
Verwerk je grote hoeveelheden documenten en PDF’s? Dan herken je het probleem: bestanden die ondersteboven, zijwaarts of in een verkeerde hoek binnenkomen. Verkeerd geroteerde PDF pagina’s, gescande bonnetjes en factuurafbeeldingen verstoren je workflow, vertragen je team en zorgen voor fouten in de data-extractie.
Volgens Gartner kost slechte datakwaliteit organisaties gemiddeld $12,9 miljoen per jaar. Verkeerd geroteerde documenten dragen direct bij aan dit probleem: OCR-software kan scheef of omgedraaid tekst niet correct lezen, waardoor je team handmatig moet ingrijpen.
In deze blog leggen we uit wat documentrotatie precies inhoudt, waarom het een terugkerend probleem is bij documentverwerking op grote schaal, en hoe je met OCR en AI het roteren van PDF’s, afbeeldingen en documenten volledig automatiseert.
Key Takeaways
- Verkeerd geroteerde documenten en PDF’s zijn een veelvoorkomend probleem bij grootschalige documentverwerking. Ze verlagen de datakwaliteit, vertragen workflows en vereisen handmatige correctie.
- Handmatig roteren is kostbaar: het corrigeren van 10% verkeerd geroteerde documenten uit een volume van 100.000 per maand kost al snel €20.000 per jaar aan arbeidskosten. Automatisering bespaart tot 90% van deze kosten.
- Klippa’s aanpak combineert OCR en AI om de tekstrichting te detecteren en documenten nauwkeurig te roteren, ongeacht formaat of afmeting.
- De software werkt in drie stappen: beeldoptimalisatie, tekstextractie met OCR, en slimme rotatie op basis van taalherkenning.
- Klippa DocHorizon biedt meer dan alleen rotatie: met functies als OCR, classificatie, anonimisatie en data-extractie is het een complete oplossing voor intelligente documentverwerking.
Wat is het roteren van documenten en waarom is het nodig?
Het roteren van documenten is het proces waarbij een digitaal document, een PDF pagina of een afbeelding wordt gedraaid naar de juiste leesrichting. Dit houdt in dat de tekst horizontaal van links naar rechts leesbaar wordt, zodat zowel mensen als software de inhoud correct kunnen interpreteren.
Correct documenten draaien is nodig omdat documenten op allerlei manieren binnenkomen. Een gescande factuur kan op zijn kop liggen. Een bonnetje dat met een telefoon is gefotografeerd staat zijwaarts. Een PDF die is gegenereerd vanuit een ander systeem heeft pagina’s in wisselende richtingen. Bij kleine volumes is dit een kleine ergernis, bij grote volumes wordt het een serieus operationeel probleem.
De gevolgen zijn direct merkbaar in je workflow. OCR-software kan tekst op een verkeerd geroteerd document niet goed herkennen, waardoor extractieresultaten onbetrouwbaar worden. Medewerkers moeten documenten handmatig controleren en corrigeren voordat verdere verwerking mogelijk is. Dit kost tijd, verhoogt de kans op fouten en drijft de operationele kosten omhoog.
Vooral bij PDF-bestanden is correcte rotatie belangrijk. PDF’s zijn het meest gebruikte bestandsformaat voor zakelijke documenten, van facturen en contracten tot identiteitsbewijzen en formulieren. Een enkel PDF-bestand kan pagina’s bevatten met verschillende oriëntaties, wat geautomatiseerde verwerking extra complex maakt. Zonder correcte rotatie is het onmogelijk om betrouwbaar data te extraheren, documenten te classificeren of bestanden doorzoekbaar te maken.
Een praktijkvoorbeeld: de kosten van verkeerd geroteerde PDF’s
Stel dat je werkt voor een organisatie die financiële documenten op grote schaal verwerkt, bijvoorbeeld bonnetjes en facturen voor een loyaliteitsprogramma. Dit is een veelvoorkomende situatie bij onder andere cashback-automatisering.
Je hebt een data-entry team dat documenten controleert in een interface en bepaalde gegevens extraheert of goedkeuringen verleent. Het handmatig controleren van documenten is al tijdrovend voor correcte bestanden, laat staan voor documenten met kwaliteitsproblemen.
Bij een volume van 100.000 documenten per maand en 10% verkeerd geroteerde bestanden, betekent dat 10.000 documenten die maandelijks handmatig gecorrigeerd moeten worden. De jaarlijkse kosten voor het roteren van 120.000 documenten lopen snel op tot €20.000 aan arbeid. Automatisering brengt deze kosten met 90% omlaag: een besparing van €18.000 per jaar.

Er is dus een duidelijke business case voor het automatiseren van het draaien van documenten. Maar hoe pak je dat aan? Laten we stap voor stap bekijken hoe je de oriëntatie van PDF’s, bonnetjes en facturen automatisch detecteert en corrigeert.
Hoe roteer je PDF pagina’s en documenten automatisch?
Er zijn verschillende soorten problemen met binnenkomende documenten: scheef gescande pagina’s, omgedraaide PDF’s, zijwaarts gefotografeerde bonnetjes. In deze sectie richten we ons op het automatisch roteren van PDF’s, facturen en bonnetjes, maar dezelfde aanpak werkt voor elk documenttype.
Ben je geïnteresseerd in andere documentverwerking oplossingen, zoals automatische documentclassificatie of onze beeld naar tekst converter? Lees dan onze artikelen over deze onderwerpen.
Een eenvoudige aanpak die veel mensen als eerste bedenken, is het controleren van de hoogte en breedte van een document en het roteren naar een verticale oriëntatie. Hoewel dit simpel klinkt, is het in de praktijk foutgevoelig. Bonnetjes, facturen en PDF’s komen in allerlei vormen en maten: soms rechthoekig, soms vierkant.
Deze aanpak kan ertoe leiden dat documenten die al correct staan juist verkeerd worden gedraaid, of dat pagina’s 180 graden worden omgekeerd en ondersteboven komen te staan.
Er is een betere oplossing: rotatie baseren op de tekstinhoud van het document. Om daar te komen, neemt de software drie belangrijke stappen.
Stap 1: Beeldkwaliteit optimaliseren
De eerste stap is het verbeteren van de beeldkwaliteit. De software snijdt de documentfoto bij, corrigeert het perspectief en verbetert het contrast. Dit levert direct beter leesbare afbeeldingen op, wat essentieel is voor de tweede stap. Bij PDF-bestanden wordt elke pagina afzonderlijk geoptimaliseerd, zodat ook meerpagina-PDF’s correct verwerkt worden.

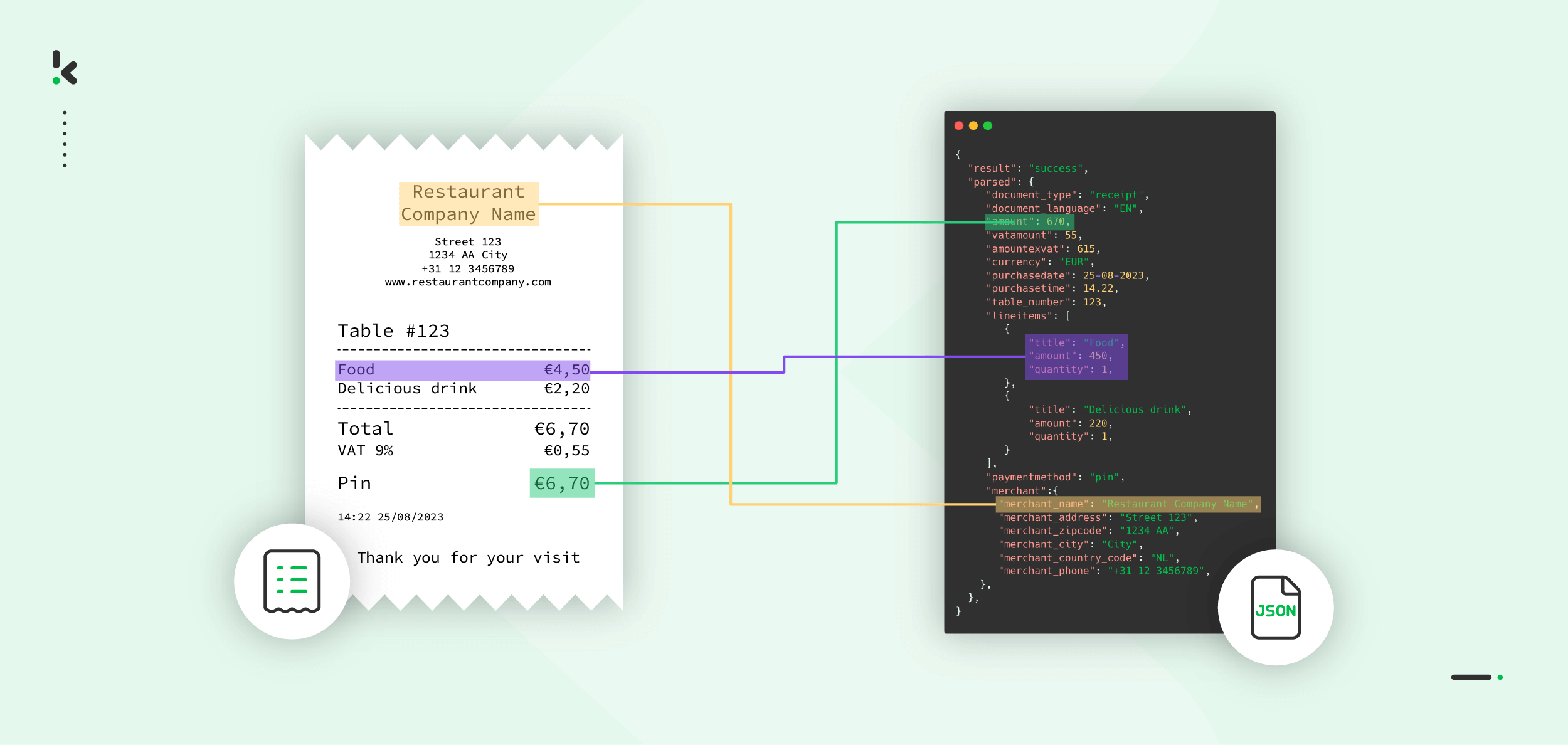
Stap 2: Documenten en PDF’s omzetten naar tekst met OCR
De tweede stap is het omzetten van documenten en afbeeldingen naar tekst met behulp van OCR (Optical Character Recognition). Als het document een PDF is, wordt het eerst omgezet naar een afbeelding en vervolgens naar tekst. Dit proces maakt het document doorzoekbaar en onthult de tekstrichting.
Niemand leest een zin van boven naar beneden. Tekst wordt gelezen van links naar rechts, en in sommige talen van rechts naar links. Op bepaalde documenten komt tekst in meerdere richtingen voor. In die gevallen voert de software een teksttelling uit en kiest de rotatie die overeenkomt met de richting waarin de meeste tekst staat.
Stap 3: Het document roteren
Nu de tekstrichting bekend is, kan het document worden geroteerd. De doelrichting verschilt per taal: voor de meeste talen is dat van links naar rechts, maar voor talen als Arabisch en Hebreeuws is dat van rechts naar links.
De software gebruikt een machine learning classifier om het land van herkomst en de taal van het document te bepalen. Zodra dit vaststaat, wordt de afbeelding of het PDF-bestand geroteerd en opgeslagen in het gewenste formaat. In veel gevallen is dat het originele bestandsformaat (JPEG voor afbeeldingen, PDF voor PDF-bestanden), maar conversie naar een ander formaat is ook mogelijk.

Bonusstappen: gestructureerde data-extractie
Na de rotatie kan de software nog verder gaan. De OCR-resultaten zijn beschikbaar als platte tekst in TXT-formaat, maar ook als gestructureerde data in JSON. Denk aan het automatisch extraheren van leveranciersnaam, datum, bedrag en btw-informatie uit een factuur of bonnetje, en het exporteren van deze gegevens naar je boekhoudsysteem of ERP-pakket.
Waarom handmatig PDF’s roteren niet werkt op grote schaal
Gratis online tools voor het roteren van PDF’s zijn er genoeg. Diensten als Adobe Acrobat, Smallpdf en vergelijkbare websites bieden de mogelijkheid om individuele PDF pagina’s te draaien. Voor een enkel bestand werkt dat prima.
Maar zodra je te maken hebt met honderden of duizenden documenten per dag, schieten deze tools tekort. Handmatig roteren vereist dat iemand elk bestand opent, de verkeerde pagina’s identificeert, de juiste rotatie toepast en het bestand opslaat. Bij grote volumes is dit niet alleen tijdrovend, maar ook foutgevoelig en onschaalbaar.
Daarnaast missen gratis tools de mogelijkheid om de correcte oriëntatie automatisch te detecteren. Ze roteren een pagina als jij dat aangeeft, maar ze weten niet welke pagina’s verkeerd staan. De intelligentie ontbreekt. Voor organisaties die structureel grote volumes PDF’s en documenten verwerken, is een geautomatiseerde oplossing op basis van OCR en AI de enige schaalbare aanpak.
Automatisch PDF’s roteren met Klippa DocHorizon
Klippa DocHorizon is een AI-gestuurde OCR-oplossing, ook bekend als Intelligent Document Processing (IDP), die al je document gerelateerde workflows automatiseert. Het automatisch roteren van PDF’s, afbeeldingen en documenten is slechts het begin. Met DocHorizon kun je onder andere het volgende doen:
- Mobiel scannen: documenten scannen vanaf mobiele apparaten, altijd en overal
- OCR: gescande documenten en afbeeldingen omzetten naar tekst en gestructureerde dataformaten
- Data-extractie: relevante datapunten in real-time uit documenten halen
- Classificatie: documenten automatisch classificeren en sorteren op basis van je eigen regels
- Data parsing: JPG-, PNG- en PDF-bestanden omzetten naar doorzoekbare tekst en exporteren naar formaten als PDF/A, CSV, XLSX, XML en JSON
- Anonimisering: gevoelige gegevens maskeren, van anonimisering tot volledige verwijdering
- Verificatie: de authenticiteit en geldigheid van documenten en data verifieren
Klinkt dit als een oplossing die bij je past? Plan een demo of neem contact op met onze specialisten voor meer informatie. We kijken graag hoe we je kunnen helpen je doelen te bereiken.
Veelgestelde vragen
Correcte oriëntatie zorgt ervoor dat OCR-software tekst nauwkeurig kan detecteren en lezen. Verkeerd geroteerde documenten leiden tot onjuiste tekenherkenning, verkeerd geïdentificeerde velden of volledig onleesbare resultaten. Zonder correcte rotatie is betrouwbare geautomatiseerde data-extractie niet mogelijk.
2. Hoe helpt OCR bij het detecteren van de juiste oriëntatie van een document?
OCR extraheert tekst uit afbeeldingen en PDF’s. Door de richting en uitlijning van de gedetecteerde tekstregels te analyseren, kan de software de meest waarschijnlijke leesrichting bepalen (bijvoorbeeld links-naar-rechts of boven-naar-beneden) en het document dienovereenkomstig roteren.
3. Hoe corrigeert Klippa automatisch de oriëntatie van gescande documenten en PDF’s?
Klippa gebruikt Optical Character Recognition (OCR) gecombineerd met Artificial Intelligence (AI) om de tekstrichting binnen een document te detecteren. Door de richting van de tekst te analyseren, kan het systeem het document nauwkeurig naar de correcte oriëntatie roteren, zodat leesbaarheid en correcte verwerking gegarandeerd zijn.
4. Kan Klippa documenten met verschillende layouts en formaten verwerken?
Ja. De AI-gestuurde OCR-technologie van Klippa is ontworpen om een breed scala aan documenttypen, layouts en formaten te verwerken. De software past zich aan verschillende structuren aan zonder dat handmatige templates nodig zijn, waardoor het geschikt is voor uiteenlopende documentverwerkingsbehoeften.
5. Werkt automatische documentrotatie ook voor PDF’s met meerdere pagina’s?
Ja. Klippa DocHorizon analyseert elke pagina van een PDF-bestand afzonderlijk. Als een meerpagina-PDF pagina’s bevat met verschillende oriëntatie, wordt elke pagina individueel gedetecteerd en gecorrigeerd. Zo is het volledige document na verwerking correct leesbaar.
6. Welke bestandsformaten ondersteunt Klippa voor automatische rotatie?
Klippa ondersteunt alle gangbare bestandsformaten, waaronder PDF, JPEG, PNG, TIFF en meer. Na rotatie kun je het document opslaan in het originele formaat of converteren naar een ander formaat, zoals PDF/A voor langetermijnarchivering.
7. Hoeveel kan ik besparen door documentrotatie te automatiseren?
De besparing hangt af van je documentvolume en het percentage verkeerd geroteerde bestanden. Bij een volume van 100.000 documenten per maand waarvan 10% verkeerd geroteerd is, bedraagt de jaarlijkse besparing door automatisering ongeveer €18.000 aan arbeidskosten. Dat is een kostenreductie van 90%.
8. Kan ik Klippa integreren met mijn bestaande systemen?
Ja. Klippa DocHorizon is beschikbaar als API en SDK, waardoor je de software eenvoudig kunt integreren in je bestaande workflow, ERP-systeem of documentmanagementsysteem. De integratie is flexibel en geschikt voor zowel kleine als grote organisaties.