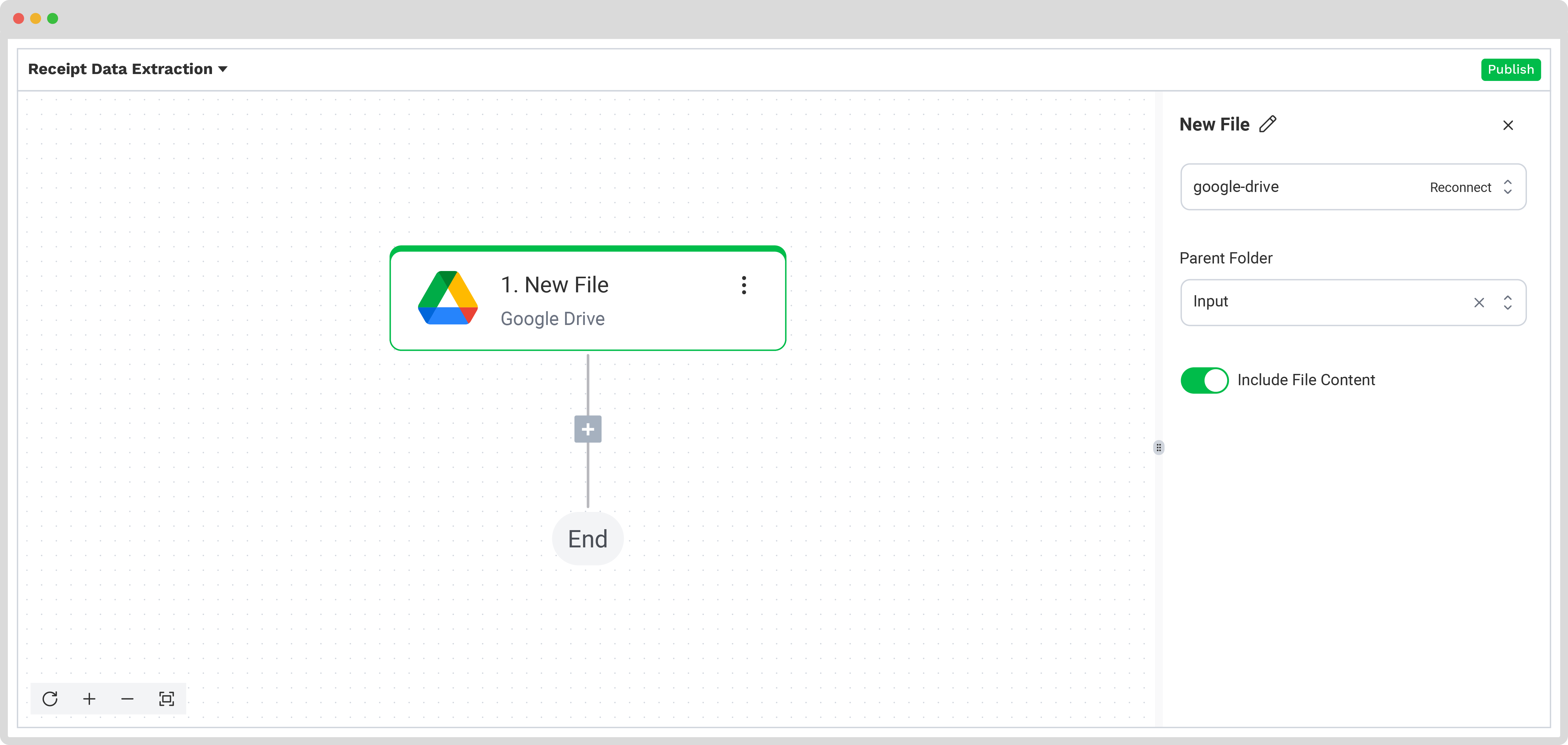
Stap 4: Capture en extractie van data
Nu is het tijd om de benodigde data te extraheren met behulp van de eerder aangemaakte preset, zodat alle geselecteerde datavelden uit de bonnetjes in de inputmap worden verwerkt.
In de Flow Builder klik je op de +-knop en kies je Document Capture: Financial Document.
Configureer vervolgens het volgende:
- Connection: Default AI.dp Platform
- Preset: De naam van je preset (in ons geval “extract_data_from_receipts”)
- File or URL: New file → Content
Test deze stap om te controleren of alles correct werkt. Zodra de test succesvol is, ben je klaar voor de volgende stap: je resultaten opslaan.
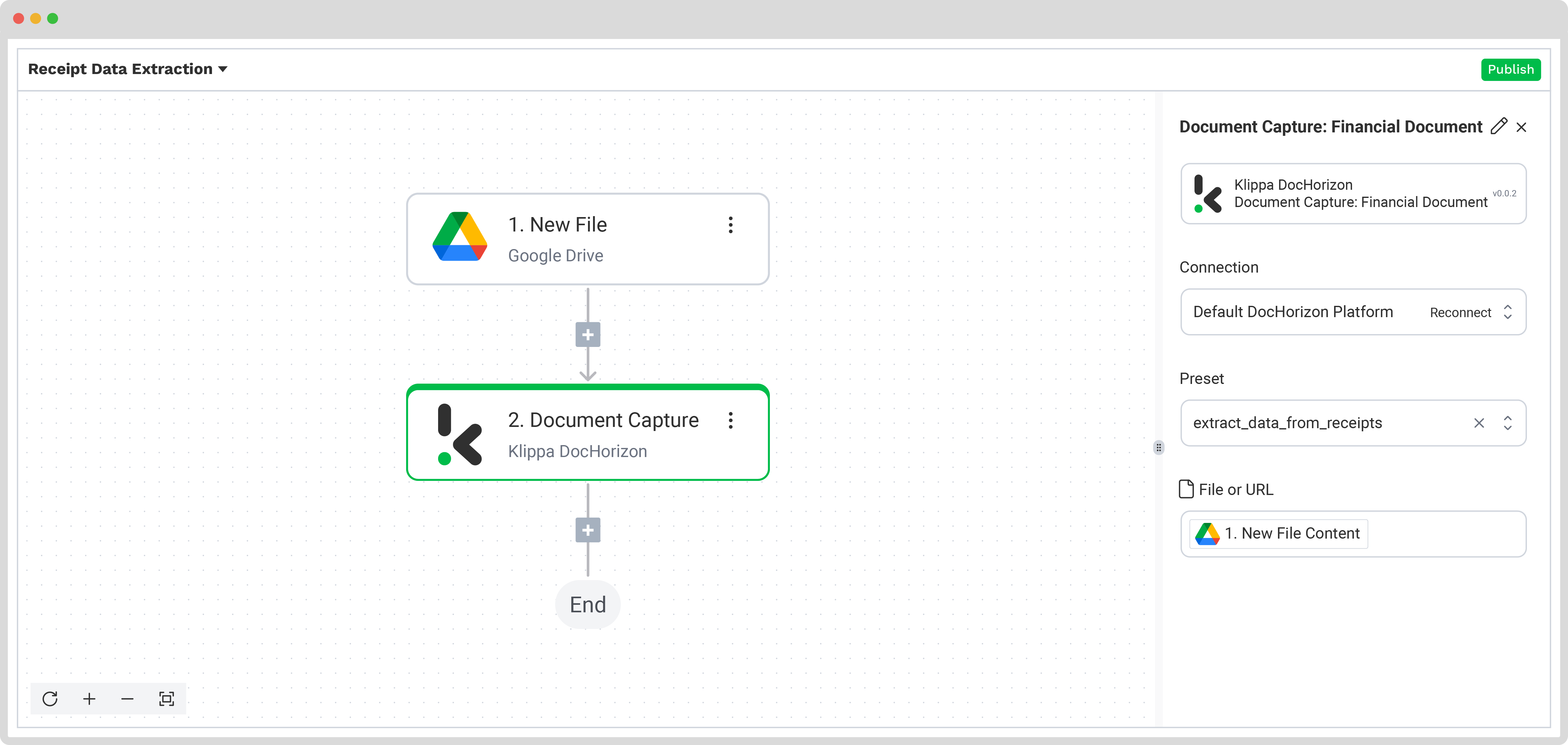
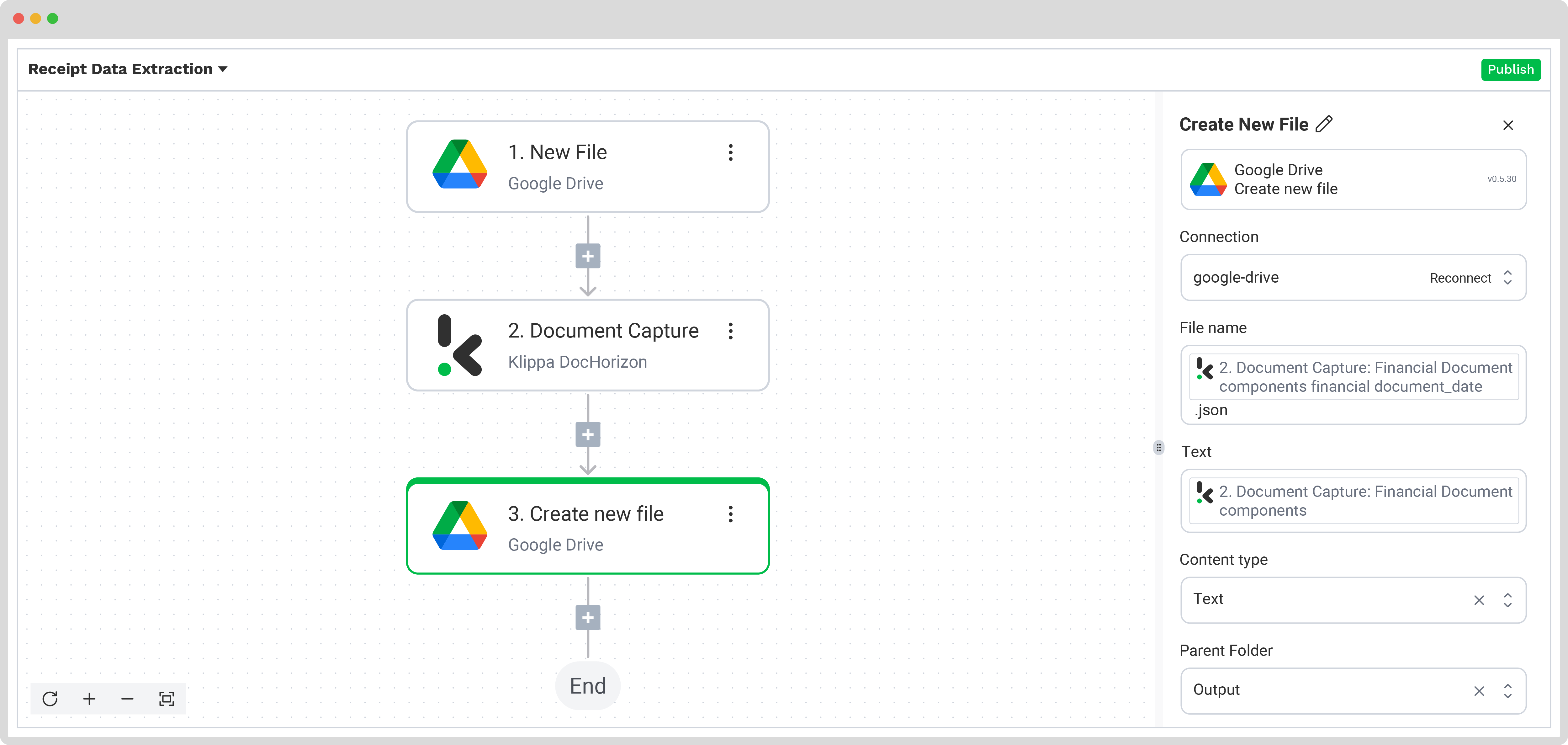
Stap 5: Sla het bestand op
Zodra de bon is verwerkt, is de laatste stap het kiezen van de bestemming en het dataformaat voor de uiteindelijke output. De bestemming kan je database, ERP-systeem, boekhoudsoftware of een ander platform zijn, afhankelijk van je workflow. Het data-outputformaat kan worden gekozen uit JSON, XML, CSV, XLSX, UBL, PDF of TXT.
In dit voorbeeld gebruiken we het bonnummer als bestandsnaam voor het bestand met de geëxtraheerde data en slaan we het op in JSON-formaat. We maken een nieuwe map in Google Drive, noemen deze outputmap “Output” en stellen die in als eindbestemming voor ons bestand met de geëxtraheerde data.
Klik op de +-knop en selecteer Create new file → Google Drive.
Configureer vervolgens het volgende:
- Connection: google-drive
- File Name: Document Capture: Financial Document → components → financial → receipt_number. Typ daarna .json achter de naam.
- Text: Document Capture: Financial Document → components
Tip: Selecteer de tekst die je in het nieuwe document wilt opnemen. Door “components” te kiezen, selecteer je alle geëxtraheerde elementen.
- Content Type: Text
- Parent Folder: Output (de naam van je outputmap)
Test deze stap door op de knop rechtsonder te klikken en je bent klaar!
Gefeliciteerd! Alle bondata is nu beschikbaar in je Google Drive-map. Met deze setup kun je de flow publiceren, en alle nieuwe bonnetjes die aan de map worden toegevoegd, worden automatisch verwerkt. Zo bespaar je tijd en zorg je voor nauwkeurigheid in je workflows.
Naast bonnetjes verwerk je mogelijk ook facturen. In dat geval is het de moeite waard om ook onze gids voor data extractie uit facturen te bekijken.
En onthoud: je hoeft dit niet allemaal zelf te doen. Verwerk je grote documentvolumes of heb je een unieke use case? Neem gerust contact met ons op — we horen graag je verhaal!
Veelvoorkomende use cases voor geautomatiseerde data extractie uit bonnetjes
Geautomatiseerde data extractie uit bonnetjes verbetert snelheid, nauwkeurigheid en compliance in verschillende zakelijke workflows. Veelvoorkomende toepassingen zijn:
Onkostendeclaraties
Automatisch bondetails vastleggen en koppelen aan onkostendeclaraties van medewerkers, waardoor de tijd voor handmatige invoer afneemt en de nauwkeurigheid van terugbetalingen toeneemt.
Belastingaangifte & compliance
Btw-, GST- of sales tax-gegevens extraheren om nauwkeurige rapportage en audit-gereedheid te waarborgen. Geautomatiseerde categorisering vereenvoudigt eindejaarsaangiftes en vermindert compliancerisico’s.
Terugbetalingen aan medewerkers
Goedkeuringsflows stroomlijnen door bondetails te verifiëren, te controleren op beleidsregels en terugbetalingen sneller af te handelen.
Fraudedetectie
Dubbele, gewijzigde of vervalste bonnetjes identificeren met verificatiechecks en image hashing. Dit helpt om buitensporige claims en financiële verliezen te voorkomen.
Retail- & FMCG-analyse
Gespecificeerde bondata analyseren om productverkopen, klantvoorkeuren en categorieprestaties te volgen. Ondersteunt loyaliteitsprogramma’s en het meten van promotiecampagnes.
Verzekeringsclaims
Bewijs van aankoop verifiëren voor claimvalidatie, waardoor verwerkingstijden korter worden en frauduleuze uitbetalingen worden verminderd.
Subsidie- & fondsbeheer
Toegestane kosten documenteren voor non-profit- en subsidieprojecten, zodat transparantie en naleving van subsidierichtlijnen gewaarborgd blijven.
Automatiseer data extractie uit bonnetjes met Doxis AI.dp
Wil je data uit bonnetjes extraheren naar Google Sheets, Excel, JSON en meer? Dan ben je bij ons aan het juiste adres. Met Doxis AI.dp kun je al je workflows eenvoudig automatiseren:
- Data extractie met OCR: Automatiseer data extractie uit elk type bon.
- Loyaliteitsprogramma outsourcing: Automatiseer het verwerken en controleren van bonnetjes voor loyaliteitsprogramma’s.
- Human-in-the-loop: Zorg voor bijna 100% nauwkeurigheid met onze Human-in-the-Loop-optie, waarbij interne verificatie of ondersteuning door het data-annotatieteam van Doxis mogelijk is.
- Documentconversie: Converteer documenten in elk formaat – PDF, gescande afbeeldingen of Word-documenten – naar diverse business-ready dataformaten, waaronder JSON, XLSX, CSV, TXT, XML en meer.
- Data-anonimisering: Bescherm gevoelige informatie en voldoe aan regelgeving door privacygevoelige data, zoals persoonlijke gegevens of contactgegevens, te anonimiseren.
- Documentverificatie: Valideer documenten automatisch en identificeer frauduleuze activiteiten om het frauderisico te verkleinen.
Bij Doxis hechten we veel waarde aan privacy; daarom zijn al onze documentworkflows compliant met HIPAA, GDPR en ISO-standaarden, zodat gegevens altijd veilig worden verwerkt. Met die gemoedsrust kun je de volgende stap zetten en je data extractieworkflows optimaliseren.
Ben je geïnteresseerd in het automatiseren van je workflow voor data extractie uit bonnetjes met de intelligente documentverwerkingsoplossing van Doxis? Neem dan contact op met onze experts voor meer informatie of boek een gratis demo!
FAQ
Gebruik een OCR-tool (Optical Character Recognition) die bonafbeeldingen of PDF’s kan scannen en lezen, en deze vervolgens kan omzetten naar gestructureerde data zoals JSON, CSV of XML. AI-gestuurde oplossingen verhogen de nauwkeurigheid doordat ze verschillende layouts, talen en valuta’s aankunnen.
2. Wat is OCR voor bonnetjes?
OCR voor bonnetjes is een technologie die tekst uit gescande of gefotografeerde bonnetjes leest en omzet in machine-leesbare velden zoals naam van de verkoper, datum, totalen en belastingen. Het vervangt handmatige gegevensinvoer in expense management- en boekhoudprocessen.
3. Hoe nauwkeurig is AI-gestuurde OCR voor bonnetjes?
De nauwkeurigheid hangt af van de beeldkwaliteit, de layout van het bonnetje en het gebruikte OCR-model. Geavanceerde oplossingen die OCR, machine learning en natural language processing combineren, behalen routinematig meer dan 90% nauwkeurigheid en kunnen met Human-in-the-Loop-validatie bijna perfecte resultaten bereiken.
4. Kan bonnetjesextractie meerdere talen en valuta’s verwerken?
Ja. Moderne OCR- en AI-modellen kunnen meertalige en multi-valuta bonnetjes binnen dezelfde workflow verwerken en passen zich automatisch aan verschillende formats, belastingtermen en numerieke notaties aan.
5. Wat zijn veelvoorkomende toepassingen van geautomatiseerde bonnetjesextractie?
Expense reporting, belastingaangifte, terugbetalingen, fraudedetectie, retailanalytics, verzekeringsclaims en kostenregistratie voor subsidies/fondsen. Deze workflows profiteren van snelle verwerking, hogere nauwkeurigheid en compliance-klare data-uitvoer.
6. Hoe kan ik de OCR-nauwkeurigheid voor bonnetjes verbeteren?
Maak heldere beelden met hoge resolutie. Vermijd schaduwen, vouwen en schittering. Gebruik een tool met beeldvoorbewerking (croppen, rechtzetten, contrastverbetering) en validatieregels om veldnauwkeurigheid te bevestigen.
7. Is geautomatiseerde bonnetjesextractie veilig?
Kies platforms die voldoen aan privacywetgeving zoals GDPR of HIPAA en gebruikmaken van encryptie, veilige cloudomgevingen en data-anonimisering voor gevoelige informatie.
8. Kan ik Doxis AI.dp uitproberen voordat ik een beslissing neem?
Ja. We bieden een gratis proefversie met €25 tegoed, zodat je workflows voor bonnetjesextractie kunt testen, integraties kunt verkennen en de nauwkeurigheid kunt meten vóór implementatie.
9. Waarin verschilt Doxis van basis-OCR-tools?
Doxis AI.dp combineert OCR met AI, geavanceerde classificatie, fraudedetectie, compliance-functies en flexibele integratieopties, waardoor het geschikt is voor grootschalige, multi-format en meertalige omgevingen die zowel snelheid als nauwkeurigheid nodig hebben.
10. Welke outputformaten ondersteunt Doxis?
JSON, CSV, XML, XLSX, PDF/A, TXT en meer. Klaar voor integratie met ERP-, boekhoud- of analytics-systemen.