In vielen Unternehmen und öffentlichen Behörden wurden die eingehenden Dokumente früher von der Verwaltung oder dem Sekretariat bearbeitet. Diese Dokumente reichten von Steuerbescheiden und Bußgeldern bis hin zu Rechnungen und Kundenserviceanliegen. Jedes dieser Dokumente musste an die entsprechende Abteilung weitergeleitet werden. Schließlich wurden sie manuell bearbeitet und landeten in einem großen Archiv.
Da die meisten dieser Unternehmen ihre Systeme in den letzten zehn Jahren digitalisiert haben, wird der Umfang der eingehenden Papierdokumente von Jahr zu Jahr geringer. Viele Organisationen haben bereits auf digitale Poststellen, Aktenverwaltungssysteme und Archive umgestellt und erhalten die meisten Dokumente per E-Mail. Einige arbeiten mit großen Scannern, um den verbleibenden Teil des Prozesses zu digitalisieren.
Der Eingang und die Konvertierung von Dokumenten in ein digitales Format ist jedoch nur der erste Schritt zur Reduzierung von Fehlerquellen und zur Steigerung der Betriebseffizienz. Die Klassifizierung, das Sortieren und Weiterleiten von Dokumenten an die richtige Abteilung und die Gewährleistung, dass die Dokumente in durchsuchbarem Text vorliegen, sind wertvolle nächste Schritte. Mit OCR & Machine Learning können diese Schritte automatisiert werden und in dem Set-Up des Dokumenteingang- und Verarbeitungsprozess implementiert werden.
In diesem Blog zeigen wir Ihnen, wie Sie dies mit unserer Lösung zur Dokumentenklassifizierung umsetzen können.
Kurzübersicht
- Was ist automatische Dokumentenklassifizierung? Eine KI-gestützte Methode zur Erkennung und Sortierung von Dokumenten.
- Wie funktioniert es? OCR und Machine Learning analysieren Inhalte und ordnen Dokumente automatisch den richtigen Kategorien zu.
- Welche Vorteile bietet es? Spart Zeit, reduziert manuelle Fehler und verbessert die Datenorganisation.
- Wo wird es eingesetzt? Ideal für Rechnungen, Verträge, Quittungen, Formulare und viele weitere Dokumententypen.
- Mit Klippa DocHorizon: Eine intelligente Lösung für die präzise und effiziente Dokumentenklassifizierung.
Das Geheimnis liegt in den Algorithmen
Klippa hat Machine-Learning Algorithmen entwickelt, die mit einem Datensatz von mehr als 1 Million Dokumenten trainiert wurden. Die Algorithmen extrahieren viele Merkmale der Dokumente wie beispielsweise Dateiformate, Dateigrößen und Layouts.
Die Software extrahiert den Inhalt von Dokumenten mithilfe von Optical Character Recognition (OCR) und führt Textanalysen und Statistiken mithilfe von Natural Language Processing (NLP) durch, um Themen-Cluster zu bestimmen. Sie identifiziert Muster innerhalb der Datensätze von Dokumenttypen, die es ihr ermöglichen, unbekannte Dokumente einem dieser Sätze zuzuordnen.
Für jedes unbekannte Dokument, das klassifiziert werden muss, werden die Merkmale extrahiert und den Algorithmen zugeführt. Ein Algorithmus ist im Grunde eine mathematische Formel, sodass das Ergebnis eine bestimmte Punktzahl sein wird.
Wir nennen dies eine Ähnlichkeitsbewertung (Similarity Score). Diese Punktzahl wird mit allen Dokumentenkategorien in dem Datensatz verglichen, mit dem das Modell trainiert wurde. Die größte Übereinstimmung zwischen der Dokumentenbewertung und der Kategoriebewertung ist der wahrscheinlichste Kandidat für die Klassifizierung.
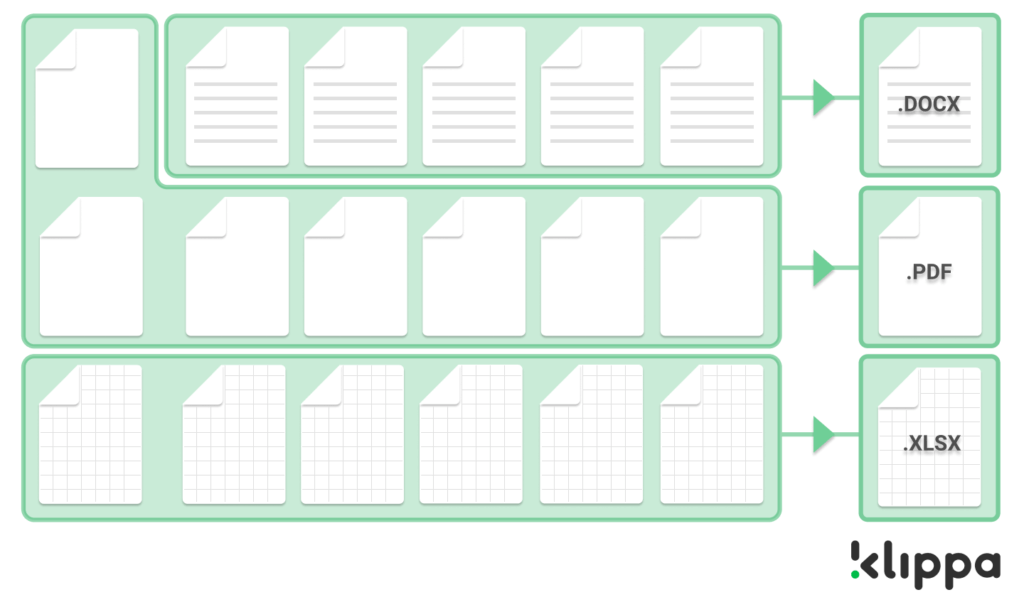
Die nachstehende Abbildung zeigt ein vereinfachtes Beispiel für den Ablauf einer Dokumentenklassifizierung:

Mit der automatischen Klassifizierung von Dokumenten kann eine Genauigkeit von mehr als 99 % erreicht werden, wobei ein einzelner Sortiervorgang etwa eine Zehntelsekunde dauert. Die manuelle Klassifizierung ist viel langsamer, im Durchschnitt nimmt diese einige Sekunden in Anspruch. Abgesehen von der geringeren Geschwindigkeit sind manuelle Klassifizierungen im Allgemeinen nicht genauer als 95 %, abhängig von der Komplexität der Sortieraufgabe.
Verarbeitet ein Unternehmen große Mengen an Dokumenten, z. B. 100.000+ Dokumenten pro Monat, dauert das manuelle Sortieren 20 Mal länger und führt zu 5 % mehr Fehlern. Dies kostet ein großes Unternehmen leicht Tausende von Euro pro Monat, während ein Algorithmus Sie nur einen Bruchteil davon kosten würde.
Klassifizierungen können auf jeglichen Dokumenten durchgeführt werden
Jedes Merkmal, das eine Person identifizieren kann, kann von unserer Software klassifiziert werden, und noch ein bisschen mehr. Die wichtigste Voraussetzung ist, dass genügend Datensätze vorhanden sind, um ein Modell zu trainieren, das die Unterschiede zwischen bestimmten Merkmalen erkennt.
In dieser Hinsicht unterscheiden sich die Machine-Learning-Algorithmen gar nicht so sehr vom Menschen. Sie lernen die Unterschiede zwischen einer Rechnung und einer Zahlungserinnerung durch Erfahrung.
Klippa erledigt folgende Aufgaben:
- Klassifizierung des Dateitypen
- Klassifizierung der Dokumentart
- Klassifizierung der Sprache auf dem Dokument
- Herkunftsland des Eingangsdokuments
- Klassifizierung des Händler/Lieferant
- Klassifizierung der Line Items
- Risiko oder Prioritätsklassifizierung
- Klassifizierung von Datenschutz-sensiblen Daten
Klassifizierung des Dateitypen
Wenn Sie nicht wissen, welche Dateien Sie in Ihrer Poststelle oder Ihrem Archiv haben, besteht der erste Schritt darin, jede einzelne gespeicherte Datei schnell zu identifizieren. Dabei können Sie an Dateitypen wie PDFs, Word-Dokumente, Excel-Tabellen, E-Mails, Bilder, Scans oder jeden anderen Typ denken.
Klassifizierung der Dokumentart
Auch Dokumenttypen können klassifiziert und sortiert werden. Sie können zum Beispiel Rechnungen, Belege, Verträge, Briefe an den Kundendienst, Frachtbriefe, Bestellungen, Lieferscheine, Bankauszüge, Ausweisdokumente, Gehaltsabrechnungen und vieles mehr klassifizieren. Klippa klassifiziert mehr als 30 verschiedene Arten von Dokumenten.
Klassifizierung der Sprache auf dem Dokument
Auch die Sprache der Dokumente kann klassifiziert und sortiert werden. Jedes Dokument kann ein Etikett mit “Englisch”, “Niederländisch”, “Spanisch” oder einer anderen Sprache erhalten. Dies kann sehr nützlich sein, wenn Sie Dokumente in mehreren Sprachen haben und nach einer bestimmten Sprache suchen.
Herkunftsland des Eingangsdokuments
Einige Dokumente, z. B. Versandetiketten oder Reisepässe, enthalten Informationen über das Herkunftsland. Diese können zur Kennzeichnung der Dokumente für Sortierzwecke verwendet werden. Denken Sie an Länderetiketten wie “Niederlande”, “Vereinigtes Königreich” oder Regionenetiketten wie “Europa”.
Klassifizierung von Händler/Lieferant
Händler sind wichtig für die Bearbeitung von Belegen und Rechnungen. Sie können Ihnen Informationen über die Art von Geschäft geben, in dem der Kauf getätigt wurde. Kategorie-Etiketten können verwendet werden, um zu klassifizieren, ob der Kauf in einem Baumarkt, Supermarkt, Elektronikgeschäft oder einer Apotheke getätigt wurde.
Klassifizierung von Line Items
Die Klassifizierung von Einzelpositionen (d. h. Produktkäufe) ist ebenfalls möglich. Mit einem intelligenten Algorithmus, der aus der Analyse von 500.000 Belegen und Rechnungen gelernt hat, kann Klippa Produkte in mehr als 20 Kategorien einordnen, z. B. “Lebensmittel und Getränke”, “Elektronik”, “Alkoholika”, “Transport” und mehr. Dies kann verwendet werden, um die Berechtigung zur Steuerrückerstattung, die Verteilung von Treuepunkten oder Kundenanalysen zu bestimmen.
Risiko oder Prioritätsklassifizierung
Risiko- oder Dringlichkeitsklassifizierungen spielen eine wichtige Rolle, wenn es darum geht, Prioritäten in hohen Volumen an Supportanfragen von Kunden zu setzen. Beschwerdebriefe oder E-Mails von Kunden, die verärgert sind oder rechtliche Schritte einleiten wollen, können als “hohe Priorität” eingestuft werden, während eine Supportanfrage zu einer Funktion als “niedrige Priorität” gilt.
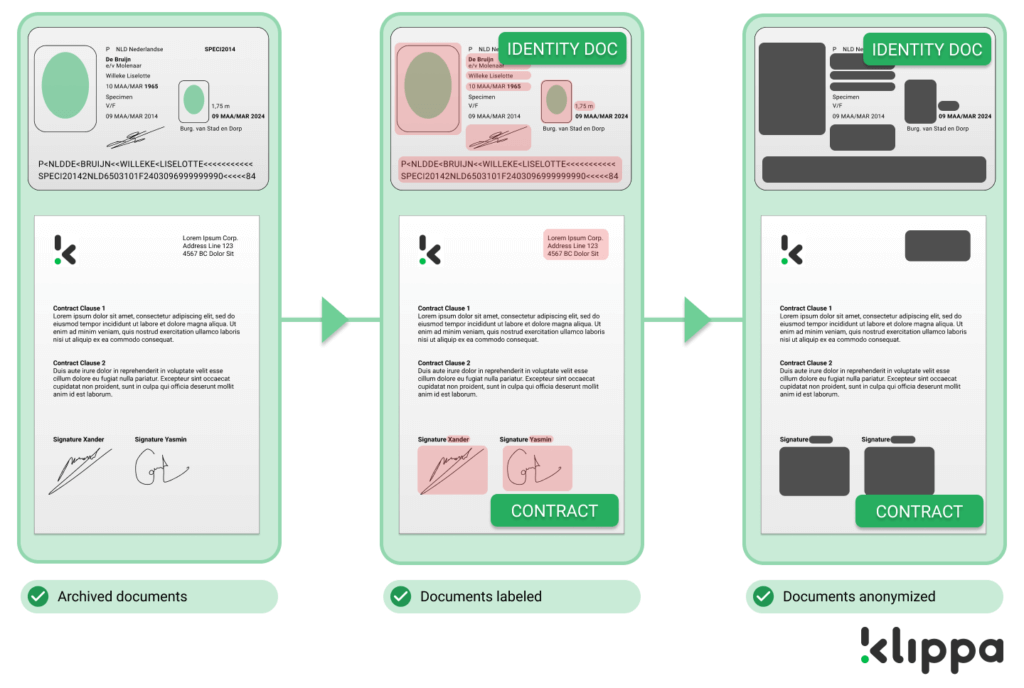
Klassifizierung von Datenschutz-sensiblen Daten
In einigen Branchen ist es wichtig, Dokumente mit sensiblen Daten aufgrund von DSGVO- oder anderen datenschutzrechtlichen Vorschriften zu identifizieren und zu klassifizieren. Denken Sie an Dokumente wie Reisepässe, Personalausweise, Führerscheine, Kreditkarten und Verträge. Die OCR-API von Klippa kann diese Dokumente automatisch für Sie erkennen und kennzeichnen. Es ist sogar möglich, sie automatisch zu anonymisieren, indem bestimmte Zeilen auf einem Dokument entfernt oder geschwärzt werden.
Die Vorteile der Klassifizierung und Sortierung von Dokumenten
Welche Vorteile OCR und KI-basierte Dokumentenklassifizierung für Sie haben, hängt von Ihrer Ausgangssituation ab. Im Allgemeinen lassen sich alle Vorteile auf zwei Aspekte reduzieren:
- Steigerung der Betriebseffizienz → Höhere Geschwindigkeit bei der Dokumentenverarbeitung und geringere Bearbeitungskosten
- Wenn Sie die manuelle Bearbeitung durch eine klassifizierungsbasierte und automatisierte Lösung zur Dokumentklassifizierung und Sortierung ersetzen, können Sie Ihre operativen Kosten um 70 % senken.
Die nächsten Schritte mit Klippa
Wenn Ihr Unternehmen Herausforderungen im Hinblick auf eine effiziente Dokumentenverarbeitung hat, ist Klippa für Sie da. Wir beraten Sie gerne zu Best Practices oder demonstrieren Ihnen wie und ob unsere Software für Ihren Anwendungsfall geeignet ist. Unten finden Sie einen Online-Demo-Planer, der für Sie der nächste Schritt in der digitalen Transformation sein könnte.
Mehr über die Organisierung, Kennzeichnung und Anonymisierung von Archiven können Sie auch in einem unserer anderen Blogs lesen.
FAQ
Durch die Kombination von Optical Character Recognition (OCR) und Machine Learning werden eingehende Dokumente digitalisiert und analysiert. OCR extrahiert den Text aus den Dokumenten, während Machine-Learning-Algorithmen Muster erkennen und die Dokumente basierend auf ihrem Inhalt in vordefinierte Kategorien einordnen.
Die Technologie kann eine Vielzahl von Dokumenten verarbeiten, darunter Rechnungen, Verträge, Bestellungen, Lieferscheine und viele mehr. Sie ist flexibel und kann an die spezifischen Anforderungen verschiedener Branchen angepasst werden.
Unternehmen profitieren von einer erheblichen Zeitersparnis, reduzierten Fehlerquoten und einer effizienteren Dokumentenverwaltung. Die automatische Klassifizierung ermöglicht eine schnellere Verarbeitung und Ablage von Dokumenten, was zu optimierten Arbeitsabläufen führt.
Moderne OCR- und Machine-Learning-Systeme erreichen eine hohe Genauigkeit bei der Dokumentenklassifizierung. Während die manuelle Sortierung anfällig für menschliche Fehler ist, bieten automatisierte Systeme konsistente und zuverlässige Ergebnisse, insbesondere bei großen Dokumentenvolumen.
Ja, die Systeme können individuell konfiguriert werden, um spezifische Klassifizierungskriterien zu berücksichtigen. Unternehmen können eigene Kategorien und Regeln definieren, um sicherzustellen, dass die Dokumente gemäß ihren spezifischen Anforderungen sortiert werden.
Der erste Schritt besteht darin, die aktuellen Dokumentenprozesse zu analysieren und Bereiche zu identifizieren, die von einer Automatisierung profitieren würden. Anschließend kann eine passende OCR- und Machine-Learning-Lösung ausgewählt und implementiert werden. Es ist ratsam, mit einem spezialisierten Anbieter wie Klippa zusammenzuarbeiten, um eine nahtlose Integration und optimale Ergebnisse zu gewährleisten.