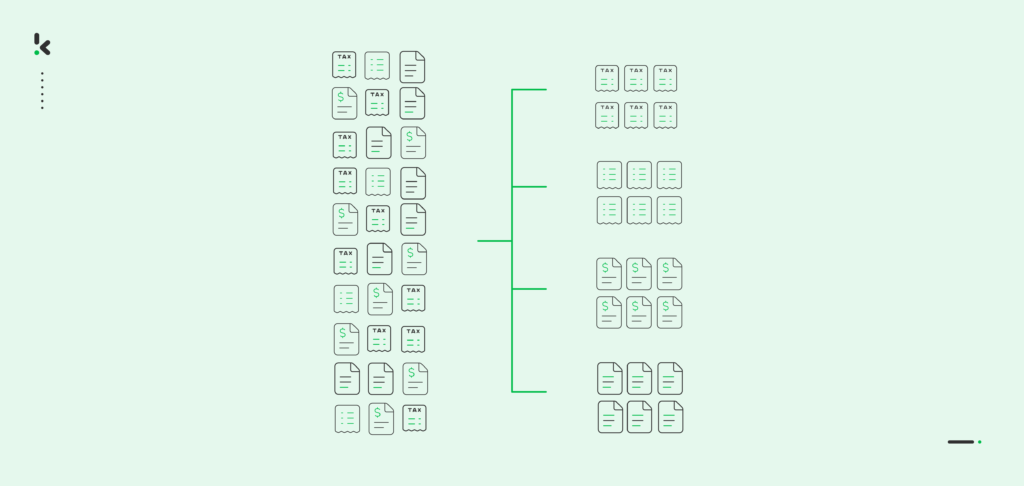
Les organisations traitent quotidiennement de grandes quantités de documents dont le type, le contenu ou l’importance varient. Assurer une classification précise de ces fichiers peut rapidement devenir frustrant, surtout si cela est fait manuellement. Certains de vos employés sont chargés d’organiser manuellement les documents sur la base de ces labels. Cela prend du temps et, dans le pire des cas, les fichiers sont perdus car ils sont classés de manière inexacte.
Cependant, grâce au développement rapide de la technologie, les employés ne passent plus trop de temps à identifier les documents, laissant ces tâches entre les mains de l’automatisation. Dans ce blog, vous trouverez une explication détaillée de ce que représente la classification des documents, vous découvrirez le processus qui permet de l’automatiser et vous découvrirez une solution prête à l’emploi pour la classification de vos documents d’entreprise.
Les Points Clés :
- La classification documentaire automatise l’organisation des fichiers, accélérant les recherches et optimisant les flux de travail.
- Grâce à l’IA, notamment à la reconnaissance optique de caractères (OCR) et à l’apprentissage automatique, les entreprises peuvent classer leurs documents avec précision, sans intervention manuelle.
- Cette automatisation limite les erreurs, renforce la conformité et améliore la sécurité des données qui est un atout indispensable pour les entreprises modernes.
- Les solutions logicielles de classification automatique offrent une méthode rapide et prête à l’emploi pour trier efficacement les documents, tout en réduisant les efforts manuels et les risques d’erreurs.
Qu’est-ce que la classification des documents ?
La classification des documents est le processus qui consiste à classer les documents dans des catégories pertinentes afin d’en faciliter la gestion et l’analyse. L’objectif est d’organiser les fichiers de la manière la plus précise possible, afin de faciliter la recherche et le repérage des éléments.
Si la classification des documents est une tâche importante en soi, elle s’inscrit également dans le cadre d’une initiative d’automatisation beaucoup plus vaste, appelée le traitement intelligent des documents. Par conséquent, le tri de ces fichiers n’est que l’une des nombreuses actions qui peuvent être automatisées pour améliorer les flux de traitement des documents.
La classification des documents peut être effectuée à l’aide de deux paramètres, à savoir la classification textuelle et la classification visuelle. Certains de ces paramètres peuvent être observés dans des moteurs de recherche réels, permettant aux utilisateurs de trouver ce qu’ils recherchent sans trop d’efforts.
Pour mieux comprendre comment la catégorisation des documents peut avoir lieu, il est nécessaire de prendre du recul et d’analyser d’abord le processus technique qui sous-tend la classification automatisée des documents.
Types de classification des documents
Comme indiqué précédemment, les documents sont classés en fonction de leur contenu, qu’il s’agisse de texte ou d’image. Pour chaque type de classification de document, vous pouvez découvrir différentes méthodes utilisées pour détecter et analyser le contenu spécifique, que nous allons aborder dans quelques instants.
1. Classification de texte
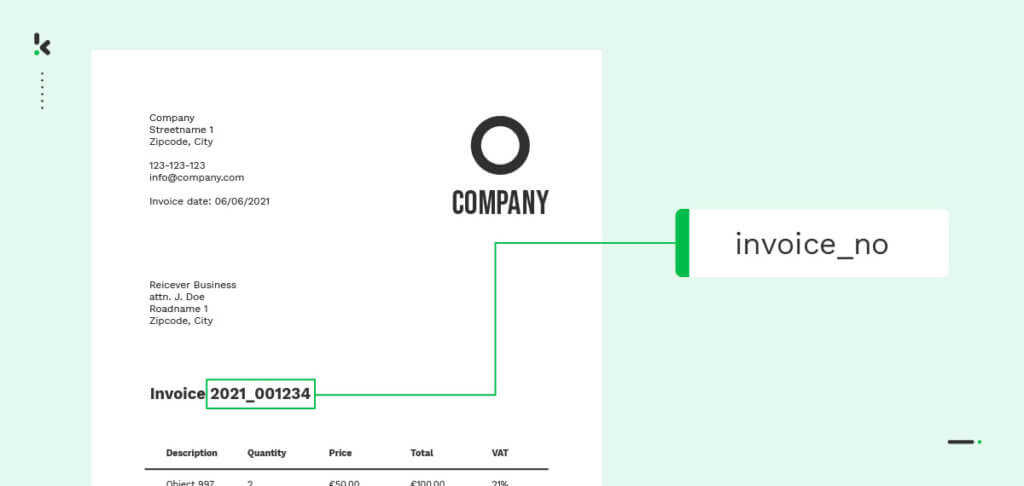
La classification de textes concerne le traitement d’informations textuelles provenant de divers types de documents. Étant donné que la majorité des entreprises s’appuient sur des documents à forte teneur en texte pour leurs activités quotidiennes, la classification des textes est devenue le principal objectif de la plupart des fournisseurs de logiciels tels que les logiciels OCR.
Comment fonctionne la classification des textes ? La classification des documents textuels fait souvent appel à des technologies telles que l’OCR et le NLP, qui relèvent de la technologie du machine learning.
Reconnaissance optique de caractères (ROC ou OCR) :
L’OCR est une technologie qui permet d’extraire du texte d’images ou de documents numérisés et de le convertir dans un format lisible par une machine. Souvent, cette technologie est associée à l’intelligence artificielle (IA) et à l’apprentissage automatique (ML), afin d’obtenir une grande précision dans l’extraction des données.
Natural Language Processing (NLP) :
Le NLP (Natural Language Processing) ou TALN (Traitement Automatique des Langues) est une technique plus complexe, chargée d’analyser plus en détail les données extraites et de comprendre la sémantique du texte. Le NLP permet aux ordinateurs de comprendre le langage humain dans un contexte spécifique, créant ainsi un processus d’extraction de données de haute précision et de haute qualité.
Pour classer automatiquement un document, il faut d’abord utiliser l’OCR pour extraire l’information et le NLP pour comprendre le contenu de l’information.
2. Classification des images
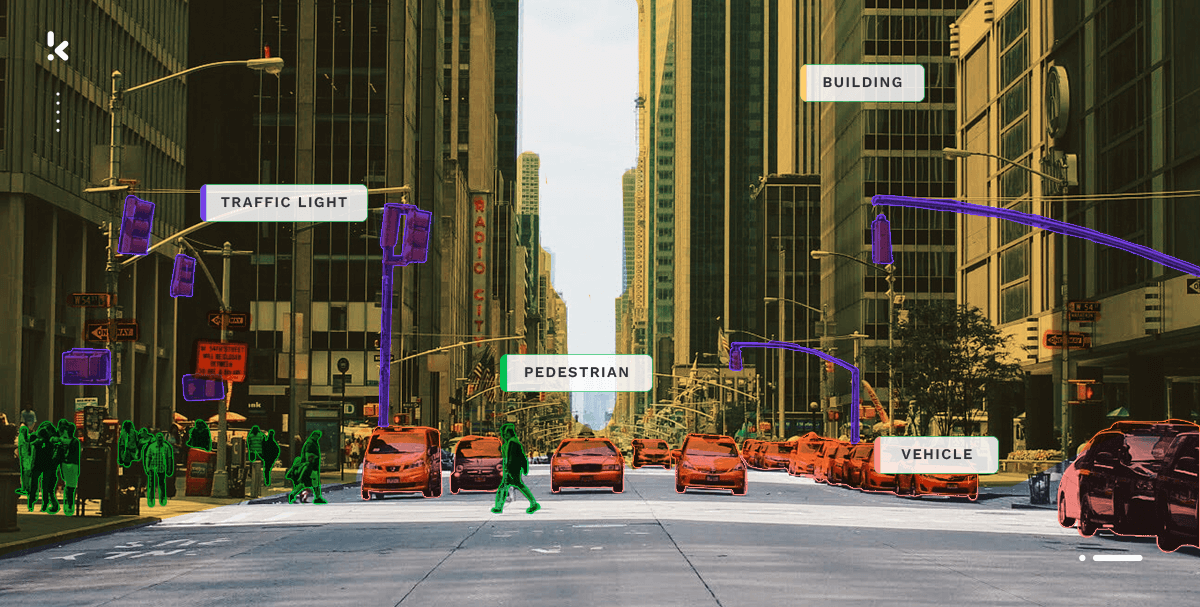
En matière de classification d’images, l’accent est mis sur la structure visuelle des documents. La détection des images et des vidéos dans un document se fait en analysant les pixels qui créent le visuel et en déterminant ensuite son contenu. L’identification et la classification des images s’effectuent à l’aide de technologies telles que la vision par ordinateur et la détection d’objets.
Computer Vision ou vision par ordinateur :
La vision par ordinateur est une technologie basée sur l’intelligence artificielle capable de reconnaître des objets sur des images fixes ou des vidéos. Vous pouvez l’utiliser pour détecter des objets dans une image, leur emplacement dans le document ou l’action décrite dans le contenu visuel. La vision par ordinateur vous aide à classer les images en appliquant des options de filtrage et de recherche.
Détection d’objets :
La détection d’objets est utilisée dans les secteurs d’activité qui doivent gérer de grandes quantités de données visuelles et où la classification s’effectue à grande échelle. Par exemple, la détection d’objets est répandue dans les services logistiques, les entrepôts et les stocks, où la numérisation de codes-barres ou de QR codes fait partie des opérations quotidiennes.
Maintenant que vous vous êtes familiarisés avec les technologies utilisées pour améliorer la classification des textes et des images, approfondissons le sujet et découvrons les méthodes utilisées pour la classification automatisée des documents.
Méthodes de classification automatisée de documents avec le Machine Learning
La classification automatisée des documents est réalisée à l’aide de la méthode du « machine learning » (apprentissage automatique). Il s’agit principalement de NLP, qui nécessite l’apprentissage de grandes quantités de données, afin de détecter et de définir des modèles dans les documents avec une grande précision.
Pour entraîner le modèle, nous lui fournissons des données préexistantes, qui bénéficient déjà de catégories et d’ensembles de caractéristiques prédéterminés. Cela permet au modèle d’apprendre les liens statistiques entre les mots et les phrases.
Les systèmes de classification par machine learning collectent des ensembles de données d’entraînement, par exemple des articles, des essais ou tout autre texte pouvant être utilisé pour extraire des mots clés et définir des catégories sur lesquelles le modèle peut s’appuyer pour apprendre. Cependant, il existe plusieurs méthodes de classification des documents à l’aide du machine learning, que nous aborderons dans la section suivante.
Classification supervisée des documents
Dans la classification supervisée de documents, vous fournissez vous-même les données d’entrée, c’est-à-dire que vous entraînez le modèle sur des documents déjà labellisés. Par conséquent, la classification est effectuée en évaluant la relation entre le nouveau document et les données historiques déjà labellisées.
Par exemple, vous fournissez au modèle des factures, des reçus et des relevés bancaires pour qu’il apprenne. Le modèle reconnaîtra et classera très bien ces types de documents. Mais si vous demandez au modèle de classer des documents d’identité, il échouera. Le modèle n’a pas pu trouver de relation entre les nouveaux documents, c’est-à-dire les documents d’identité, et les données historiques labellisées, c’est-à-dire les factures ou les reçus, de sorte que la classification s’avère inexacte.
Avantages
- Il s’agit d’une classification précise des documents
- Il est facile d’évaluer ses résultats
Inconvénients
- Elle nécessite un grand ensemble de données pour entraîner le modèle
- La labellisation d’une grande quantité de données peut prendre du temps et coûter cher.
Classification non supervisée des documents
La classification non supervisée des documents ne nécessite pas de données d’apprentissage. Elle vise à trier les documents en analysant leur contenu et en trouvant des différences entre eux. Le modèle crée ensuite des grappes, ou catégories, dans lesquelles les documents triés sont placés. Bien que certains documents puissent présenter des similitudes, les catégories sont inconnues du modèle, ce qui laisse place à l’incertitude quant à la qualité de la classification.
Avantages
- Il ne nécessite pas de données d’apprentissage préalablement labellisées.
- Il est plus rapide et moins coûteux à utiliser puisqu’il ne nécessite pas de labellisation.
Inconvénients
- Elle est plus difficile à évaluer
- Elle est moins précise que la méthode supervisée
Classification semi-supervisée des documents
La classification semi-supervisée des documents consiste en une combinaison entre les classifications labellisés et non labellisé. Elle utilise des ensembles de données d’apprentissage étiquetés et non étiquetés, ce qui améliore les performances des deux méthodes de classification, mais n’en perfectionne aucune.
Avantages
- Améliore la précision des deux méthodes de classification
- Elle ne nécessite pas autant de données d’apprentissage que la classification supervisée.
Inconvénients
- Elle est plus difficile à mettre en œuvre que les méthodes supervisées et non supervisées.
- Elle peut être moins précise qu’une classification entièrement supervisée.
Maintenant que nous avons découvert les différentes méthodes de classification qui utilisent l’apprentissage automatique, voyons comment se déroule le processus d’automatisation de la classification des documents.
Comment classer automatiquement des documents ?
La classification automatique des documents utilise des méthodes d’apprentissage profond (un sous-ensemble de l’apprentissage automatique) pour classer les fichiers dans différentes catégories, sans aucune intervention humaine. Pour ce faire, vous suivez un processus simple en trois étapes, qui se déroule comme suit :
Étape 1 : Rassembler un ensemble de donnée
Pour entraîner le modèle de classification, vous devez d’abord préparer les données. Il s’agit de recueillir au moins 20 points de données par label, c’est-à-dire 20 documents par catégorie. Cela permet d’augmenter la précision des résultats et d’obtenir un résultat final qualitatif. L’algorithme classe les résultats en fonction des données spécifiques sur lesquelles il a été entraîné.
Par exemple, si vous souhaitez classer uniquement des factures, il serait logique d’entraîner le modèle sur plusieurs factures. En revanche, si vous souhaitez classer un autre type de document, par exemple un reçu, le modèle risque d’avoir du mal à classer avec précision les documents souhaités.
Étape 2 : Entraîner le modèle
Cette étape peut s’avérer longue et coûteuse, en fonction de la méthode de classification choisie, c’est-à-dire supervisée, non supervisée ou semi-supervisée. Bien qu’il s’agisse d’une tâche redondante, elle est nécessaire pour obtenir les résultats les plus précis.
Étape 3 : Évaluer les résultats
La comparaison des résultats avec les attentes est une pratique essentielle pour s’assurer que le modèle fonctionne comme prévu. Pour ce faire, les résultats de la classification peuvent être comparés à ceux d’un document déjà prédit, ce qui garantit une représentation précise lors de la comparaison.
Pour bien comprendre ce processus, il faut prendre tout le temps nécessaire. Si vous vous empressez de fournir au modèle des données inexactes ou si vous ne lui fournissez pas suffisamment de points de données, vous vous compliquerez la vie à long terme. Le fait de ralentir et de bien comprendre cette procédure vous permet d’obtenir les meilleurs résultats de vos efforts de classification des documents.
Besoin d’une solution plus rapide ?
Inutile de développer et d’entraîner votre propre modèle : optez pour Klippa DocHorizon, une plateforme intelligente de gestion documentaire qui classe automatiquement vos documents, sans configuration manuelle.
Testez-la dès maintenant avec 25 € de crédit offert et découvrez la classification documentaire sans effort.
Il est normal de se demander si la classification automatique des données est utile pour votre activité. Découvrez quelques-uns de ses avantages.
Les avantages de la classification des documents pour les entreprises
La classification automatique des documents permet à votre organisation de déployer plus facilement les processus opérationnels quotidiens. Voici quelques-uns des avantages de la mise en œuvre de cette pratique :
- Il permet à votre entreprise de gagner du temps et d’économiser des ressources : La classification automatique des documents permet d’organiser et d’analyser de grandes quantités de documents, ce qui se traduit par un gain de temps et de ressources financières considérable.
- Il vous aide à identifier les documents frauduleux : Classer les documents de manière automatique, c’est aussi identifier les documents frauduleux par le biais d’anomalies ou d’erreurs humaines présentes dans ces dossiers. L’automatisation permet donc de réduire la fraude documentaire au sein de votre organisation, comme la fraude à la facture.
- Il permet d’automatiser le tri des documents : Le classement manuel des documents peut facilement prêter à confusion et vous faire douter du label à leur attribuer, ce qui entraîne des erreurs et une prise de décision imprécise. La classification automatique résout ce problème, en triant les documents sur la base de catégories prédéterminées par vous et votre équipe.
Ces avantages peuvent sembler insignifiants au départ, mais ils peuvent faire une grande différence dans la manière dont vous menez vos activités. Pour mieux comprendre cette question et avoir une vue d’ensemble, examinons quelques cas concrets d’utilisation de la classification automatique des documents.
Cas d’utilisation réels et applications de classification des documents
Il ne suffit pas de connaître la théorie qui sous-tend la classification des documents pour en comprendre l’utilisation. Nous allons vous présenter quelques cas d’utilisation où la classification automatisée des documents a un impact positif sur votre entreprise :
Détection du spam dans les e-mails
La classification automatisée des documents permet d’identifier les courriels qui entrent dans la catégorie des spams. Ils contiennent généralement un texte à la sonorité peu naturelle, des erreurs de grammaire ou des fautes d’orthographe, qui éveillent les soupçons par rapport à des courriels normaux. Grâce à la classification des documents, les courriels qui répondent à ces critères sont récupérés dans la boîte de réception des spams correspondante, ce qui permet à votre entreprise d’éviter les liens dangereux ou la correspondance non sollicitée.
Traitement du retour d’information des clients
En analysant la sémantique et le ton du texte, ce qui, comme nous l’avons découvert, se fait à l’aide de la NLP, vous pouvez séparer les commentaires positifs des commentaires constructifs. Par conséquent, votre organisation bénéficie d’un meilleur accès aux suggestions visant à améliorer les processus commerciaux, ce qui vous aide à fournir de meilleurs services à vos clients.
Faciliter l’assistance à la clientèle
Grâce à la classification des documents, les employés du service clientèle peuvent facilement séparer les réclamations, les remboursements, les demandes de renseignements ou d’autres commentaires, en fonction du texte. L’efficacité du flux de travail s’en trouve améliorée, car les commentaires correspondants sont envoyés aux services désignés.
Numérisation des documents
Votre entreprise traite peut-être plusieurs types de documents, par exemple des factures, des reçus ou des contrats. L’utilisation d’un logiciel de numérisation de documents pour scanner le document, le numériser et l’étiqueter par le biais d’une classification, rationalisera considérablement vos processus.
Votre entreprise mérite un logiciel qui rend possible tous les cas d’utilisation décrits ci-dessus, et plus encore. C’est le cas de Klippa DocHorizon, qui vous aide à automatiser n’importe quel flux de traitement de documents, y compris la classification des documents, offrant à votre organisation les avantages sur le long terme.
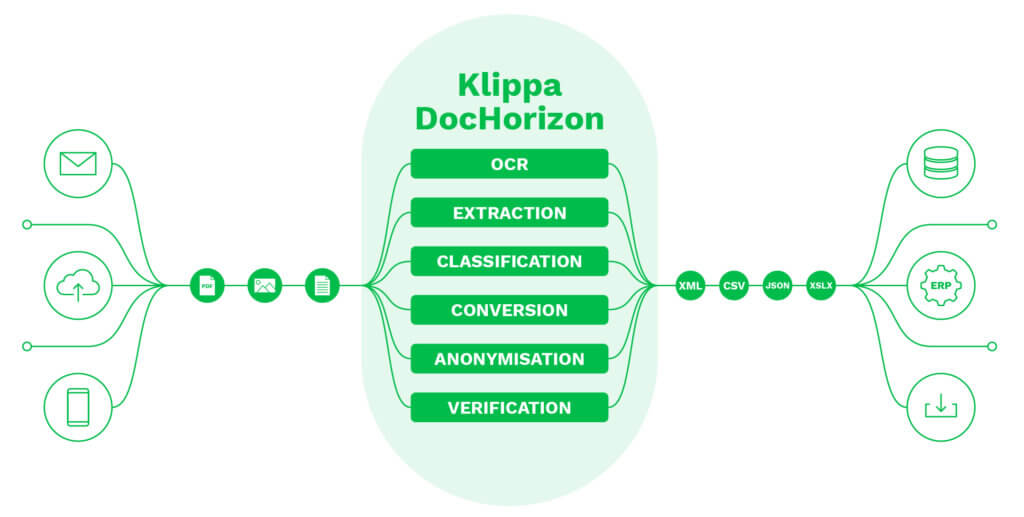
Allez plus loin que la simple classification automatique de documents avec Klippa
Klippa Dochorizon est une solution intelligente de traitement des documents alimentée par l’IA, visant à rationaliser les opérations commerciales quotidiennes à grande échelle. Elle vous permet non seulement d’obtenir une classification précise des documents, mais aussi d’aider votre entreprise dans d’autres domaines :
- Extraction de champs de données à partir d’une multitude de types de documents à l’aide d’une reconnaissance de caractères de haute précision
- Anonymisation automatique des données et des images pour une conformité maximale aux réglementations en matière de protection de la vie privée
- Conversion des documents au format souhaité, tel que CSV, XML, JSON ou PDF
- Bénéficier d’une intégration fluide avec les solutions logicielles existantes via SDK ou API
- Prévenir la fraude au sein de votre organisation grâce à la vérification automatisée des documents
- Classifier et catégoriser une multitude de types de documents
- Traiter les documents en fonction de champs de données spécifiques
Avec Klippa DocHorizon, votre entreprise est prête pour le succès. Si vous souhaitez en savoir plus sur notre produit, contactez nos experts ou réservez une démonstration ci-dessous !
FAQ
Si votre entreprise traite quotidiennement de grands volumes de documents et rencontre des difficultés avec l’organisation manuelle, les fichiers perdus ou la récupération lente, la classification automatique de documents peut faire gagner du temps, réduire les erreurs et améliorer la conformité.
Oui, de nombreux outils de classification basés sur l’IA prennent en charge le traitement multilingue des documents, y compris des fonctions d’OCR et de NLP pour extraire et analyser du texte dans différentes langues.
De nombreux systèmes de classification alimentés par l’IA, comme Klippa, proposent la rédaction et l’anonymisation automatiques, garantissant la conformité en matière de confidentialité et la sécurité des données sans intervention manuelle.
Vous pouvez tester des logiciels de classification basés sur l’IA avec un essai gratuit ou des solutions pré-entraînées comme Klippa DocHorizon, qui offre 25 € de crédit gratuit pour commencer.
Oui, Klippa DocHorizon est entièrement conforme au RGPD et respecte des réglementations strictes en matière de sécurité et de confidentialité des données, notamment les normes ISO 27001, HIPAA et SOC 2. Vos documents sont traités de manière sécurisée, avec chiffrement et contrôle d’accès.
Absolument ! Klippa DocHorizon propose plus de 50 intégrations ainsi qu’un support API et SDK complet, ce qui facilite la connexion avec les outils ERP, CRM, de stockage cloud, de comptabilité et d’automatisation des workflows.