
Quer pretenda extrair datas e montantes de faturas ou esteja à procura de itens de linha de produtos em recibos, uma das primeiras soluções de OCR que encontrará online é o Tesseract. O Tesseract é um dos primeiros motores de OCR sérios e de código aberto desenvolvidos.
O software remonta a 1985, quando o desenvolvimento foi iniciado pela Hewlett-Packard como uma solução comercial. Em 2005, acabou por se tornar um projeto de código aberto e, desde então, a Google tem apoiado o seu desenvolvimento durante vários anos.
Nos últimos anos, o desenvolvimento foi interrompido pelo facto de muitas empresas de software terem desenvolvido soluções de OCR alternativas. Estas soluções comerciais não são gratuitas, mas se procura uma solução madura que esteja a melhorar continuamente e que incorpore a aprendizagem automática e a inteligência artificial (IA), então temos a melhor alternativa ao Tesseract para si.
Mas vamos primeiro discutir brevemente o que é o Tesseract, porque é que deve e não deve utilizá-lo e, em seguida, analisar as cinco melhores alternativas ao Tesseract OCR.
O que é o Tesseract?
Como mencionado, o Tesseract é um software OCR de código aberto que pode ser utilizado para extrair texto de imagens. É capaz de reconhecer mais de 100 idiomas e é compatível com muitas linguagens de programação e frameworks.
Uma das vantagens do Tesseract é que pode ser agrupado e acoplado a bibliotecas Python OCR, o que dá aos utilizadores acesso a benefícios como a extração de dados de PDF, Computer Vision (CV) em tempo real e funcionalidades de processamento de imagem.
Por que razão deve utilizar o Tesseract?
O Tesseract inclui algumas funcionalidades que tornam o software perfeitamente adequado para um determinado grupo-alvo. Se não quiser ou não puder investir dinheiro em software de OCR, o Tesseract pode ser uma ótima opção. A sua utilização é gratuita, uma vez que se trata de um software de código aberto.
O Tesseract oferece uma excelente documentação, o que facilita a implementação do software no seu sistema. Se ainda tiver dúvidas, muitos outros utilizadores podem ajudá-lo com a configuração, uma vez que o software é utilizado por uma vasta gama de escritórios. O software é frequentemente utilizado como uma solução automatizada de introdução de dados, de integração digital de clientes e de processamento automatizado de faturas.
Contras da utilização do Tesseract
Embora o Tesseract seja adequado para alguns casos de utilização, também tem limitações significativas. Para que o software funcione para si, terá de escrever manualmente o código, o que significa que é necessário investir muito tempo e recursos. Na maioria dos casos, o desenvolvimento demora muito mais tempo até poder utilizar a solução de OCR, uma vez que não existe apoio por parte dos programadores.
Além disso, nem todos os tipos de documentos são suportados, o que conduz rapidamente a erros e a baixas taxas de precisão em comparação com soluções mais avançadas. Além disso, o Tesseract não automatiza outros processos documentais, como a verificação e a validação cruzada, uma vez que carece de mais desenvolvimento e da integração de IA.
Talvez já tenha sentido estas limitações e esteja agora à procura de uma solução alternativa. É por isso que na próxima secção vamos apresentar cinco alternativas ao Tesseract, três das quais são também de código aberto e duas são oferecidas como um serviço pago.
As 5 melhores alternativas ao Tesseract
De seguida, discutiremos cinco alternativas ao Tesseract:
- Klippa DocHorizon
- GImageReader
- OCR4all
- OpenScan
- Kofax OmniPage
#1 Klippa DocHorizon
O Klippa DocHorizon combina OCR com tecnologias avançadas de IA. Sendo um software de Processamento Inteligente de Documentos (IDP), é capaz de digitalizar, classificar, tornar anónimos, extrair e verificar dados.
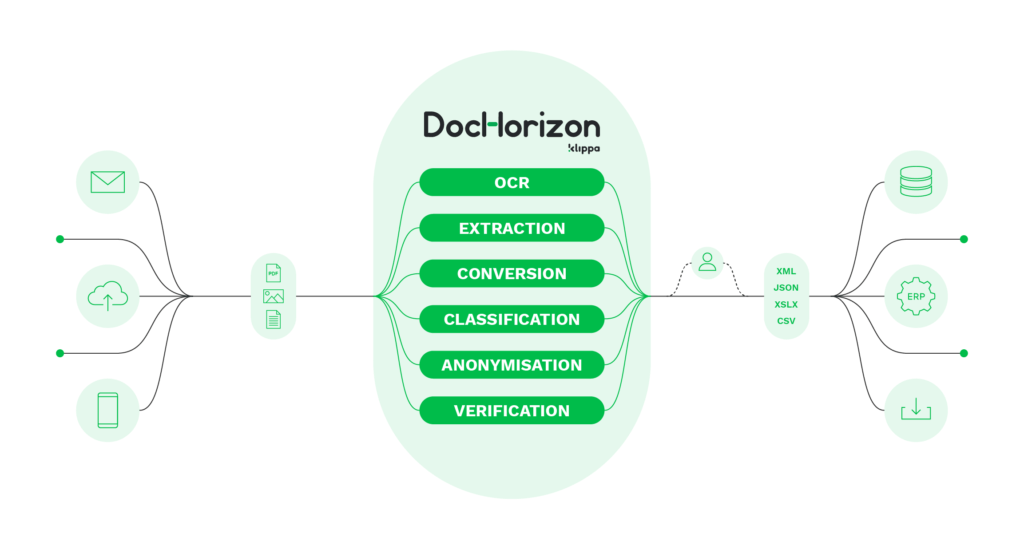
A solução de software é baseada principalmente na nuvem, mas também está disponível como uma implantação local. O Klippa DocHorizon permite que os utilizadores enviem documentos por e-mail, web ou aplicações móveis, ajudando as organizações a poupar até 95% do seu atual tempo de processamento manual de documentos.
Em geral, a solução IDP ajuda as empresas de vários sectores, como a contabilidade, os serviços financeiros, o marketing, a banca e a fidelização, a automatizar a introdução de dados. Ao utilizar a Klippa DocHorizon, as empresas destes setores podem capturar imagens, extrair dados, anonimizar dados sensíveis, classificar documentos e converter documentos em ficheiros pesquisáveis.
Prós do Klippa DocHorizon
- Captura de campos e itens de linha
- Infraestrutura da UE e dos EUA
- Implantação na nuvem e no local
- Extração de assinaturas e imagens
- Mascaramento de dados
- Pré-processamento de imagens
- SLA padrão
- Enviar ficheiros a qualquer momento, em qualquer lugar
- Integrável através de API ou SDK para aplicações de terceiros
- Classificação de documentos e dados
- Verificação cruzada com bases de dados de terceiros
Contras do Klippa DocHorizon
- Não há suporte para alfabetos não latinos
- Sem armazenamento de documentos
O Klippa DocHorizon é melhor utilizado para
- Documentos financeiros (faturas, recibos, etc.)
- Documentos de identidade (passaportes, bilhetes de identidade, cartas de condução)
- Documentos do setor do retalho
#2 GImageReader
O GImage Reader é uma aplicação OCR gratuita que permite aos utilizadores abrir imagens e ficheiros PDF com facilidade. Depois de um documento ser aberto, os utilizadores podem selecionar qualquer área de uma imagem ou ficheiro PDF e extrair o texto necessário.
Prós do GImageReader
- Podem ser processadas várias imagens de uma só vez
- Código aberto
- Suporta a personalização de documentos
- Integra-se com a linguagem OCR Tesseract
Contras do GImageReader
- Não é possível uma personalização avançada
- Sem anonimização de dados
- Limitado a imagens e ficheiros PDF
O GImageReader é melhor utilizado para
- Documentos PDF
- Imagens
#3 OCR4all
Com o OCR4all, são combinadas várias soluções de fonte aberta, o que fornece ao utilizador um fluxo de trabalho totalmente automatizado para o reconhecimento automático de texto. O OCR4all pretende oferecer o seu serviço especificamente a utilizadores não técnicos.
Prós do OCR4all
- Ferramenta de OCR de fonte aberta
- Aplicação flexível a muitos tipos de documentos (desde manuscritos a impressões)
- Fácil implementação em várias plataformas
Contras do OCR4all
- Anotação manual de elementos de texto com o editor LAREX
- Os dispositivos Apple com um chip M1 / M2 ainda não são suportados
- A instalação e o arranque do Docker parecem ser um problema frequente
- Sem anonimização de dados
OCR4all é melhor utilizado para
- Imagens
#4 OpenScan
Com o OpenScan, os utilizadores podem digitalizar cópias impressas de documentos e notas e convertê-las em ficheiros PDF ou JPEG. É uma aplicação de código aberto com o lema “Sem anúncios. Sem recolha de dados. Nós respeitamos a sua privacidade.”.
Prós do OpenScan
- Focado na privacidade dos dados
- Sem anúncios
- Assinatura fácil de PDFs
- Visualizador de pré-visualização incorporado
- Permite-lhe preencher formulários PDF
- Telemóvel como scanner móvel
Contras do OpenScan
- Limitado a documentos PDF
- Não é possível a extração de dados
O OpenScan é melhor utilizado para
- Documentos PDF
#5 Kofax OmniPage
O Kofax OmniPage é um software de OCR capaz de automatizar a extração de dados de grandes volumes de documentos PDF. É especializado em extração de tabelas e correspondência de itens de linha. A plataforma de automação inteligente da Kofax ajuda as organizações a transformar processos de negócios com uso intensivo de informações.
Prós do Kofax OmniPage
- Reconhece mais de 120 idiomas durante o processamento de documentos
- Utilização de scanners móveis, scanners de secretária e impressoras multifunções
- Pesquisa, edita e acede a documentos em qualquer dispositivo
- Captura de campos e itens de linha
- Armazenamento de documentos
Contras do Kofax OmniPage
- A interface do utilizador poderia ser melhorada
- Sem controlos cruzados com bases de dados de terceiros
- Não existe uma infraestrutura europeia
- Não está disponível uma implementação no local
- Não há capacidade de extração de assinaturas e imagens
- Sem mascaramento de dados
O Kofax OmniPage é melhor utilizado para
- Faturas
- Recibos
- Pedidos de compra
Porque é que o Klippa DocHorizon é a melhor alternativa ao Tesseract?
Com o Klippa DocHorizon, organizações de todo o mundo podem automatizar fluxos de trabalho relacionados com documentos. Com o nosso software baseado em IA, é possível extrair com precisão dados de formatos de dados não estruturados (por exemplo, PDFs) e, além disso, verificá-los e torná-los anónimos.
O Klippa DocHorizon tem como objetivo eliminar a introdução manual de dados e ajudar as organizações a poupar tempo, custos e recursos. A nossa solução está disponível via API e SDK e inclui os seguintes benefícios:
- Extração de dados → Extração de dados de informações importantes em tempo real
- Digitalização móvel → Os documentos podem ser digitalizados com dispositivos móveis em qualquer altura e em qualquer lugar
- OCR → Os documentos podem ser transformados em texto e formatos estruturados legíveis por máquina
- Classificação → Os documentos podem ser classificados e ordenados de acordo com as suas necessidades
- Anonimização → Os dados sensíveis podem ser mascarados ou removidos, protegendo-o a si e aos seus clientes de violações de dados
- Conversão de documentos → Os formatos de documentos não estruturados, como JPG, PNG e PDF, podem ser convertidos em texto pesquisável e depois exportados para formatos estruturados legíveis por máquina, como CSV, XLSX, XML e JSON.
- Verificação → A autenticidade e a validade dos documentos e dados podem ser verificadas
Quer saber mais sobre a nossa solução e como pode servir de alternativa ao Tesseract? Teremos todo o gosto em mostrar-lhe como funciona o nosso software. Basta reservar uma demonstração gratuita em baixo ou contactar um dos nossos especialistas.