
Vous a-t-on déjà demandé d’extraire les données d’un fichier PDF ? Par exemple, pour capturer les données d’une facture et les saisir dans un programme de comptabilité ? Ou simplement pour copier-coller des informations fichier PDF vers un fichier Excel ?
Si c’est le cas, vous vous êtes peut-être demandé s’il existait une méthode plus efficace que le simple copier-coller manuel des données d’un document à l’autre.
Si cette méthode fonctionne si vous n’avez que quelques documents, elle devient fastidieuse et difficile à organiser lorsque vous avez des centaines, voire des milliers de documents.
Heureusement pour vous, cet article couvre quelques solutions plus intelligentes d’extraire des données d’un ficher PDF. L’une d’entre elles est entièrement automatisée !
Nous aborderons l’importance des documents PDF, les défis de l’extraction des données des PDF et la manière dont les logiciels peuvent vous aider à automatiser ce processus.
Points Clés :
- Il existe 5 principales méthodes pour extraire des données des fichiers PDF : cela inclut le copier-coller, l’utilisation de convertisseurs PDF, les outils d’extraction de tableaux, l’externalisation de la saisie des données et l’automatisation du processus avec l’OCR.
- Les méthodes manuelles et les convertisseurs PDF sont limitées et inefficaces : le copier-coller est lent, tandis que les convertisseurs ne peuvent pas traiter des fichiers volumineux ou des PDF numérisés, ce qui les rend inadaptés à l’extraction de données complexes.
- Doxis AI.dp vous permet d’extraire des données PDF en cinq étapes simples : configurez un flux, définissez les entrées, créez des préréglages, extrayez les champs clés et exportez vers la destination de votre choix.
- Doxis s’intègre parfaitement via API pour une automatisation de bout en bout : connectez-le à votre logicielle et déclenchez les flux de travail automatiquement depuis des sources comme Google Drive.
Quels sont les défis de l’extraction de données de PDF ?
L’extraction de données à partir de PDF peut être très difficile. Les défis les plus importants sont les suivants :
- Difficile à éditer : le format PDF est conçu pour préserver l’intégrité des données afin de s’assurer que le contenu a la même apparence sur n’importe quelle plateforme et à tout moment. Cela signifie que vous ne pouvez pas facilement modifier ou extraire le contenu.
- Cela prend du temps : Comme vous ne pouvez pas facilement modifier ou extraire le contenu des PDF, il faut qu’un membre de votre équipe ouvre chaque fichier PDF, trouve le texte pertinent, le sélectionne, puis le copie dans un autre fichier ou programme. Cela peut prendre beaucoup du temps précieux de vos employés.
- Risque d’erreur : L’un des inconvénients majeurs de tout processus fastidieux et répétitif est qu’il comporte des erreurs. Si vous ne vérifiez que quelques documents, ce n’est probablement pas un gros problème. Mais si vous traitez des centaines de documents par jour, un taux d’erreur de seulement 1 % se traduit déjà par des dizaines d’erreurs par semaine.
Maintenant que vous êtes conscient des défis que pose l’extraction de données de PDF, nous allons passer à 5 façons différentes d’extraire des données de documents PDF.
5 façons d’extraire des données de fichiers PDF
Plongeons dans les options dont vous disposez pour extraire des données de documents PDF :
- Copier-coller
- Convertisseurs PDF
- Externalisation de la saisie manuelle des données
- Outils d’extraction de tableaux PDF
- Automatisation de l’extraction de données de PDF
Copier-coller

Si vous ne disposez que de quelques documents, le plus simple est probablement de copier manuellement les données du PDF et de les coller dans le système ou la plate-forme de votre choix.
Bien que cela puisse sembler être l’option la plus pratique pour obtenir des informations du point A au point B, il est très probable que des erreurs se produisent, comme des fautes de frappe ou l’absence d’une statistique importante.
En outre, vous devrez réorganiser les données manuellement, ce qui peut prendre beaucoup de temps. Lorsque vous devez traiter des centaines de documents par jour, cela devient un véritable casse-tête.
| Avantages | Inconvénients |
| – Plus facile – Aucun logiciel supplémentaire ou équipement requis | – Chronophage – Propice aux erreurs – Faible productivité – Données non-structurées |
Convertisseurs PDF
Un convertisseur PDF vous permet d’extraire des données rapidement et en toute sécurité. Parmi les outils de conversion PDF les plus populaires figurent : Adobe, Cometdocs, PDF to Excel et SimplyPDF.
Ces outils, souvent peu coûteux, utilisent une technologie de reconnaissance de texte pour transformer les PDF en d’autres formats, tels que Word, SOCX et JPEG. Pour ce faire, il suffit de télécharger les documents PDF et de les convertir dans le format souhaité.
Cette méthode permet de réduire considérablement le nombre d’erreurs, mais elle présente quelques inconvénients : il est impossible d’extraire des données en vrac. Par conséquent, si vous disposez de nombreux documents, vous ne pouvez utiliser le convertisseur qu’en téléchargeant un seul PDF à la fois. En outre, les convertisseurs ne fonctionnent qu’avec des fichiers PDF natifs, et ne peuvent donc pas vous aider avec des documents numérisés.
| Avantages | Inconvénients |
| – Facilité de trouver les outils en ligne – Option à faible coût | – Fonctionnalité limitée – Extraction des données en masse impossible – Les convertisseurs de PDF ne fonctionnent qu’avec des PDF natifs |
Externalisation de la saisie manuelle des données
Si vous traitez un grand nombre de documents, l’externalisation de la saisie manuelle des données peut être une bonne solution. Il existe de nombreuses entreprises de saisie de données qui offrent des services de qualité. Les meilleurs services en ligne sont les suivants :
- Freelancer.com
- Upwork
- Hubstaff Talent
- Fiverr
La plupart de ces entreprises sont basées en Afrique ou en Asie du Sud, où le salaire médian est plus faible qu’en Europe occidentale ou aux États-Unis.
Si les services d’externalisation réduisent les coûts et les délais d’extraction des données, la qualité et la sécurité des données peuvent être mises en péril. Très souvent, les sociétés d’externalisation ne sont pas motivées par les mêmes normes et la même mission que votre entreprise.
Ces entreprises sont motivées par le profit, plutôt que par vos objectifs de performance internes. Un autre aspect que vous devez prendre en considération est la menace pour la sécurité et la confidentialité.
Les informations de vos clients seront exposées et capturées ailleurs. Imaginez comment vos clients réagiraient au fait que leurs données personnelles soient stockées ailleurs.
| Avantages | Inconvénients |
| – Un degré de flexibilité plus élevé – Pas besoin d’embaucher ou deformer plus d’employés | – Normes de qualité inférieures – Menace sur la sécurité et la confidentialité |
Outils d’extraction de tableaux PDF

Les documents PDF contiennent souvent des tableaux avec du texte, des images et des figures. Dans de nombreux cas, les données pertinentes se trouvent généralement dans les tableaux.
Il est particulièrement difficile d’extraire les tableaux des PDF, mais heureusement, il existe différents outils. Parmi les meilleurs outils d’extraction de tableaux, citons :
- Tabula
- PdfTables
- Docparser
- Camelot
- Excalibur
Ces outils vous permettent de sélectionner une section du PDF en dessinant un cadre autour du tableau, puis d’extraire les données dans différents formats tels que CSV ou XLS.
Bien que les outils d’extraction de tableaux fournissent des résultats raisonnablement efficaces, il se peut que vous ayez besoin d’un effort de développement ou d’experts internes pour les faire fonctionner dans votre cas d’utilisation spécifique.
En outre, la plupart de ces outils ne fournissent pas le processus le plus automatisé, et avec certains de ces outils, vous ne pouvez travailler que sur un seul document PDF (natif) à la fois.
| Avantages | Inconvénients |
| – Facile à utiliser – Extraction efficace et précise du tableau – Certains outils sont gratuits | – Ne fonctionne qu’avec des fichiers PDF natifs – Nécessite des experts internes – N’est pas un processus entièrement automatisé |
Automatisation de l’extraction de données de PDF

La solution idéale pour les entreprises est de pouvoir analyser tous les types de fichiers PDF avec un minimum d’intervention humaine. Cela est possible grâce à un logiciel d’OCR intelligent. Cette solution peut sembler intimidante au premier abord, car elle n’est pas aussi simple que la saisie manuelle ou même les convertisseurs de PDF.
Cependant, en choisissant la solution OCR, vous serez en mesure d’extraire les données des PDF en quelques secondes.
Le logiciel OCR utilise une technologie de reconnaissance de texte appelée reconnaissance optique de caractères (OCR). Cette technologie identifie le texte dans les documents et le convertit en données lisibles par une machine. Elle est sécurisée, extrêmement efficace, rapide et évolutive.
Les logiciels d’OCR peuvent traiter de gros volumes de PDF natifs et non natifs. Le seul inconvénient est le temps et les coûts de mise en œuvre qui y sont associés.
| Avantages | Inconvénients |
| – Rapide et évolutif – Efficace et sécurisé – Capacité à traiter des PDF natifs et non natifs en masse – Extraction de données à partir de gros volumes de documents | – Temps de mise en œuvre – Coûts associés au logiciel |
Automatisez l’extraction de données des PDF avec Doxis
Le moyen le plus fiable et le plus rapide d’extraire des données de fichiers PDF est sans aucun doute d’utiliser une solution d’extraction de données automatisée.
Un bon exemple d’une telle solution est Doxis AI.dp.
Mais comment cela fonctionne-t-il exactement ? Voyons une explication étape par étape :
Étape 1 : Inscrivez-vous sur la plateforme
- Inscrivez-vous gratuitement sur AI.dp avec votre e-mail et mot de passe.
- Recevez 25 € de crédits gratuits pour explorer les fonctionnalités.
- Créez une organisation et un projet, puis activez le modèle Capture de documents : Modèle financier et Flow Builder.
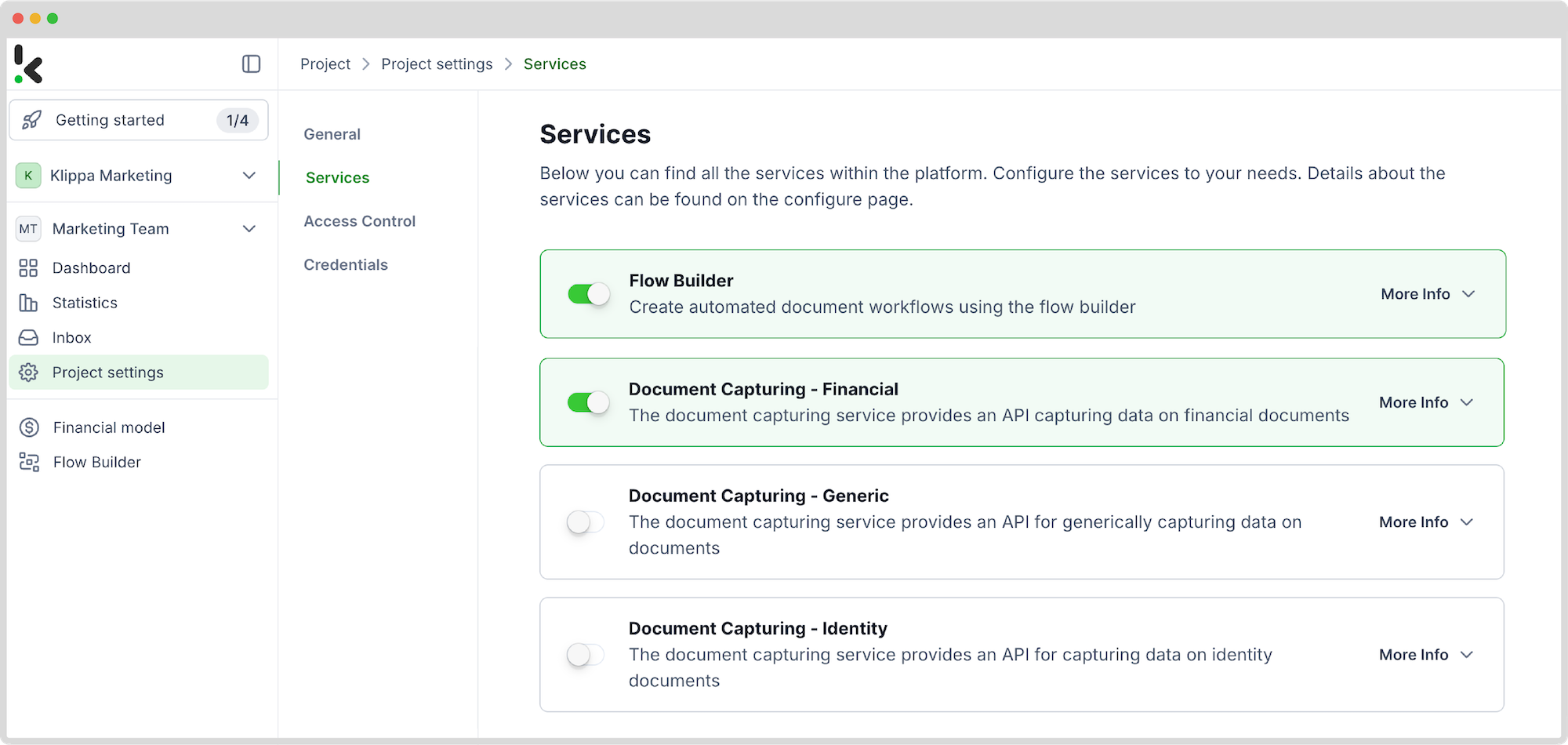
Étape 2 : Créez un préréglage
- Cliquez sur le modèle Financier et créez un préréglage.
- Sélectionnez les composants à extraire (ex. : détails du fournisseur, montants, TVA).
- Enregistrez le préréglage une fois satisfait.
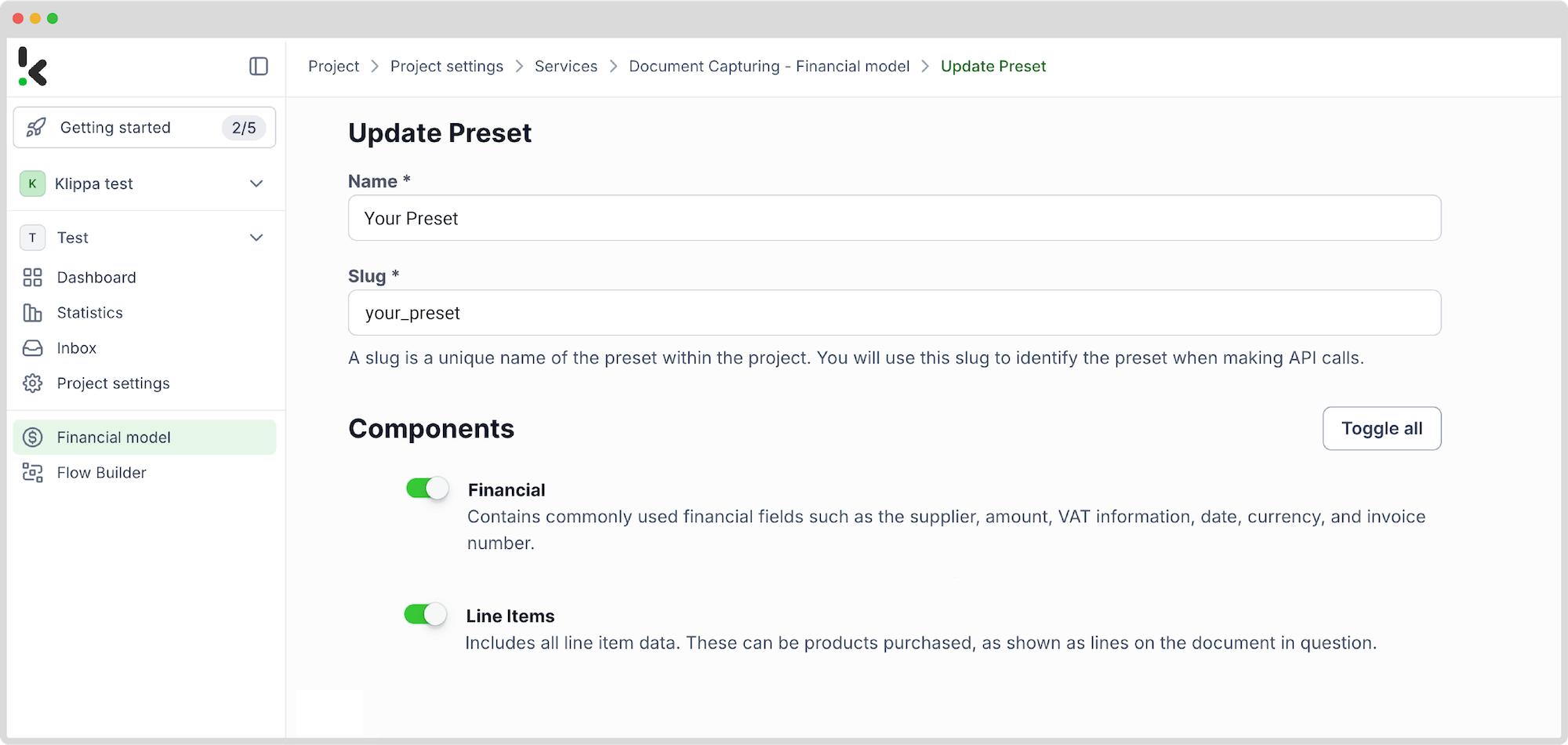
Étape 3 : Sélectionnez votre source d’entrée
- Créez un flux via Flow Builder > Nouveau flux.
- Choisissez un déclencheur (par exemple, un nouveau fichier sur Google Drive).
- Assurez-vous de cocher Inclure le contenu du fichier.
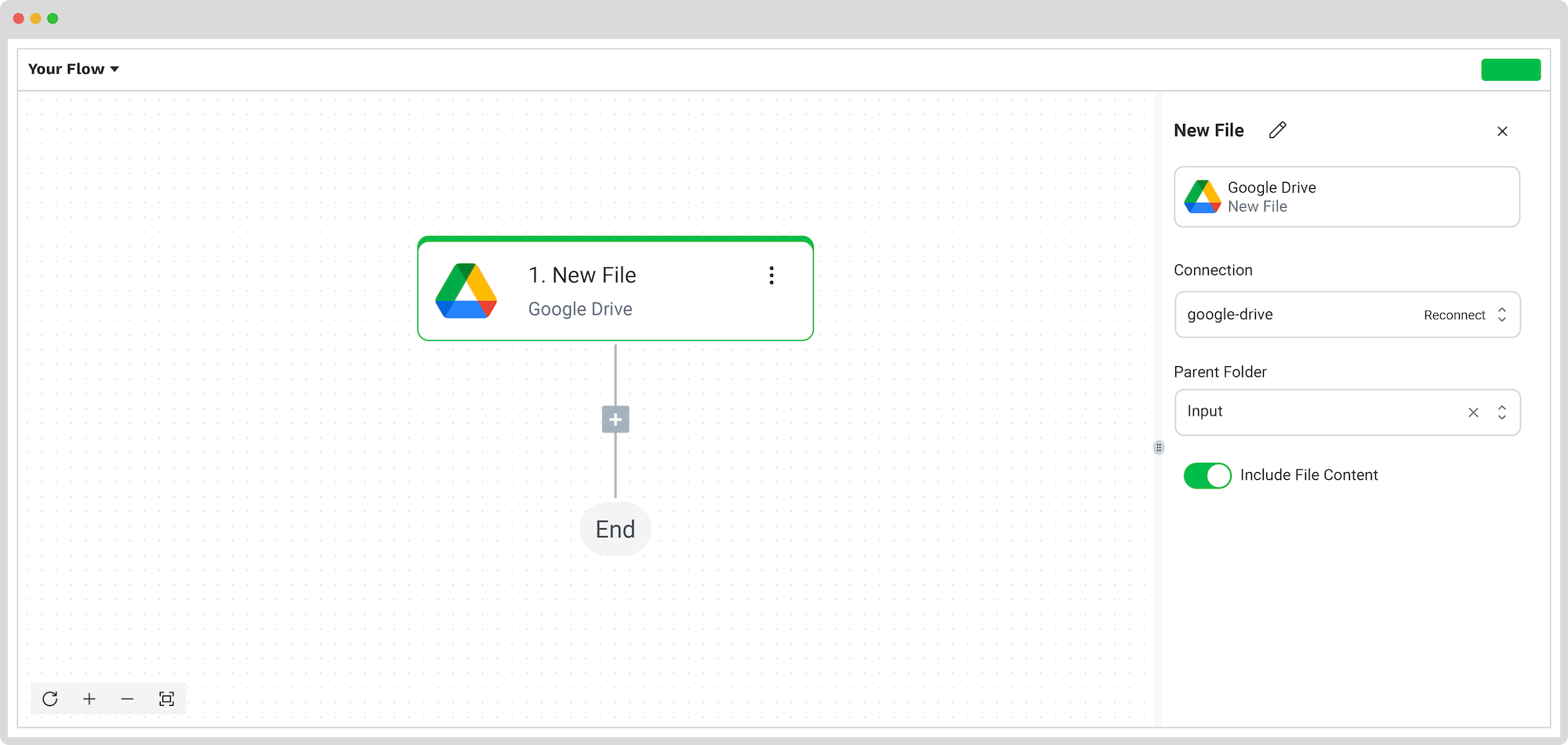
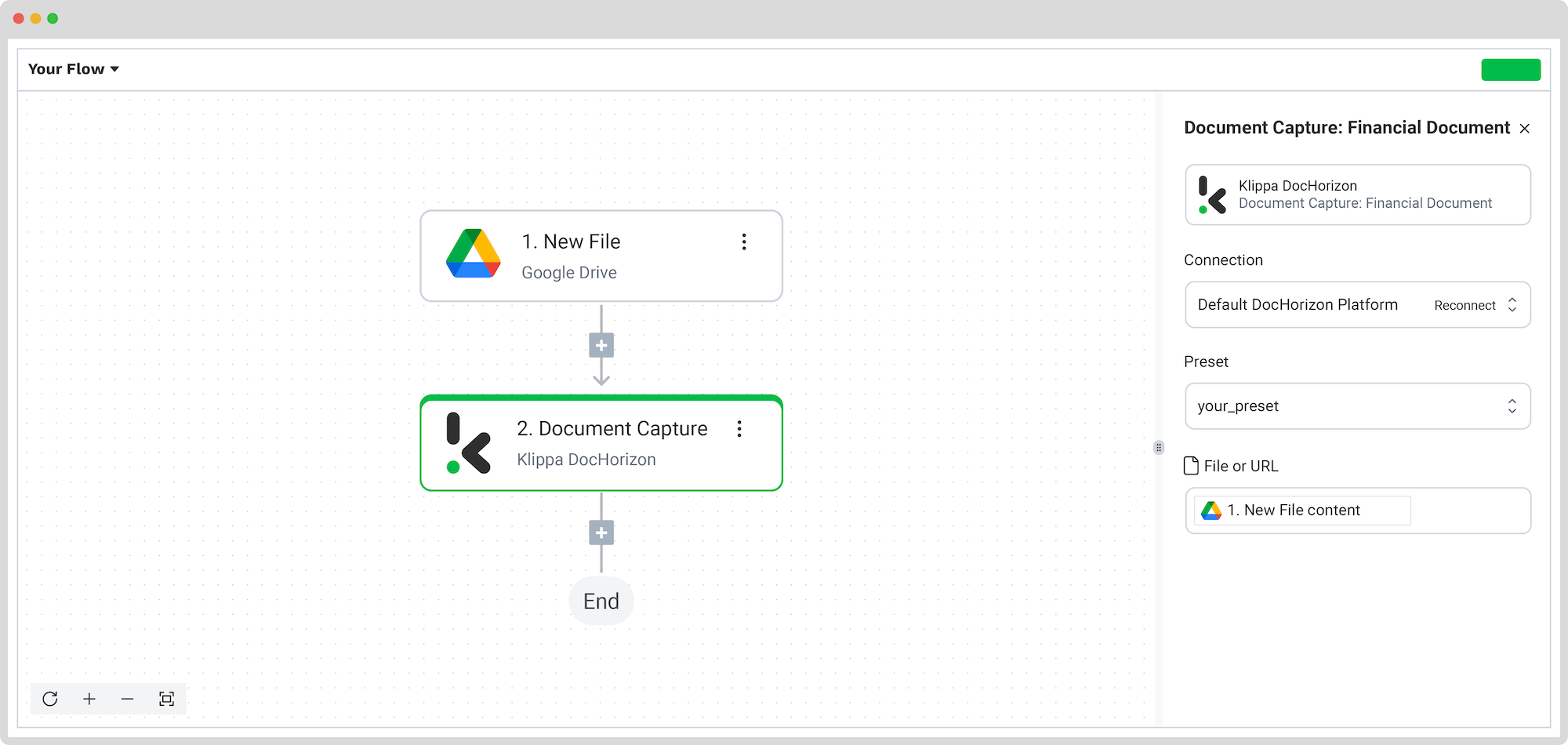
Étape 4 : Capturez et extrayez les données
- Ajoutez une étape pour Capture de documents : Modèle financier.
- Sélectionnez votre préréglage et configurez le champ Fichier ou URL.
- Testez pour vérifier que tout fonctionne correctement.
Étape 5 : Configurez la destination de sortie
- Choisissez où envoyer les données extraites (par exemple, Google Drive).
- Spécifiez le nom du fichier (par exemple, numéro de facture).
- Testez pour vérifier que le fichier est créé avec toutes les données nécessaires.
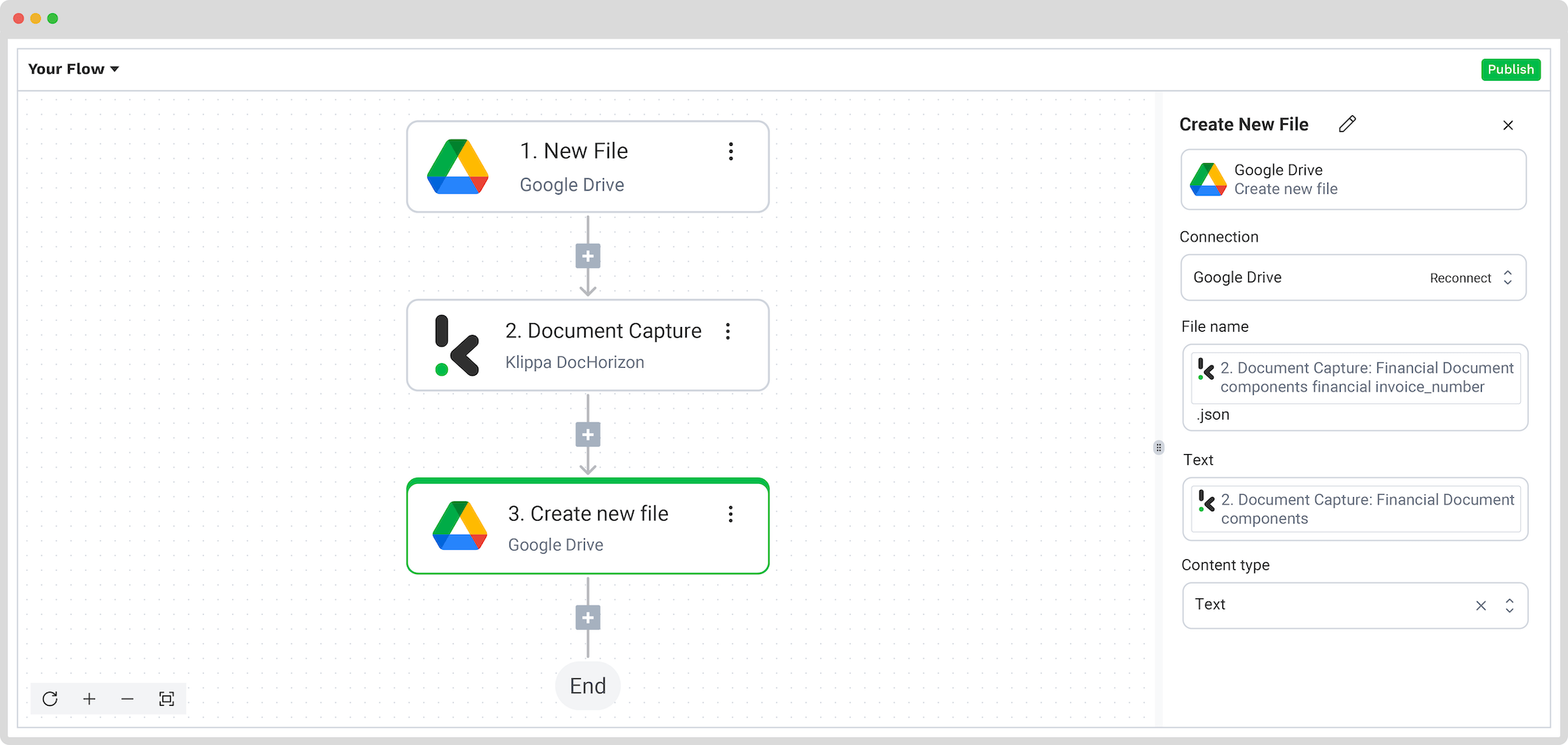
Enfin, testez l’ensemble du flux pour confirmer que tout fonctionne comme prévu. Et voilà ! Votre flux automatisé pour l’extraction des données des fichiers PDF est complet.
Et n’oubliez pas : si vous traitez un grand volume de documents, vous n’avez pas à configurer le flux vous-même ! N’hésitez pas à nous contacter car nous serions ravis de vous aider !
Améliorez l’extraction de données de vos fichiers PDF avec Doxis
Parmi les 5 méthodes présentées, la manière la plus fiable et la plus rapide d’extraire des données des fichiers PDF est, sans aucun doute, via une solution d’extraction automatisée des données.
Une plateforme comme Doxis AI.dp peut facilement être intégrée aux logiciels et applications existants grâce à l’utilisation de l’API Doxis. Mais comment cela fonctionne-t-il concrètement en coulisses ? Voyons cela étape par étape :
- Téléchargement du document PDF sur l’API – Le document PDF doit être téléchargé sur l’API. Il est important que le contenu du PDF soit clair et qu’il n’y ait pas de bruit de fond. Le fichier peut être téléchargé via notre application mobile ou web.
- Prétraitement du document PDF – Les caractéristiques du document sont améliorées pour augmenter la précision de la reconnaissance. Cela inclut, par exemple, l’optimisation de la luminosité d’un scan ou l’amélioration des niveaux de gris du document.
- Conversion de l’image en texte – Le logiciel convertit automatiquement le document PDF en fichier texte (TXT). Les données du PDF sont ensuite extraites, mais elles ne sont pas encore structurées.
- Conversion en sortie structurée – Le parseur de Doxis convertit le fichier texte en JSON. À partir de là, vous pouvez facilement traiter les données extraites du PDF dans votre base de données ou logiciel.
La reconnaissance optique de caractères est le produit central de Doxis. Notre logiciel OCR est alimenté par l’IA et le machine learning ce qui en fait l’un des plus précis et rapides sur le marché.
Nous aidons les entreprises à se soucier moins de la délégation des tâches de maintenance et permettons à votre équipe de profiter d’un logiciel facile à utiliser qui vous fera gagner du temps et de l’argent.
Si vous souhaitez essayer notre solution, n’hésitez pas à nous contacter ou à planifier une démo gratuite ci-dessous.
FAQ
Les PDF sont conçus pour préserver la mise en forme, et non pour structurer les données, ce qui rend difficile l’isolement et l’extraction d’informations sans outils spécialisés.
Oui, les solutions OCR avancées utilisent des techniques de prétraitement telles que l’optimisation de la luminosité et du contraste pour améliorer la reconnaissance sur des scans de mauvaise qualité.
Doxis extrait des données structurées telles que les numéros de factures, les informations sur les fournisseurs, les totaux, les informations sur la TVA, les lignes de détail et bien plus encore, notamment dans les documents financiers.
Absolument. Doxis prend en charge les téléchargements en masse et l’automatisation évolutive, ce qui le rend idéal pour les entreprises traitant des centaines ou des milliers de fichiers PDF.