Klippa devient Doxis - En savoir plus
Logiciel OCR Reconnaissance Optique de Caractères
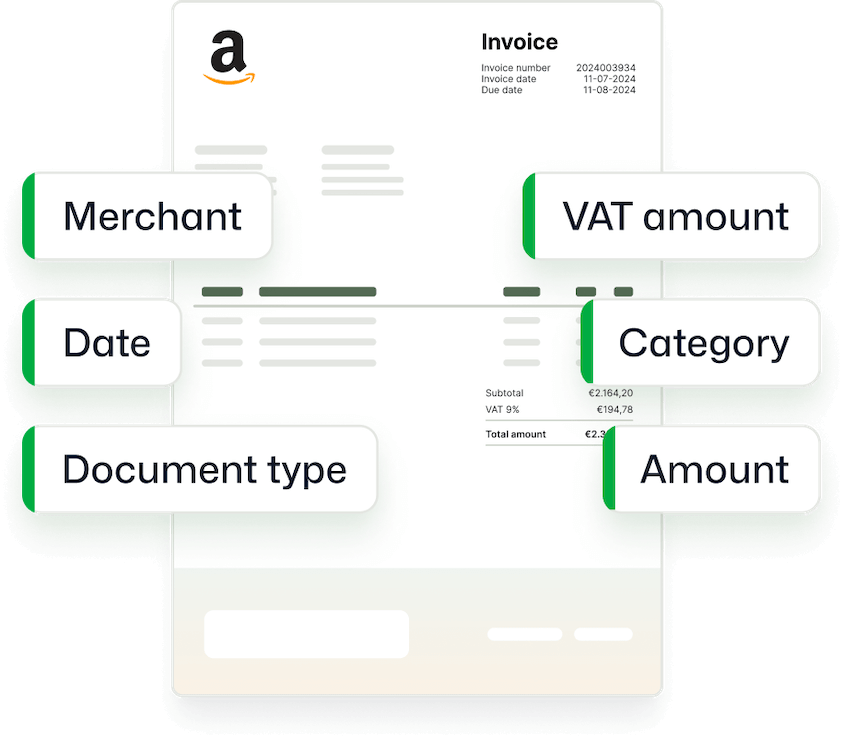
Doxis offre une solution propulsée par l’IA permettant d’extraire toutes les données de vos documents en un rien de temps.
Plus de 1000 marques dans le monde nous font confiance
Nous vous garantissons des données fiables extraites de vos documents
La saisie manuelle des données est lente et sujette aux erreurs, tandis que les solutions OCR traditionnelles peinent face aux mises en page complexes et aux documents multilingues. Avec le logiciel d’océrisation de Doxis, ces problèmes disparaissent.
Sans Doxis
Avec Doxis
LA SOLUTION
Automatisez vos processus documentaires avec l’OCR alimenté par l’IA
L’OCR de Doxis utilise l’IA pour simplifier le traitement des documents. Il permet d’extraire, classfier, convertir les données et de les intégrer directement dans vos systèmes métiers avec une conformité complète.
Automatisation de la saisie
Éliminez la saisie manuelle en extrayant automatiquement les champs clés (noms, dates, montants, références) et en les envoyant vers votre ERP ou base de données.- Classez vos documents dès leur réception par catégorie (factures, documents d’identité, bons de livraison…), facilitant l’organisation et la recherche ultérieure.
- Extraire et normaliser les informations des pièces d’identité (nom, date de naissance, numéro de document, MRZ) pour accélérer l’ouverture de compte et la conformité.
Gestion des reçus et notes de frais
Capturez rapidement les reçus depuis un mobile, extrayez montant, TVA, commerçant et catégorie, et alimentez vos workflows de remboursement.- Accélérez l’enregistrement et le rapprochement des factures fournisseurs pour réduire les délais de paiement et améliorer la gestion de trésorerie.
Conformité fiscale
Repérez les anomalies et les fraudes grâce à l’analyse métadonnées, duplication d’images et niveaux de gris, mais aussi la détection de factures générées par l’IA.
Découvrez nos témoignages clients
Notre OCR prend en charge plus de 100 documents
Traitez différents types de documents, y compris fiches de paie, bons de commande, cartes d’identité, et bien plus encore. Notre technologie OCR avancé extrait des données précises pour vous en 0.5 à 4 secondes.
Comment ça fonctionne ?
Comment notre solution OCR pour documents fonctionne en 4 étapes simples
Soumettez vos fichiers à l’OCR via le logiciel application mobile, web ou par mail
Téléchargez tout fichier ou donnée 24h/24 et 7j/7 depuis les pièces jointes d’email ou des documents scannés, et notre OCR se charge du reste.
Les formats pris en charge incluent :
.jpg, .jpeg, .png, .pdf, .doc, .docx, .xlsx, .heic, .webp, et plus encore.Extrayez les informations clés avec la reconnaissance optique de caractère
Notre OCR avancé alimenté par l’IA analyse et extrait les données des documents sans avoir besoin de modèles.
Validation des données
Notre logiciel OCR valide les données et signale toute information manquante ou potentiellement frauduleuse, pour améliorer la précision et l’authenticité des données.
Exportez vers divers formats
Transférez les données structurées directement vers votre CRM, ERP ou base de données – ou exportez les données au format
.json, .csv, .xml, .xls, .ubl, et plus encore.FONCTIONNALITÉS PRINCIPALES
L’OCR de Doxis alimenté par l’IA pour traiter vos documents
L’OCR de Doxis simplifie la numérisation et le traitement des documents avec des fonctionnalités avancées, offrant des données précises et structurées rapidement.
Atteignez 99 % de précision
Découvrez une précision inégalée dans l’extraction de texte avec l’OCR, garantissant que chaque champ est correctement capturé.OCR alimenté par l’IA
Nous exploitons la puissance de l’IA pour améliorer les capacités OCR, rendant le traitement des documents plus intelligent et plus rapide.Large prise en charge des documents
Notre OCR pour documents prend en charge 150 langues et de nombreux types de documents, offrant polyvalence et flexibilité.- Intégration fluide
Prétraitement des images
Notre OCR améliore automatiquement la qualité des images pour une extraction et une analyse des données précises.Plus de 20 formats pris en charge
Nous prenons en charge JSON, CSV, PDF, XML, XLS, XLSX, UBL, PNG, TIFF, DOC, DOCX, JPG, et bien plus encore.Traitement de documents multi-pages
Téléchargez des documents multi-pages pour garantir un flux de travail de traitement documentaire évolutif, efficace et précis.Protection des données garantie
Par défaut, aucune donnée traitée n’est stockée sur nos serveurs, garantissant ainsi une conformité optimale aux réglementations.
Comment Alasco a automatisé le traitement des factures dans son logiciel immobilier
” Pour nous, il est exceptionnel que l’intégration de l’OCR soit fluide, ainsi nos clients ne se rendent pas compte qu’ils utilisent en réalité un autre outil. “
Grâce à Doxis, Alesco a pu convertir toutes ses factures en données exploitable, ce qui a permis un traitement des factures beaucoup plus rapide.
Allez au-delà de l’OCR avec des fonctionnalités avancées
Améliorez vos flux de travail grâce à des fonctionnalités supplémentaires, flexibles et performantes, pour un traitement documentaire fluide et évolutif.
Implémentez l’OCR pour vos documents en un rien de temps
Intégrez la technologie OCR dans votre application via API, SDK ou plateforme de traitement documentaire intelligent grâce à notre documentation dédiée aux développeurs.
L’intégration est fluide : une fois que vous obtenez votre clé API en vous inscrivantvous pouvez rapidement implémenter notre OCR documentaire dans votre application ou votre stack technologique. Avec notre API OCR, vous recevrez des données structurées au format JSON en sortie standard.
Pour implémenter la fonctionnalité de numérisation documentaire en temps réel pour la capture de données, vous devrez intégrer notre SDK OCR. Notre SDK offre diverses fonctionnalités et est disponible pour iOS et Android. Pour commencer, contactez l’un de nos experts.
Une autre alternative est d’utiliser notre plateforme de traitement documentaire intelligent (Klippa DocHorizon), qui va au-delà de l’OCR. Avec Doxis AI.dp, vous pouvez créer un flux de travail complet de traitement documentaire, de l’ingestion des données à l’exportation, sans code ! Vous pouvez commencer immédiatement en vous inscrivant.
- ✓ Sécurisé

- ✓ Conforme
- ✓ Protégé
- ✓ Hébergé dans l’UE
- ✓ Fiable
FAQ
Qu’est-ce que l’OCR documentaire ?
Un logiciel OCR peut-il traiter les documents manuscrits ?
Quels types de documents sont pris en charge par un logiciel OCR ?
Quelles langues sont prises en charge ?
Puis-je utiliser l’OCR pour la numérisation de documents ?
Est-il possible de personnaliser l’OCR de Doxis ?
Quelle est la précision de l’OCR documentaire ?
Comment l’OCR peut-il être implémenté ?
À quoi ressemble la réponse de l’OCR ?
Puis-je tester votre OCR avant de m’engager ?
Quels sont les coûts d’utilisation de l’OCR ?
Est-ce que Doxis stocke les données traitées ?