
Documents papier, e-mails, photos, fichiers PDF… Alors que la prise de décisions fondée sur les données devient la nouvelle norme, il est essentiel de trouver un moyen efficace de gérer des sources de données variées.
Vous savez probablement combien il serait long (et coûteux !) de devoir vérifier chaque fichier à la main et de saisir toutes les données, sans parler de la nécessité de corriger les erreurs de saisie ou de régler les conséquences de la fraude documentaire non détectée.
Il n’est donc pas surprenant que, selon l’enquête SER IDP 2025, 78 % des entreprises utilisent déjà l’IA dans leurs projets IDP – un saut considérable par rapport à l’année précédente. Le traitement intelligent des documents (IDP) automatise la gestion des documents, vous aidant à transformer vos sources de données en informations exploitables avec rapidité, précision et justesse.
Continuez à lire pour découvrir tout ce qu’il faut savoir sur le traitement intelligent des documents et découvrez comment cela peut transformer votre flux de travail documentaire.
Points clés :
- Le Traitement Intelligent des Documents (IDP) automatise la capture, l’extraction, la classification, la vérification et l’intégration des données issues de documents papier, PDF, images, e-mails ou photos.
- L’IDP transforme les données non structurées en formats exploitables (CSV, JSON, XML), intégrables directement dans les systèmes ERP ou bases de données.
- Les solutions IDP offrent des gains majeurs : productivité accrue, réduction du temps de traitement de 90 %, précision d’extraction allant jusqu’à 99 %, meilleure qualité des données, et réduction des coûts de plus de 80 %.
- Les technologies clés incluent : OCR, IA, Machine Learning, Vision par ordinateur, Traitement du langage naturel (NLP) et RPA.
- Les cas d’usage couvrent de nombreux secteurs : santé, finance, marketing, logistique, juridique et RH.
- L’IDP contribue à la conformité réglementaire (RGPD, HIPAA) grâce au masquage automatique des données sensibles et à la détection de fraude.
- La solution Doxis AI.dp propose une implémentation rapide, accessible via API/SDK, et adaptée aux documents multisources et multiformats.
Qu’est-ce que le traitement intelligent des documents (IDP)?
Avez-vous déjà vu une technologie sophistiquée capable de comprendre l’objet d’un document, les informations qu’il contient, d’extraire ces informations et de les transmettre là où elles sont nécessaires (par exemple, une base de données ou un système ERP)? C’est ce que l’on appelle le traitement intelligent des documents ou IDP.
L’IDP est une forme d’automatisation intelligente des documents qui s’appuie sur la science des données pour aider les machines à comprendre les données non structurées et à les transmettre sous forme de données structurées. Les formes de données structurées comprennent souvent les formats CSV, JSON et XLSM qui peuvent être envoyés aux systèmes ERP par exemple.
Les 8 avantages du traitement intelligent des documents
L’automatisation intelligente des documents avec les solutions IDP peut s’avérer très efficace pour rendre les processus liés aux documents plus performants. Il existe un certain nombre d’avantages que vous pouvez rechercher:
Augmentation de la productivité de six heures par semaine
Selon Smartsheet, près de 60% des travailleurs interrogés ont estimé que l’automatisation des tâches répétitives leur permettrait de gagner six heures ou plus par semaine (presque une journée de travail complète). C’est là que l’IDP entre en jeu.
L’IDP peut automatiser une variété de tâches telles que la saisie manuelle de données ou la vérification de documents. D’un simple clic, il capture, convertit, catégorise, vérifie et transmet les données au bon point d’accès. Ce faisant, vous pouvez augmenter la productivité de votre personnel.
Réduction du temps de traitement de 90%
Disons qu’un employé a besoin en moyenne de deux minutes pour trier un document et en extraire les données. Une solution IDP peut le faire en 10 secondes. Cela représente une réduction de temps de plus de 90%.
La rapidité avec laquelle les solutions IDP traitent de grands volumes de données est l’un des avantages les plus notables de leur utilisation.
Précision d’extraction des données pouvant atteindre 99%
Les tâches fastidieuses telles que la saisie manuelle de données sont sujettes à des erreurs. En général, les personnes ne sont pas précises à plus de 95%. Avec des volumes plus importants, chaque pourcentage d’erreurs commises peut facilement coûter des milliers d’euros, grugeant ainsi vos résultats.
En comparaison, une solution IDP peut vous aider à atteindre une précision d’extraction des données de plus de 99% sans augmenter vos frais généraux.
Accès facile aux données grâce à la numérisation
Recevoir des documents et les convertir au format numérique n’est pas un problème, qu’ils soient structurés ou non. IDP peut facilement convertir n’importe quel document en un format lisible par machine, accessible aux parties et aux systèmes prévus.
En outre, il peut catégoriser, trier et acheminer les documents vers le service et la plate-forme appropriés. Ce qui est génial, c’est que vous n’avez plus besoin de vous occuper d’un énorme arriéré de documents papier.
Amélioration de la sécurité et de la conformité
Un autre avantage majeur du traitement intelligent des documents est qu’il aide les entreprises à améliorer leur conformité réglementaire. Comment?
Il définit des champs de données sensibles, tels que les champs contenant des informations personnelles identifiables (PII), et utilise le masquage des données pour les supprimer ou les rendre anonymes. Cela aide les entreprises à garantir la conformité avec les réglementations relatives à la confidentialité des données, comme la RGPD ou l’HIPAA.
À côté de cela, les solutions IDP utilisent diverses techniques pour détecter les fraudes, ce qui peut être utile pour les contrôles de connaissance du client (KYC) et de lutte contre le blanchiment d’argent (AML) dans le secteur financier.
Évolutivité pour la croissance de l’entreprise
Les solutions de traitement intelligent des documents permettent aux entreprises de traiter de gros volumes de documents à une vitesse impossible à reproduire par un humain. Elles le font sans augmenter les coûts.
Lorsque votre entreprise se développe et que le volume de documents augmente, l’IDP veille à ce que vous n’ayez pas besoin d’embaucher plus de personnel ou de dépenser plus d’argent.
Réduction des coûts de plus de 80% pour un résultat net plus optimisé
Les entreprises ont parfois du mal à maintenir leurs coûts opérationnels à un faible niveau. Cela nous amène à l’un des principaux avantages de l’IDP, à savoir la réduction des coûts.
En moyenne, le tri manuel d’un document et la saisie des données dans un système peuvent coûter entre 4 et 6 euros par document. Avec la RPA, le coût par document peut être réduit à 1-2€ et la PDI à moins de 0,50€.
Cela représente une réduction des coûts de plus de 80% par rapport au traitement manuel. En général, plus vous traitez de documents, plus vous économisez de l’argent.
Amélioration de la qualité des données
Étant donné que 80% des données d’entreprise se présentent sous des formats non structurés, la qualité et la convivialité des données ne sont pas une mince affaire pour beaucoup. C’est exactement là que le traitement intelligent des documents excelle.
Il n’est pas limité par le type de document. En fait, il peut traiter et extraire des données de documents structurés et non structurés, pour autant que les modèles d’IA aient été formés correctement.
Une fois les données extraites, elles sont converties en une sortie lisible par une machine. Comme il peut être configuré pour n’extraire que les données pertinentes, vous n’avez pas à vous soucier de savoir si les données sont bien organisées ou non. Ainsi, l’IDP améliore la qualité et la convivialité des données.
Maintenant que nous avons couvert les principaux avantages du traitement intelligent des documents, examinons certains de ses cas d’utilisation.
Quelles sont les technologies utilisées en IDP ?
Le traitement intelligent des documents automatise simplement les flux de travail de traitement des documents, en utilisant divers composants technologiques.
Reconnaissance optique de caractères (OCR)
La reconnaissance optique de caractères (OCR) est une technologie extrayant les données telles que du texte à partir d’images ou de documents numérisés grâce à sa capacité à identifier des caractères individuels. Elle convertit également le texte extrait en une sortie lisible par une machine (MRZ), telle que JSON. Ce sont les tâches de l’OCR dans une solution IDP.
Intelligence artificielle (IA)
L’IA extrait le sens des images et documents, détecte à la fois les motifs récurrents et les anomalies, puis formule des prédictions à partir d’algorithmes.
Par exemple, ses capacités sont essentielles dans la détection de fraude : elle peut être programmée pour signaler des montants inhabituellement élevés, repérer des signes de falsification de documents ou identifier des incohérences dans les totaux des factures.
Vision par ordinateur
La vision par ordinateur est une forme d’IA axée sur le deep learning permettant aux ordinateurs de comprendre des informations significatives à partir d’images numériques, de vidéos et d’autres contenus visuels. Dans une solution IDP, la vision par ordinateur lui permet de voir, d’observer et de comprendre les objets. Par exemple, la vision par ordinateur peut reconnaître des objets tels que des étiquettes de prix, des canettes de soda, des plaques d’immatriculation, des compteurs électriques, etc.
Machine Learning (ML)
Le Machine Learning est une branche de l’intelligence artificielle (IA), utilisant des algorithmes et fournissant des données à un ordinateur pour l’aider à apprendre comment s’améliorer dans une tâche.
Traitement du langage naturel (NLP)
Le traitement du langage naturel (NLP) est également une composante de l’intelligence artificielle, visant à permettre aux ordinateurs de comprendre le sens complet d’un texte ou de mots parlés de la même manière que les humains. Le NLP permet aux solutions IDP de comprendre les données plus rapidement et plus intelligemment.
L’une des techniques qu’elle utilise est la reconnaissance des entités nommées (NEM), qui consiste à identifier des mots ou des phrases dans des documents. Par exemple, le NLP permet à IDP de comprendre que « Jane » est le nom d’une femme et que « Amsterdam » est un lieu.
Automatisation des processus robotiques (RPA)
L’automatisation des processus robotiques (RPA) est l’automatisation des processus basés sur des règles à l’aide d’un logiciel qui utilise souvent une interface utilisateur. Dans ce type d’automatisation, le logiciel exécute des tâches qui sont codifiées par des ordinateurs, d’où le terme « robotique » ou « robots ».
Cette technologie est efficace lorsqu’elle traite des données structurées présentant peu ou pas de variations. Le rôle de la RPA dans une solution de traitement intelligent des documents est de capturer des informations à partir de sources structurées. Ce faisant, la RPA peut traiter une transaction ou communiquer avec d’autres systèmes numériques grâce à un ensemble de règles.
Maintenant que nous avons abordé les principales technologies qui sous-tendent le traitement intelligent des documents, examinons les différences entre les terminologies suivantes: IDP, OCR et RPA.
Comment fonctionne le traitement intelligent de documents et que peut-il faire?
Il est désormais clair que le traitement intelligent de documents est une évolution sophistiquée de l’OCR qui exploite l’intelligence artificielle pour automatiser les tâches dans les flux de travail liés aux documents. Mais que peut-il réellement faire? Examinons la liste des fonctions que le traitement intelligent de documents offre.
Capture de données
L’IDP permet de capturer des données provenant de diverses sources dans un système informatique pour un traitement ultérieur, souvent à l’aide d’un appareil mobile. Il peut être utilisé pour numériser et capturer les données de divers documents tels que des reçus, des factures, des cartes d’identité, des bons de commande et bien d’autres documents.
Extraction de données
À la réception de l’image numérisée ou capturée d’un document, l’IDP en extrait intelligemment les données pertinentes à l’aide d’algorithmes d’OCR et d’IA. Tous les types de données peuvent être extraits, y compris:
- Les données structurées – Les données qui sont organisées et ont une structure logique (par exemple CSV, JSON, XML).
- Données non structurées – Nécessitent une manipulation telle que le nettoyage des données avant le processus d’extraction des données, car elles n’ont pas toujours une structure logique que les machines peuvent lire (par exemple, les courriels, les images, les documents numérisés).
Plus les algorithmes sont raffinés, plus l’extraction des données est précise.
Classification
Après l’extraction des données, l’IDP utilise des algorithmes d’IA combinés au NLP pour identifier les types de documents en faisant correspondre les documents inconnus aux catégories existantes.
Les caractéristiques sont extraites et transmises aux algorithmes, qui calculent un score de similarité. Le score de similarité est utilisé pour déterminer la catégorie la plus précise pour la classification du document.
Anonymization
Quelques solutions de traitement intelligent des documents peuvent anonymiser automatiquement les informations sensibles des documents. Ce que cela implique, c’est la suppression ou le chiffrement des données sensibles, telles que les numéros de sécurité sociale pour la conformité à la RGPD et d’autres réglementations relatives à la vie privée.
Vérification
Après les étapes précédentes, l’IDP peut authentifier le document en le comparant aux registres et bases de données officiels. Cela permet d’éviter les tentatives de fraude nuisibles et de minimiser les risques de recevoir des documents fabriqués.
Livraison et intégration
Après la vérification du document, l’IDP livre la sortie lisible par machine à la destination souhaitée, qu’il s’agisse d’une base de données ou d’un système de planification des ressources de l’entreprise (ERP).
Cela dépend en grande partie des types d’intégration offerts par la solution de traitement intelligent des documents.
Maintenant que nous avons vu ce dont le traitement intelligent des documents est capable, examinons ses principaux avantages.
Quels sont les cas d’utilisation du traitement intelligent des documents?
Il existe une multitude d’applications pour le traitement intelligent des documents. Voyons maintenant les cas d’usage que nous rencontrons le plus souvent.
Santé
Dans le secteur de la santé, l’IDP est utilisé pour le traitement sécurisé des documents et la gestion des dossiers patients, ouvrant la voie aux contrôles d’identité et à la vérification automatisée. Les compagnies d’assurance santé peuvent également exploiter l’IDP pour automatiser le traitement des demandes de remboursement et vérifier leur validité en un temps record.
Finance
Qu’il s’agisse de vérifier des documents d’identité, une preuve de revenus ou de domicile pour l’automatisation des procédures KYC, ou de prendre en charge le traitement des factures dans le cadre de la comptabilité fournisseurs, l’IDP permet aux institutions financières et aux équipes comptables de détecter les incohérences et de prévenir les fraudes ainsi que les pénalités de non-conformité en vérifiant la précision des données extraites.
Analyse de marché
Dans une industrie fondée sur l’exploitation des données, le marketing peut tirer pleinement parti de l’IDP pour automatiser la validation des reçus dans le cadre de campagnes de fidélité, extraire des données produits à partir d’étiquettes pour réaliser des analyses de prix, ou encore traiter des cartes de menus afin d’optimiser l’offre ou ajuster les tarifs.
Logistique
L’IDP peut être déployé pour automatiser le traitement documentaire dans le secteur transport et logistique par exemple lié à la gestion des commandes. En extrayant les données des factures, bons de commande et bordereaux de livraison, il permet de réaliser un rapprochement à trois volets et de marquer une commande comme complète dès que tous les documents ont été traités. Cette automatisation assure une tenue rigoureuse des registres et une gestion fluide des opérations logistiques.
Juridique et ressources humaines
Grâce à l’IDP, les professionnels du droit et des ressources humaines peuvent extraire automatiquement toutes les informations pertinentes pour un dossier juridique ou garantir un recrutement rigoureux grâce à l’analyse intelligente de CV et aux contrôles Know Your Employee.
Si vous pensez que votre entreprise peut bénéficier de ces avantages, Doxis AI.dp est là pour vous. Nous avons à cœur de vous offrir des solutions de traitement documentaire efficaces et sécurisées, adaptées à vos besoins spécifiques.
Automatisation intelligente des documents avec Doxis AI.dp
En conclusion, si votre entreprise ne traite qu’un petit nombre ou une faible variété de documents, alors peut-être que la RPA est une meilleure solution pour commencer. Souvent, la RPA a besoin d’intelligence, surtout lorsque vous traitez des documents dans plusieurs langues, formats et structures. Pour cela, vous avez besoin d’un traitement intelligent des documents.
C’est pourquoi, chez Doxis, nous pouvons en toute confiance automatiser vos flux de documents à l’échelle avec notre solution IDP alimentée par l’IA, AI.dp. Cette solution vous permettra de passer au niveau supérieur en matière d’extraction de données, de classification, de conversion de documents, de masquage et de vérification.
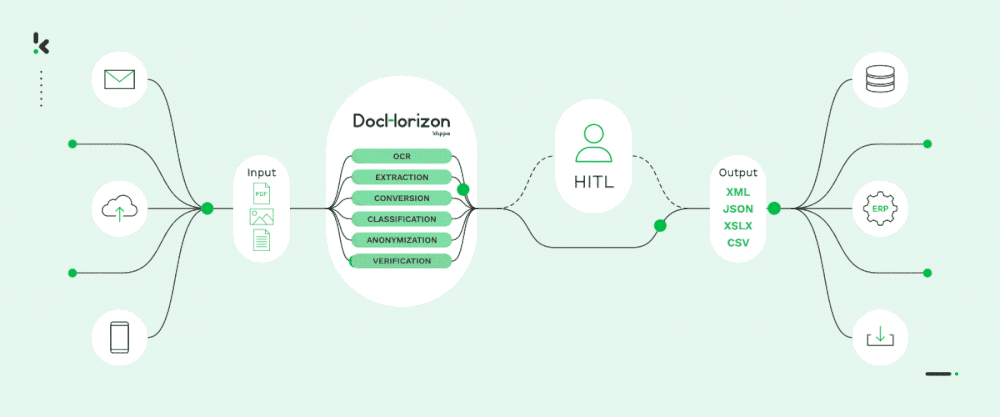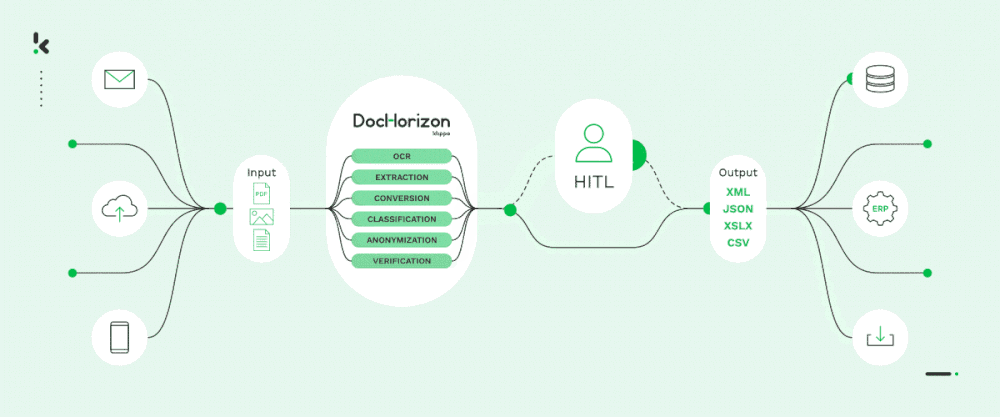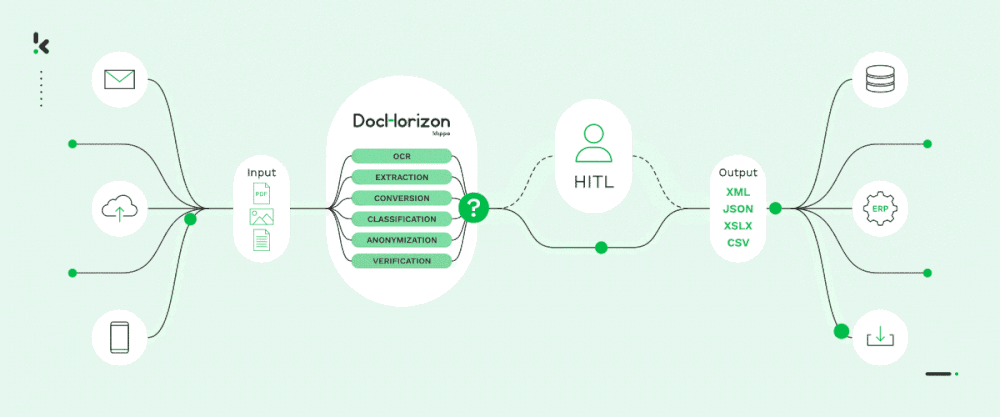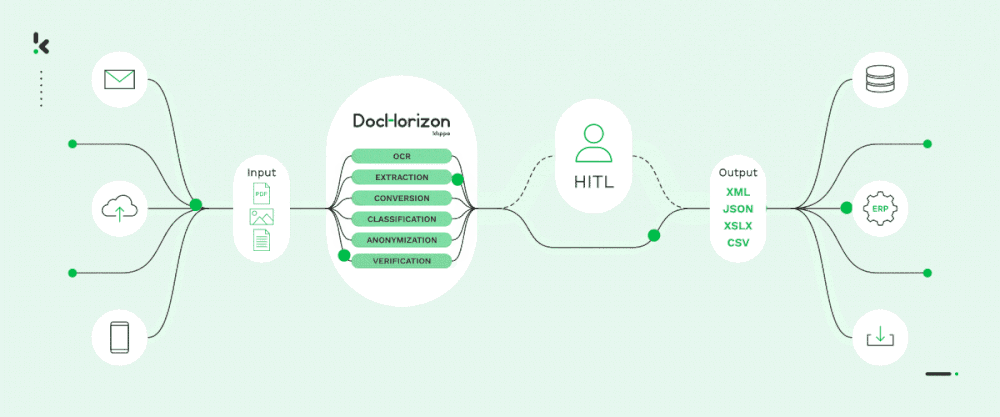
Notre solution intelligente est souvent utilisée comme colonne vertébrale de l’automatisation du traitement des documents à plus grande échelle. Elle est accessible via une API et un SDK. Avec notre équipe d’accueil et une documentation bien structurée, il ne vous faudra pas plus d’une journée pour démarrer!
Nous vous recommandons de réserver une démonstration ci-dessous pour commencer votre voyage et devenir un champion du traitement des documents!
FAQ
Le traitement intelligent des documents (Intelligent Document Processing) est une technologie qui utilise l’IA et l’OCR pour automatiser la transformation de données contenues dans tous types de documents vers un format exploitable et intégré dans vos systèmes métiers.
– OCR : lit et transforme le texte des images ou PDF en données exploitables.
– RPA : automatise des tâches répétitives basées sur des règles mais ne comprend pas le contenu.
– IDP : combine OCR, IA, NLP et autres technologies pour comprendre, extraire, vérifier et traiter les documents de manière intelligente.
Factures, justificatifs, contrats, pièces d’identité, bons de commande, reçus, e-mails, formulaires, cartes de menus, ou tout autre format structuré ou non structuré.
Oui. L’IDP identifie et masque automatiquement les informations sensibles (PII) et aide à respecter des réglementations telles que le RGPD et HIPAA. Il peut aussi intégrer des algorithmes de détection de fraude.
La santé, la finance, le marketing, la logistique, le juridique et les ressources humaines sont parmi les secteurs qui tirent le plus grand profit de l’IDP, grâce à l’automatisation de tâches documentaires complexes.
Oui. Avec le bon entraînement des modèles d’IA et l’utilisation d’un OCR multilingue, l’IDP peut traiter et extraire des données dans plusieurs langues et alphabets.