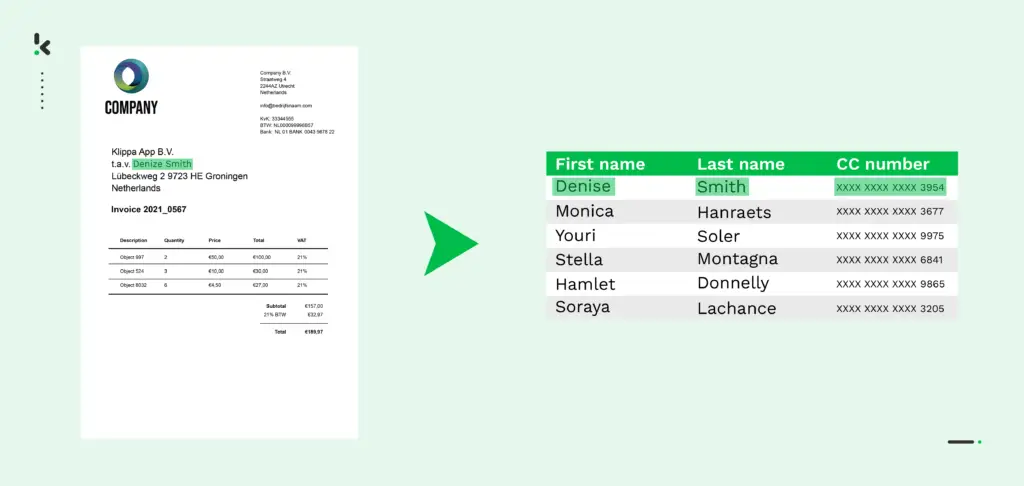
Daten entfalten ihren Wert erst, wenn Systeme sie eindeutig erkennen, vergleichen und weiterverarbeiten können. In vielen Unternehmen liegen relevante Informationen jedoch in unterschiedlichen Systemen, Dokumenten oder Datenbanken. Dadurch entstehen Schreibvarianten, Dubletten und unvollständige Datensätze, die automatische Prozesse verlangsamen oder falsche Entscheidungen auslösen.
Schlechte Datenqualität entsteht häufig nicht durch fehlende Daten, sondern durch uneinheitliche Daten. Ein Kundenname kann abgekürzt sein, eine Rechnungsnummer falsch erkannt werden oder ein Lieferant mehrfach mit leicht unterschiedlichen Schreibweisen vorkommen. Solche Abweichungen erschweren Suche, Datenabgleich und automatisierte Dokumentenverarbeitung. Eine Dell-Studie hat festgestellt, dass Datenverluste Unternehmen fast 900.000 Euro im Jahr kosten.
Fuzzy Matching löst dieses Problem, indem es nicht nur exakte Übereinstimmungen sucht, sondern auch ähnliche Zeichenfolgen erkennt. Das System vergleicht Werte, berechnet die Abweichung und entscheidet anhand eines Ähnlichkeitswerts, ob zwei Einträge zusammengehören. Dadurch lassen sich Tippfehler, OCR-Abweichungen, Abkürzungen und Dubletten zuverlässig erkennen.
In Dokumentenprozessen ist Fuzzy Matching besonders relevant, weil OCR-Ergebnisse selten immer exakt sind. Wenn ein Feld wie „Rechnungsnummer“ falsch gelesen oder verkürzt dargestellt wird, kann ein Fuzzy-Matching-Algorithmus trotzdem die wahrscheinlich passende Information identifizieren. Das verbessert die Datenqualität, reduziert manuelle Prüfungen und macht extrahierte Dokumentendaten nutzbar für nachgelagerte Workflows.
Wichtige Erkenntnisse
- Fuzzy Matching ersetzt exakte Suche durch Ähnlichkeitslogik: Statt nur identische Werte zu erkennen, vergleicht der Algorithmus Zeichenfolgen und berechnet Abweichungen. Dadurch können auch fehlerhafte, verkürzte oder unterschiedlich formatierte Daten korrekt zugeordnet werden.
- Algorithmen gleichen typische Datenabweichungen systematisch aus: Verfahren wie die Levenshtein-Distanz erkennen Unterschiede durch Einfügen, Löschen, Ersetzen oder Vertauschen von Zeichen. Systeme nutzen diese Logik, um trotz Abweichungen die wahrscheinlich passende Übereinstimmung zu bestimmen.
- Direkter Einfluss auf Dokumenten- und Datenprozesse: Fuzzy Matching wird in der Dokumentendatenextraktion eingesetzt, um OCR-Fehler auszugleichen, in Suchsystemen für bessere Treffer und in Datenbanken zur Erkennung von Dubletten. Dadurch werden Daten nutzbar, auch wenn sie nicht exakt vorliegen.
- Doxis AI.dp integriert Fuzzy Matching in die Extraktionslogik: Nach der OCR-Erkennung werden Datenfelder mit erwarteten Mustern abgeglichen und anhand von Ähnlichkeitswerten bewertet. So können relevante Informationen auch ohne exakte Übereinstimmung extrahiert und doppelte Trainingsdaten entfernt werden, was die Genauigkeit und Effizienz der Verarbeitung erhöht.
Was ist Fuzzy Matching?
Fuzzy Matching (FM), auch bekannt als Fuzzy Logic Name Matching oder Approximate String Matching, Fuzzy Matching beschreibt eine Methode, mit der Systeme ähnliche statt identische Datenwerte erkennen. Anstatt nur exakte Übereinstimmungen zu finden, vergleicht der Algorithmus Zeichenfolgen, berechnet deren Unterschiede und bewertet, wie nah sie beieinander liegen. Diese Technik wird häufig durch Technologien wie künstliche Intelligenz (KI) und Machine Learning (ML) ermöglicht.
Fuzzy Matching basiert auf dem Vergleich von Zeichenketten anhand definierter Regeln. Der Algorithmus analysiert zwei Werte und berechnet, wie viele Änderungen notwendig sind, um sie identisch zu machen. Dazu zählen beispielsweise das Hinzufügen, Entfernen oder Ersetzen von Zeichen. Aus diesen Änderungen entsteht ein Ähnlichkeitswert, der entscheidet, ob eine Übereinstimmung vorliegt.
Ein typisches Problem entsteht bei der Suche nach Daten in Dokumenten. Wenn beispielsweise der Begriff „Rechnungsnummer“ in einem Dokument als „Rechnungnummer“ falsch geschrieben oder als „Rechnungs-Nr.“ abgekürzt ist, liefert eine klassische Suche kein Ergebnis. Das System erkennt keine exakte Übereinstimmung und übersieht relevante Informationen.
Mit Fuzzy Matching wird der Begriff trotzdem erkannt. Der Algorithmus identifiziert die Abweichung, bewertet die Ähnlichkeit und ordnet die Begriffe einander zu.

Mit einem Fuzzy-Matching-Algorithmus stellt diese Abweichung kein Problem dar. Das System vergleicht die Begriffe, identifiziert Unterschiede und berechnet daraus einen Ähnlichkeitswert zwischen 0-100%. Auf dieser Basis entscheidet es, ob zwei Werte trotz Abweichungen als übereinstimmend gelten und weiterverarbeitet werden können.
Editierkorrekturen beschreiben die notwendigen Anpassungen, um zwei Zeichenfolgen anzugleichen. Der Algorithmus analysiert, welche Änderungen erforderlich sind, zum Beispiel das Einfügen, Entfernen oder Ersetzen von Zeichen. Jede dieser Anpassungen wird gezählt und beeinflusst den berechneten Ähnlichkeitswert.
Die vier grundlegenden Korrekturoperationen
Im Allgemeinen verwenden FM-Algorithmen die folgenden Schnittkorrekturen:
- Einfügen
- Fehlende Zeichen werden ergänzt
- Beispiel: „Rechnun“ → „Rechnung“
- Löschen
- Überflüssige Zeichen werden entfernt
- Beispiel: „Rechnnung“ → „Rechnung“
- Ersetzen (Substitution)
- Falsche Zeichen werden korrigiert
- Beispiel: „Technung“ → „Rechnung“
- Vertauschen (Transposition)
- Falsch angeordnete Zeichen werden umgestellt
- Beispiel: „Rehcnung“ → „Rechnung“
Wie die Übereinstimmung berechnet wird
Jede Korrektur zählt als eine Einheit in der sogenannten Bearbeitungsdistanz.
Der Algorithmus summiert alle notwendigen Anpassungen und setzt sie ins Verhältnis zur Länge der Zeichenfolge. Daraus ergibt sich ein Ähnlichkeitswert, der angibt, wie nah zwei Begriffe beieinander liegen.
Beispiel:
Eine Zeichenfolge mit 11 Zeichen erfordert 2 Korrekturen → Übereinstimmung ≈ 81,8 %
Um ein besseres Verständnis für die Funktionsweise von Fuzzy Matching und die Berechnung der Bearbeitungsdistanzen zu bekommen, werden im nächsten Abschnitt verschiedene Fuzzy Matching Algorithmen im Detail erläutert.
Fuzzy-Matching-Algorithmen
Fuzzy Matching fällt in die Kategorie der Methoden, für die es keinen spezifischen Algorithmus gibt, der alle Szenarien und Anwendungsfälle abdeckt. Daher werden wir einige der am häufigsten verwendeten und zuverlässigsten Fuzzy-Matching-Algorithmen für die Suche nach ungefähren Datenübereinstimmungen behandeln:
- Levenshtein-Distanz (LD)
- Hamming-Distanz (HD)
- Damerau-Levenshtein
Levenshtein-Distanz
Die Levenshtein-Distanz ist der am häufigsten eingesetzte Algorithmus im Dokumenten- und Datenmanagement. Sie berechnet, wie viele Änderungen notwendig sind, um eine Zeichenfolge in eine andere zu überführen. Dabei werden Einfügen, Löschen und Ersetzen von Zeichen berücksichtigt. Je weniger Anpassungen erforderlich sind, desto näher liegen die Begriffe beieinander und desto höher ist die Übereinstimmung.
Nehmen wir an, Sie möchten die LD zwischen „Rechnungsnummer“ und „Rechnungs-Nr.“ messen. Der Abstand zwischen den beiden Begriffen ist „1 x u“, „2 x m“ und „1 x e“, was einem Abstand von 4 entsprechen würde. Warum? Weil Sie diese Zeichen hinzufügen müssten, um eine Übereinstimmung zu erreichen. Siehe die Beispiele unten.
Levenshtein-Abstand Beispiel
- Rechnungnummer → Rechnungsnummer (Einfügung von „s“) – Abstand: 1
- Rechnung numr → Rechnungsnummer (Einfügung von „m“ & „e“) – Abstand: 2
- Rechnung nr → Rechnungsnummer (Einfügung von „u, m, m, e„) – Abstand: 4
Hamming-Distanz
Die Hamming-Distanz vergleicht Zeichen an festen Positionen und berechnet Unterschiede zwischen gleich langen Zeichenfolgen. Sie eignet sich nur für Daten, bei denen die Struktur identisch ist, da keine Einfügungen oder Löschungen berücksichtigt werden. In realen Dokumentenprozessen ist sie daher weniger flexibel, da Daten häufig unterschiedlich formatiert oder unvollständig sind.
Die HD-Methode basiert auf der ASCII-Tabelle (American Standard Code for Information Interchange). Zur Berechnung des Abstandswertes verwendet der Hamming-Distanz-Algorithmus die Tabelle, um den Binärcode zu bestimmen, der jedem Buchstaben in den Zeichenketten zugeordnet ist.
Hamming-Abstand-Beispiel
Nehmen wir die folgenden Textzeichenfolgen „Number“ und „Lumber“ als Beispiel. Wenn wir versuchen, den HD zwischen den Zeichenfolgen zu bestimmen, ist der Abstand nicht 1, wie es mit dem Levenshtein-Algorithmus der Fall wäre. Stattdessen würde er 10 betragen. Das liegt daran, dass die ASCII-Tabelle einen Binärcode von (1001110) für den Buchstaben N und (1001100) für den Buchstaben L anzeigt.
Beispielrechnung:
D = N – L = 1001110 – 1001100 = 10
Damerau-Levenshtein
Die Damerau-Levenshtein-Distanz erweitert die klassische Levenshtein-Logik um eine zusätzliche Operation: das Vertauschen von benachbarten Zeichen. Dadurch können typische Eingabefehler wie Buchstabendreher effizient erkannt werden, ohne mehrere Korrekturen berechnen zu müssen. Das reduziert die Distanz und verbessert die Trefferquote bei realen Schreibfehlern..
Hier unterscheidet sich die Damerau-Levenshtein-Distanz von der regulären Levenshtein-Distanz, da sie zusätzlich zu den Einzelzeichen-Editieroperationen, auch Transpositionen berücksichtigt, um eine ungefähre Übereinstimmung zu finden (Fuzzy Match).
Damerau-Levenshtein Beispiel
Zeichenfolge 1: Rechnung
Zeichenfolge 2: Rehcnun
Operation 1: Transposition -> Vertauschen der Zeichen „h“ und „c“
Operation 2: Einfügen eines „g“ am Ende der Zeichenfolge 2
Da zwei Operationen erforderlich waren, um die beiden Wörter identisch zu gestalten, beträgt der Abstand 2. Vereinfacht ausgedrückt zählt jede Operation wie Einfügung, Löschung, Transposition usw. als ein Abstand von „1“. Mit der Levenshtein-Distanz müssten Sie jedoch drei Korrekturen vornehmen, was einem Abstand von 3 entspricht.
Alle oben genannten Fuzzy-Matching-Algorithmen unterscheiden sich natürlich in der Art und Weise, wie die Bearbeitungsdistanz berechnet wird. Dies ist der Grund, warum es keinen FM-Algorithmus gibt, der für alle geeignet ist. Von den drei vorgestellten Algorithmen ist die Levenshtein-Distanz jedoch der am häufigsten verwendete FM-Algorithmus in der Datenverwaltung und Datenwissenschaft.
Fuzzy Matching Anwendungsfälle
Es gibt eine Vielzahl von Möglichkeiten, FM in der Praxis einzusetzen, von denen einige in Ihrem täglichen Leben vorkommen. Sehen wir uns im Folgenden ein paar Beispiele an (die Liste ist nicht vollständig):
- Extraktion von Dokumentendaten
- Automatischer Vorschlag mit Rechtschreibprüfung
- Deduplizierung
- Genom-Sequenzierung
Extraktion von Dokumentendaten
Obwohl OCR, auch bekannt als Bild-zu-Text Extraktionstechnologie, heute fortschrittlicher ist als vor 10 oder sogar 20 Jahren, kann sie immer noch ungenaue Datenextraktionsergebnisse liefern. Da viele Unternehmen eine Vielzahl von Dokumenten in großen Mengen verarbeiten, können sie durch ungenaue Datenextraktionsergebnisse erhebliche Geldbeträge verlieren.
Zur Ergänzung der OCR-Software und zur Lösung dieses Problems kann Fuzzy Matching eingesetzt werden. In Fällen, in denen OCR beim Extrahieren bestimmter Datenfelder und Daten aus Dokumenten keine „exakte Übereinstimmung“ findet, kann Fuzzy Matching helfen, die nächstgelegene Übereinstimmung mit einer annähernden Zeichenfolgenübereinstimmung unter Verwendung der Levenshtein-Distanz zu finden.
Auf diese Weise können Unternehmen immer noch Daten aus Dokumenten extrahieren, anstatt dass die OCR-Software überhaupt keine Ergebnisse liefert, wenn keine exakte Übereinstimmung gefunden werden kann.
Automatischer Vorschlag mit Rechtschreibprüfung
Wahrscheinlich sind Sie in Ihrem Leben schon auf verschiedene Suchmaschinen gestoßen oder haben sie benutzt. Dabei ist Ihnen auch aufgefallen, dass Suchmaschinen uns manchmal, trotz falsch geschriebener Wörter oder Sätze, die Inhalte liefern, nach denen wir suchen.
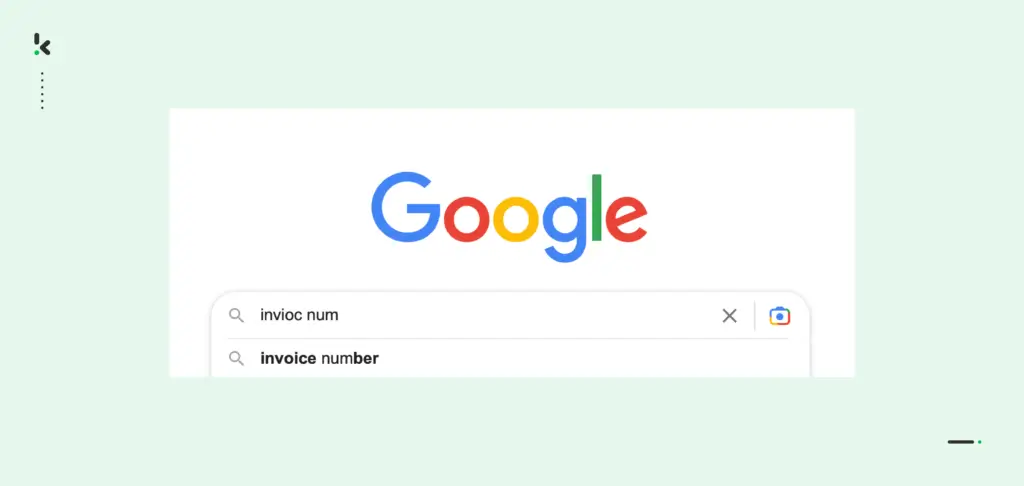
Das geschieht nur, weil Suchmaschinen wie Google Fuzzy-Matching-Algorithmen verwenden. Google versteht, was Sie als Hauptanfrage eingeben wollten, und bietet Ihnen eine Option für das Suchwort an, während Sie in die Suchleiste tippen.
Zusammen mit KI oder ML hat Fuzzy Matching dazu beigetragen, Suchmaschinen wie Google und YouTube zu verbessern, um das Sucherlebnis zu verbessern.
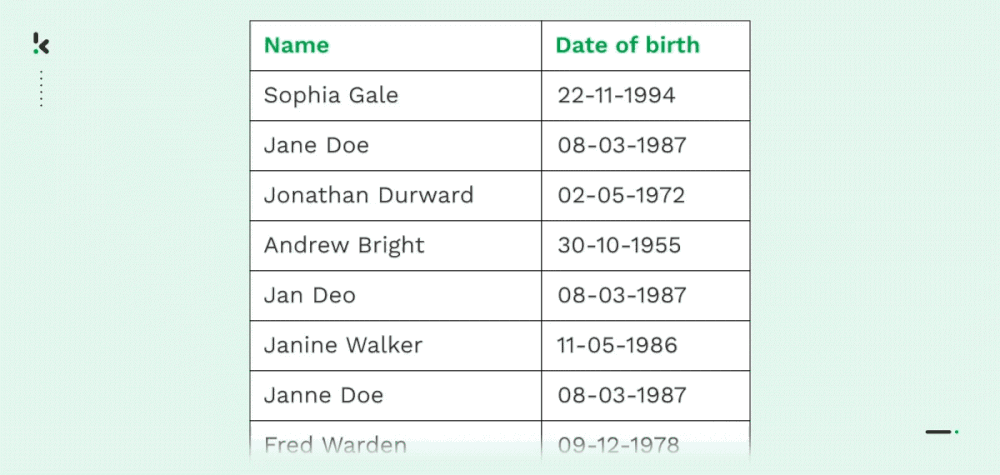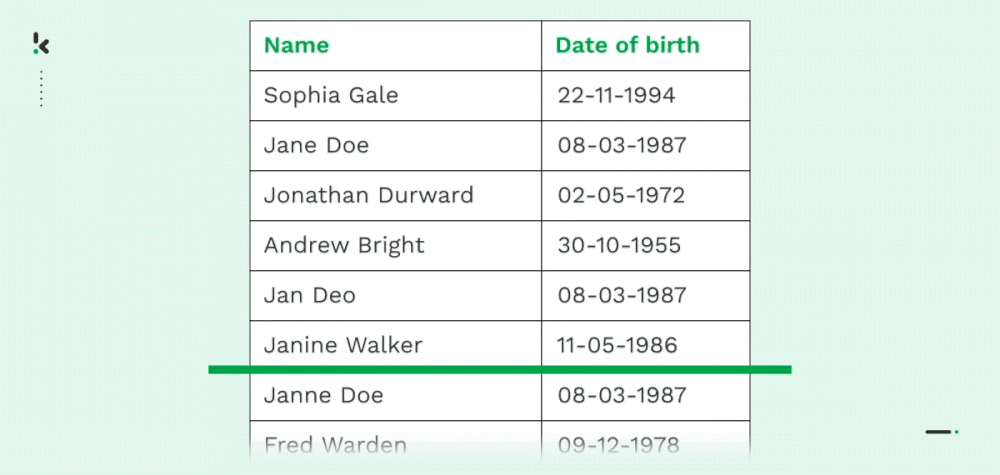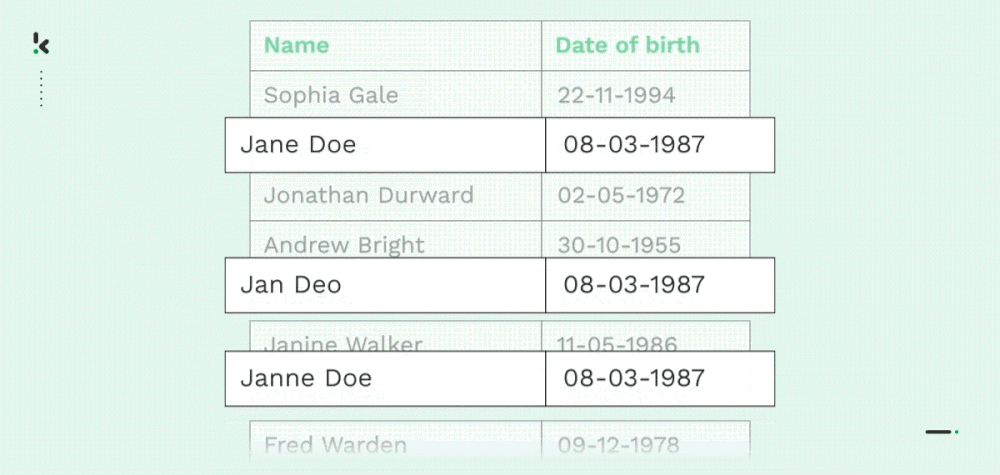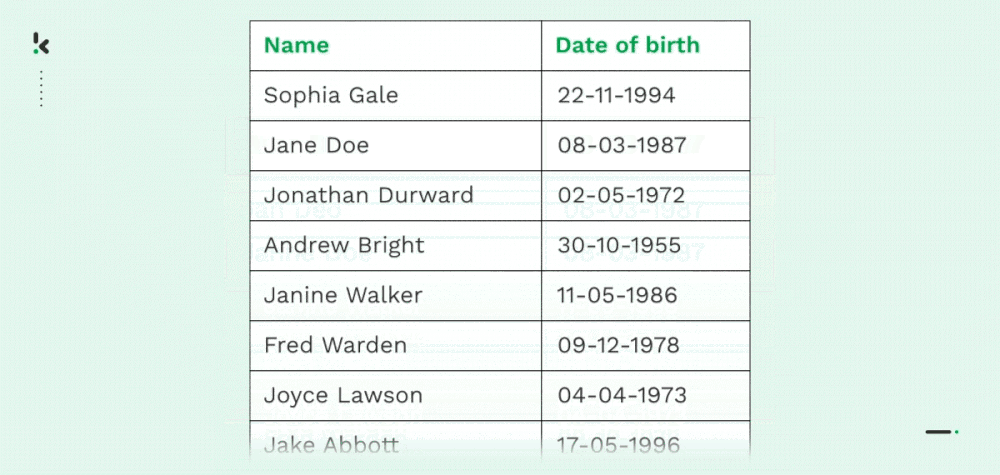
Deduplizierung
Wie bereits erwähnt, leiden zahlreiche Unternehmen unter doppelten Daten, hauptsächlich aufgrund von Datenübertragungen, mangelnder Kontrolle oder Dateneingabefehlern. Sowohl identische Kopien eines Datensatzes (Name, Adresse, E-Mail, Telefonnummer usw.) als auch teilweise Duplikate sind in Unternehmen üblich.
Mit Fuzzy Matching können Unternehmen Daten zusammenführen, löschen oder reorganisieren, indem sie ungefähre Übereinstimmungen finden. So können Unternehmen ihre Datensätze und ihr Datenmanagement rationalisieren, was verschiedene Vorteile mit sich bringt, die später in diesem Blog erläutert werden.
Die Entduplizierung ist auch sehr nützlich, wenn Sie OCR-Modelle trainieren, um Informationen aus Dokumenten zu extrahieren. Durch das Entfernen doppelter Datenproben aus den Trainingsdatensätzen wird das Training effizienter und die Vorhersagegenauigkeit der OCR-Modelle verbessert sich erheblich.
Genomsequenzierung
Im Gesundheitswesen und in der Wissenschaft kann das Fuzzy Matching sehr hilfreich sein, insbesondere bei der Genomsequenzierung. Es ermöglicht Forschern, eine ungefähre Übereinstimmung mit einer bestimmten Genomsequenz zu finden, indem sie einen Algorithmus auf die Sequenz anwenden.
Mit dem Fuzzy-Matching-Algorithmus sind sie in der Lage, die nächstgelegene übereinstimmende Sequenz oder Sequenzmenge zu finden und anhand des Ergebnisses zu bestimmen, zu welchem Organismus die Sequenz gehört. Ein Beispiel wäre die Suche nach der nächsten Übereinstimmung mit einem bestimmten Bakterium oder Virus, um das richtige Heilmittel zu finden.
Mit anderen Worten: Fuzzy Matching kann Forschern helfen, ein Heilmittel für bestimmte Krankheiten zu finden. Interessant, oder?
Inzwischen sollte klar sein, dass die Verwendung von FM flexibel ist und in verschiedenen Anwendungsfällen eingesetzt werden kann. Was auch immer Ihr Anwendungsfall sein mag, es gibt verschiedene Vorteile, die Fuzzy Matching mit sich bringt.
Vorteile des Fuzzy Matching
Zu den häufigsten Vorteilen für Unternehmen, die Fuzzy Matching als Ansatz zur Identifizierung von Übereinstimmungen verwenden, gehören:
- Höhere Datengenauigkeit in automatisierten Prozessen: Fuzzy Matching gleicht Abweichungen zwischen Datenwerten systematisch aus. Der Algorithmus erkennt Unterschiede, berechnet deren Distanz und ordnet Werte trotz Schreibfehlern oder Formatabweichungen korrekt zu. Dadurch werden auch unvollständige oder fehlerhafte Daten nutzbar gemacht. Das Ergebnis sind extrahierte und verarbeitete Daten, welche zuverlässiger zur Weiterverarbeitung sind.
- Durchsuchbare Daten trotz Abweichungen: Klassische Suchmechanismen scheitern an Tippfehlern oder unterschiedlichen Schreibweisen. Fuzzy Matching erweitert die Suche um eine Ähnlichkeitslogik, sodass auch variierende Begriffe gefunden werden. Das gilt insbesondere für Dokumente, OCR-Ergebnisse und große Datenbestände. So bleiben relevante Informationen bleiben auffindbar, unabhängig von Schreibweise oder Format.
- Automatische Bereinigung und Deduplizierung: In vielen Systemen entstehen doppelte oder leicht abweichende Datensätze. Fuzzy Matching erkennt diese Ähnlichkeiten und ermöglicht das Zusammenführen oder Entfernen von Duplikaten. Dadurch werden Datenbestände strukturiert und vereinheitlicht.
- Flexibler Einsatz in unterschiedlichen Anwendungsfällen: Fuzzy Matching lässt sich in verschiedene Systeme und Prozesse integrieren. Es wird in der Dokumentenverarbeitung, Datenintegration, Suche und Analyse eingesetzt und passt sich an unterschiedliche Datenstrukturen an. Besonders in Kombination mit KI und OCR erhöht es die Robustheit von automatisierten Workflows. So können Systeme auch mit komplexen und variierenden Daten zuverlässig arbeiten.
Nachteile des Fuzzy Matching
Nicht alles am Fuzzy String Matching ist perfekt. Im Gegenteil, FM weist verschiedene Einschränkungen auf, darunter:
- Falsche Verknüpfung: Obwohl Fuzzy Matching hervorragend geeignet ist, um ungefähre Übereinstimmungen zu finden, führt es manchmal zu einer hohen Anzahl von falsch positiven Ergebnissen, was zu falschen Verknüpfungen führt, insbesondere bei größeren Datenbanken.
- Erfordert Wartung: Die Algorithmen müssen ständig getestet und die Regeln aktualisiert werden, um einen genauen Zeichenkettenabgleich zu ermöglichen.
Obwohl es auch Nachteile gibt, bringt der Einsatz von Fuzzy Matching Unternehmen mehr Vorteile als Herausforderungen. Wie können Sie es also in Ihre eigenen Lösungen implementieren? Schauen wir uns das als Nächstes an!
Implementierung des Fuzzy Matching
Sie können Fuzzy-Matching-Algorithmen mit verschiedenen Programmiersprachen implementieren, darunter:
- Python: Die Fuzzywuzzy-Python-Bibliothek wendet den Levenshtein-Distanz-Ansatz an, um ein annäherndes String-Matching durchzuführen.
- Java: Es ist sehr schwierig, FM in Java zu implementieren, aber es ist über ein GitHub-Repository möglich, die Fuzzywuzzy-Bibliothek in Java zu implementieren.
- Excel: Einfache Implementierung von FM über Add-ons wie Exis Echo, Fuzzy Lookup und sogar unter Verwendung der nativen VLOOKUP-Funktion.
Natürlich ist es möglich, eigene Lösungen zu entwickeln, um ungefähre Übereinstimmungen von Zeichenfolgen zu finden, aber das kostet Zeit und erfordert viele Ressourcen. Oft ist es besser, eine Lösung zu erwerben, die Fuzzy-Matching-Algorithmen verwendet, um Ihren Anwendungsfall zu unterstützen.
Wenn Sie daran interessiert sind, wie wir bei Doxis Fuzzy Matching in unseren Lösungen einsetzen, dann lesen Sie weiter!
Wie verwendet Doxis Fuzzy Matching?
In der Dokumentenverarbeitung entstehen Abweichungen bereits im ersten Schritt der Datenextraktion. OCR-Systeme erkennen Inhalte aus Dokumenten, liefern jedoch nicht immer exakte Ergebnisse. Abkürzungen, unterschiedliche Schreibweisen oder Layoutvarianten führen dazu, dass relevante Datenfelder nicht eindeutig zugeordnet werden können.
Doxis AI.dp erweitert diesen Prozess durch Fuzzy Matching als Teil der Extraktionslogik. Nach der OCR-Erkennung werden extrahierte Werte nicht nur übernommen, sondern mit erwarteten Mustern und Referenzdaten abgeglichen. Dabei berechnet das System mithilfe der Levenshtein-Distanz die Abweichung zwischen erkanntem Wert und Zielstruktur. Sobald die Datenextraktion abgeschlossen ist, wird die Datenausgabe im JSON-Format mit einer Übereinstimmungsbewertung bereitgestellt.
Jedes extrahierte Datenfeld wird mit einem Ähnlichkeitswert versehen. Dieser Wert zeigt, wie nah das Ergebnis an einer erwarteten Übereinstimmung liegt. Auf Basis dieser Bewertung können Systeme automatisch entscheiden, ob Daten direkt verarbeitet oder zur Prüfung weitergeleitet werden.
In der Praxis bedeutet das:
- Hohe Trefferquote → automatische Weiterverarbeitung
- Niedrige Trefferquote → gezielte Validierung (z. B. Human-in-the-Loop)
Dadurch werden manuelle Prüfungen auf kritische Fälle reduziert, während Standardfälle vollständig automatisiert bleiben.
Fuzzy Matching wird nicht nur in der Extraktion eingesetzt, sondern auch in der Datenaufbereitung. Beim Training von OCR- und KI-Modellen identifiziert Doxis ähnliche oder doppelte Datensätze und bereinigt diese automatisch. Dadurch werden redundante Trainingsdaten entfernt und inkonsistente Beispiele vermieden.
Ergebnis:
- effizienteres Training
- stabilere Modelle
- geringere Fehlerraten bei der späteren Datenextraktion
Sind Sie daran interessiert, mit Fuzzy Matches die Datenextraktion oder das Datenmanagement in Ihrem Unternehmen zu verbessern? Vereinbaren Sie über das untenstehende Formular einen Termin für eine Demo, um zu sehen, wie unsere Lösung mit Fuzzy Matching funktioniert. Falls Sie ein Beratungsgespräch wünschen oder weitere Informationen wünschen, kontaktieren Sie einen unserer Experten.
FAQ – Häufig gestellte Fragen
1. Was ist Fuzzy Matching?
Fuzzy Matching ist eine Technik zur ungefähren Zeichenketten- und Textsuche, auch bekannt als Approximate String Matching. Mithilfe von Algorithmen wie der Levenshtein-Distanz oder der Hamming-Distanz werden Unterschiede zwischen Zeichenketten erkannt und bewertet, um auch dann Übereinstimmungen zu finden, wenn Tippfehler, Abkürzungen oder Formatabweichungen vorliegen.
2. Welche Algorithmen werden beim Fuzzy Matching eingesetzt?
Zu den häufigsten Algorithmen gehören:
Levenshtein-Distanz: misst die Anzahl notwendiger Änderungen (Einfügen, Löschen, Ersetzen), um eine Zeichenkette in eine andere umzuwandeln.
Hamming-Distanz: berechnet Unterschiede zwischen Zeichenketten gleicher Länge auf Basis ihrer binären ASCII-Codes.
Damerau-Levenshtein: berücksichtigt zusätzlich Transpositionen (Vertauschen zweier Zeichen).
3. In welchen Anwendungsfällen ist Fuzzy Matching sinnvoll?
Fuzzy Matching wird u. a. eingesetzt bei: Dokumentendaten-Extraktion, um OCR-Ergebnisse zu verbessern, Rechtschreibkorrekturen und Suchvorschlägen, Daten-Deduplizierung in Unternehmensdatenbanken und Genomsequenzierung in Forschung und Gesundheitswesen.
4. Welche Vorteile bietet Fuzzy Matching?
Fuzzy Matching sorgt für: Erhöhte Datengenauigkeit, durchsuchbare Daten trotz Abweichungen, Flexible Anpassung an verschiedene Szenarien und saubere Datenbank durch Entfernung von Duplikaten.
5. Welche Nachteile hat Fuzzy Matching?
Es kann zu falsch-positiven Ergebnissen kommen, insbesondere bei großen Datenmengen, und Algorithmen müssen regelmäßig geprüft sowie angepasst werden, um hohe Genauigkeit sicherzustellen.
6. Wie nutzt Doxis AI.dp Fuzzy Matching?
Doxis AI.dp verwendet die Levenshtein-Distanz, um auch bei fehlenden exakten Übereinstimmungen relevante Daten aus Dokumenten zu extrahieren. Außerdem wird es eingesetzt, um doppelte Datensätze aus Trainingsdaten zu entfernen, was den OCR-Trainingsprozess effizienter macht und die Genauigkeit erhöht.