
L’adoption de l’intelligence artificielle (IA) connaît une croissance rapide. Selon une enquête de McKinsey, l’adoption de l’IA a augmenté de 50 % entre 2020 et 2021. En outre, l’utilisation de l’IA a eu un impact significatif sur les résultats des entreprises interrogées, avec une augmentation de 22 % des bénéfices par rapport à l’année précédente.
Faites-vous partie des entreprises utilisant déjà l’IA pour automatiser les flux de travail ? Si oui, c’est formidable ! Il existe un grand nombre de technologies géniales qui permettent d’automatiser de nombreuses tâches fastidieuses, sujettes aux erreurs et répétitives.
Toutefois, l’utilisation de ces technologies seules ne permet pas toujours de résoudre toutes les pièces du puzzle. Cela ne signifie certainement pas que vous devez vous débarrasser complètement de l’aspect humain.
Prenons l’exemple de l’extraction de données. Même avec la technologie la plus avancée, il est pratiquement impossible d’extraire des données de documents avec une précision de 100 % en permanence. Dans certains secteurs, 1% d’erreurs d’extraction de données peut déjà coûter des millions d’euros à votre entreprise.
C’est pourquoi, dans de nombreux cas, la combinaison du meilleur de l’humain et du meilleur de l’intelligence artificielle peut donner les meilleurs résultats. Une telle approche est appelée l’automatisation Human-In-The-Loop (HITL), dont nous parlerons en détail dans ce blog.
Nous vous invitons donc à rester avec nous jusqu’à la fin (ou à passer directement aux bénéfits si vous savez déjà ce qu’est l’HITL).
Point Clés :
- L’IA n’est pas parfaite, et c’est normal. Le HITL (Humans In The Loop) permet de corriger ce que l’automatisation seule peut manquer, surtout avec des données complexes, désordonnées ou à enjeux élevés.
- Vous pouvez commencer petit ou évoluer à grande échelle. Que vous formiez un modèle depuis zéro ou validiez des résultats, le HITL fonctionne à chaque étape de l’automatisation.
- Vous avez des options de configuration flexibles. Choisissez entre un HITL géré en interne ou en externe, en fonction de vos ressources et de vos besoins en matière de confidentialité des données.
- Les cas d’utilisation sont nombreux. De la gestion des factures à la vérification KYC, le HITL apporte de la valeur là où la précision est cruciale.
Pour vous aider à choisir le flux de travail qui vous convient, nous avons inclus ci-dessous un tableau comparatif montrant comment les processus manuels, automatisés et alimentés par HITL se comparent.

Flux de travail automatisés ou manuels
L’automatisation de divers flux de travail apporte aux entreprises une efficacité opérationnelle qui n’est pas toujours réalisable avec des flux de travail manuels ; elle permet de gagner du temps, de minimiser les erreurs et de réduire les frais généraux. De nombreuses tâches manuelles sont souvent répétitives, longues et sujettes aux erreurs, ce qui entraîne des frais généraux inutiles.
Prenons l’exemple d’une entreprise qui doit traiter un grand nombre de documents. Un document doit être vérifié ; le personnel de back-office doit scanner le document pour le numériser en vue de sa conservation ; ensuite, le préposé à la saisie des données doit extraire et saisir les données dans le système souhaité ; une autre personne doit valider que les données ont été saisies correctement, etc.
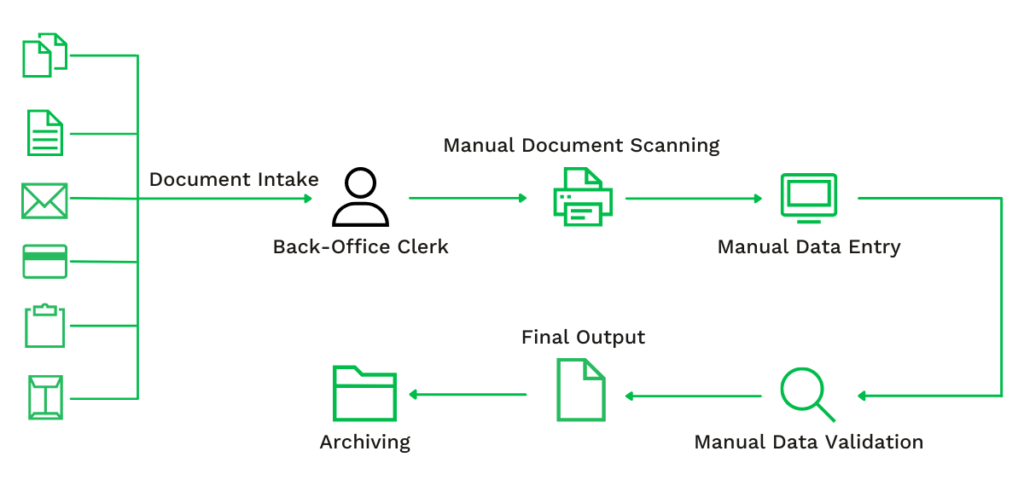
Ce flux de travail manuel peut donner lieu à de nombreuses erreurs et n’est tout simplement pas évolutif. C’est pourquoi les entreprises recherchent souvent des solutions pour automatiser ces types de flux de documents.
Par exemple, des solutions comme le traitement intelligent de document (IDP) peuvent facilement éliminer les tâches manuelles en automatisant l’extraction des données, la conversion des catégories et la validation.
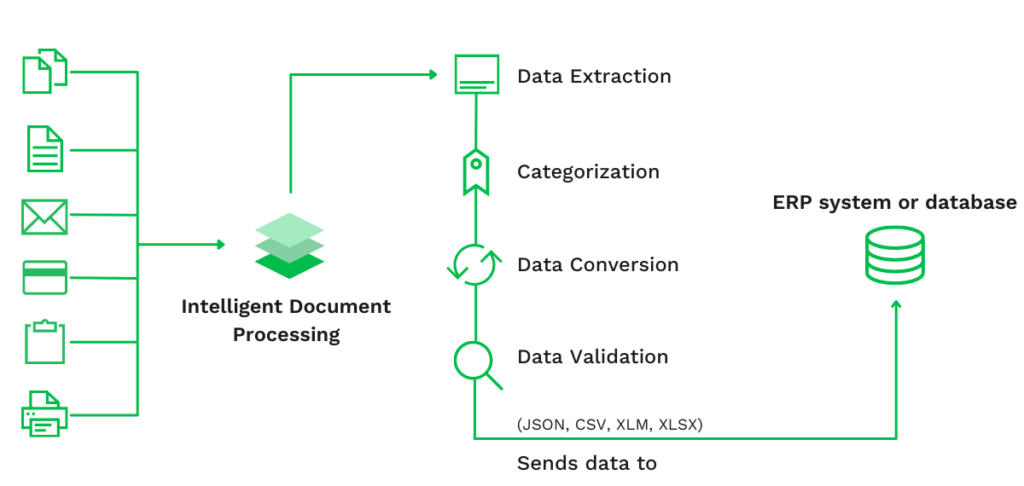
Bien que l’automatisation des flux de travail manuels à l’aide du seul IDP semble être une excellente idée, il existe des limites que même l’IA et les machines ne sont pas encore en mesure de résoudre.
Par exemple, les machines seules ne peuvent pas faire face à des flux de travail compliqués et à des entrées de données de mauvaise qualité. Au pire, elles risquent de ronger les résultats de votre organisation.
Imaginez un scénario dans lequel les machines extraient automatiquement les données d’une facture et saisissent 100 000 € dans un système au lieu de 10 000 €. Cela pourrait entraîner une perte financière importante si vous ne disposez d’aucune mesure de protection pour l’empêcher.
Souvent, ce seul fait rend les solutions entièrement automatisées fragiles.
Heureusement, l’implication humaine peut surmonter ce défi et vous aider à atteindre la plus grande précision et les meilleurs résultats possibles. Ainsi, de nombreuses organisations ont adopté l’automatisation par l’homme dans la boucle, aussi appelé Human-in-the-loop.
Mais qu’entendons-nous exactement par automatisation par l’homme dans la boucle ? Continuez à lire et vous trouverez la réponse dans les sections suivantes.
Qu’est-ce que Human-in-the-loop ?
Souvent, le terme « human-in-the-loop » (HITL) désigne un mécanisme qui tire parti de l’interaction humaine pour former, affiner ou tester certains systèmes tels que des modèles d’IA ou des machines afin d’obtenir les résultats les plus précis possibles.
Prenons l’exemple du flux de travail dans les supermarchés. Même si de nombreux supermarchés sont équipés de lecteurs automatiques, il y a souvent un employé (humain dans la boucle) qui se trouve à proximité de ces machines.
L’employé est placé là pour s’assurer que les clients obtiennent de l’aide en cas de besoin et pour valider que les produits ont été correctement scannés afin d’éviter les tentatives de fraude ou de vol.
L’utilisation de machines à scanner automatique permet de réduire les files d’attente et le nombre d’employés que les supermarchés doivent employer. Cependant, les machines ne sont pas suffisamment performantes pour être totalement autonome.
C’est pourquoi l’approche Human-in-the-loop est la plus efficace dans ce type de situation.
Examinons maintenant l’automatisation de Human-in-the-loop avec des solutions d’IA.
Human-in-the-loop et Intelligence Artificielle
Même si les technologies modernes sont avancées, elles ne sont pas parfaites. Elles ne pourront peut-être jamais être « parfaites », car les objectifs, besoins et demandes évoluent avec le temps. C’est pourquoi l’automatisation par Human-in-the-loop est si essentielle pour obtenir les meilleurs résultats possibles.
Alors comment fonctionne le HITL dans le contexte de l’IA ? Grâce à la méthode « human-in-the-loop », vous pouvez former des modèles d’IA pour qu’ils deviennent plus précis dans l’identification, la classification et la prédiction d’un objet.
Supposons que vous souhaitiez entraîner des algorithmes d’IA à reconnaître des formes (par exemple, un carré, un cercle, un triangle), vous auriez besoin d’un humain pour étiqueter correctement les images de ces formes.
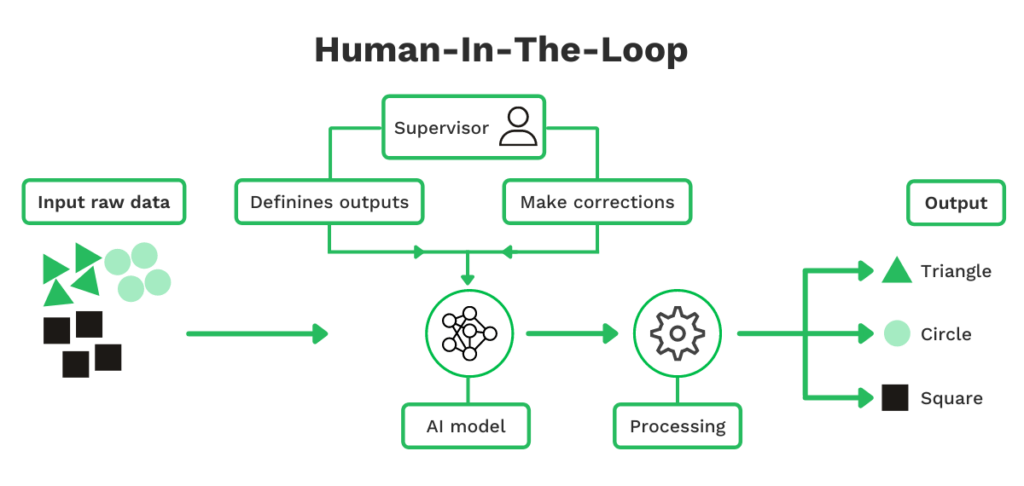
Lorsque l’IA se trompe dans une prédiction ou une identification, l’humain dans la boucle est là pour apporter les corrections. C’est ce qu’on appelle une boucle de rétroaction qui contribue à améliorer la précision des modèles d’IA.
En général, les modèles d’IA ne peuvent pas constamment faire des prédictions avec un niveau de confiance de 100 %.
Le même défi s’applique à l’extraction des données. De nombreux logiciels OCR prêts à l’emploi peuvent extraire des données avec une précision de 97 % (99 % dans de rares cas) dans le meilleur des cas, mais la précision moyenne d’extraction des données se situe toujours autour de 80 % pour la plupart des solutions.
Dans la plupart des cas, cela laisse 20% des données inexactes, ce qui peut devenir un problème dévastateur pour votre organisation, même si elle peut automatiser la plupart du travail de saisie manuelle des données.
Heureusement, l’intelligence humaine peut facilement combler cette lacune.
L’Human-in-the-loop permet d’identifier rapidement les problèmes et les améliorations grâce à une boucle de rétroaction, que l’on peut appeler annotation HITL. Sans cela, les erreurs et les fautes sont difficiles à détecter.
Nous allons examiner ce processus plus en détail ci-dessous.
L’annotation de l’Human-in-the-loop
L’annotation de l’Human-in-the-loop ou l’étiquetage des données fait souvent partie du processus de développement des modèles d’IA.
Les modèles d’IA ont besoin de grands volumes de données brutes (par exemple, des documents, des images, des fichiers texte et d’autres objets) pour identifier les objets et faire des prédictions avec précision.
L’annotation, la constitution de jeux de données et la collecte de données exigent beaucoup de temps, d’argent et d’efforts.
Alors comment cela fonctionne-t-il ? Un annotateur de données, human-in-the-loop, étiquette les ensembles de données qui permettent aux modèles d’IA de se concentrer sur des champs de données spécifiques de manière répétée jusqu’à ce qu’ils puissent reconnaître de manière optimale et faire les meilleures prédictions.
Par exemple, si votre organisation souhaite que le modèle d’IA reconnaisse et extraie les postes des reçus, vous devrez peut-être alimenter le modèle avec des milliers de reçus étiquetés pour obtenir des résultats satisfaisants.
Pour disposer d’un ensemble de données étiquetées afin d’entraîner les modèles d’IA, vous devrez collecter des données brutes et mettre en place une équipe d’experts pour l’annotation.
Alors pourquoi préférer l’automatisation de l’HITL, alors qu’il existe des solutions qui peuvent vous permettre d’atteindre une précision de 97 % ?
Vous trouverez les réponses à cette question dans la section suivante.
Les avantages de l’automatisation de l’HITL
Pourquoi avons-nous encore besoin de l’intervention humaine ? Tout simplement parce qu’il existe encore des cas où les solutions entièrement automatisées présentent les mêmes défauts que les solutions manuelles. Nous savons tous que l’erreur zéro est impossible. Cela vaut aussi bien pour les flux de travail manuels que pour les flux entièrement automatisés.
Par rapport à l’IA, le cerveau humain fonctionne très bien dans les situations où les données ou les informations sont limitées. Par exemple, si nous observons la queue d’un tigre, cette information est suffisante pour nous permettre d’identifier s’il s’agit d’un tigre ou non.
Cependant, ce n’est pas le cas des machines, car elles ont besoin d’un développement important pour y parvenir. C’est pourquoi l’automatisation avec Human-in-the-loop est utilisée pour combler cette lacune.
L’utilisation de l’HITL pour former des modèles d’IA ou améliorer les flux de travail présente divers avantages :
- L’utilisation de l’HITL augmente la précision de la prédiction, de l’extraction, de la classification et de la validation, ainsi que la qualité des résultats.
- Les machines peuvent être entraînées à comprendre des données complexes qu’elles n’ont pas encore rencontrées.
- Les algorithmes peuvent être progressivement améliorés grâce à l’apport humain.
- N’est pas limitée par la qualité des données sur lesquelles les modèles d’IA sont entraînés.
- Permet aux développeurs de gagner un temps précieux.
- Peut traiter des ensembles de données incomplets et difficiles de manière plus efficace.
Cependant, il faut également garder à l’esprit certaines limites, que nous abordons ci-après.
Limites de l’approche HITL
Même si l’automatisation par l’homme dans la boucle combine le meilleur de l’intelligence humaine et de l’intelligence artificielle, elle présente certaines limites. Ces limites sont les suivantes :
- Identification de Human-in-the-loop – Les organisations doivent identifier qui va interagir avec quelle interface et quelle section dans la boucle d’automatisation.
- Les grands volumes de données – Le HITL ne s’adapte pas toujours bien aux grands volumes de données, car il faut davantage d’humains inclus dans la boucle d’automatisation.
- Évolutivité limitée – Lorsqu’un humain est impliqué dans un processus, l’évolutivité peut devenir un problème.
Ces limitations sont encore mineures par rapport à celles des flux de travail manuels ou entièrement automatisés. Tant que vous êtes conscient de ces problèmes et que vous y répondez correctement, l’efficacité de l’HITL n’est pas réduite à néant.
L’humain au début ou à la fin d’une boucle ?
Vous ne savez pas quand utiliser Human-in-the-loop dans vos flux de travail ? Pas de problème. Nous avons tout ce qu’il vous faut. D’après notre expérience, il est plus judicieux d’avoir un humain dans la boucle au début ou à la fin d’une boucle. Examinons les options suivantes :
- HITL au début d’une boucle
- HITL au début d’une boucle
HITL au début d’une boucle
Dans les cas où il n’existe pas de solution prête à l’emploi, vous devriez envisager d’utiliser l’approche HITL et d’intégrer un humain au début de la boucle. Pourquoi ?
Disons que vous ne disposez actuellement d’aucun modèle ou algorithme d’IA pour automatiser certains processus, mais que vous avez beaucoup de données brutes.
Avec ces données brutes, vous pouvez créer des données étiquetées avec un humain inclu dans la boucle, qui s’assure que les données sont nettoyées (les données inexactes sont supprimées ou corrigées) et étiquetées correctement.
Une fois les données étiquetées, vous pouvez les utiliser pour entraîner vos propres modèles d’IA à reconnaître les factures ou même à en extraire des données.
Par exemple, si vous avez des tonnes de factures différentes, vous pouvez étiqueter ces données pour entraîner des modèles d’IA à reconnaître les factures.
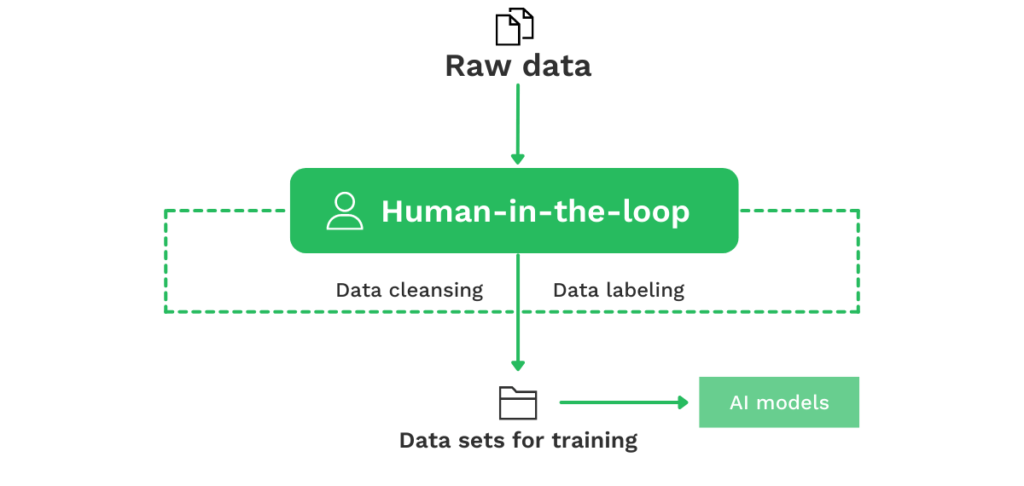
Une telle approche vous permet de partir de 0% d’automatisation et d’évoluer vers +80% d’automatisation. Dans quelles situations devriez-vous envisager de placer un humain au début d’une boucle ?
- Vous voulez construire vos ensembles de données
- Vous voulez créer vos propres modèles d’IA
- Vous n’avez pas ou peu d’automatisation en place, mais vous souhaitez évoluer vers une automatisation de +80%
- Vous disposez en interne d’annotateurs de données et d’experts en intelligence artificielle.
HITL à la fin d’une boucle
L’utilisation de l’humain en fin de boucle est plus courante dans de nombreux cas. Cette approche tire parti de l’automatisation pour effectuer les tâches répétitives et de l’intelligence humaine pour s’assurer que tout fonctionne correctement.
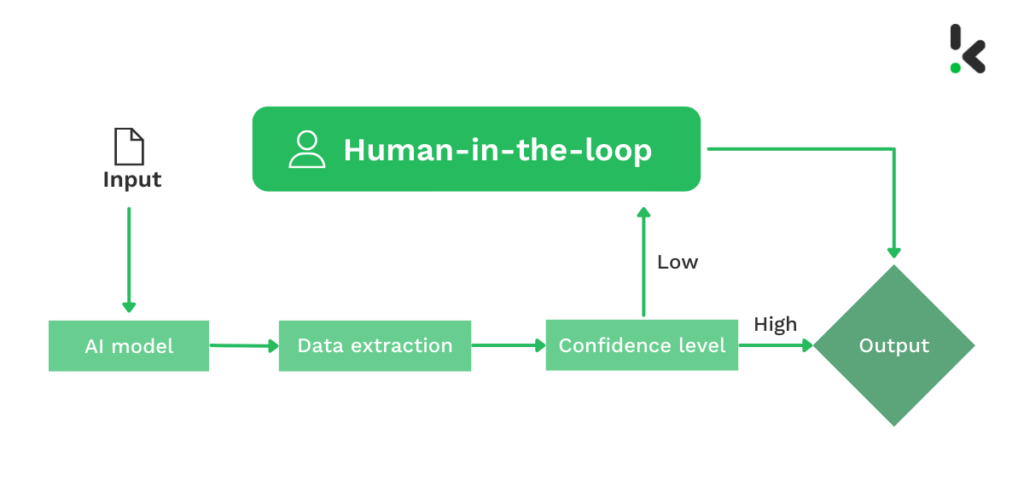
Nous constatons souvent que 80 % du flux de travail est automatisé et que 20 % reste à la charge des humains. Quand choisissez-vous cette approche plutôt que la précédente ?
- Vous voulez atteindre une précision aussi proche de 100 % que possible (extraction de données, prédiction, vérification, anonymisation, etc.)
- Vous voulez diminuer le besoin d’intervention humaine de 20% pour réduire les frais généraux.
- Vous voulez minimiser les erreurs coûteuses (c.-à-d., données inexactes, entrées en double, etc.)
- Vous cherchez à améliorer les délais d’exécution tout en maintenant une grande précision
- Il existe des solutions sur le marché automatisant la plupart des tâches pour vous avec une grande précision.
Pour vous montrer davantage la différence entre un humain au début et à la fin de la boucle, nous avons choisi deux exemples concrets.
Human-in-the-loop : examples
De nombreuses marques reconnues utilisent l’automatisation HITL pour améliorer leurs systèmes. Ci-dessous, nous vous présentons quelques exemples d’humain dans la boucle en action.
Dans le cas de Facebook, le HITL est utilisé de manière créative pour améliorer son algorithme DeepFace, qui peut atteindre une précision de 97,35 %. Pour ce faire, Facebook permet à ses utilisateurs de procéder à la reconnaissance faciale des photos en les confirmant ou en les rejetant. Les utilisateurs finaux sont les humains dans la boucle (début d’une boucle) et contribuent à améliorer l’algorithme (en annotant).
Une autre grande marque, Coca-Cola, a créé un programme de fidélité, MyCokeRewards, qui a utilisé une stratégie de l’Human-in-the-loop pour en faire un succès. Coca-Cola a créé une application intégrant la technologie de Reconnaissance Optique de Caractères (OCR).
Grâce à cette technologie, les utilisateurs pouvaient simplement prendre des photos de leurs codes imprimés sur les bouchons des bouteilles et d’autres surfaces au lieu de les saisir manuellement.
L’application fournit ensuite un niveau de confiance pour chaque caractère. Si le code échoue, l’application met en évidence les caractères dont le niveau de confiance est faible afin que les utilisateurs puissent apporter des corrections. L’apport des clients a entraîné le modèle, ce qui a amélioré la précision de l’extraction des données (fin de la boucle).
Malheureusement, il n’est pas toujours possible d’impliquer les utilisateurs finaux dans le processus.
Si c’est le cas pour vous, vous pouvez faire appel à des experts externes en annotation de données ou à des systèmes « human-in-the-loop ». Cependant, n’oubliez pas que dans certains cas d’utilisation, il peut être obligatoire de disposer d’un système HITL autogéré pour se conformer aux réglementations sur la confidentialité des données.
Examinons les différences entre ces deux solutions.
HITL externe ou autogéré
Vous êtes convaincu que l’automatisation Human-in-the-loop est bénéfique pour vous. Que faire maintenant ? Avant de sauter le pas ou d’essayer des tonnes d’API différentes de fournisseurs SaaS, il est essentiel de comprendre qu’il existe deux façons d’aborder l’approche HITL :
- Le HITL géré en externe
- HITL autogéré
Le HITL géré en externe
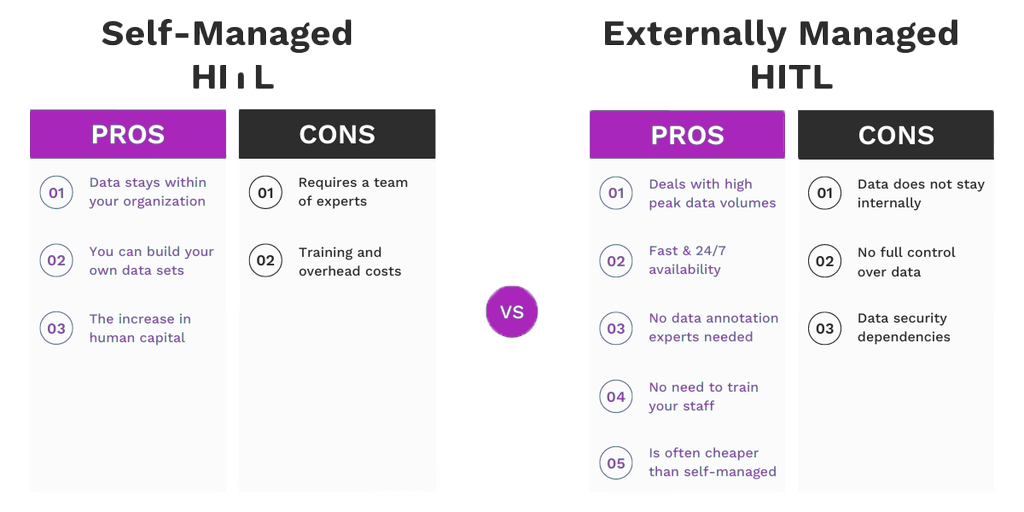
Par HITL géré en externe, on entend l’intervention humaine fournie par une partie externe (fournisseur de SaaS, fournisseur de services d’annotation de données). Le recours à un HITL géré en externe présente des avantages et des inconvénients.
Pour :
- Peut traiter des pics de volume de données élevés
- Rapide et souvent disponible 24 heures sur 24, 7 jours sur 7
- Moins cher, car les experts maîtrisent leur sujet
- Pas besoin de consacrer du temps à la formation du personnel
Contre :
- Les données sont transmises à la partie externe
- Les mesures de sécurité peuvent dépendre de la partie externe
- Problèmes de conformité réglementaire
HITL autogéré
Le HITL autogéré, comme son nom l’indique, désigne les entreprises qui incluent elles-mêment un humain dans la boucle du flux de travail. Voyons les avantages et les inconvénients de l’approche de l’HITL autogéré.
Pour :
- Les données restent au sein de l’entreprise
- Bénéfique à long terme car le personnel devient plus compétent
- Un excellent moyen d’accumuler des données
Contre :
- La formation et la mise en œuvre peuvent s’avérer coûteuses
C’est à vous de réfléchir au facteur décisif. Voulez-vous maintenir vos coûts à un niveau bas ou est-il plus important de conserver les données dans votre infrastructure ?
En fin de compte, il s’agit de déterminer ce qui est le plus important pour vous et votre cas d’utilisation.
Cas d’utilisation de l’automatisation HITL
Il existe plusieurs cas d’utilisation pour une automatisation efficace des HITL. Nous rencontrons généralement les cas d’utilisation suivants :
- Traitement des reçus pour les campagnes de fidélisation
- Traitement des factures pour les comptes fournisseurs
- Anonymisation d’informations sensibles pour la conformité
- Vérification des cartes d’identité pour les processus KYC
Si vous ne voyez pas votre cas d’utilisation dans la liste ci-dessus, ne vous inquiétez pas. Bien sûr, il existe de nombreux autres cas d’utilisation de l’automatisation des HITL. Pour cet article, nous avons choisi d’analyser plus en détail le premier cas d’utilisation.
Entrons dans le vif du sujet !
Traitement des reçus pour les campagnes de fidélisation
Dans les campagnes de fidélisation, les clients soumettent leurs reçus comme preuve d’achat. L’agence de marketing ou le magasin de détail vérifie les données du reçu pour voir si toutes les conditions sont remplies. Par exemple, si les articles achetés sont liés à la campagne et s’ils ont été achetés pendant la campagne.
Si toutes les conditions sont remplies, le client recevra une récompense.
Avec des campagnes réussies, vous pouvez finir par traiter des milliers de reçs par jour. Par conséquent, l’automatisation des tâches répétitives peut éliminer les inefficacités et faire gagner du temps.
Cependant, l’automatisation de l’ensemble du processus a ses défauts, car les machines et l’IA ne sont pas parfaites. Par exemple, la précision de l’extraction des données n’est pas élevée lorsque les reçus scannés sont délivrés en mauvaise qualité, ce qui entraîne des erreurs importantes.
Combiner l’automatisation et l’intelligence humaine permet de minimiser les données inexactes, les erreurs et même la fraude documentaire, ce qui conduit aux résultats financiers souhaités de vos campagnes.
Alors, comment l’automatisation HITL entre-t-elle en jeu ? Nous vous l’expliquons ci-dessous.
Abandonner le flux traditionnel de traitement des reçus
Traditionnellement, le flux de travail du traitement des reçus pour les campagnes de fidélisation se compose des étapes suivantes :
- Réception des preuves d’achat
- Faire correspondre le document avec un client dans la base de données (pour la personnalisation)
- Lire chaque reçu
- Confirmer sur un reçu que les articles de la campagne ont été achetés pendant la période de la campagne.
- Saisir les données dans la base de données
- Déterminer le nombre de points de fidélité attribués au client
- Envoyer les récompenses
Ce flux de travail est coûteux et prend du temps, surtout lorsque votre personnel et vos employés sont affectés à ces tâches administratives.
Alors comment cela se présente-t-il avec l’automatisation human-in-the-loop ?
Tout d’abord, le reçu peut être téléchargé par FTP, par courrier électronique, par application Web ou scanné avec un téléphone portable.

Une fois le reçu numérisé, des solutions telles que le traitement intelligent des documents classent le document grâce à l’IA. Elles déterminent si le document est un reçu ou d’autre nature.

Après la classification, les champs de données pertinents sont extraits du document.

Cette étape est suivie d’une validation automatisée, qui vérifie si les articles de la campagne ont été achetés pendant la période de la campagne. Cette étape est également connue sous le nom de validation des reçus.

Si le modèle OCR et d’IA donne un score de confiance faible, le fichier sera transmis à l’humain dans la boucle pour valider l’exactitude des données.
Quant au niveau du score de confiance, vous pouvez le déterminer vous-même. Par exemple, si le document reçoit un score de confiance <70, vous le transmettez à un humain inclus dans la boucle pour une validation supplémentaire.
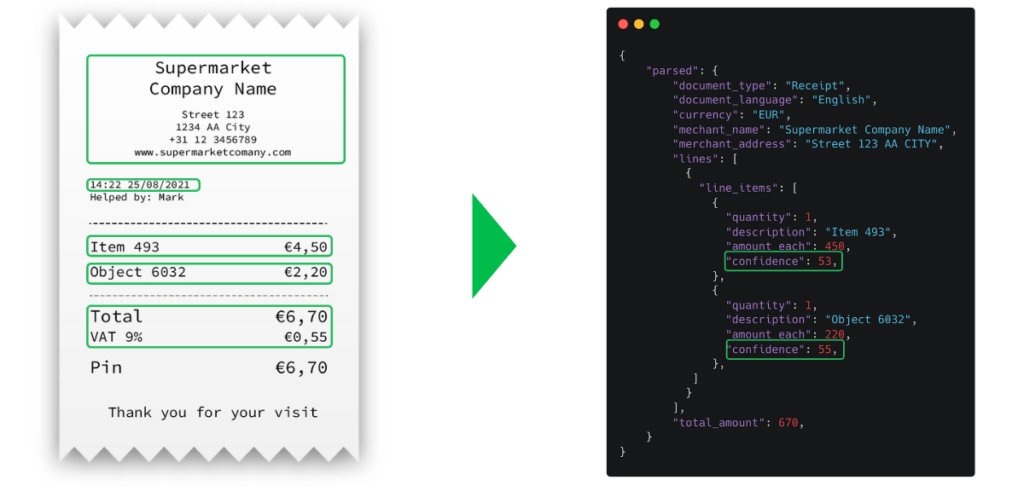
Les données sont ensuite converties dans le format souhaité (feuille Excel, PDF ou JSON) et transmises à une base de données.
Grâce à l’automatisation de l’human-in-the-loop, vous pouvez :
- Augmenter la précision de l’extraction des données.
- Accélérer le temps de traitement des reçus
- Réduire les frais généraux
- Améliorer l’engagement des employés
- Minimiser les erreurs humaines coûteuses.
Maintenant que nous avons couvert l’un des cas d’utilisation les plus courants, nous espérons que vous avez une meilleure compréhension des avantages de l’automatisation HITL.
Si vous êtes convaincu que l’automatisation de l’intégration d’Human-in-the-loop est faite pour vous, lisez la section suivante qui contient quelques conseils sur les éléments à prendre en compte.
Comment démarrer ?
Avant de rechercher différentes solutions et différents fournisseurs, il serait sage de prendre une minute. Posez-vous les questions suivantes :
- Votre organisation a-t-elle besoin d’atteindre une précision d’extraction des données proche de 100% ?
- Avez-vous besoin d’un HITL géré en externe ou en interne ?
- Disposez-vous d’experts en IA en interne ?
- Quelle est l’importance du fait que les données restent à 100 % dans votre infrastructure interne ?
- Qu’est-ce qui est essentiel pour votre cas d’utilisation ?
- Voulez-vous construire vos propres ensembles de données ?
Pour vous donner un petit coup de pouce supplémentaire, nous avons comparé les économies de coûts avec des flux de travail entièrement automatisés et des flux automatisés HITL. Consultez notre calculateur d’économies gratuit !
Quelles que soient vos réponses, nous sommes convaincus que Doxis peut résoudre vos problèmes liés aux documents grâce à ses solutions de traitement intelligent des documents.
La meilleure partie de l’IA est qu’elle reproduit les capacités humaines pour scanner et comprendre les informations clés avec une grande vitesse et précision.
Quel que soit votre cas d’entreprise, une solution OCR alimentée par l’IA peut vous aider à faire travailler les données pour vous.
Automatiser les flux de travail liés aux documents avec Doxis
Doxis est spécialisé dans l’automatisation des flux de travail liés aux documents. Que vous souhaitiez automatiser seulement une infime partie de votre flux de travail avec l’approche HITL ou l’ensemble du flux de travail, nous pouvons vous aider.
Doxis AI.dp automatise l’extraction de données, la classification, la conversion de documents, l’anonymisation et la vérification avec la technologie OCR intégrée à l’IA. Quels que soient les défis d’automatisation des documents auxquels vous êtes confrontés, Doxis peut faire de vous un champion du traitement des documents.
Si vous disposez déjà d’une application web, vous pouvez choisir d’intégrer notre technologie à votre solution via une API. Pour les applications mobiles, nous fournissons une solution de numérisation mobile, que vous pouvez facilement intégrer grâce à un SDK bien documenté.
Toutes nos solutions peuvent être connectées à notre interface HITL afin de tirer parti de l’automatisation de la boucle humaine pour des résultats plus précis.
Interface « human-in-the-loop
La création et la conception d’une interface utilisateur peuvent mobiliser vos ressources – en temps et en argent. Si vous ne disposez pas d’experts en interne, tels que des concepteurs UI et UX, vous devrez confier ce travail à un tiers. Votre délai de mise sur le marché dépend alors de cette tierce partie.
C’est pourquoi nous proposons à nos clients une interface « human-in-the-loop » intégrée à nos ou à vos solutions – afin que vous n’ayez pas à en créer une vous-même !
Vous pouvez en tirer parti dans le cadre d’un flux de travail HITL autogéré ou même utiliser notre back-office pour effectuer les dernières annotations à votre place.
L’interface permet à l’utilisateur de contrôler, vérifier, valider et annoter les données sans effort et en quelques secondes. Il peut être invité à le faire lorsque le score de confiance est inférieur au seuil que vous avez configuré.
Ou même dans les situations où vous savez que vous recevrez des images de mauvaise qualité ou des documents complexes d’un certain fournisseur.
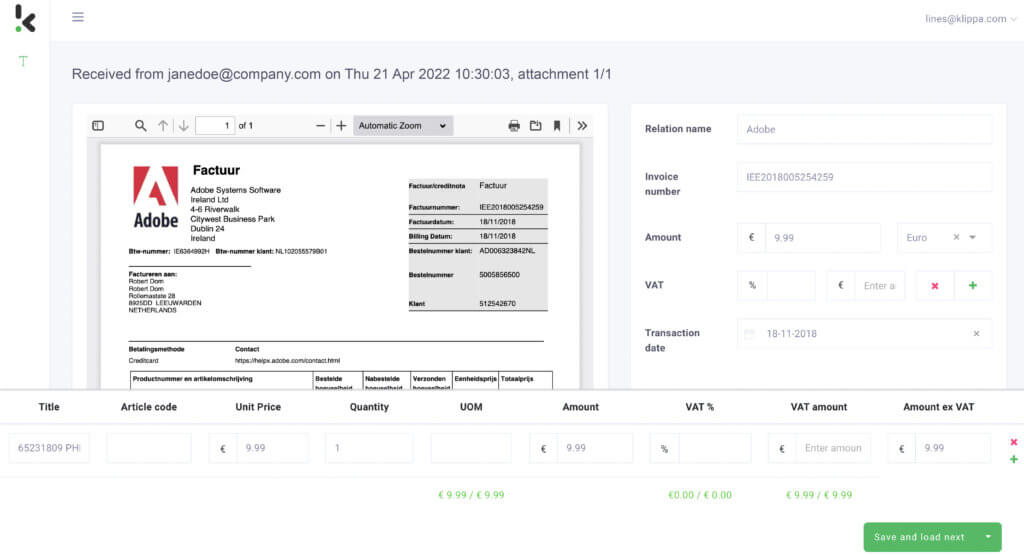
L’automatisation de l’HITL permet de gagner du temps et d’accroître la précision de l’extraction des données, ce qui se traduit par une amélioration significative des résultats. Si elle est utilisée au début d’une boucle, vous pouvez annoter les données et créer vos ensembles de données.
Envie de savoir comment l’appliquer à votre cas d’utilisation ?
Réservez une place pour une démonstration à l’aide du formulaire ci-dessous pour commencer (ou contactez notre équipe d’experts si vous avez des questions supplémentaires) !
FAQ
L’automatisation Human-in-the-Loop (HITL) est un flux de travail où l’IA gère la majorité des tâches, mais un humain intervient à des moments clés pour revoir, corriger ou guider le système, en particulier lorsque la confiance est faible ou lorsque la précision est cruciale.
Utilisez HITL lorsque vous traitez des données sensibles, des documents complexes ou des tâches où les erreurs peuvent être coûteuses, comme le traitement des factures, le KYC ou les travaux liés à la conformité. C’est idéal lorsque vous avez besoin d’une grande précision sans compter entièrement sur le travail manuel.
Oui. Avec des plateformes comme Doxis AI.dp, HITL peut être intégré à vos flux de travail existants via API ou SDK. Que vous ayez une application web ou mobile, HITL peut s’intégrer de manière fluide pour gérer les exceptions et valider les résultats à faible confiance.
Un HITL auto-géré signifie que votre équipe prend en charge le processus de révision humaine en interne. Un HITL géré en externe implique l’externalisation de ce travail à un fournisseur de confiance. Le choix dépend de vos ressources internes, de vos besoins en matière de confidentialité des données et de vos objectifs de scalabilité.
Chaque correction humaine crée une boucle de rétroaction qui entraîne et améliore votre modèle d’IA. Au fil du temps, cela rend le système plus précis, réduisant ainsi le besoin d’intervention humaine à long terme.