Seit 2018 hat die europäische Datenschutz-Grundverordnung (DSGVO) dazu geführt, dass sich Unternehmen ihrer Verantwortung bei der Speicherung und Verwaltung personenbezogener Daten bewusster sind als je zuvor. Die DSGVO schreibt vor, dass Unternehmen den Schutz personenbezogener Daten (PII) gewährleisten müssen, und eine der wichtigsten Strategien zur Einhaltung dieser Vorschriften ist die Pseudonymisierung.
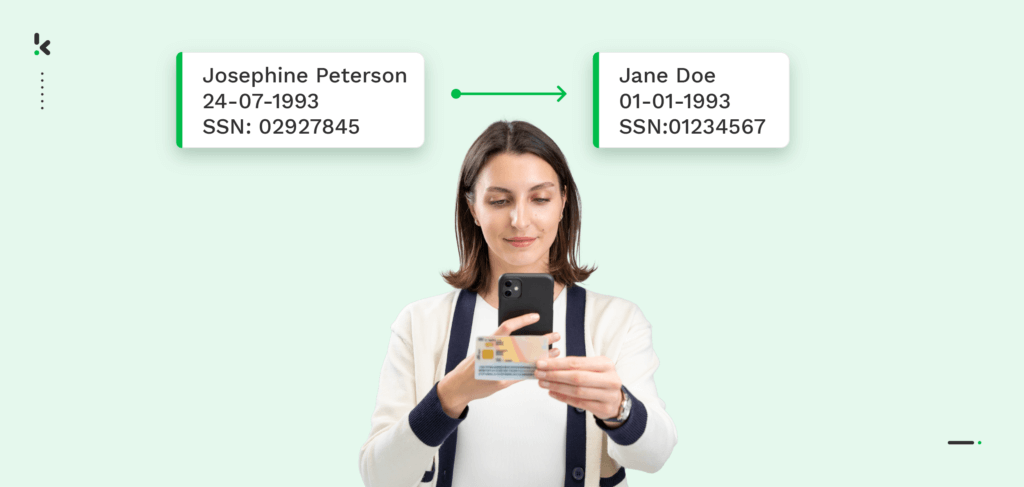
Im Gegensatz zur Datenanonymisierung, bei der sensible Informationen entfernt werden, ermöglicht die Pseudonymisierung eine Re-Identifizierung, indem identifizierbare Informationen durch Pseudonyme ersetzt werden und sensible Informationen sicher entfernt werden. In diesem Blog definieren wir Anonymisierung und Pseudonymisierung, erläutern den Unterschied zwischen beiden und gehen darauf ein, wie automatisierte Pseudonymisierung Ihrem Unternehmen bei der Einhaltung der DSGVO helfen kann.
Wichtige Erkenntnisse
- DSGVO seit 2018: Unternehmen sind stärker als je zuvor verpflichtet, personenbezogene Daten (PII) sicher zu speichern, zu verarbeiten und zu schützen.
- Pseudonymisierung als Schlüsselstrategie: Sie ersetzt identifizierbare Informationen durch Pseudonyme, entfernt sensible Details und ermöglicht bei Bedarf eine Re-Identifizierung.
- Unterschied zur Anonymisierung: Während Anonymisierung jegliche Rückverfolgung unmöglich macht, bleibt bei der Pseudonymisierung eine kontrollierte Rückgewinnung der Originaldaten möglich.
- Automatisierte Pseudonymisierung: Digitale Tools, wie Intelligent Document Processing (IDP) und OCR-Technologien, ermöglichen eine DSGVO-konforme Datenverarbeitung effizient und skalierbar.
- Business-Vorteil: Durch konsequente Umsetzung stärken Sie die Compliance Ihres Unternehmens und das Vertrauen von Kunden und Partnern.
Was ist Datenpseudonymisierung?
Bei der Datenpseudonymisierung handelt es sich um ein Verfahren, bei dem sensible Informationen wie Namen oder E-Mails entfernt und durch Pseudonyme, Aliasse oder Platzhalterwerte ersetzt werden.
Pseudonyme lassen sich als Decknamen beschreiben, die dazu dienen, die Identität einer Person zu verschleiern. Viele Autoren verwenden beispielsweise ein Pseudonym oder einen Künstlernamen, um ihre wahre Identität zu verbergen. Es ist wichtig zu erwähnen, dass nicht nur Namen, sondern auch personenbezogene Daten wie E-Mail-Adressen, Standortdaten und IDs pseudonymisiert werden können.
Dieses Verfahren ist umkehrbar, was bedeutet, dass die verschleierten Daten bei Bedarf später wieder rückgängig gemacht werden können. Die Pseudonymisierung erfüllt zwei Zwecke: Sie verbessert den Datenschutz und die Wahrung der Privatsphäre und ermöglicht es Unternehmen gleichzeitig, die Daten für legitime Zwecke zu nutzen.
Wie funktionieren Pseudonomysierungen?
Wie wir gesehen haben, funktioniert die Pseudonymisierung, indem persönliche Daten durch künstliche Identitäten oder Pseudonyme ersetzt werden. Dadurch ist es ohne zusätzliche Informationen unmöglich, die Daten einer bestimmten Person zuzuordnen. Die Verknüpfung zwischen den Pseudonymen und den Originaldaten wird getrennt in einer sicheren Umgebung gespeichert und häufig durch Verschlüsselung geschützt.
Typische Schritte bei der Pseudonymisierung sind:
- Identifizierung: Persönliche Daten der Person finden, die pseudonymisiert werden soll
- Ersetzen: Persönliche Daten durch Ersatzinformationen austauschen
- Speicherort festlegen: Die Verbindung zwischen den gefälschten Kennungen und den Originaldaten muss sicher gespeichert werden.
- Datennutzung: Verwenden Sie pseudonymisierte Daten für Geschäftszwecke, ohne dabei personenbezogene Daten preiszugeben.

Dieses Verfahren ermöglicht es Unternehmen, Daten weiterhin für Analysen oder zur Verarbeitung zu nutzen, ohne dabei persönliche Identitäten direkt offenzulegen.
Nachdem wir nun die Pseudonymisierung behandelt haben, schauen wir uns den Vergleich zur Anonymisierung genauer an. Beide Verfahren dienen dem Schutz personenbezogener Daten, erreichen dies jedoch auf unterschiedliche Weise. Die Unterschiede von beiden Methoden zu verstehen hilft Ihnen dabei, die beste Lösung für Sie zu finden.
Pseudonymisierung vs Anonymisierung
Pseudonymisierung und Anonymisierung sind zwei wesentliche Verfahren zum Schutz personenbezogener Daten, unterscheiden sich jedoch deutlich in ihrer Vorgehensweise und ihren Ergebnissen.
Wie bereits erwähnt, Pseudonymisierungen ersetzen identifizierbare Informationen so, dass sie keiner Person zugeschrieben werden können. Dieser Vorgang kann jedoch bei Bedarf rückgängig gemacht werden, weshalb das Datenschutzniveau als moderat einzustufen ist. Bei der Datenanonymisierung hingegen ist die Verschleierung sensibler Informationen irreversibel, wodurch dieses Verfahren das höchste Maß an Datenschutz bietet.
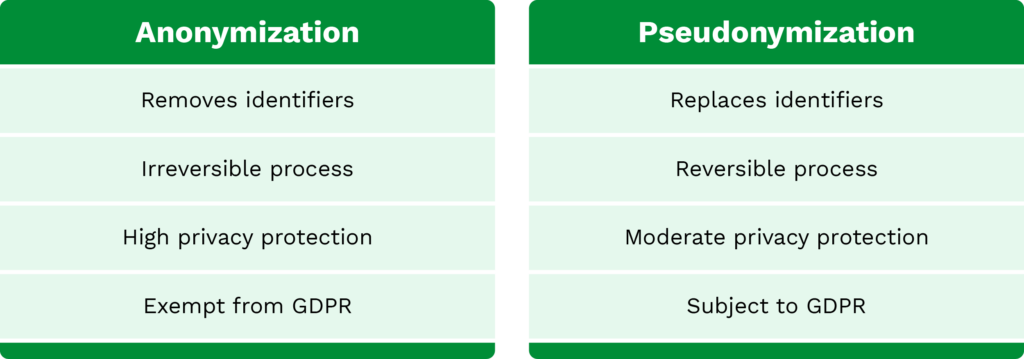
Hinsichtlich der Datenverwertbarkeit gibt es einen wesentlichen Unterschied. Im Gegensatz zur Pseudonymisierung werden bei der Anonymisierung Identifikatoren entfernt, wodurch die Daten deutlich weniger nutzbar sind. Pseudonymisierte Daten können weiterhin für Analysen und zur Verarbeitung genutzt werden, während sie geschützt bleiben. Dies bietet ein ausgewogenes Verhältnis zwischen Datenschutz und Datennutzen.
Die Datenanonymisierung ist ideal für statistische Analysen, Forschung und die Weitergabe von Daten ohne Datenschutzbedenken, wie beispielsweise bei Studien im Bereich der öffentlichen Gesundheit. Im Gegensatz dazu eignet sich die Datenpseudonymisierung eher für Situationen, in denen Daten zwar weitergegeben werden müssen, für die Analyse oder Verarbeitung jedoch noch ein gewisses Maß an Identifizierbarkeit erforderlich ist, wie etwa bei klinischen Studien.
Hinsichtlich der DSGVO ist die Anonymisierung ausgenommen, da hierbei keine personenbezogenen Daten mehr vorliegen. Bei der Pseudonymisierung von Dokumenten hingegen lassen sich die verschleierten Daten re-identifizieren. Das bedeutet, dass sie weiterhin als personenbezogene Daten gelten und somit der DSGVO unterliegen.
Vorteile der Datenpseunonymisierung
Nachdem wir nun den Unterschied zwischen Pseudonymisierung und Anonymisierung geklärt haben, schauen wir uns die wichtigsten Vorteile der Pseudonymisierung genauer an.
1. Verbesserter Datenschutz
Die Pseudonymisierung von Daten verringert das Risiko unbefugter Zugriffe und von Datenpannen, indem identifizierbare Informationen durch Pseudonyme ersetzt werden. Dies führt zu einem verbesserten Datenschutz.
2. Einhaltung gesetzlicher Vorschriften
Durch den Einsatz von Pseudonymisierungsverfahren können Unternehmen Datenschutzbestimmungen, wie die DSGVO, leichter einhalten und so rechtliche Konsequenzen sowie Bußgelder vermeiden.
3. Sicheres Datenteilen
Mit Pseudonymisierungen ist es einfacher sensible Daten zwischen verschiedenen Unternehmen, Abteilungen oder Drittanbietern zu teilen. Dies hilft ebenfalls Unternehmen Datenschutzstandards zu treffen und einzuhalten, ohne die Privatsphäre des Einzelnen zu gefährden.
4. Erhalt der Datennutzung
Da die Pseudonymisierung kein irreversibler Vorgang ist, behalten pseudonymisierte Daten ihre Funktionalität. Sie können somit für verschiedene Anwendungsfälle genutzt werden, beispielsweise für Kundenbindungskampagnen, Analysen und Forschung, während die Identität einzelner Personen geschützt bleibt.
5. Geringeres Datenrisiko
Im Falle einer Datenpanne erschwert die Pseudonymisierung es Angreifern, sensible Informationen zu identifizieren und darauf zuzugreifen.
6. Gesteigertes Kundenvertrauen
Heutzutage erwarten Kunden, dass Unternehmen sorgsam mit ihren sensiblen Daten umgehen. Die Pseudonymisierung hilft Unternehmen dabei, dies unter Beweis zu stellen und stärkt somit das Vertrauen der Kunden.
Nachteile der Datenpseudonymisierung
Obwohl Pseudonymisierungen mehr Vorteile als Nachteile haben, gibt es trotzdem erwähnenswerte Nachteile. Hier ein Überblick:
1. Risiko der Umkehrbarkeit
Die Pseudonymisierung ist ein reversibler Prozess. Das bedeutet, dass bei Vorliegen zusätzlicher Informationen wieder auf die ursprünglichen Daten zugegriffen werden kann.
2. Compliance-Problematik
Zwar trägt die Pseudonymisierung bis zu einem gewissen Grad zur Einhaltung der DSGVO bei, sie befreit jedoch nicht vollständig von den datenschutzrechtlichen Anforderungen, da pseudonymisierte Daten weiterhin als personenbezogene Informationen gelten.
3. Komplexität der Implementierung
Die Pseudonymisierung ist ein komplexes Verfahren, das fortschrittliche und hochentwickelte Software erfordert, um einen sicheren und effizienten Umgang mit Daten zu gewährleisten.
4. Genauigkeitsverlust
Beim Ersetzen personenbezogener Identifikatoren durch Pseudonyme können Informationen verloren gehen oder verändert werden. Dies führt zu Ungenauigkeiten, wenn die Daten für Analysen oder zur Entscheidungsfindung herangezogen werden.
Das Verständnis der Vorteile und Herausforderungen der Pseudonymisierung hilft Ihnen dabei, Ihre sensiblen Daten besser zu schützen. Im Folgenden untersuchen wir einige Anwendungsfälle aus der Praxis, in denen Pseudonymisierung zum Einsatz kommen kann.
Anwendungsfälle der Pseudonymisierung
Die Pseudonymisierung ist ein leistungsstarkes Instrument für viele Unternehmen, die ein Gleichgewicht zwischen der Datennutzung und dem Schutz der individuellen Privatsphäre wahren wollen. Vom Gesundheitswesen über Finanzdienstleistungen bis hin zur Softwareentwicklung und Forschung, die Pseudonymisierung macht Ihnen das Leben leichter. Werfen wir einen Blick auf die häufigsten Anwendungsfälle:
1. Finanzdienstleistungen
Kontonummern und Kreditkartendaten können pseudonymisiert werden, bleiben aber für die Verarbeitung und Analyse weiterhin nutzbar. Banken und Finanzinstitute können so vorgehen und gleichzeitig sensible Kundendaten schützen.
2. Medizinische Forschung
Medizinische Einrichtungen können pseudonymisierte Daten an Forscher weitergeben. Dies ermöglicht großangelegte Studien und verbessert die Behandlungsergebnisse, während gleichzeitig die Privatsphäre der Patienten geschützt wird.
3. Softwareentwicklung und Softwaretests
Entwicklungsteams können echte Daten in Testumgebungen nutzen, um mit realistischen Informationen zu arbeiten und dabei gleichzeitig die Privatsphäre des Einzelnen zu schützen.
4. Cybersicherheit
Pseudonyme können echte Benutzerkennungen ersetzen, um die Systemleistung besser zu analysieren, die Benutzerreputation nachzuverfolgen, Identitäten bei Sicherheitsuntersuchungen zu schützen und vieles mehr.
Automatisierung der Datenpseudonymisierung mit Software
Die Pseudonymisierung von Dokumenten lässt sich mithilfe von Software automatisieren, um den Prozess zu optimieren und die Effizienz zu steigern. Die Automatisierung hat dabei entscheidende Vorteile: Sie gewährleistet, dass sensible Daten schnell und präzise durch Pseudonyme ersetzt werden, und minimiert so das Risiko menschlicher Fehler.
Die Automatisierung der Dokumentenpseudonymisierung mit der richtigen Software hilft Unternehmen dabei, die Datensicherheit zu erhöhen, ohne auf fehleranfällige manuelle Prozesse angewiesen zu sein. Zudem ermöglicht sie es Unternehmen, große Datenmengen effizient zu verarbeiten und dabei gleichzeitig Datenschutzstandards zu wahren sowie die Einhaltung der DSGVO sicherzustellen.
Vor allem aber spart die Automatisierung des Pseudonymisierungsprozesses Zeit, wodurch sich ihre Mitarbeiter auf höher priorisierte Aufgaben konzentrieren können. Dies steigert die Gesamtproduktivität und trägt zum langfristigen Erfolg bei.
Bevor Sie fortfahren, sollten Sie sich fragen: Reicht Pseudonymisierung aus, um Ihre Anforderungen zu erfüllen, oder gibt es einen sichereren Ansatz zum Schutz sensibler Daten?
Wie kann Klippa beim sichern Ihrer Daten helfen?
Wenn die Pseudonymisierung von Daten Ihre Anforderungen nicht vollständig abdeckt, weil beispielsweise eine Re-Identifizierung weiterhin möglich ist oder die benötigte vollständige Unumkehrbarkeit fehlt, könnte Anonymisierung die ideale Lösung für Ihr Unternehmen sein. In jedem Fall steht Ihnen Klippa zur Seite, um die optimale Datenschutzstrategie umzusetzen.
Sollten Sie Daten in Dokumenten anonymisieren müssen, kann die Anonymisierungssoftware von Klippa bestimmte Felder und Texte problemlos schwärzen und maskieren. Dokumente können per E-Mail, über das Web oder über mobile Anwendungen in Formaten wie JPG, PNG oder PDF eingereicht werden. Nach der Anonymisierung erhalten Sie die verarbeiteten Dateien in Ihrem bevorzugten Format, wie zum Beispiel JSON, XLSX, XML oder CSV.
Klippa DocHorizon bietet folgende Vorteile:
- Erhaltung der Nutzbarkeit Ihrer Daten: Automatische Anonymisierung sensibler Informationen.
- Verbesserte und mühelose Einhaltung: Einhaltung von gesetzlichen Verordnungen.
- Kostenreduzierung: Sparen Sie Kosten durch die Bündelung von digitalen Datenprozessen.
- Schnellere Durchlaufzeiten: Anonymisierung und Verarbeitung von Daten durch Automatisierung.
- Nahtlose Skalierbarkeit: Erzielen Sie eine nahtlose Skalierbarkeit bei minimalem manuellem Aufwand.
Bereit Ihre Datenanonymisierungen zu automatisieren? Buchen Sie sich eine kostenlose Demo mit dem unteren Link oder wenden Sie sich an unsere Experten für weitere Informationen.
FAQ – Häufig gestellte Fragen
1. Was ist der Unterschied zwischen Pseudonymisierung und Anonymisierung?
Der Hauptunterschied liegt in der Umkehrbarkeit. Bei der Pseudonymisierung werden Daten verschleiert, können aber wieder re-identifiziert werden. Das Datenschutzniveau ist moderat, und die Daten unterliegen weiterhin der DSGVO.
Bei der Anonymisierung werden die sensiblen Daten werden irreversibel entfernt oder verändert. Eine Re-Identifizierung ist nicht mehr möglich. Diese Daten fallen nicht mehr unter die DSGVO und bieten das höchste Datenschutzniveau.
2. Unterliegen pseudonymisierte Daten der DSGVO?
Ja. Da pseudonymisierte Daten theoretisch wieder einer Person zugeordnet werden können (Re-Identifizierung), gelten sie weiterhin als personenbezogene Daten. Das Verfahren hilft Unternehmen jedoch erheblich dabei, die Datenschutzbestimmungen einzuhalten und Bußgelder zu vermeiden, befreit sie aber nicht gänzlich von der DSGVO-Pflicht.
3. Welche Vorteile bietet die Pseudonymisierung für Unternehmen?
Sie ermöglicht ein Gleichgewicht zwischen Datenschutz und Datennutzen. Unternehmen können Daten weiterhin für Analysen, Forschung oder Softwaretests verwenden, ohne die Identität von Personen direkt preiszugeben.
4. Warum sollte man die Pseudonymisierung automatisieren?
Die manuelle Bearbeitung ist fehleranfällig und zeitaufwendig. Automatisierte Softwarelösungen können große Datenmengen schnell und präzise verarbeiten, menschliche Fehler minimieren und sicherstellen, dass sensible Daten konsistent geschützt werden. Dies spart Zeit und Kosten.
5. Wie kann Klippa beim Datenschutz helfen?
Wenn Pseudonymisierung für Ihre Anforderungen nicht ausreicht und Sie eine irreversible Lösung benötigen, bietet Klippa DocHorizon eine leistungsstarke Software zur Datenanonymisierung. Sie kann sensible Felder in Dokumenten automatisch schwärzen und maskieren. Dies gewährleistet, dass Daten dauerhaft unkenntlich gemacht werden, während die Dokumente in verschiedenen Formaten (JSON, XML, CSV etc.) weiterverarbeitet werden können.