As organizações lidam diariamente com grandes quantidades de documentos, documentos esses que variam em termos de tipo, conteúdo ou importância. Garantir uma classificação precisa destes ficheiros pode rapidamente tornar-se frustrante, especialmente se for feito manualmente. Alguns dos seus funcionários são responsáveis pela organização manual dos documentos com base nestas etiquetas. Isto leva tempo e, na pior das hipóteses, os ficheiros perdem-se porque são classificados de forma incorreta.
No entanto, graças ao rápido desenvolvimento da tecnologia, os funcionários já não gastam tempo excessivo a classificar documentos, deixando estas tarefas nas mãos da automatização. Neste blogue, encontrará uma explicação completa do que representa a classificação de documentos, conhecerá o processo subjacente à sua automatização e descobrirá uma solução pronta a utilizar para classificar os seus documentos empresariais. Vamos começar.
O que é a classificação de documentos?
A classificação de documentos é o processo de atribuição de documentos a categorias relevantes para facilitar a gestão e a análise. O objetivo é organizar os ficheiros com a maior precisão possível, facilitando a pesquisa e a localização de itens.
Embora a classificação de documentos seja uma tarefa importante por si só, também faz parte de uma iniciativa de automatização muito maior, denominada processamento inteligente de documentos. Portanto, a classificação destes ficheiros é apenas uma das muitas ações que podem ser automatizadas para melhorar os fluxos de trabalho de processamento de documentos.
A classificação de documentos pode ser efetuada utilizando dois parâmetros, nomeadamente a classificação de texto e a classificação visual. Alguns destes parâmetros podem ser vistos em motores de busca reais, permitindo aos utilizadores encontrar o que procuram sem grande esforço.
Para compreender melhor como pode ser efetuada a categorização de documentos, é necessário dar um passo atrás e analisar primeiro o processo técnico subjacente à classificação automática de documentos.
Tipos de classificação de documentos
Como já foi referido, os documentos são classificados em função do seu conteúdo, seja ele texto ou imagem. Para cada tipo de classificação de documentos, pode descobrir diferentes métodos utilizados para detetar e analisar o conteúdo específico, que iremos abordar em breve.
Classificação de textos
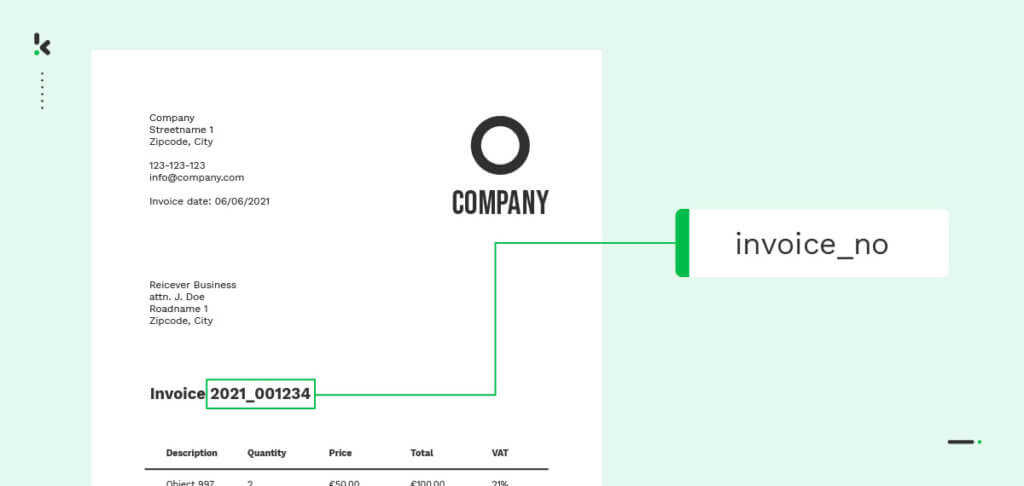
A classificação de texto diz respeito ao processamento de informações textuais de uma variedade de tipos de documentos. Uma vez que a maioria das empresas depende de documentos com muito texto para as suas operações quotidianas, a classificação de texto tornou-se o principal objetivo da maioria dos fornecedores de software, como o software OCR.
Como é que a classificação de texto funciona? A classificação de texto em documentos utiliza frequentemente tecnologias como o OCR e a PNL, que se enquadram na tecnologia de aprendizagem automática.
O OCR é uma tecnologia que o ajuda a extrair texto de imagens ou documentos digitalizados e a convertê-lo num formato legível por máquina. Muitas vezes, esta tecnologia é associada à Inteligência Artificial (IA) e à Aprendizagem Automática (Machine Learning), para obter uma elevada precisão na extração de dados.
A Programação Neurolinguística (PNL) é uma técnica mais complexa, responsável por analisar melhor os dados extraídos e compreender a semântica do texto. A PNL (ou NLP, na sigla em inglês) permite que os computadores compreendam a linguagem humana num contexto específico, criando um processo de extração de dados de elevada precisão e qualidade.
Para classificar automaticamente um documento, é necessário utilizar primeiro o OCR para extrair informações e o PNL para compreender o conteúdo das informações.
Classificação de imagens
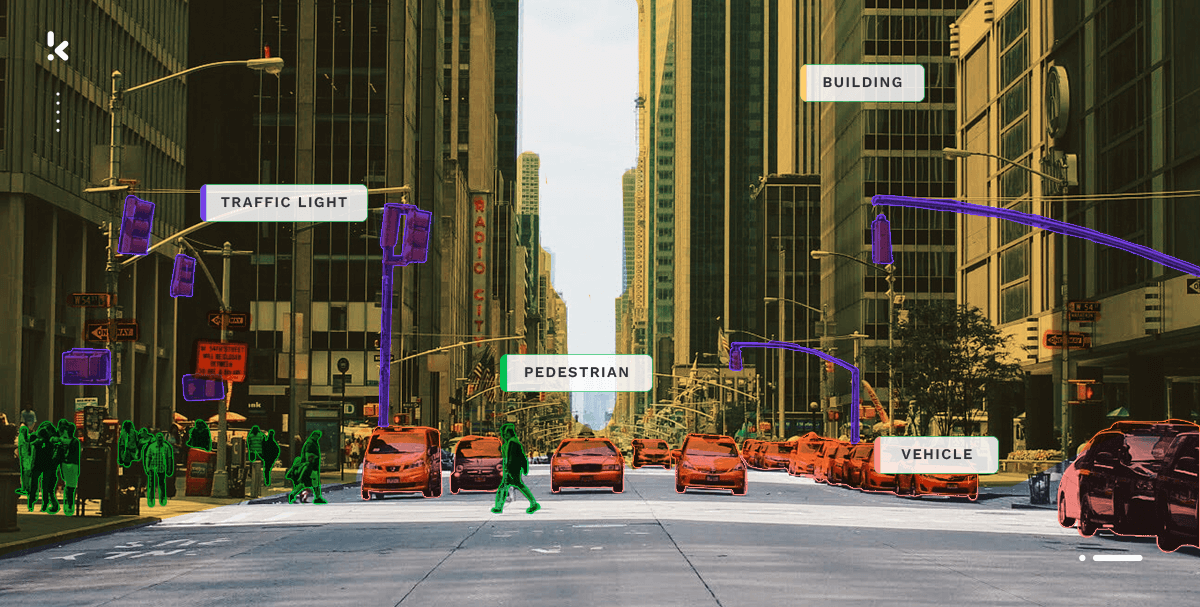
Quando se trata de classificação de imagens, o foco está na estrutura visual dos documentos. A deteção de imagens e vídeos num documento é feita através da análise dos pixels que criam o visual e, em seguida, determinam o seu conteúdo. A identificação e classificação de imagens é feita através da utilização de tecnologias como a Visão Computacional e a Deteção de Objetos.
A Visão Computacional (ou Computer Vision) é uma tecnologia alimentada por IA capaz de reconhecer objetos em imagens fixas ou vídeos. Pode ser utilizada para detetar objetos dentro de uma imagem, a sua localização no documento ou a ação representada no conteúdo visual. A visão computacional ajuda-o a classificar imagens aplicando opções de filtragem e pesquisa.
A Deteção de Objetos é aplicada em áreas de negócio que precisam de gerir grandes quantidades de dados visuais e onde a classificação ocorre a uma escala maior. Por exemplo, a deteção de objetos está espalhada pelos departamentos de logística, armazéns e inventários, onde a leitura de códigos de barras ou códigos QR faz parte das operações diárias.
Agora que já está familiarizado com as tecnologias utilizadas para melhorar a classificação de textos e imagens, vamos aprofundar o tema e descobrir os métodos utilizados na classificação automática de documentos.
Métodos de classificação automática de documentos com Machine Learning
A classificação automatizada de documentos é conseguida através da Aprendizagem Automática (Machine Learning). Utiliza principalmente a PNL, que requer a formação de grandes quantidades de dados, para detetar e definir padrões em documentos com elevada precisão.
Para treinar o modelo, alimentamo-lo com dados pré-existentes, que já beneficiam de categorias e conjuntos de características pré-determinados. Isto permite que o modelo aprenda ligações estatísticas entre palavras e frases.
Os classificadores de aprendizagem automática recolhem conjuntos de dados de treino, por exemplo, artigos, ensaios ou qualquer corpo de texto que possa ser utilizado para extrair palavras-chave e definir categorias para o modelo aprender. No entanto, existem vários métodos de classificação de documentos utilizando Machine Learning, que serão abordados na próxima secção.
Classificação supervisionada de documentos
Na classificação supervisionada de documentos, o próprio utilizador fornece os dados de entrada, ou seja, treina o modelo em documentos que já têm uma etiqueta. Por conseguinte, a classificação é efetuada através da avaliação da relação entre o novo documento e os dados históricos rotulados.
Por exemplo, pode alimentar o modelo com faturas, recibos e extratos bancários para aprender. O modelo fará um ótimo trabalho ao reconhecer e classificar estes tipos de documentos. Mas se o fizer classificar documentos de identidade, o resultado será uma tentativa falhada. O modelo não conseguiu encontrar uma relação entre os novos documentos, ou seja, documentos de identidade, e os dados históricos rotulados, ou seja, faturas ou recibos, pelo que a classificação acaba por ser imprecisa.
Prós
- Trata-se de uma classificação exata dos documentos
- É fácil avaliar os seus resultados
Contras
- Requer um grande conjunto de dados de treino
- Pode ser demorado e dispendioso rotular uma grande quantidade de dados ou o conjunto de treino
Classificação não supervisionada de documentos
A classificação não supervisionada de documentos não requer um conjunto de dados de treino para aprender. O seu objetivo é classificar documentos analisando o seu conteúdo e encontrando diferenças entre eles. De seguida, o modelo cria agrupamentos, ou categorias, onde os documentos classificados são colocados. Embora alguns documentos possam partilhar semelhanças, as categorias são desconhecidas para o modelo, deixando espaço para a incerteza na qualidade da classificação.
Prós
- Não requer um conjunto de dados de treino rotulado
- A sua utilização é mais rápida e mais económica, uma vez que não é necessário etiquetar
Contras
- É mais difícil avaliar
- É menos preciso do que o método supervisionado
Classificação semi-supervisionada de documentos
A classificação semi-supervisionada de documentos consiste numa combinação entre as classificações supervisionada e não supervisionada. Utiliza conjuntos de dados de treino com e sem rótulo, melhorando o desempenho de ambos os métodos de classificação, mas não aperfeiçoando nenhum deles.
Prós
- Melhora a precisão de ambos os métodos de classificação
- Não necessita de tantos dados de treino como a classificação supervisionada
Contras
- É mais difícil de implementar do que os métodos supervisionado e não supervisionado
- Pode ser menos exato do que uma classificação completamente supervisionada
Agora que já conhecemos os diferentes métodos de classificação que utilizam Machine Learning, vamos ver como é o processo de automatização da classificação de documentos.
Como classificar documentos automaticamente?
A classificação automática de documentos utiliza métodos de aprendizagem profunda (um subconjunto da aprendizagem automática) para ordenar os ficheiros em várias categorias, sem qualquer intervenção humana. Para este processo, segue-se um processo simples de três passos, como se segue:
- Reúna um conjunto de dados: Para treinar o modelo de classificação, é necessário primeiro efetuar a preparação dos dados. Isto significa reunir pelo menos 20 pontos de dados por etiqueta, ou seja, 20 documentos por categoria. Isto aumenta a precisão do resultado, dando-lhe um resultado final qualitativo. O algoritmo categoriza o resultado com base nos dados específicos em que foi treinado.
Por exemplo, se quiser classificar apenas faturas, só faria sentido treinar o modelo em várias faturas. No entanto, se pretender classificar um tipo de documento diferente, por exemplo, um recibo, o modelo poderá ter dificuldade em classificar com precisão os documentos pretendidos.
- Treine o modelo: Esta etapa pode tornar-se demorada e dispendiosa, dependendo do método de classificação escolhido, ou seja, supervisionado, não supervisionado ou semi-supervisionado. Embora seja, de facto, uma tarefa redundante, é necessária para obter os resultados mais precisos.
- Avalie os resultados: A comparação dos resultados com as expetativas é uma prática essencial para garantir que o modelo funciona como pretendido. Isto pode ser feito comparando os resultados da classificação com um documento já previsto, garantindo uma representação exata na comparação.
Para compreender verdadeiramente este processo, é necessário dedicar-lhe todo o tempo necessário. Apressar-se a fornecer ao modelo dados incorretos ou não lhe fornecer pontos de dados suficientes só dificultará a sua vida a longo prazo. Abrandar e compreender verdadeiramente este procedimento garante que obtém os melhores resultados dos seus esforços de classificação de documentos.
Compreendemos se ainda não tiver a certeza se a implementação da classificação automática de dados é ou não benéfica para as necessidades da sua empresa. Por isso, vamos esclarecer algumas das vantagens que a classificação automática de documentos pode trazer à sua empresa.
As vantagens da classificação de documentos para as empresas
A classificação automática de documentos proporciona à sua organização uma implementação mais fácil dos processos empresariais quotidianos. Alguns dos benefícios da implementação desta prática são:
- Poupa tempo e recursos à sua empresa: A classificação automática de documentos organiza e analisa grandes quantidades de documentos, poupando-lhe uma quantidade significativa de tempo e recursos financeiros.
- Ajuda-o a identificar documentos fraudulentos: Classificar documentos automaticamente significa também identificar documentos fraudulentos através de anomalias ou erros humanos presentes nestes ficheiros. A automatização ajuda, portanto, a reduzir a fraude de documentos na sua organização, como a fraude de faturas.
- Ajuda a automatizar a classificação de documentos: A classificação manual de documentos pode facilmente tornar-se confusa, dando-lhe dúvidas quanto à etiqueta a atribuir-lhes, o que resulta em erros e na tomada de decisões incorretas. A classificação automática resolve este problema, ordenando os documentos com base em categorias pré-determinadas por si e pela sua equipa.
Estes benefícios podem não parecer impactantes no início, mas podem fazer uma grande diferença na forma como conduz a sua atividade. Para podermos compreender esta questão e ver o panorama geral, vamos discutir alguns casos de utilização reais da classificação automática de documentos.
Casos de utilização reais e aplicações da classificação de documentos
Conhecer a teoria subjacente à classificação de documentos não é suficiente para compreender realmente a sua utilização. Vamos apresentar alguns casos de utilização em que a classificação automática de documentos tem um impacto positivo na sua atividade:
- Deteção de spam em e-mails: A classificação automatizada de documentos ajuda a identificar os e-mails que se enquadram na categoria de spam. Normalmente, incluem texto com um som pouco natural, erros gramaticais ou ortográficos, que levantam suspeitas em comparação com os e-mails normais. Utilizando a classificação de documentos, os e-mails que assinalam estas caixas são recuperados na caixa de entrada de spam correspondente, mantendo a sua empresa livre de ligações perigosas ou correspondência não solicitada.
- Processamento do feedback de clientes: Analisando a semântica e o tom do texto, que descobrimos que é feito através da PNL, pode separar o feedback positivo do construtivo. Assim, a sua organização tem melhor acesso a sugestões que visam melhorar os processos empresariais, ajudando-o a prestar melhores serviços aos seus clientes.
- Facilitar o apoio ao cliente: Utilizando a classificação de documentos, os funcionários de apoio ao cliente podem facilmente separar reclamações, reembolsos, pedidos de informação ou outros comentários, com base no texto. Isto melhora a eficiência do fluxo de trabalho, enviando os comentários correspondentes para os departamentos designados.
- Digitalização de documentos: A sua empresa pode estar a tratar de vários tipos de documentos, por exemplo, faturas, recibos ou contratos. A utilização de software de digitalização de documentos para escanear o documento e etiquetá-lo através da classificação, irá simplificar significativamente os seus processos.
A sua empresa merece um software que torne possíveis todos os casos de utilização acima referidos e muito mais. É o caso do Klippa DocHorizon, que o ajuda a automatizar qualquer fluxo de trabalho de processamento de documentos, incluindo a classificação de documentos, oferecendo à sua organização os benefícios de uma vida inteira.
Vá além da classificação automática de documentos com a Klippa
O Klippa Dochorizon é uma solução de processamento inteligente de documentos alimentada por IA, destinada a simplificar as operações comerciais diárias em grande escala. Não só o ajuda a obter uma classificação de documentos precisa, como também ajuda a sua empresa noutras áreas:
- Captura de dados de uma grande variedade de tipos de documentos utilizando OCR de elevada precisão
- Anonimização automática de dados e imagens para máxima conformidade com os regulamentos de privacidade
- Conversão de documentos para o formato pretendido, como CSV, XML, JSON ou PDF
- Beneficie de uma integração perfeita com soluções de software existentes através de SDK ou API
- Evite fraudes na sua organização com a verificação automática de documentos
- Classificação e categorização de uma grande variedade de tipos de documentos
- Processamento de documentos com base em campos de dados específicos
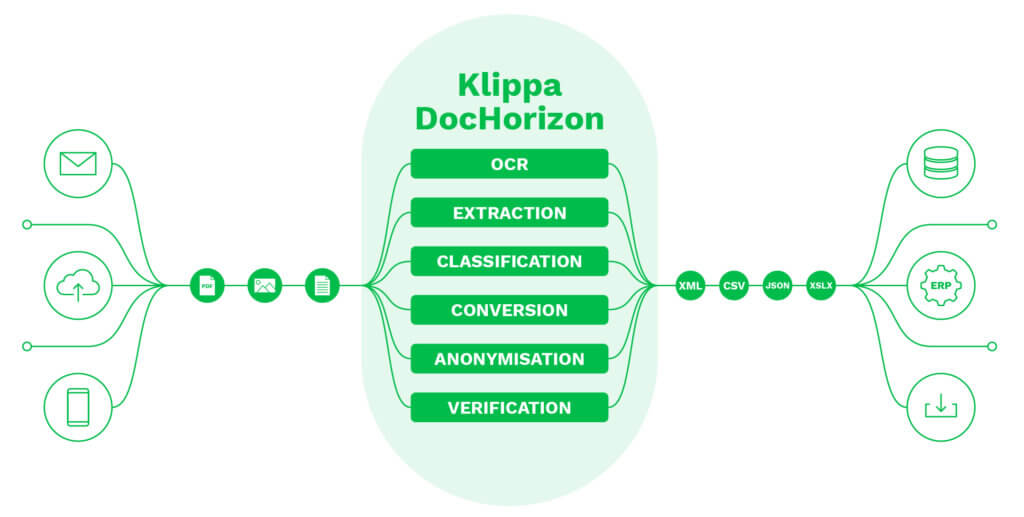
Com o Klippa DocHorizon, a sua empresa está preparada para o sucesso. Se estiver interessado em obter mais informações sobre o nosso produto, contacte os nossos especialistas ou marque uma demonstração em baixo!