
Wir wissen, wie schwierig es für Unternehmen sein kann, eine große Anzahl von Dokumenten zu verarbeiten, von Quittungen über Rechnungen bis hin zu anderen internen Dokumenten. Die manuelle Verarbeitung dieser Dokumente ist anfällig für Fehler bei der Datenextraktion und für Dokumentenbetrug. Laut einer Gartner-Studie belaufen sich die jährlichen Kosten für menschliche Fehler bei der Dateneingabe auf fast 1 Million US-Dollar.
Aus diesem Grund hat sich die KI-gestützte OCR-Technologie (Optical Character Recognition) für viele Unternehmen, die mit der Datenextraktion aus Dokumenten wie Quittungen, Rechnungen oder Bestellungen befasst sind, zu einem entscheidenden Faktor entwickelt. Die Verwendung von OCR für die Extraktion und Erkennung von Einzelposten und Belegzeilen bietet einen rationalisierten Ansatz für die Verarbeitung großer Datenmengen in einer Reihe von Branchen wie dem Finanzsektor, dem Einzelhandel und anderen.
In diesem Blog erfahren Sie mehr über die Einzelheiten der Extraktion und Erkennung von einzelnen Belegzeilen und wie Sie mit Klippa Einzelpostendaten aus Quittungen oder Rechnungen extrahieren können
Kurzübersicht
- Zeilenweise Datenextraktion: Erfasst gezielt relevante Informationen aus Dokumenten, ohne unnötige Daten mitzunehmen.
- Automatisierte Verarbeitung: KI-gestützte Systeme erkennen und extrahieren Daten aus Rechnungen, Quittungen & Co.
- Präzise & effizient: Reduziert manuelle Fehler, spart Zeit und verbessert die Datenqualität.
- Vielseitig einsetzbar: Funktioniert in verschiedenen Branchen, von Finanzwesen bis Gesundheitssektor.
- Mit Klippa DocHorizon: Eine leistungsstarke Lösung zur intelligenten und regelkonformen Zeilenextraktion.
Warum ist die Erkennung & Verarbeitung von einzelnen Belegzeilen für Unternehmen nützlich?
Da die Welt immer weiter zu der Automatisierung und KI vordringt, gibt es immer mehr Gründe für Unternehmen, sich zu fragen, wie Automatisierung ihnen helfen kann. Aber wie genau können Unternehmen OCR für die Extraktion von Einzelposten nutzen? Hier sind einige Einsatzbeispiele, um zu untersuchen, wie dies geschehen kann.
Anwendungsfälle
Es gibt unterschiedliche Anwendungsmöglichkeiten für die Extraktion und Verarbeitung von Beleg- und Rechnungspositionen. Hier sind jedoch einige der Anwendungsfälle, auf die wir häufig stoßen:
- Automatisierung der Kreditorenbuchhaltung: Die Erkennung von Einzelposten vereinfacht die Extraktion von Produktdetails, Mengen und Preisen, um die Prozesse der Kreditoren- und Debitorenbuchhaltung zu beschleunigen.
- Automatisierte Spesenabrechnung: Unternehmen können das Spesenmanagement automatisieren, indem sie die manuelle Eingabe reduzieren und die Genauigkeit der Rückerstattung mit OCR für die Datenextraktion von Belegzeilen sicherstellen.
- Beschaffungs- und Lieferantenmanagement: Die Extraktion von Einzelposten kann zur Rationalisierung der Datenextraktion verwendet werden, um die Effizienz der Auftragsverfolgung, der Verwaltung von Lieferanten und der Einhaltung von Vorschriften zu verbessern. Rechnungen oder Bestellungen können für eine schnelle Extraktion und Verarbeitung gescannt werden.
- Scannen von Quittungen für Kundenbindungsprogramme: Die Extraktion von Einzelposten kann verwendet werden, um Artikel zu identifizieren, die von Kunden, die an Treueprogrammen teilnehmen, häufig gekauft werden. Diese Informationen können Unternehmen dabei helfen, Treueprämien und -angebote auf individuelle Kundenpräferenzen abzustimmen und so die Kundenbindung und -bindung zu verbessern.
- Belegabrechnung für Treuekampagnen: Die Extraktion von Belegzeilen kann von Unternehmen genutzt werden, die Treuekampagnen durchführen, bei denen die Kunden Quittungen einreichen müssen, um Prämien oder Punkte zu erhalten. Die Erkennung von Einzelposten ermöglicht eine automatische Quittungsvalidierung, die sicherstellt, dass Kunden ihre Einkäufe korrekt gutgeschrieben werden.
Wie funktioniert die Zeilenextraktion mit OCR?
Die OCR-Technologie ist ein leistungsfähiges Werkzeug, das die Qualität eines gescannten Textes oder Bildes verbessert und mehrere Schritte zur Extraktion der erfassten Daten durchführt. Bei der Extraktion von einzelnen Zeilen oder Posten ermöglicht die OCR-Software das Scannen von Quittungen und Rechnungen, wodurch die manuelle Extraktion einzelner Posten überflüssig wird. Auf diese Weise können Sie die Genauigkeit besser gewährleisten, Betrug verhindern und Zeit sparen.
Es gibt 2 Hauptansätze für OCR: OCR mit Vorlagen und OCR basierend auf KI, die sich in ihrer Fähigkeit unterscheiden, Einzelposten effizient zu extrahieren und zu verarbeiten. Die Vorlagen-OCR basiert auf vorgegebenen Vorlagen. Ein schablonenbasiertes Modell erfordert häufig manuelle Eingriffe, was bei der Bearbeitung verschiedener Dokumentenformate zeitaufwändig und ineffizient sein kann.
Die KI-gestützte OCR von Belegen ist dagegen eine effizientere Lösung für die Extraktion von Einzelposten. KI-basierte OCR nutzt die Lernfähigkeiten, um nicht nur verschiedene Dokumenttypen und Datenfelder zu erkennen, sondern sich auch an unterschiedliche Dokumentenformate anzupassen und von ihnen zu lernen, was sie zur idealen Wahl für Unternehmen macht, die eine automatisierte Extraktion von Belegpositionen wünschen.
Bei der Verarbeitung einer Vielzahl von Rechnungen und Dokumenten von einer noch größeren Anzahl von Lieferanten und Dienstleistern sind Effizienz und Optimierung sehr wichtig. Mit maschinellem Lernen und KI-gestützter OCR wie Klippa DocHorizon kann dies besser erreicht werden.
Sehen wir uns nun an, wie Klippa Einzelposten aus Belegen und Rechnungen extrahiert.
Einzelpostenextraktion aus Belegen
Die Einzelpostenextraktion wird typischerweise von Unternehmen und Organisationen im Einzelhandel und in der Finanzverwaltung verwendet. Als Unternehmen im Bereich der Kundenbindung verlangen Sie beispielsweise von Ihren Kunden, dass sie Quittungen einreichen, um Prämien oder Punkte zu erhalten. Die Einzelposten-Extraktion und -Verarbeitung bietet eine automatische Belegprüfung, die sicherstellt, dass Kunden, die Prämien erhalten, gültige und korrekte Einkäufe tätigen.
Das Verfahren funktioniert folgendermaßen. Für die Verarbeitung benötigen Sie zunächst ein Foto oder eine Kopie des Belegs. Sobald Sie ein Foto einer Quittung haben, können Sie diese per Handy, Web, FTP oder sogar per E-Mail in die OCR-API hochladen. Sobald die OCR-Technologie von Klippa die Quittung erhalten hat, beginnt sie mit der Mustererkennung und Layoutanalyse und erkennt, dass es sich bei dem Bild um eine Quittung handelt. Anschließend identifiziert und extrahiert die OCR-Software von Klippa den Text aus verschiedenen Abschnitten der Quittung, einschließlich der einzelnen Positionen, Daten und Händlerinformationen.
Anschließend werden die einzelnen Positionen des Bons getrennt, einschließlich Produktnamen, Mengen, Preise und Gesamtbeträge. Die extrahierten Daten werden mithilfe von Algorithmen für maschinelles Lernen in ein maschinenlesbares Format wie JSON, CSV, XML usw. umgewandelt. Diese werden dann als Ausgabe von der API zurückgegeben, um den Bon in Ihrer Datenbank oder in Ihrem bestehenden Softwaresystem einfach zu verarbeiten.
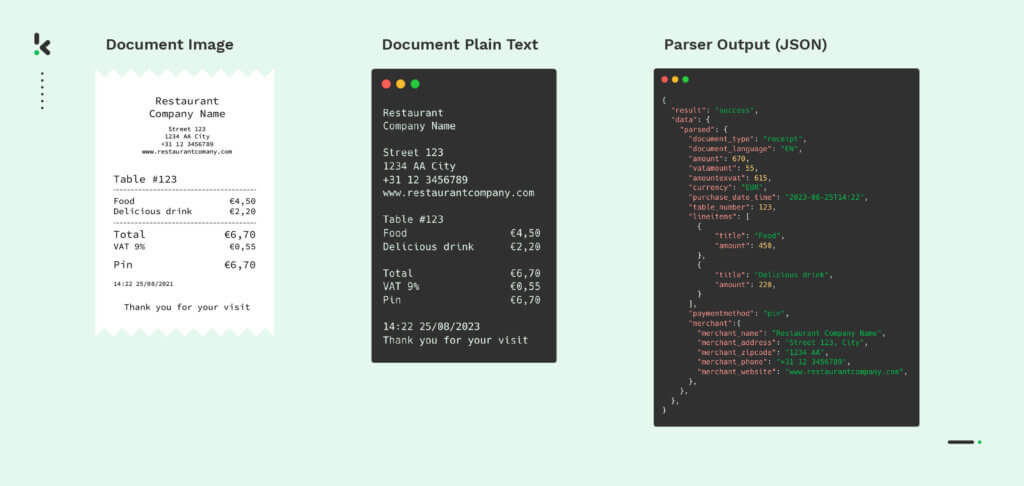
Die strukturierten Daten stehen dann für Datenanalysen, Loyalität, Ausgabenmanagement und Buchhaltung zur Verfügung. Mit diesen Schritten ist der Prozess der Einzelpostenextraktion und -verarbeitung schneller, effizienter und weniger fehleranfällig als die manuelle Alternative.
Extraktion von Rechnungszeilen
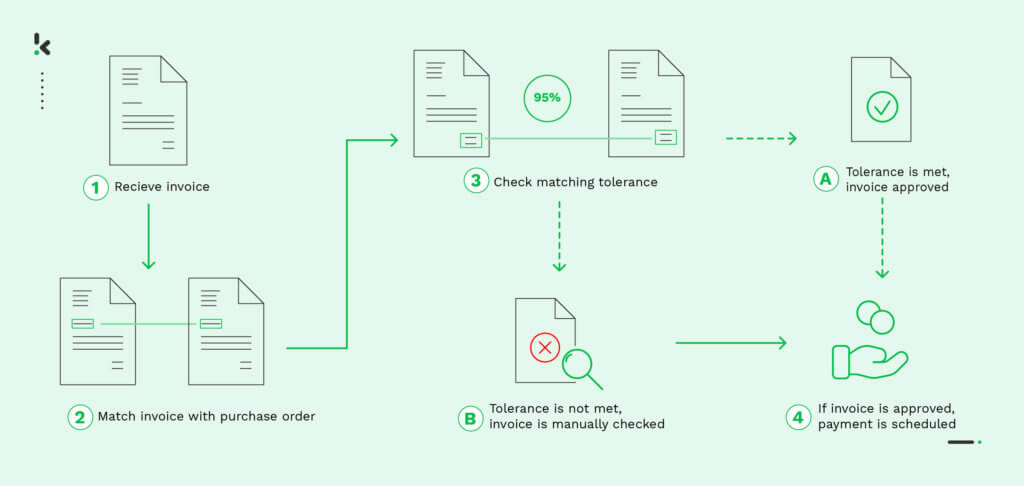
Der Finanzsektor und Fachleute profitieren am meisten von der Extraktion von Rechnungspositionen. Die genaue Extraktion von Rechnungspositionen ist beispielsweise für die Nachverfolgung von Ausgaben, die Validierung von Rechnungen und die Verwaltung von Kreditoren- und Debitorenbuchhaltung unerlässlich. Durch die Automatisierung dieses Vorgangs können Sie den Prozess effizienter gestalten, sind weniger auf menschliche Eingriffe angewiesen und können Ihr Unternehmen vor Betrug schützen.
Die gute Nachricht ist, dass der Prozess des Scannens und Extrahierens dem des Scannens von Belegen sehr ähnlich ist. Nach dem Scannen wird das Bild oder Dokument gescannt und als Rechnung identifiziert. Nachdem die OCR-API das Dokument gescannt hat, werden die relevanten Informationen wie Firmennamen, Beträge, Telefonnummern und Mehrwertsteuerwerte hervorgehoben und extrahiert.
Diese Details werden extrahiert und in ein maschinenlesbares Format wie JSON, CSV, XML usw. umgewandelt, damit Sie fortfahren können. In diesem Stadium können Sie die Rechnungen problemlos bearbeiten, um sie beispielsweise durch einen Zwei-Wege-Abgleich auf Dokumentenbetrug zu prüfen. Klippa DocHorizon ist beispielsweise mit einer OCR-Technologie ausgestattet, die es ermöglicht, diese und weitere Aufgaben zu erfüllen.
Diese Technologien sparen nicht nur Zeit, sondern verbessern auch die Genauigkeit erheblich, was sie für Unternehmen, die verschiedene Lieferantenrechnungen verwalten, unverzichtbar macht.
Die Vorteile der automatisierten Einzelpostenverarbeitung
Nachdem wir Ihnen den Prozess der Einzelpostenextraktion und seine Funktionsweise erläutert haben, wollen wir nun die Vorteile der Automatisierung der Einzelpostenverarbeitung erläutern.
- Genauigkeit: Durch die automatische Extraktion und Erkennung werden Fehler bei der manuellen Dateneingabe reduziert, was zu präziseren und zuverlässigeren Daten führt.
- Zeiteffizienz: Sparen Sie Zeit und Ressourcen, indem Sie die Extraktion von Positionen aus Dokumenten automatisieren, sodass sich die Mitarbeiter auf wertschöpfende Aufgaben konzentrieren können.
- Kosteneinsparungen: Senken Sie die mit der manuellen Dateneingabe verbundenen Betriebskosten und verbessern Sie die Gesamteffizienz.
- Zeitersparnis: Sparen Sie Zeit mit der automatisierten Dokumentenverarbeitung, die auf der OCR-Technologie von Klippa basiert, und eliminieren Sie die manuelle Eingabe und Verarbeitung von Dokumenten.
- Skalierbarkeit: Einfache Skalierung je nach Geschäftsanforderungen ohne zusätzlichen Personalbedarf.
- Verbessertes Kundenerlebnis: Schnellere und präzisere Antworten auf Kundenanfragen und -wünsche.
Nahtlose Extraktion von Belegzeilen mit Klippa DocHorizon
Ganz gleich, ob Sie Ihr Spesenmanagement, die Rechnungsverarbeitung, die Kreditorenbuchhaltung oder die Belegvalidierung für Kundenbindungskampagnen automatisieren möchten, Klippa DocHorizon hat die Lösung für Sie. DocHorizon ist eine intelligente Dokumentenverarbeitungslösung (IDP), die die Leistungsfähigkeit von OCR und verschiedenen KI-Technologien nutzt, um eine breite Palette von Dokumenten zu verarbeiten.
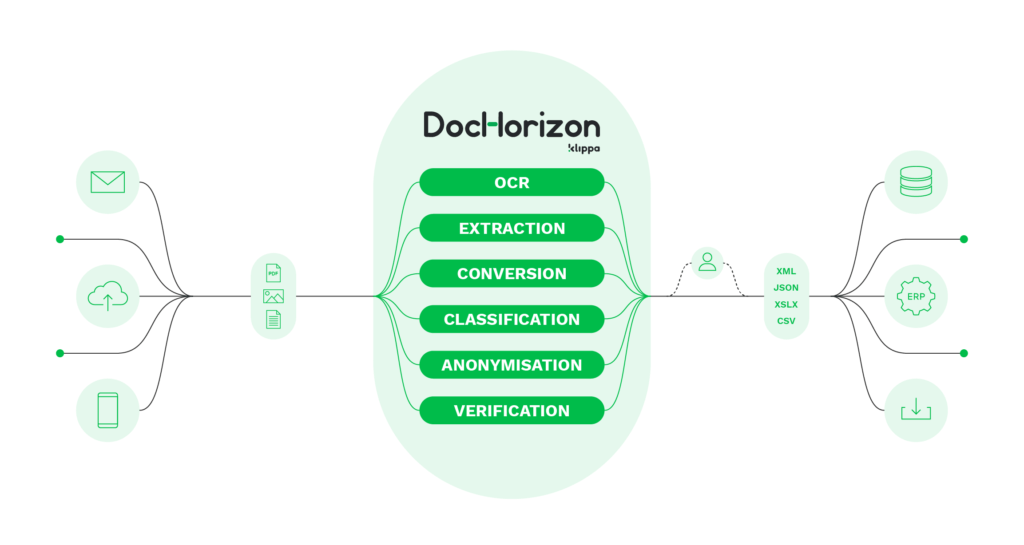
Hier sind die Vorteile der Verwendung von DocHorizon:
- Mehrsprachige Verarbeitung: Klippa DocHorizon ist in der Lage, Dokumente in allen lateinischen Sprachen zu verarbeiten. Dies gewährleistet Flexibilität und Zugänglichkeit und macht es zu einer idealen Wahl für Unternehmen mit unterschiedlichen sprachlichen Anforderungen.
- Genauigkeit und Effizienz: Die fortschrittliche OCR-Technologie von DocHorizon gewährleistet Genauigkeit bei der Zeilenextraktion und Dokumentenverarbeitung. Sie minimiert Fehler, spart Zeit und verbessert die Gesamteffizienz.
- Automatisieren Sie den Workflow der Dokumentenverarbeitung: Mit der DocHorizon-Plattform können Sie ganz einfach Workflows einrichten und dokumentenbezogene Geschäftsprozesse automatisieren.
- Optimierte Integration: Integrieren Sie DocHorizon nahtlos in Ihre bestehenden Systeme, Datenbanken und ERP-Lösungen, um Ihren Workflow zu verbessern und die Vorteile der Automatisierung zu maximieren.
- Erkennung von Betrug: Erkennen Sie Dokumentenbetrug durch EXIF- und Copy-Move-Analyse mit intelligenten KI-Algorithmen.
Klippa DocHorizon bietet nicht nur Automatisierung, sondern sorgt auch für eine effizientere, sicherere und genauere Dokumentenverarbeitung.
FAQ
Unter Einzelpostenerkennung versteht man das automatische Auslesen bestimmter Daten wie Produktnamen, Mengen und Preise aus Dokumenten wie Quittungen und Rechnungen. Dies hilft Unternehmen, Ausgaben, Rechnungen und Verbindlichkeiten effizienter zu verwalten und gleichzeitig das Risiko von Fehlern und Betrug zu verringern.
KI-gesteuerte OCR scannt und analysiert Dokumente, erkennt Muster und liest Text aus verschiedenen Positionen wie z. B. Einzelposten. Die Technologie nutzt maschinelles Lernen, um sich an unterschiedliche Dokumentenformate anzupassen und den Prozess schnell und genau zu gestalten.
Vor allem der Einzelhandel und der Finanzsektor profitieren, aber auch Unternehmen im Bereich Kundenbindungsprogramme und Beschaffungsmanagement sehen große Vorteile durch eine effizientere Datenverarbeitung und Betrugserkennung.
Template OCR arbeitet mit vordefinierten Vorlagen und ist bei verschiedenen Dokumentenformaten weniger flexibel. Die KI-gesteuerte OCR nutzt maschinelles Lernen, um sich kontinuierlich anzupassen und zu verbessern, so dass sie besser in der Lage ist, unterschiedliche Dokumente zu verarbeiten.
Klippa DocHorizon automatisiert die Dokumentenverarbeitung mit OCR und KI, bietet mehrsprachigen Support, lässt sich mühelos in bestehende Systeme integrieren und hilft bei der Betrugserkennung. Dies erhöht die Effizienz, Genauigkeit und Sicherheit Ihrer Prozesse.
Ja, Klippa DocHorizon unterstützt alle lateinischen Sprachen und ist somit für Unternehmen mit unterschiedlichen Sprachbedürfnissen geeignet.
Unternehmen können Quittungen für Prämien oder Punkte automatisch verarbeiten, indem sie Einzelposten validieren, um sicherzustellen, dass Prämien nur für gültige Einkäufe vergeben werden. Dies erhöht die Effizienz von Kundenbindungsprogrammen und verbessert das Kundenerlebnis.
Klippa DocHorizon kann nahtlos in bestehende Systeme, Datenbanken und ERP-Lösungen integriert werden, so dass Unternehmen ihre Arbeitsabläufe ohne größere Änderungen optimieren können.