
Ob Sie nun Datumsangaben und Beträge aus Rechnungen extrahieren wollen oder nach Produktpositionen auf Quittungen suchen, eine der ersten OCR-Lösungen, die Sie online finden werden, ist Tesseract. Tesseract ist eine der ersten ernsthaft entwickelten Open-Source-OCR-Engines.
Die Software geht auf das Jahr 1985 zurück, als die Entwicklung von Hewlett-Packard als kommerzielle Lösung begonnen wurde. Im Jahr 2005 wurde sie schließlich zu einem Open-Source-Projekt, und seither hat Google die Entwicklung über mehrere Jahre hinweg unterstützt.
In den letzten Jahren ist die Entwicklung zum Stillstand gekommen, da viele Softwareunternehmen alternative OCR-Lösungen entwickelt haben. Diese kommerziellen Lösungen sind nicht kostenlos, aber wenn Sie eine ausgereifte Lösung suchen, die kontinuierlich verbessert wird und maschinelles Lernen und künstliche Intelligenz (KI) einbezieht, dann haben wir die beste Alternative zu Tesseract für Sie.
Aber lassen Sie uns zunächst kurz darüber sprechen, was Tesseract ist, warum Sie es verwenden sollten und warum nicht, und dann die fünf besten Alternativen zu Tesseract OCR vorstellen.
Kurzübersicht
- Klippa DocHorizon: Die führende KI-basierte OCR-Lösung für Unternehmen: Hohe Erkennungsgenauigkeit, Betrugserkennung, strukturierte Datenausgabe und einfache Integration – ideal für automatisierte Dokumentenprozesse. 🏆
- GImageReader: Kostenlose Open-Source-OCR mit grafischer Benutzeroberfläche – geeignet für einfache Texterkennung ohne Setup-Aufwand.
- OCR4all: Open-Source-Tool mit GUI für historische Drucke – besonders geeignet für die Digitalisierung von Altbeständen mit komplexem Layout.
- OpenScan: Datenschutzorientierte OCR für kleine Unternehmen – kostenlos, lokal und ohne Cloud-Anbindung.
- Kofax OmniPage: Kommerzielle OCR mit hoher Genauigkeit, umfangreichen Funktionen und Unterstützung für viele Dateiformate – ideal für Unternehmen mit hohem Volumen
Was ist Tesseract?
Wie bereits erwähnt, ist Tesseract eine Open-Source-OCR-Software, die zur Extraktion von Text aus Bildern verwendet werden kann. “Sie kann von Haus aus mehr als 100 Sprachen erkennen und ist mit vielen Programmiersprachen und Frameworks kompatibel.
Einer der Vorteile von Tesseract ist, dass es mit Python OCR-Bibliotheken gekoppelt werden kann, was den Benutzern Zugang zu Vorteilen wie PDF-Datenextraktion, Echtzeit-Computer Vision (CV) und Bildverarbeitungsfunktionen verschafft.
Warum Sollten Sie Tesseract Nutzen?
Tesseract verfügt über eine Reihe von Funktionen, die die Software perfekt für eine bestimmte Zielgruppe geeignet machen. Wenn Sie kein Geld in eine OCR-Software investieren wollen oder können, dann könnte Tesseract eine gute Option sein. Die Nutzung ist kostenlos, da es sich um eine Open-Source-Software handelt.
Tesseract bietet eine hervorragende Dokumentation, die es Ihnen leicht macht, die Software in Ihr System zu implementieren. Wenn Sie noch Fragen haben, können Ihnen viele andere Benutzer bei der Einrichtung helfen, da die Software von einer Vielzahl von Büros verwendet wird. Die Software wird häufig als Lösung für die automatisierte Dateneingabe, das digitale Kunden-Onboarding und die automatisierte Rechnungsverarbeitung eingesetzt.
Nachteile bei der Verwendung von Tesseract
Tesseract ist zwar für einige Anwendungsfälle geeignet, hat aber auch erhebliche Einschränkungen. Damit die Software für Sie funktioniert, müssen Sie manuell selbst Code schreiben, was bedeutet, dass viel Zeit und Ressourcen investiert werden müssen. In den meisten Fällen dauert es viel länger, bis Sie die OCR-Lösung nutzen können, da es keine Unterstützung durch die Entwickler gibt.
Darüber hinaus wird nicht jeder Dokumententyp unterstützt, was im Vergleich zu fortschrittlicheren Lösungen schnell zu Fehlern und niedrigen Genauigkeitsraten führt. Darüber hinaus automatisiert Tesseract keine anderen Dokumentenprozesse wie Verifizierung und Gegenprüfung, da es an Weiterentwicklung und der Integration von KI mangelt.
Vielleicht haben Sie diese Einschränkungen bereits selbst erfahren und sind nun auf der Suche nach einer alternativen Lösung. Deshalb stellen wir Ihnen im nächsten Abschnitt fünf Tesseract-Alternativen vor, von denen drei ebenfalls Open Source sind und zwei als kostenpflichtiger Service angeboten werden.
Die 5 besten Tesseract-Alternativen 2025
Im Folgenden werden wir fünf Alternativen zu Tesseract diskutieren:
#1 Klippa DocHorizon
Klippa DocHorizon kombiniert OCR mit anspruchsvollen KI-Technologien. Wie auch eine Intelligent Document Processing (IDP) software, it is capable of scanning, classifying, anonymizing, extracting, and verifying data.
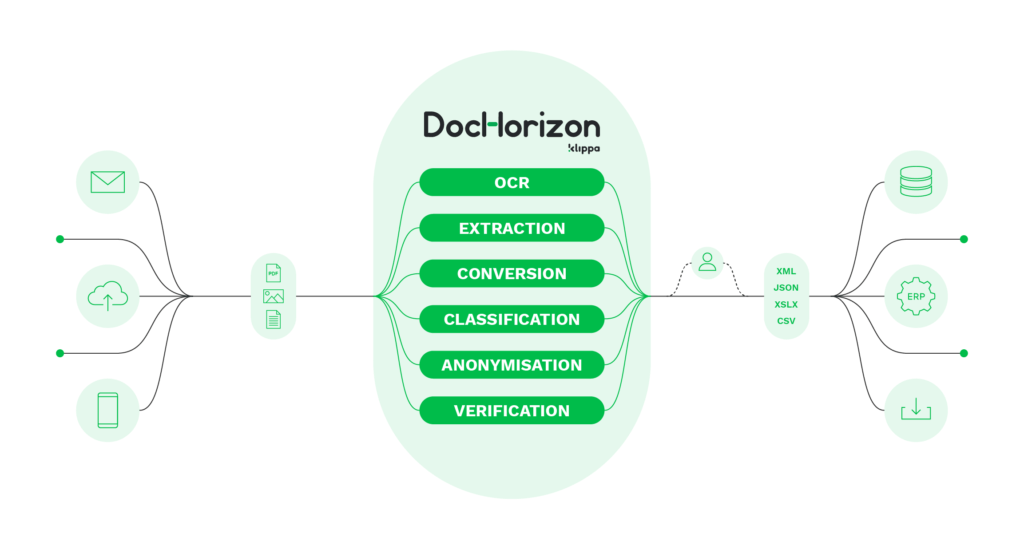
Die Softwarelösung ist in erster Linie Cloud-basiert, aber auch als On-Premise-Lösung erhältlich. Klippa DocHorizon ermöglicht es den Benutzern, Dokumente per E-Mail, Web oder über mobile Apps einzureichen, wodurch Unternehmen bis zu 95 % ihrer derzeitigen manuellen Dokumentenverarbeitungszeit einsparen können.
Im Allgemeinen hilft die IDP-Lösung Unternehmen in verschiedenen Branchen wie Buchhaltung, Finanzdienstleistungen, Marketing, Bankwesen und Loyalität bei der Automatisierung der Dateneingabe. Mit Klippa DocHorizon können Unternehmen in diesen Branchen Bilder erfassen, Daten extrahieren,sensible Daten anonymisieren, Dokumente klassifizieren und Dokumente in durchsuchbare Dateien konvertieren.
Vorteile von Klippa DocHorizon
- Erfassung von Feldern und Einzelposten
- EU- und US-Infrastruktur
- Cloud- und Vor-Ort-Einsatz
- Extraktion von Unterschriften und Bildern
- Maskierung von Daten
- Vorverarbeitung von Bildern
- Standard-SLA
- Senden Sie Dateien jederzeit und überall
- Integrierbar über API oder SDK in Anwendungen von Drittanbietern
- Klassifizierung von Dokumenten und Daten
- Gegenprüfung mit Datenbanken von Drittanbietern
Nachteile von Klippa DocHorizon
- Keine Unterstützung für nicht-lateinische Alphabete
- Keine Speicherung von Dokumenten
Anwendungsmöglichkeiten von Klippa DocHorizon
- Finanzdokumente (Rechnungen, Belege, etc.)
- Ausweisdokumente (Reisepässe, Personalausweise, Führerscheine)
- Einzelhandelsdokumente
#2 GImageReader
GImage Reader ist eine kostenlose OCR-Anwendung, mit der sich Bilder und PDF-Dateien mühelos öffnen lassen. Nach dem Öffnen eines Dokuments können Benutzer einen beliebigen Bereich eines Bildes oder einer PDF-Datei auswählen und den erforderlichen Text extrahieren.
Vorteile von GImageReader
- Mehrere Bilder können in einem Arbeitsgang verarbeitet werden
- Offene Quelle
- Unterstützt die Anpassung von Dokumenten
- Integriert mit Tesseract OCR Sprache
Nachteile von GImageReader
- Keine erweiterten Anpassungen möglich
- Keine Anonymisierung der Daten
- Beschränkung auf Bilder und PDF-Dateien
Anwendungsmöglichkeiten von GImageReader
- PDF-Dokumente
- Bilder
#3 OCR4all
Mit OCR4all werden verschiedene Open-Source-Lösungen kombiniert, die dem Nutzer einen vollautomatischen Workflow zur automatischen Texterkennung bieten. OCR4all beabsichtigt, seinen Service speziell für nicht-technische Benutzer anzubieten.
Vorteile von OCR4all
- Open source OCR tool
- Flexible application to many document types (from manuscripts to printings)
- Easy cross-platform deployment
Nachteile von OCR4all
- Manuelle Beschriftung von Textelementen mit dem LAREX-Editor
- Apple-Geräte mit einem M1 / M2-Chip werden noch nicht unterstützt
- Die Installation und der Start von Docker scheint ein häufiges Problem zu sein
- Keine Anonymisierung der Daten
Anwendungsmöglichkeiten von OCR4all
- Bilder
#4 OpenScan
Mit OpenScan können Benutzer Dokumente und Notizen scannen und in PDF- oder JPEG-Dateien umwandeln. Es ist eine Open-Source-App mit dem Motto “Keine Werbung. Keine Datenerfassung. Wir respektieren Ihre Privatsphäre.”.

Vorteile von OpenScan
- Fokus auf Datenschutz
- Werbefrei
- Einfache PDF-Signierung
- Eingebauter Vorschau-Viewer
- Ermöglicht das Ausfüllen von PDF-Formularen
- Mobiltelefon als mobiler Scanner
Nachteile von OpenScan
- Begrenzt auf PDF-Dokumente
- Keine Datenextraktion möglich
Anwendungsmöglichkeiten von OpenScan
- PDF-Dokumente
#5 Kofax OmniPage
Kofax OmniPage ist eine OCR-Software, die in der Lage ist, die Extraktion von Daten aus großen Mengen von PDF-Dokumenten zu automatisieren. Sie ist auf die Extraktion von Tabellen und den Abgleich von Zeilen spezialisiert. Die intelligente Automatisierungsplattform von Kofax unterstützt Unternehmen bei der Transformation informationsintensiver Geschäftsprozesse.

Vorteile von Kofax OmniPage
- Erkennt über 120 Sprachen bei der Dokumentenverarbeitung
- Verwendung von mobilen Scannern, Desktop-Scannern, All-in-One-Druckern und Multifunktionsdruckern
- Suche, Bearbeitung und Zugriff auf Dokumente von jedem Gerät aus
- Erfassung von Feldern und Belegpositionen
- Speicherung von Dokumenten
Nachteile von Kofax OmniPage
- Die Benutzeroberfläche könnte verbessert werden
- Keine Abgleiche mit Datenbanken von Drittanbietern
- Keine europäische Infrastruktur
- Kein Einsatz vor Ort möglich
- Keine Möglichkeit zur Unterschriften- und Bildextraktion
- Keine Datenmaskierung
Anwendungsmöglichkeiten von Kofax OmniPage
- Rechnungen
- Belege
- Kaufaufträge
Warum Klippa DocHorizon die beste Alternative zu Tesseract ist
Mit Klippa DocHorizon sind Unternehmen auf der ganzen Welt in der Lage, dokumentenbezogene Arbeitsabläufe zu automatisieren. Mit unserer KI-basierten Software sind Sie in der Lage, Daten aus unstrukturierten Datenformaten (z. B. PDFs) präzise zu extrahieren und diese darüber hinaus zu verifizieren und zu anonymisieren.
Klippa DocHorizon zielt darauf ab, die manuelle Dateneingabe zu automatisieren und Unternehmen zu helfen, Zeit, Kosten und Ressourcen zu sparen. Unsere Lösung ist über API und SDK verfügbar und bietet die folgenden Vorteile:
- Datenextraktion → Datenextraktion wichtiger Informationen in Echtzeit
- Mobiles Scannen → Dokumente können mit mobilen Geräten jederzeit und an jedem Ort gescannt werden
- OCR → Dokumente können in Text und strukturierte, maschinenlesbare Formate umgewandelt werden
- Klassifizierung → Dokumente können nach Ihren Bedürfnissen klassifiziert und sortiert werden
- Anonymisierung → Sensible Daten können maskiert oder entfernt werden, um Sie und Ihre Kunden vor Datenverstößen zu schützen
- Dokumentenkonvertierung → Unstrukturierte Dokumentenformate wie JPG, PNG und PDF können in durchsuchbaren Text konvertiert und anschließend in strukturierte, maschinenlesbare Formate wie CSV, XLSX, XML und JSON exportiert werden.
- Verifizierung → Die Authentizität und Gültigkeit von Dokumenten und Daten kann überprüft werden.
Möchten Sie mehr über unsere Lösung erfahren und wie sie als Alternative zu Tesseract dienen kann? Wir zeigen Ihnen gerne, wie unsere Software funktioniert. Buchen Sie einfach unten eine kostenlose Demo oder kontaktieren Sie einen unserer Experten.