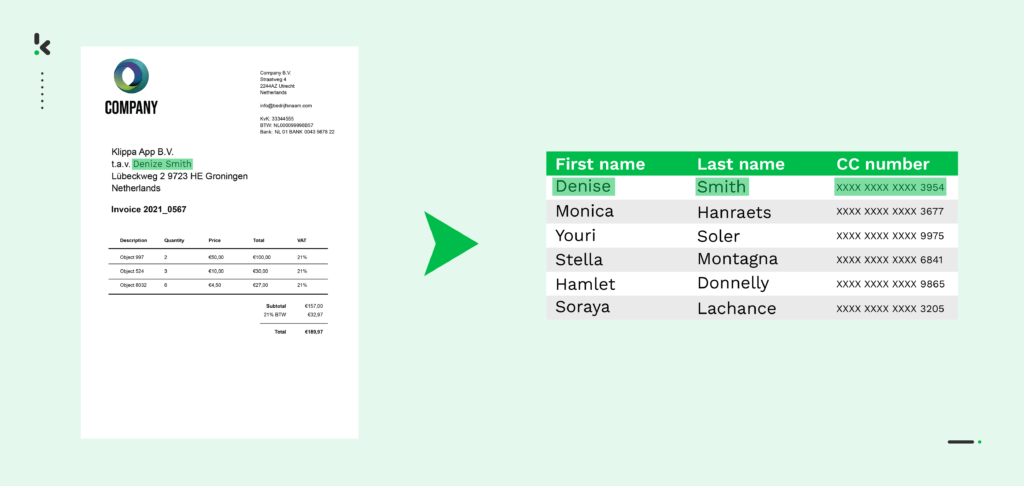
Ce n’est probablement pas nouveau pour vous que les données soient considérées comme de “l’or des temps modernes”. Bien que tout le monde soit conscient de l’importance des données, de nombreuses entreprises ne sont pas axées sur les données ou ne peuvent pas utiliser leurs données. Les raisons varient, mais c’est souvent parce que les données ne sont pas bien stockées, structurées ou même consultables pour être utilisées.
Bien que les données puissent être stockées, les entreprises peuvent les stocker plus d’une fois ou de manière inexacte en raison d’une erreur humaine. Cela conduit bien sûr à une mauvaise qualité des données, ce qui peut nuire gravement aux organisations. En fait, on dit que des données inexactes font perdre en moyenne 15 millions de dollars par année aux entreprises.
Pour relever les défis liés aux données, les entreprises peuvent utiliser des solutions automatisées capables de faire correspondre les données de deux sources de données différentes. Avec une telle solution, les données en double et les inexactitudes peuvent être facilement éliminées. C’est là que le Fuzzy Matching (aussi appelée correspondance floue) entre en jeu.
Pour comprendre ce concept technique, nous prendrons le temps d’expliquer ce qu’il est, pourquoi il est nécessaire pour les organisations modernes et comment il peut être mis en œuvre.
Allons-y !
Qu’est-ce que Fuzzy Matching?
Fuzzy Matching (FM) aussi appelée correspondance de noms en logique floue ou correspondance approximative de chaînes, est une technique qui aide les utilisateurs à comparer et à trouver une correspondance approximative entre deux sections de données différentes ou même une ligne de texte. Cette technique est souvent rendue possible par des technologies telles que l’intelligence artificielle (IA) et l’apprentissage machine (ML).
Techniquement, Fuzzy Matching est utilisée comme algorithme de correspondance de chaînes (algorithme qui recherche une chaîne dans ’autre chaîne) avec des règles prédéterminées pour trouver des chaînes, des mots ou des entrées en double qui sont les plus proches les uns des autres. Avec l’utilisation de Fuzzy Matching, il est possible de trouver des noms, des mots ou des chaînes qui sont abrégés, raccourcis ou mal orthographiés, par exemple.
Supposons que vous souhaitiez trouver “numéro de facture” sur un document, mais que le mot est mal orthographié “numéro de factur” ou est abrégé en “no de facture”. Dans cette situation, vous n’obtiendriez pas une correspondance exacte lors de la recherche du “numéro de facture”, donc vous ne pouvez pas trouver ce que vous cherchez.

Avec un algorithme de Fuzzy Matching, ce n’est pas un problème, car l’algorithme peut toujours trouver une correspondance approximative avec le mot mal orthographié ou raccourci en fournissant un score de correspondance de 0 à 100% basé sur les “corrections d’édition”. Une correction d’édition est une correction que l’algorithme FM doit effectuer en fonction de la logique pour ajuster une certaine chaîne afin que cette chaîne corresponde à une autre chaîne.
Corrections d’édition de Fuzzy Matching
En général, les algorithmes FM utilisent les corrections d’édition suivantes :
- Insertion – ajout d’une lettre pour compléter le mot (p. ex. “factur” devient “facture“)
- Suppression – suppression d’une lettre d’un mot (par exemple, “Facturee” devient “Facture”)
- Substitution – échange d’une lettre pour corriger un mot (par exemple, “pacture” devient “facture”)
- Transposition – échange de lettres pour corriger un mot (par exemple, “afcture” devient “facture”)
Chaque correction qui doit être effectuée attribuera une “distance d’édition” de 1. Les distances d’édition influencent le score de correspondance mentionné précédemment. Par exemple, si vous avez une chaîne de 11 caractères et que vous devez effectuer 2 corrections, le score de correspondance final est égal à 81,81 %.
Calcul : 100%- 2 / 11= 81,81%
En plus de ces corrections, FM peut être utilisé pour corriger les ponctuations, les mots supplémentaires et les espaces manquants dans les chaînes ou les textes.
Pour mieux comprendre le fonctionnement de Fuzzy Matching et le calcul des distances d’édition, la section suivante est consacrée à l’explication détaillée des différents algorithmes de Fuzzy Matching.
Fuzzy Matching Algorithmes
Fuzzy Matching fait partie de la catégorie des méthodes qui n’ont pas un algorithme spécifique qui couvre tous les scénarios et cas d’utilisation. Par conséquent, nous allons couvrir certains des algorithmes de Fuzzy Matching les plus couramment utilisés et fiables pour trouver des correspondances de données approximatives:
- Distance de Levenshtein (LD)
- Distance de Hamming (HD)
- Damerau-Levenshtein
Levenshtein Distance
La distance de Levenshtein (LD) est une technique de Fuzzy Matching qui prend en compte deux chaînes lors de la comparaison et de la recherche d’une correspondance. Plus la valeur de Levenshtein Distance est élevée, plus les deux chaînes ou “termes” sont loin d’être identiques.
Alors comment obtenir la valeur de la distance Levenshtein ? Le LD entre les deux chaînes est égal au nombre d’éditions nécessaires pour convertir une chaîne en l’autre. Pour l’ID, l’insertion, la suppression et la substitution d’un seul caractère s’appliquent en tant qu’opérations d’édition.
Supposons que vous voulez mesurer le LD entre “numéro de facture” et “nméro de factur”. La distance entre les deux termes est “1 x u” et “1 x e”, ce qui équivaudrait à une distance de 2. Pourquoi ? Parce qu’il faudrait ajouter ces deux caractères pour qu’ils correspondent exactement. Voir les exemples ci-dessous.
Levenshtein Distance Exemple
- Numéo de facture→ Numéro de facture (insertion de “r”) – Distance: 1
- Numéro de actre → Numéro de facture (insertion de “f” & “u”) – Distance: 2
- Numéro de fre → Numéro de facture (insertion de “a,c,t,u”) – Distance: 4
Hamming Distance
La distance de Hamming (HD) n’est pas trop différente de la Levenshtein. La distance de Hamming est souvent utilisée pour calculer la distance entre deux chaînes textuelles de longueur égale.
La méthode HD est basée sur la table ASCII (American Standard Code for Information Interchange). Pour calculer le score de distance, l’algorithme de distance de Hamming utilise la table pour déterminer le code binaire associé à chaque lettre dans les chaînes.
Exemple de distance de Hamming
Prenons les chaînes textuelles suivantes “number” (numéro) et “lumber” comme exemple. Lorsque nous essayons de déterminer le HD entre les chaînes, la distance n’est pas 1 comme ce serait le cas avec l’algorithme de Levenshtein. Au lieu de cela, ce serait 10. En effet, la table ASCII montre un code binaire de (1001110) pour la lettre N et (1001100) pour la lettre L.
Exemple de calcul:
D = N – L = 1001110 – 1001100 = 10
Damerau-Levenshtein
Le Damerau-Levenshtein mesure également la distance entre deux mots en mesurant les changements requis pour ajuster un mot dans l’autre. Ces modifications dépendent du nombre d’opérations telles que les insertions, les suppressions ou les substitutions d’un seul caractère ou la transposition de deux caractères adjacents.
C’est là que la distance de Damerau-Levenshtein diffère de la distance de Levenshtein normale, car elle inclut des transpositions en plus des opérations d’édition d’un seul caractère pour trouver une correspondance approximative (Fuzzy Match).
Damerau-Levenshtein Exemple
Chaîne 1: Facture
Chaîne 2: Facutr
Operation 1: transposition -> Échanger des caractères “u” and “t”
Operation 2: insérer “e” à la fin de la chaîne 2
Comme deux opérations étaient nécessaires pour rendre les deux chaînes identiques, la distance est égale à 2. En d’autres termes, chaque opération telle que l’insertion, la suppression, la transposition, etc, compte comme une distance de “1”. Cependant, avec la distance Levenshtein, vous devez effectuer trois corrections d’édition, ce qui équivaut à la distance de 3.
Il est clair que tous les algorithmes de Fuzzy Matching mentionnés ci-dessus diffèrent les uns des autres dans la façon dont la distance d’édition est calculée. C’est la raison pour laquelle il n’y a pas d’algorithme FM adapté à tous. Cependant, la distance de Levenshtein est l’algorithme FM le plus couramment utilisé dans la gestion des données et la science des données, parmi les trois qui ont été présentés.
Fuzzy Matching Cas D’utilisation
Il existe de multiples façons d’utiliser la FM dans des applications réelles, dont certaines font partie de votre vie quotidienne. Examinons quelques exemples ci-dessous (la liste n’est pas exhaustive) :
- Extraction de données de document
- Suggestion automatique avec vérification orthographique
- Déduplication
- Séquençage Du Génome
Extraction de données de document
Bien que l’OCR, également connue sous le nom de technologie d’extraction image-texte, soit plus avancée qu’il y a 10 ou même 20 ans, il peut toujours produire des résultats d’extraction de données inexacts. Comme de nombreuses entreprises traitent un large éventail de documents en grande quantité, des résultats d’extraction de données inexacts peuvent leur faire perdre des sommes d’argent considérables.
Pour compléter le logiciel OCR et contribuer à résoudre ce problème, il est possible d’appliquer le Fuzzy Matching. Lorsque l’OCR ne parvient pas à trouver une “correspondance exacte” lors de l’extraction de certains champs de données et de données de documents, Fuzzy Matching peut aider à trouver la correspondance la plus proche grâce à une correspondance approximative des chaînes de caractères en utilisant la distance de Levenshtein.
Ainsi, les entreprises sont toujours en mesure d’extraire les données des documents au lieu que le logiciel d’OCR ne produise aucun résultat lorsqu’aucune correspondance exacte ne peut être trouvée.
Suggestion automatique avec vérification orthographique
Vous avez probablement rencontré ou utilisé différents moteurs de recherche au cours de votre vie. Ce faisant, vous avez également remarqué que les moteurs de recherche nous fournissent parfois le contenu que nous recherchons malgré les mots ou les phrases mal orthographiés.
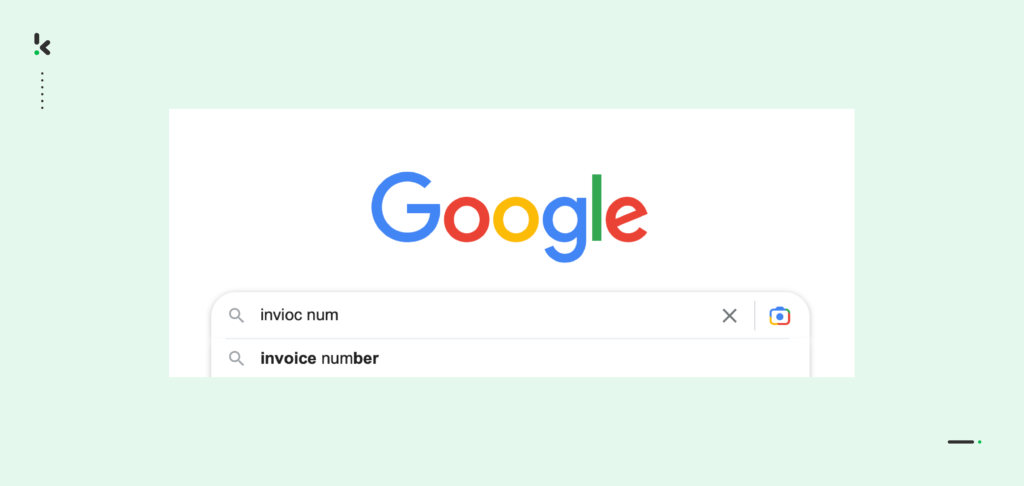
Cela est dû au fait que les moteurs de recherche tels que Google utilisent des algorithmes de Fuzzy Matching. Google comprend ce que vous avez voulu taper comme requête principale et vous propose une option pour le mot recherché lorsque vous tapez dans la barre de recherche.
Avec l’IA ou la ML, le Fuzzy Matching a permis d’améliorer les moteurs de recherche tels que Google et YouTube afin d’améliorer l’expérience de la recherche.
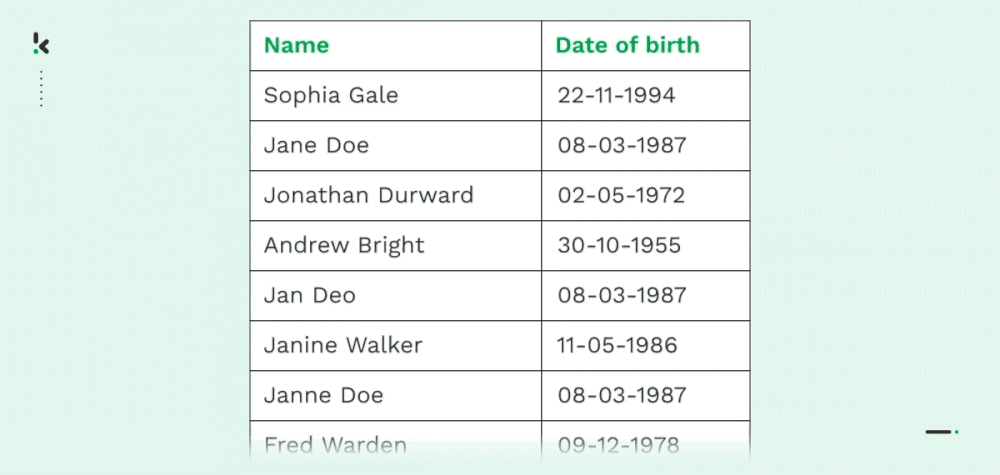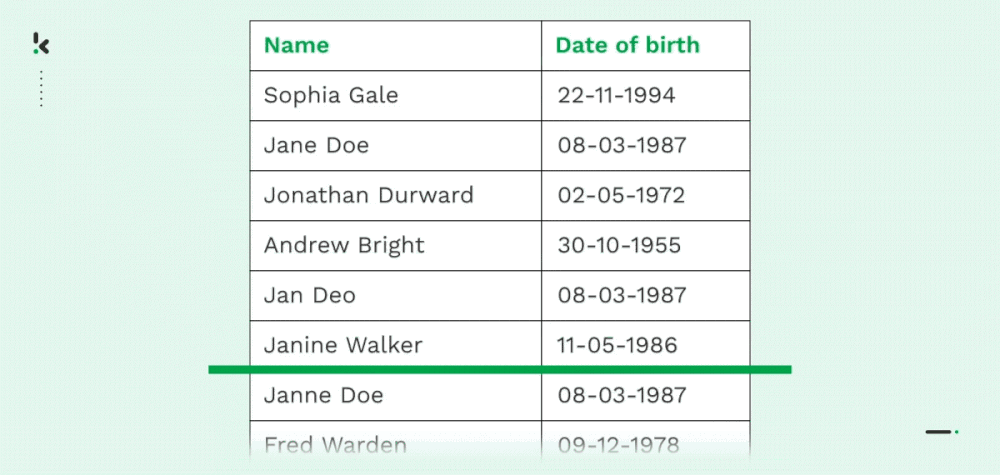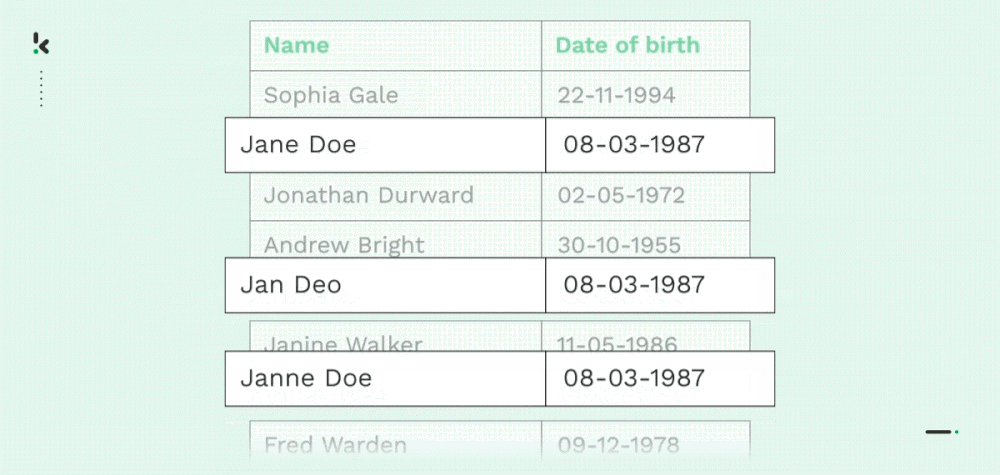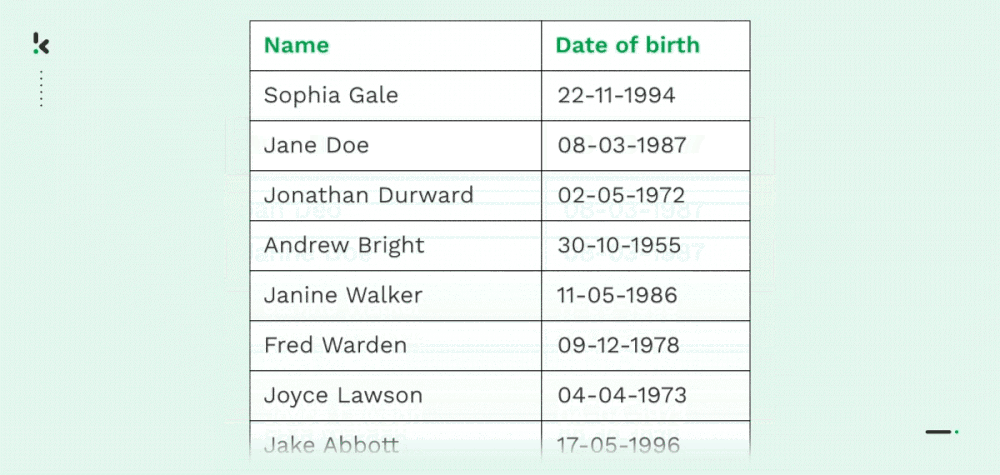
Déduplication
Comme mentionné précédemment, de nombreuses entreprises souffrent de données en double, principalement en raison de transferts de données, d’un manque de contrôle ou d’erreurs de saisie de données. Les copies carbone d’un document (nom, adresse, courriel, numéro de téléphone, etc.) ou les copies partielles sont courantes pour les organisations.
Avec Fuzzy Matching, les organisations peuvent fusionner, supprimer ou réorganiser les données en trouvant des correspondances approximatives. Il permet aux organisations de rationaliser la gestion de leurs enregistrements et de leurs données, ce qui s’accompagne de divers avantages abordés plus loin dans ce blog.
La déduplication est également très utile lorsque vous entraînez des modèles OCR à extraire des informations de documents. En supprimant les échantillons de données en double des ensembles de données d’apprentissage, la formation devient plus efficace et la précision de prédiction des modèles OCR s’améliore considérablement.
Séquençage du génome
Dans les soins de santé et la science, l’appariement flou peut être très utile, en particulier dans le séquençage du génome. Il permet aux chercheurs de trouver une correspondance approximative avec une séquence génomique particulière en exécutant un algorithme sur la séquence.
Avec l’algorithme d’appariement flou, ils sont capables de trouver la séquence d’appariement la plus proche ou l’ensemble de séquences pour déterminer à quel organisme la séquence appartient en fonction du résultat. Un exemple serait de trouver la correspondance la plus proche d’une certaine bactérie ou d’un virus afin de trouver le bon remède.
En d’autres termes, Fuzzy Matching peut aider les chercheurs à trouver un remède pour certaines maladies. Intéressant, n’est-ce pas?
À présent, il devrait être clair que l’utilisation de FM est flexible et peut être appliquée dans divers cas d’utilisation. Quel que soit votre cas d’utilisation, Fuzzy Matching présente divers avantages.
Avantages de Fuzzy Matching
Les avantages les plus courants pour les organisations utilisant Fuzzy Matching comme approche pour identifier les correspondances sont les suivants:
- Précision des données – Les organisations peuvent atteindre une précision élevée de correspondance des données, car FM a la capacité de rechercher des correspondances approximatives en analysant les chaînes et en calculant le score de distance “modifier” à l’aide d’algorithmes.
- Données consultables – Fuzzy Matching permet aux utilisateurs de trouver des correspondances malgré les variations dues à des erreurs telles que des fautes d’orthographe, des majuscules manquantes ou une mise en forme manquée de mots ou de chaînes.
- Flexibilité – Il existe de nombreuses façons dont les algorithmes de logique floue peuvent aider à résoudre même les problèmes les plus complexes.
- Base de données plus propre – Les algorithmes de Fuzzy Matching peuvent aider les organisations à trouver des enregistrements de données en double pour une base de données plus saine, plus propre et plus précise.
Inconvénients de Fuzzy Matching
Tout ce qui concerne la correspondance de chaînes floues n’est pas parfait. Au contraire, la FM est livrée avec diverses limitations, notamment:
- Liens incorrects – Bien que Fuzzy Matching soit excellente pour trouver des correspondances approximatives, elle entraîne parfois un grand nombre de faux positifs conduisant à des liens incorrects, en particulier avec des bases de données plus volumineuses.
- Nécessite une maintenance – Les algorithmes doivent être constamment testés et les règles qu’ils contiennent mises à jour afin d’effectuer une correspondance de chaîne précise.
Bien qu’il y ait des inconvénients, l’utilisation de Fuzzy Matching profite davantage aux entreprises qu’à la création de défis. Alors, comment pouvez-vous l’implémenter dans vos propres solutions? Jetons un coup d’œil à cela ensuite!
Application Fuzzy Matching
Vous pouvez implémenter des algorithmes de fuzzy matching à l’aide de différents langages de programmation, notamment:
- Python – Fuzzywuzzy La bibliothèque Python applique l’approche Levenshtein Distance pour effectuer une correspondance approximative de chaînes.
- Java – Il est très difficile d’implémenter FM en Java, cependant, cela se fait via un référentiel GitHub pour implémenter la bibliothèque Fuzzywuzzy en Java.
- Excel – Mise en œuvre facile de FM via des add-ons tels que Exis Echo, Fuzzy Lookup et même en utilisant la fonction native RECHERCHEV.
Bien sûr, il est possible de créer vos propres solutions pour trouver des correspondances de chaînes approximatives, mais cela prend du temps et nécessite des ressources. Il est souvent préférable d’acquérir une solution qui utilise des algorithmes de Fuzzy Matching pour soutenir votre analyse de rentabilisation.
Si vous êtes curieux de savoir comment chez Doxis nous utilisons Fuzzy Matching dans nos solutions, continuez à lire!
Comment Doxis utilise-t-il Fuzzy Matching?
De nombreux logiciels OCR comme Doxis AI.dp se concentrent principalement sur la recherche d’une correspondance exacte dans les champs de données pour l’extraction de données. Cependant, tous les logiciels OCR ne peuvent pas toujours trouver des correspondances exactes lors de l’extraction de données pour diverses raisons telles que l’utilisation d’abréviations, de mots abrégés, etc. C’est pourquoi il est important d’utiliser Fuzzy Matching pour s’assurer que les données pertinentes peuvent être extraites des documents.
À cet égard, Doxis utilise la distance de Levenshtein pour trouver des correspondances approximatives et s’assurer que toutes les données pertinentes sont extraites. Une fois l’extraction des données terminée, la sortie des données est fournie au format JSON avec un score de correspondance. Avec le score de match, les clients de Doxis peuvent déterminer s’ils ont besoin de demander à une personne de vérifier les résultats pour éviter d’obtenir des résultats inexacts.
En plus de l’extraction de données, Doxis utilise Fuzzy Matching pour éliminer les données en double des ensembles de données afin d’entraîner des modèles OCR. De cette façon, le processus de formation est plus efficace et apporte de meilleurs résultats d’amélioration car aucun temps n’est perdu et les risques de faux positifs (dans les résultats d’extraction et de reconnaissance des données) sont réduits.
Êtes-vous intéressé à trouver Fuzzy Matches pour améliorer l’extraction ou la gestion des données de votre organisation? N’hésitez pas à planifier une démo via le formulaire ci-dessous pour voir comment notre solution fonctionne avec Fuzzy Matching. Si vous souhaitez avoir une consultation ou obtenir plus d’informations, contactez l’un de nos experts.