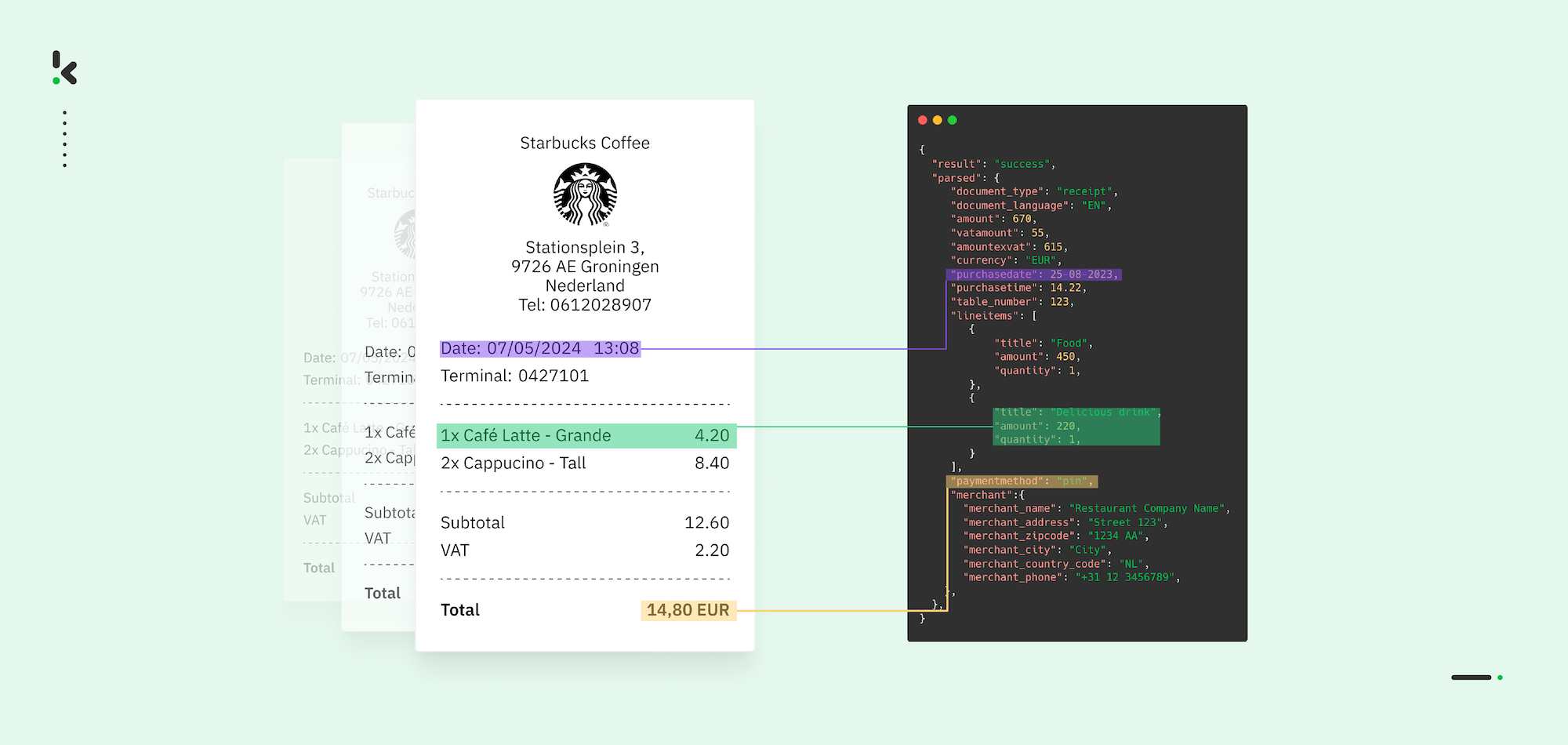
Wer regelmäßig mit Geschäftsausgaben, Buchhaltung oder Finanzprozessen zu tun hat, kennt den Aufwand bei der Quittungsverarbeitung nur zu gut. Papierbelege verlieren mit der Zeit ihre Lesbarkeit, digitale Quittungen verschwinden im Postfach und jedes Format ist anders. Die manuelle Dateneingabe ist nicht nur mühsam, sondern auch fehleranfällig und raubt wertvolle Zeit für wichtigere Aufgaben.
Die Lösung: Automatisierte Systeme erfassen relevante Informationen sofort und garantieren dabei höchste Genauigkeit – ganz ohne manuelle Arbeit. In diesem Leitfaden erfahren Sie, wie Quittungsdatenerfassung funktioniert, welche typischen Herausforderungen Unternehmen begegnen und wie KI-basierte Technologien den gesamten Ablauf optimieren können.
Legen wir los.
Das Wichtigste auf einen Blick
Die automatisierte Quittungsdatenerfassung wandelt unstrukturierte Textinhalte aus Belegen in strukturierte, maschinenlesbare Informationen um – ideal für Buchhaltung, Compliance und Datenanalysen. Der typische Arbeitsprozess besteht aus fünf Schritten:
- Erfassung: Papierquittung scannen oder fotografieren, digitale PDFs oder Bilder hochladen.
- Umwandlung: Mithilfe von OCR den Belegtext auslesen und digital verfügbar machen.
- Datenextraktion: Wichtige Felder wie Händlername, Datum, Beträge, Steuern, Rabatte und Positionen erfassen.
- Datenstrukturierung: Informationen in ein Format wie JSON, CSV, XML oder XLSX übertragen, um sie in andere Systeme einzubinden.
- Validierung: Regelbasierte Prüfungen oder Human‑in‑the‑Loop einsetzen, um Datenqualität zu sichern und Betrugsversuche zu erkennen.
Moderne Lösungen wie Doxis AI.dp kombinieren OCR mit KI‑ und Machine‑Learning‑Technologien, um verschiedenste Belegformate zu verarbeiten, die Genauigkeit zu steigern und sich reibungslos in ERP‑ oder Buchhaltungssysteme zu integrieren.
Was ist Quittungsdatenerfassung?
Früher mussten Mitarbeitende diese Informationen mühsam manuell in Excel‑Tabellen oder Buchhaltungsprogramme übernehmen. Heute übernehmen KI‑gestützte OCR‑Systeme diesen Prozess vollautomatisch: Sie scannen Belege, korrigieren Lesefehler und extrahieren die relevanten Werte. Anschließend werden die Daten in ein festes Format gebracht und nahtlos in Finanz‑, Ausgaben‑ oder Steuersysteme eingespielt.
Methoden zur Erfassung von Quittungsdaten
Firmen können Belegdaten manuell, teilautomatisiert oder vollständig automatisiert auslesen. Die optimale Methode richtet sich nach dem Belegvolumen, der Formatvielfalt, den Genauigkeitsanforderungen und den verfügbaren Ressourcen.
Manuelle Dateneingabe
Hierbei tragen Mitarbeitende alle relevanten Quittungsinformationen – etwa Händlername, Datum, Gesamtbetrag und Steuer – manuell in Excel, Datenbanken oder Buchhaltungssoftware ein.
Vorteile:
- Kein technischer Aufwand oder Implementierung notwendig
- Kostengünstig bei sehr wenigen Quittungen
Nachteile:
- Sehr zeitintensiv bei größeren Mengen
- Erhöhtes Risiko menschlicher Fehler mit möglichen Auswirkungen auf Berichte und Compliance
- Nicht skalierbar für wachsende Unternehmen
Best‑Practice: Manuelle Eingabe eignet sich nur für seltene Einzelfälle oder als Backup‑Option, wenn automatisierte Systeme einen Beleg nicht erkennen.
Vorlagenbasierte OCR
Bei der vorlagenbasierten OCR werden Belege anhand vordefinierter Layouts ausgelesen. Das System erkennt das Bild, ordnet es einer gespeicherten Vorlage zu und entnimmt die relevanten Daten aus exakt festgelegten Positionen im Dokument.
Vorteile:
- Präzise Ergebnisse bei klar standardisierten Belegformaten
- Deutlich schneller als manuelle Erfassung bei einheitlichem Aufbau
Nachteile:
- Ungeeignet für stark variierende oder unbekannte Layouts
- Erfordert Anpassungen oder neue Vorlagen bei Designänderungen
- Probleme bei Handschrift oder minderwertigen Scans
Best‑Practice: Besonders empfehlenswert für Unternehmen mit ein bis zwei festen Belegformaten, z. B. aus unternehmensinternen Kassensystemen..
KI‑basierte OCR mit Machine Learning & NLP
Diese fortschrittliche Methode kombiniert klassische Texterkennung (OCR) mit maschinellem Lernen und Sprachverarbeitung (Natural Language Processing). Sie erkennt, klassifiziert und interpretiert Quittungsdaten zuverlässig – unabhängig von Format, Sprache oder Währung.
Vorteile:
- Flexibel einsetzbar bei vielfältigen Beleglayouts, Schriftarten und Sprachen
- Verarbeitet selbst minderwertige Bilddateien dank intelligenter Vorbearbeitung (z. B. Zuschnitt, Ausrichtungskorrektur, Kontrastoptimierung)
- Felder werden automatisch erkannt und eingeordnet – ganz ohne feste Vorlagen
Nachteile:
- Benötigt Trainingsdaten für maximale Präzision
- Höhere Einstiegskosten im Vergleich zu Standard‑OCR
Best‑Practice: Eine ideale Lösung für Unternehmen mit vielfältigen Belegquellen und uneinheitlichen Designs, besonders im internationalen Umfeld.
Human‑in‑the‑Loop (HITL) Validierung
Bei dieser Methode wird die automatische Datenerfassung durch eine manuelle Qualitätskontrolle ergänzt. Geschulte Mitarbeitende prüfen die Ergebnisse, korrigieren falsche Zuordnungen und bearbeiten komplexe Ausnahmen.
Vorteile:
- Nahezu fehlerfreie Datenerfassung
- Aufdeckung von Betrugsversuchen oder subtilen Abweichungen, die rein automatisierte Systeme übersehen können
- Hohe Flexibilität bei atypischen oder schwer lesbaren Belegen
Nachteile:
- Längere Bearbeitungszeit als rein automatisierte Verfahren
- Fachpersonal wird für die Prüfung benötigt
Best‑Practice: HITL ist besonders empfehlenswert für Prozesse, bei denen Genauigkeit geschäftskritisch ist – beispielsweise bei Steuerprüfungen oder sensiblen Genehmigungsverfahren für Rückerstattungen.
Welche Daten sollten aus Belegen extrahiert werden?
Belege enthalten wichtige Finanz- und Transaktionsdaten, die Unternehmen für die Ausgabenverfolgung, die Einhaltung von Steuervorschriften und die Automatisierung der Buchhaltung benötigen. Nachfolgend sind die wichtigsten Datenpunkte aufgeführt, die aus Belegen extrahiert werden:
1. Transaktionsdetails
Informationen, die den Zeitpunkt und den Ort des Kaufs belegen.
- Datum & Uhrzeit: Exakter Zeitpunkt des Kaufs
- Transaktions-ID: Eindeutige Referenznummer zur Nachverfolgung
- Händlername: Aussteller der Quittung
- Standort: Adresse der Filiale oder des Geschäfts
2. Kaufinformationen
Posten auf der Quittung, die den Kauf im Detail beschreiben.
- Artikelbeschreibung: Detaillierte Liste der gekauften Waren/Dienstleistungen
- Menge: Anzahl pro Artikel
- Stückpreis: Preis je Einheit, exkl. Steuern
- Gesamt pro Artikel: Summe pro Position (Menge × Stückpreis)
3. Kostenübersicht
Zusammenfassung der Preisstruktur der Transaktion.
- Zwischensumme: Gesamtkosten vor Abgaben und Rabatten
- Steuern: MwSt., Umsatzsteuer oder andere Gebühren
- Rabatte/Aktionen: Preisreduzierungen durch Aktionen oder Treueprogramme
- Endbetrag: Tatsächlich gezahlte Summe
- Währung: Verwendete Währungsart
4. Zahlungsinformationen
Angaben zur Art und Weise der Zahlung.
- Zahlungsart: Bar, Karte, Mobile Payment etc.
- Kartendetails: Letzte vier Kartenziffern (falls vorhanden)
- Rückgeld: Ausgezahlter Betrag bei Barzahlung
5. Händlerspezifische Angaben
Informationen, die der internen Nachverfolgung und Markenidentität dienen.
- Belegnummer: Interne Händlerreferenz
- Kassierer-ID: ID des Verkaufsmitarbeiters
- Logo & Markenelemente: Visuelle Wiedererkennung
- Nachrichten: Hinweise wie Rückgaberegeln oder Kundenaktionen
6. Digitale & maschinenlesbare Inhalte
Zusatzinformationen in digitaler oder kodierter Form.
- QR-/Barcodes: Zugriff auf digitale Quittungen oder Produktinfos
- Kategorisierung: Analyse nach Warengruppen (z. B. Lebensmittel, Elektronik)
- Treueprogramm: Gesammelte bzw. eingelöste Punkte
7. Zusätzliche transaktionsbezogene Angaben
Weitere kaufbezogene Informationen je nach Kontext.
- Bestellnummer: Tracking-Referenz im Gastronomie- oder E‑Commerce-Bereich
- Lieferhinweise: Versand- oder Abholinformationen
- Zusatzgebühren & Trinkgeld: Besonders relevant im Gastgewerbe
Herausforderungen bei der automatisierten Quittungsdatenerfassung
Die Verarbeitung von Quittungsdaten wirkt oft simpel, birgt in der Praxis jedoch zahlreiche technische und organisatorische Hürden. Besonders bei vorlagenbasierten oder teilautomatisierten Verfahren stoßen Unternehmen schnell an Grenzen, die Genauigkeit und Effizienz beeinträchtigen. Typische Problemfelder sind:
- Uneinheitliche Formate: Layouts, Schriftarten und Strukturen unterscheiden sich je nach Händler und Standort erheblich. Das erfordert flexible, KI‑gestützte Verarbeitung, um alle Varianten korrekt zu erfassen.
- Vielfalt der Dateitypen: Belege liegen in gedruckter Form, als PDF, in E‑Mail‑Anhängen oder als Foto vor – jede Variante benötigt eine spezielle Extraktionsmethode, um zuverlässige Ergebnisse zu liefern.
- Handschriftliche oder schwer lesbare Texte: Besonders kleinere Händler nutzen noch handgeschriebene Quittungen. Für OCR‑Technologie ist deren korrekte Interpretation deutlich anspruchsvoller als bei klar gedrucktem Text.
- Verblassende oder beschädigte Belege: Thermopapier verliert mit der Zeit an Lesbarkeit. Schlechte Druckqualität oder physische Schäden müssen vor der Datenextraktion durch Bildverbesserung korrigiert werden.
- Uneinheitliche Steuer- und Rabattdarstellung: Unterschiedliche Ausweisungsarten von Steuern, Abgaben und Preisnachlässen erschweren eine konsistente Aufbereitung der Finanzdaten.
- Sprach- und Währungsunterschiede: Bei internationalen Abläufen ändern sich Formate und Schreibweisen. Ohne Lokalisierungsfunktionen besteht die Gefahr von Fehlinterpretationen.
- Störungen bei mobiler Erfassung: Schatten, ungünstige Aufnahmewinkel oder Lichtreflexe in Smartphone‑Fotos mindern die Lesbarkeit und müssen automatisch korrigiert werden.
- Fehlklassifizierungen aufgrund ausbleibender Validierung: Selbst präzise OCR‑Ergebnisse können falsche Feldzuweisungen enthalten, wenn keine systematischen Prüfungen oder Human‑in‑the‑Loop‑Kontrollen etabliert sind.
Um diese Herausforderungen zu meistern, sind hybride Lösungen ideal: KI‑basierte OCR kombiniert mit intelligenter Datenklassifizierung und robusten Validierungs‑Algorithmen. Plattformen wie Doxis AI.dp bündeln diese Technologien und ermöglichen so präzise und effiziente Datenverarbeitung für unterschiedlichste Quittungstypen.across different receipt types. All of these components can be found in IDP platforms like Doxis AI.dp.
Vorteile der automatisierten Quittungsdatenerfassung
Mit Automatisierung werden langsame und fehleranfällige manuelle Prozesse durch schnelle, präzise und sichere Arbeitsabläufe ersetzt. Das bringt Unternehmen in mehreren Bereichen entscheidende Vorteile:
- Zeitersparnis: Große Quittungsmengen lassen sich innerhalb von Sekunden statt Stunden verarbeiten. Das reduziert den Verwaltungsaufwand und gibt Teams mehr Kapazität für wertschöpfende Tätigkeiten.
- Hohe Genauigkeit: KI‑basierte OCR minimiert manuelle Fehler, sodass Finanz- und Buchhaltungsdaten zuverlässig sind und klare Audit‑Trails entstehen.
- Skalierungsfähigkeit: Auch Tausende Belege pro Monat können ohne zusätzliches Personal oder Belastung bestehender Ressourcen bewältigt werden.
- Optimierte Compliance: Steuer- und Zahlungsinformationen werden vollständig erfasst, um Berichts- und Nachweispflichten in unterschiedlichen Rechtsräumen sicher zu erfüllen.
- Kostensenkung: Der Wegfall manueller Datenerfassung und zusätzlicher Prüfschritte verringert die Betriebskosten spürbar.
- Nahtlose Integration: Strukturierte Ausgabeformate wie JSON, CSV, XML oder XLSX ermöglichen den direkten Import in ERP‑, Buchhaltungs- oder Analyseprogramme.
- Schutz vor Betrug: Eingebaute Validierungen und Dublettenerkennung helfen, manipulierte oder doppelt eingereichte Belege schnell zu identifizieren.
Ob mit einer schlanken OCR‑Anwendung oder einer vollumfänglichen IDP‑Plattform wie Doxis AI.dp: Automatisierte Quittungsdatenerfassung steigert Tempo, Präzision und Datenintegrität und senkt zugleich Kosten und Risiken.
So extrahieren Sie Quittungsdaten automatisch mit Doxis
Mit einer KI‑basierten Lösung wie Doxis AI.dp lässt sich der gesamte Prozess der Belegverarbeitung automatisieren: vom Eingang der Datei bis zur strukturierten Buchung in Ihrem System.
Hier unser Beispiel‑Workflow, bei dem wir PDF‑Belege aus Google Drive verarbeiten und die Daten im JSON‑Format ausgeben. Sie können diesen Ablauf kostenlos testen.
Schritt 1: Anmelden und Konto einrichten
Registrieren Sie sich auf der AI.dp‑Plattform mit E‑Mail und Passwort, ergänzen Sie Angaben wie Name, Unternehmen, Einsatzzweck und Belegvolumen.
Sie erhalten automatisch ein Startguthaben von 25 € für Tests der gesamten Plattformfunktionen.
Erstellen Sie eine Organisation und ein Projekt. Aktivieren Sie danach das Financial Model und den Flow Builder, um sofort mit der Quittungsdatenerfassung zu beginnen.
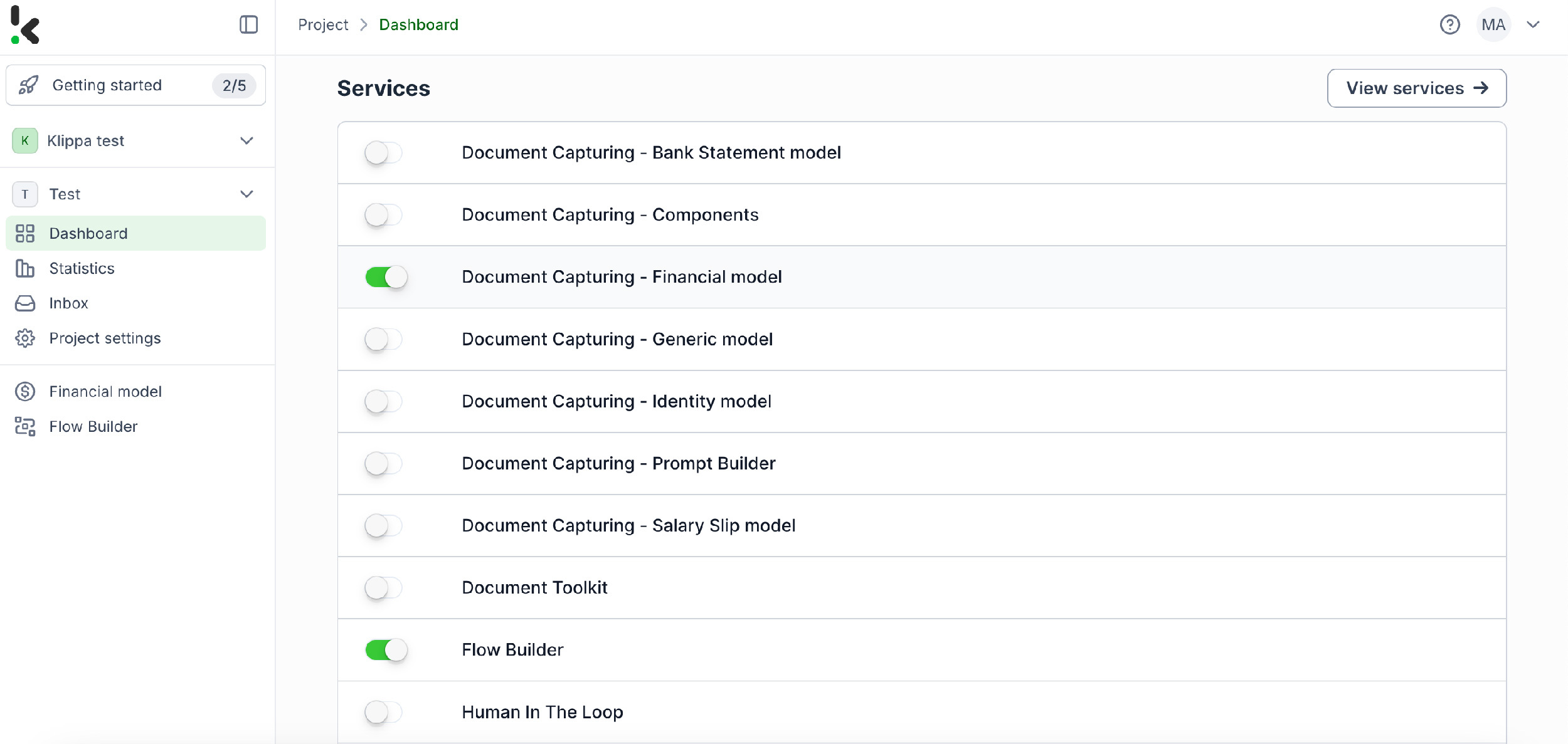
Schritt 2: Voreinstellung anlegen
Wir aktivieren das Financial Model, weil es speziell darauf ausgelegt ist, Finanzarbeitsprozesse zu optimieren: von Extraktion über Analyse und Validierung bis zur Klassifikation von Daten. Es verarbeitet eine breite Palette an Finanzdokumenten wie Quittungen, Rechnungen, Bestellungen oder Kontoauszüge.
Erstellen Sie eine neue Voreinstellung und nennen Sie sie zum Beispiel „Extract Data from Receipts“. Aktivieren Sie die Komponenten für Finanzdaten und Einzelpositionen, damit Felder wie Quittungsnummer, Händler, Datum, Betrag, Währung und MwSt. erkannt werden.
Tipp: Je nach Anwendungsfall können Sie weitere Komponenten wie Datumsangaben, Referenzinformationen oder Zahlungsdetails aktivieren.
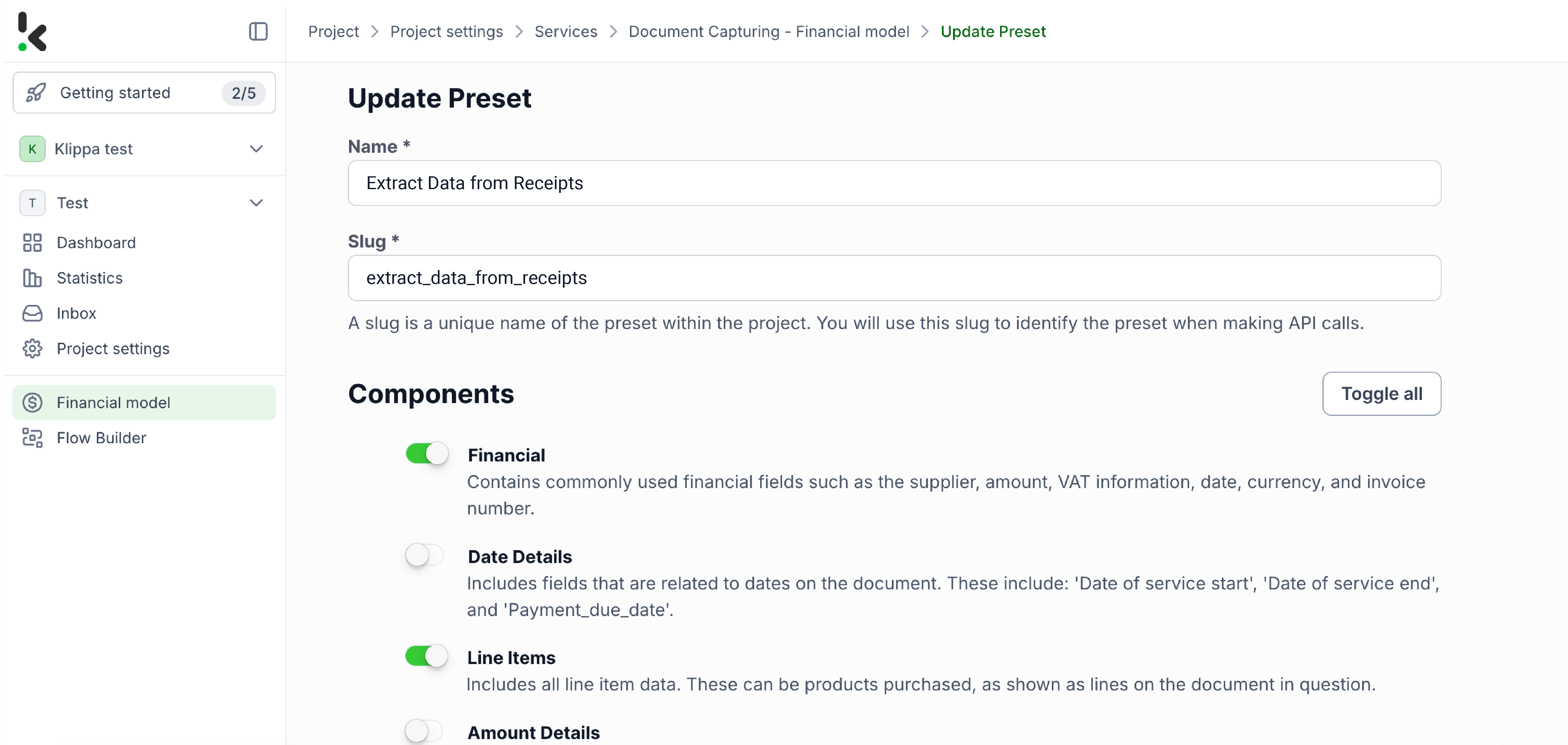
Schritt 3: Eingabequelle auswählen
Nachdem Sie Ihre Voreinstellung konfiguriert und den Flow Builder aktiviert haben, können Sie nun Ihren individuellen Flow aufbauen. Ein Flow definiert Schritt für Schritt, wie Ihre Quittungen verarbeitet und an ihr Zielsystem übergeben werden. In diesem Beispiel nutzen wir Google Drive als Eingabequelle.
Wählen Sie im Menü New Flow → + From scratch und vergeben Sie einen Namen für den Ablauf, zum Beispiel „Receipt Data Extraction“.
Tipp: Legen Sie als Erstes fest, woher die Daten stammen sollen. Sie können Belege direkt von Ihrem Gerät hochladen oder eine Verbindung zu mehr als 100 externen Plattformen herstellen, etwa Dropbox, Outlook, Salesforce, Zapier, OneDrive, die Datenbank Ihres Unternehmens oder Cloud‑Speicher wie Amazon S3 und iCloud. Achten Sie darauf, alle Quittungen in demselben Ordner zu speichern, um sie bei Bedarf gesammelt verarbeiten zu können.
Für dieses Beispiel verwenden wir PDF‑Quittungen. Erstellen Sie einen Ordner „Input“ in Google Drive und laden Sie dort die Belege hoch.
Wählen Sie daraufhin „Google Drive“ als Quelle und „New File“ als Auslöser für den Prozess. Damit starten Sie den Flow. Auf der rechten Seite tragen Sie anschließend folgende Informationen ein:
- Connection: Vergeben Sie einen aussagekräftigen Namen für die Verbindung, etwa „google‑drive“. Nach der Benennung werden Sie vom System aufgefordert, Ihr Google‑Konto zu authentifizieren.
- Parent Folder: Input
- Include File Content: Aktivieren Sie diese Option, damit der Inhalt der Datei verarbeitet wird.
Testen Sie den Schritt mit Load Sample Data. Legen Sie während der Konfiguration unbedingt mindestens eine Beispielquittung in den Eingabeordner, um die Funktion zu überprüfen.
Tipp: Die Plattform unterstützt zahlreiche Dokumenttypen für unterschiedlichste geschäftliche Anforderungen. Weitere Einzelheiten finden Sie in der ausführlichen Dokumentation.
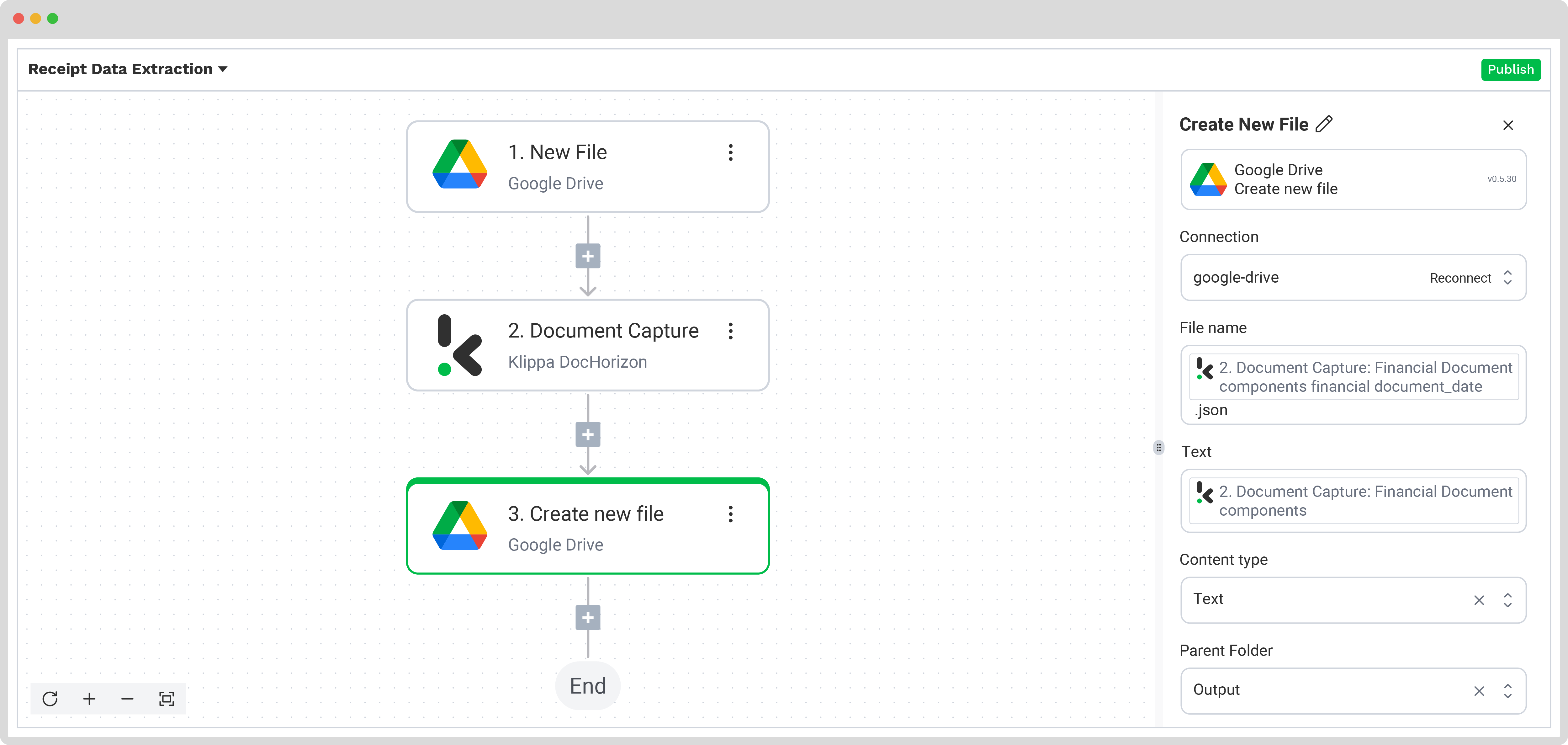
Schritt 4: Daten erfassen und auslesen
In diesem Schritt extrahieren Sie die benötigten Informationen aus Ihren Quittungen. Nutzen Sie dafür die zuvor angelegte Voreinstellung, um alle definierten Felder aus den Belegen im Eingabeordner zu verarbeiten.
Öffnen Sie im Flow Builder das Menü über den +‑Button und wählen Sie Document Capture: Financial Document.
Richten Sie den Verarbeitungsschritt folgendermaßen ein:
- Connection: Default AI.dp Platform
- Preset: Tragen Sie den Namen Ihrer Voreinstellung ein, beispielsweise „extract_data_from_receipts“
- File or URL: New file → Content
Führen Sie anschließend einen Testlauf durch, um zu prüfen, ob sämtliche gewünschten Felder korrekt ausgelesen werden. Ist dieser Test erfolgreich, können Sie direkt zum nächsten Schritt übergehen: dem Speichern der Ergebnisse.
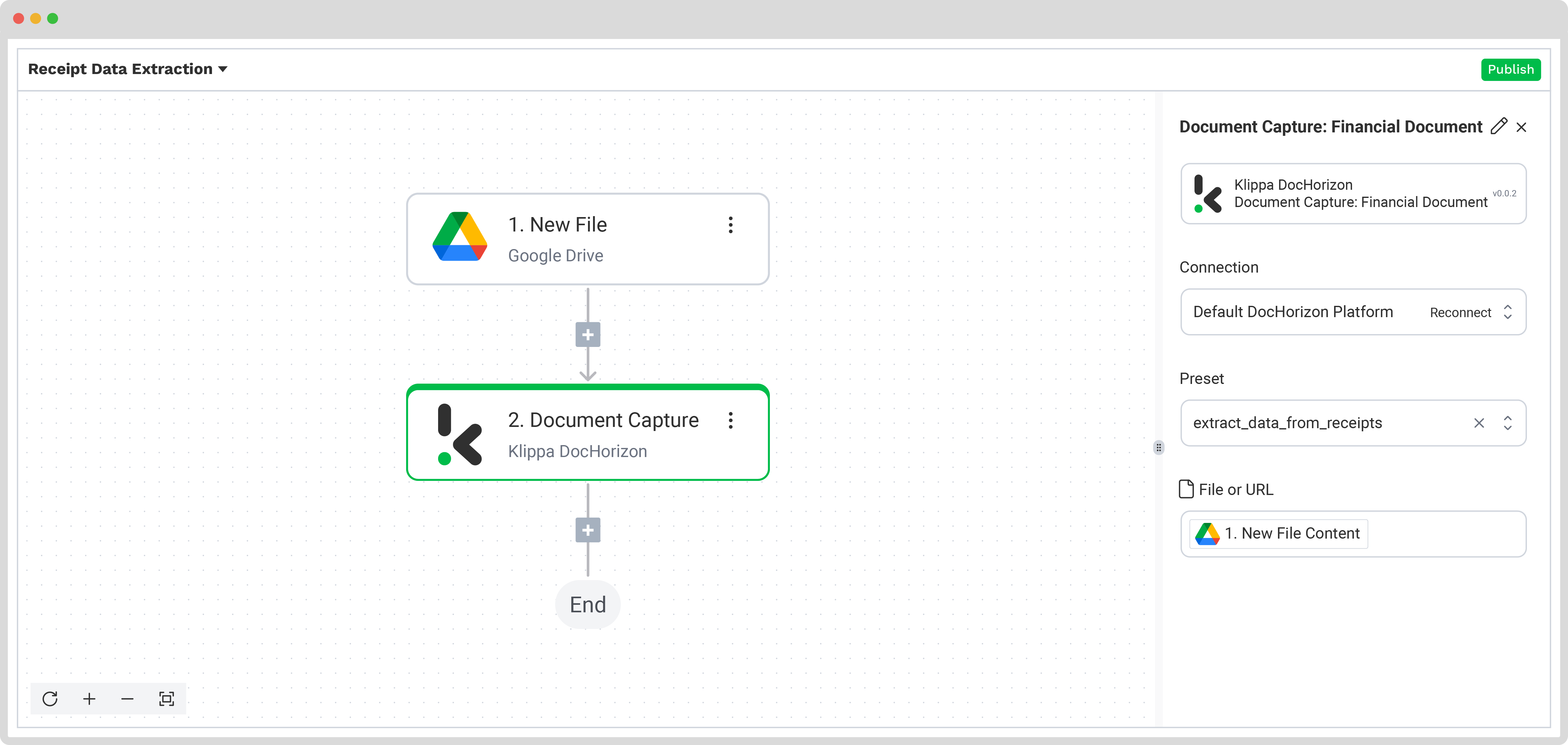
Schritt 5: Datei erzeugen und speichern
Nachdem die Quittung erfolgreich verarbeitet wurde, legen Sie im letzten Schritt fest, wohin die Daten exportiert werden und in welchem Format. Zielsysteme können beispielsweise eine Datenbank, ein ERP‑System, Buchhaltungssoftware oder eine andere Plattform sein – je nach Ihrem individuellen Workflow.
Für die Ausgabe stehen Formate wie JSON, XML, CSV, XLSX, UBL, PDF oder TXT zur Verfügung.
In unserem Beispiel speichern wir die Daten im JSON‑Format und verwenden die Quittungsnummer als Dateinamen. Im Google Drive richten wir dazu einen neuen Ordner „Output“ ein, der als endgültiger Speicherort dient.
Fügen Sie im Flow den Schritt über den +‑Button hinzu und wählen Sie Create new file → Google Drive.
Konfigurieren Sie den Speicherschritt wie folgt:
- Connection: google‑drive
- File Name: Wählen Sie im Pfad Document Capture: Financial Document → components → financial → receipt_number und ergänzen Sie .json
- Text: Document Capture: Financial Document → components, um sämtliche extrahierten Daten zu übernehmen
Tipp: Achten Sie darauf, bewusst alle Textbestandteile zu wählen, die im neuen Dokument enthalten sein sollen. Mit der Option „components“ übernehmen Sie den vollständigen Datensatz.
- Content Type: Text
- Parent Folder: Output
Führen Sie zum Abschluss einen Testlauf über die Schaltfläche unten rechts durch. Wenn dieser erfolgreich ist, ist Ihr Flow bereit und sämtliche neuen Quittungen im Eingabeordner werden automatisch verarbeitet und gespeichert.
Herzlichen Glückwunsch. Alle Quittungsdaten sind jetzt in Ihrem Google Drive Ordner verfügbar. Mit dieser Einrichtung können Sie den Flow veröffentlichen. Jede neue Quittung, die Sie in den Ordner hochladen, wird automatisch verarbeitet. Auf diese Weise sparen Sie Zeit und stellen gleichzeitig die Genauigkeit in Ihren Arbeitsprozessen sicher.
Neben Quittungen verarbeiten Sie möglicherweise auch Rechnungen. Falls dies der Fall ist, sollten Sie unbedingt unseren Leitfaden zur Rechnungsextraktion lesen.
Bedenken Sie, dass Sie nicht alles selbst erledigen müssen. Wenn Sie große Dokumentenmengen verarbeiten oder einen speziellen Anwendungsfall haben, setzen Sie sich gerne mit uns in Verbindung. Wir würden uns freuen, Ihre Geschichte zu erfahren.
Typische Einsatzgebiete für automatisierte Quittungsdatenerfassung
Die automatisierte Verarbeitung von Quittungsdaten ermöglicht schnellere Abläufe, genauere Ergebnisse und bessere Einhaltung von Vorschriften in zahlreichen Geschäftsprozessen. Wichtige Einsatzbereiche sind:
Spesenabrechnung
Quittungsinformationen werden automatisch erfasst und direkt mit den Spesenabrechnungen von Mitarbeitenden verknüpft. Dadurch entfallen manuelle Eingaben und die Genauigkeit bei Erstattungen steigt deutlich.
Steuerreporting und Compliance
Details zu Mehrwertsteuer, GST oder Umsatzsteuer werden automatisch extrahiert. Dies sorgt für korrekte Berichte, erleichtert Prüfungen und reduziert das Risiko von Verstößen. Die automatische Kategorisierung verschlankt die Jahresabschlussarbeiten.
Mitarbeiterkostenerstattung
Genehmigungsprozesse werden beschleunigt, indem Beleginformationen geprüft, mit Unternehmensrichtlinien abgeglichen und Erstattungen schneller freigegeben werden.
Erkennung von Betrug
Doppelte, manipulierte oder gefälschte Belege werden mit Validierungsprüfungen und Bild‑Hashing erkannt. So lassen sich überhöhte Forderungen und finanzielle Verluste verhindern.
Analysen im Handel und FMCG‑Bereich
Detaillierte Belegdaten werden ausgewertet, um Verkaufszahlen, Kundenverhalten und die Leistung einzelner Warengruppen zu analysieren. Diese Daten unterstützen Treueprogramme und helfen bei der Bewertung von Marketingkampagnen.
Versicherungsleistungen
Der Kaufnachweis wird automatisch validiert. Das verkürzt Bearbeitungszeiten und senkt die Gefahr unrechtmäßiger Auszahlungen.
Fördermittel- und Zuschussverwaltung
Alle förderfähigen Ausgaben werden lückenlos dokumentiert, um Transparenz zu garantieren und die Einhaltung der Förderbedingungen sicherzustellen.
Automatisieren Sie die Quittungsdatenerfassung mit Doxis AI.dp
Möchten Sie Daten aus Ihren Quittungen in Google Sheets, Excel, JSON und anderen Formaten extrahieren? Wir haben die passende Lösung. Mit Doxis AI.dp können Sie ganz einfach alle Ihre Arbeitsprozesse automatisieren:
Datenerfassung mittels OCR: Automatisches Auslesen von Daten aus beliebigen Quittungen.
Auslagerung für Treueprogramme: Automatisches Verarbeiten und Abgleichen von Belegen für Bonus- oder Treueprogramme.
Human‑in‑the‑loop: Nahezu 100 % Genauigkeit durch den Einsatz der Human‑in‑the‑loop‑Funktion, die interne Prüfungen oder Unterstützung durch das Datenerfassungsteam von Doxis ermöglicht.
Dokumentkonvertierung: Umwandeln von Dokumenten in beliebigen Formaten, einschließlich PDF, gescannter Bilder oder Word‑Dokumente, in verschiedene für Unternehmen nutzbare Datenformate wie JSON, XLSX, CSV, TXT, XML und andere.
Datenanonymisierung: Schutz sensibler Informationen und Sicherstellung der Einhaltung gesetzlicher Vorgaben durch Anonymisierung personenbezogener oder kontaktbezogener Daten.
Dokumentenprüfung: Automatische Authentifizierung von Dokumenten und Erkennung betrügerischer Aktivitäten zur Verringerung des Betrugsrisikos.
Bei Doxis hat Datenschutz höchste Priorität. Daher entsprechen alle unsere Dokumenten‑Arbeitsprozesse den HIPAA-, GDPR- und ISO‑Standards, um eine sichere Datenverarbeitung zu gewährleisten. Mit der Gewissheit, dass Ihre Daten geschützt sind, können Sie den nächsten Schritt gehen und Ihre Abläufe zur Datenerfassung optimieren.
Wenn Sie daran interessiert sind, Ihren Workflow zur Quittungsdatenerfassung mit der intelligenten Dokumentenverarbeitungslösung von Doxis zu automatisieren, kontaktieren Sie unsere Expertinnen und Experten. processing solution, don’t hesitate to contact our experts for additional information or book a free demo!
FAQ
Nutzen Sie ein OCR‑System, das Belegbilder oder PDFs scannt und den Text in strukturierte Formate wie JSON, CSV oder XML umwandelt. KI‑basierte Lösungen verarbeiten zuverlässig unterschiedliche Layouts, Sprachen und Währungen und erhöhen damit die Genauigkeit.
Quittungs‑OCR liest den Text aus gescannten oder fotografierten Belegen und überträgt ihn in maschinenlesbare Felder wie Händlername, Datum, Summe und Steuer. Damit entfällt die manuelle Eingabe in Buchhaltungs‑ oder Ausgabenmanagement‑Systeme.
Die Präzision hängt von Bildqualität, Format und verwendetem Modell ab. Moderne Lösungen mit OCR, Machine Learning und Natural Language Processing erreichen über 90 % Genauigkeit und kommen mit Human‑in‑the‑Loop‑Prüfung nahezu an perfekte Ergebnisse heran.
Ja. Fortschrittliche Systeme erkennen und verarbeiten mehrsprachige Quittungen und unterschiedliche Währungen innerhalb eines Workflows, passen sich automatisch an Formate, Steuerbegriffe und Zahlenregeln an.
Zu den wichtigsten Anwendungen zählen Spesenabrechnung, Steuerreporting, Kostenerstattung, Betrugserkennung, Handels‑ und FMCG‑Analysen, Versicherungsfälle sowie Fördermittelverwaltung. Diese Prozesse profitieren von schneller Verarbeitung, hoher Genauigkeit und Compliance‑gerechten Daten.
Nutzen Sie möglichst klare Aufnahmen mit hoher Auflösung. Achten Sie darauf, Schatten, Knicke und Spiegelungen zu vermeiden. Setzen Sie Tools ein, die über Bildvorbearbeitung verfügen und durch Validierungsregeln die korrekte Erfassung der Felder sicherstellen.
Wählen Sie eine Lösung, die geltende Datenschutzgesetze wie GDPR oder HIPAA erfüllt, Daten verschlüsselt, in sicheren Cloud‑Umgebungen verarbeitet und sensible Informationen anonymisiert.
Ja. Mit der kostenlosen Testversion und 25 € Startguthaben können Sie Quittungs‑Workflows erproben, Integrationen testen und die Genauigkeit vor dem Rollout prüfen.
Doxis AI.dp kombiniert OCR mit Künstlicher Intelligenz, fortschrittlicher Klassifizierung, Betrugserkennung, Compliance‑Features und flexiblen Integrationsmöglichkeiten. Damit eignet sich die Lösung für große, vielfältige und internationale Belegprozesse mit hohen Anforderungen an Geschwindigkeit und Genauigkeit.
Unterstützt werden JSON, CSV, XML, XLSX, PDF/A, TXT und weitere. Diese lassen sich direkt in ERP‑, Buchhaltungs‑ oder Analyse‑Systeme integrieren.