Vous savez à quel point la gestion des reçus peut être frustrante si vous traitez des notes de frais, la comptabilité ou des opérations financières. Les reçus papier s’effacent, les reçus numériques se perdent dans les boîtes mail, et aucun format ne se ressemble. Saisir ces données manuellement est fastidieux, sujet aux erreurs et détourne vos équipes de tâches à plus forte valeur ajoutée.
Mais il existe une meilleure solution. L’automatisation élimine la corvée d’extraire instantanément les informations clés tout en garantissant la précision, sans effort manuel. Dans ce guide, nous vous expliquons comment fonctionne l’extraction des données des reçus, les défis courants auxquels les entreprises sont confrontées et comment des solutions basées sur l’IA peuvent transformer le processus.
Points clés
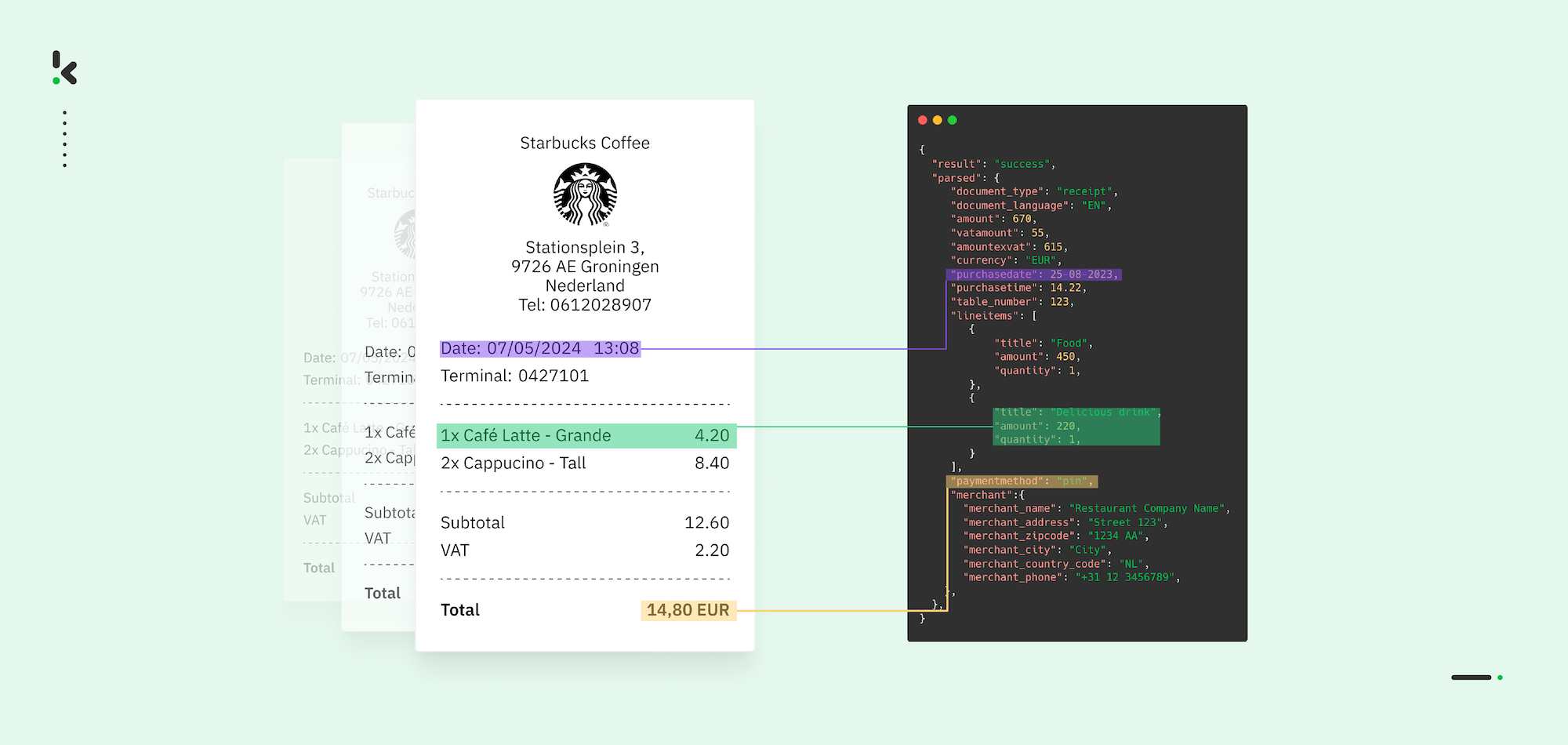
L’extraction des données des reçus automatise la conversion de textes non structurés en données structurées et lisibles par machine pour la comptabilité, la conformité et l’analyse. Un workflow type suit cinq étapes clés :
- Capture : Scannez ou photographiez un reçu papier, ou téléversez un PDF ou une image numérique.
- Conversion : Utilisez la reconnaissance optique de caractères (OCR) pour lire et numériser le texte.
- Extraction : Identifiez et capturez des champs tels que le nom du commerçant, la date, les totaux, les taxes, les remises et les achats détaillés.
- Structuration : Organisez les données dans des formats comme JSON, CSV, XML ou XLSX pour intégration.
- Vérification : Appliquez des règles de validation ou des contrôles Human‑in‑the‑Loop pour assurer la conformité et détecter la fraude.
Des solutions automatisées, comme Doxis AI.dp, combinent OCR, intelligence artificielle et machine learning pour gérer des formats variés, améliorer la précision et s’intégrer facilement aux systèmes ERP ou comptables.
Qu’est‑ce que l’extraction des données des reçus ?
L’extraction des données des reçus est le processus consistant à identifier et convertir les informations clés d’un reçu en données structurées et lisibles par machine, utilisables pour la comptabilité, les déclarations fiscales et la gestion des dépenses. Les informations scannées incluent généralement le nom du commerçant, la date, le montant, etc.
Traditionnellement, les entreprises s’appuyaient sur des collaborateurs pour saisir ces données dans des tableurs ou des logiciels comptables. Aujourd’hui, des solutions automatisées exploitent l’IA et l’OCR pour scanner les reçus, corriger les erreurs et extraire les valeurs pertinentes. Une fois extraites, ces données sont automatiquement formatées et intégrées aux systèmes de gestion des dépenses, aux logiciels comptables ou aux outils de reporting fiscal.
Méthodes pour extraire les données des reçus
Les entreprises peuvent extraire les données des reçus par des méthodes manuelles, semi‑automatisées ou entièrement automatisées. Le bon choix dépend de facteurs tels que le volume de reçus, la variabilité des formats, les exigences de précision et les ressources disponibles.
Saisie manuelle
La saisie manuelle consiste à taper les détails du reçu, comme le nom du commerçant, la date, le montant total et la TVA, dans des tableurs ou des logiciels comptables.
Avantages :
- Pas de configuration technique requise
- Faible coût pour des volumes de reçus très faibles
Inconvénients :
- Extrêmement chronophage pour des volumes importants
- Sujet aux erreurs humaines, entraînant des risques de non‑conformité et d’erreurs de reporting
- Difficile à faire évoluer pour une entreprise en croissance
Astuce : n’utilisez la saisie manuelle que pour des reçus occasionnels ou comme solution de secours lorsque les systèmes automatisés ne peuvent pas traiter un document.
OCR basé sur des templates
L’OCR basé sur des templates (gabarits) utilise des mises en page prédéfinies pour lire les reçus. Le système analyse l’image, la compare à un template et extrait les données depuis des emplacements spécifiques.
Avantages :
- Grande précision pour des reçus aux mises en page standardisées
- Plus rapide que la saisie manuelle pour des formats cohérents
Inconvénients :
- Ne fonctionne pas avec des mises en page variées ou inconnues
- Ne s’adapte pas facilement à de nouveaux designs sans recréer des templates
- A des difficultés avec l’écriture manuscrite ou les images dégradées
Astuce : l’OCR basé sur templates convient aux organisations qui utilisent un ou deux formats fixes de reçus, comme des systèmes de point de vente internes.
OCR piloté par l’IA (ML/NLP)
L’OCR piloté par l’IA combine reconnaissance optique, machine learning (ML) et traitement du langage naturel (NLP) pour reconnaître, classer et interpréter des données sur des formats, langues et devises variés.
Avantages :
- Très adaptable aux différents layouts, polices et langues
- Peut traiter des images de faible qualité via des prétraitements (recadrage, redressement, ajustement du contraste)
- Automatise la classification des champs sans templates prédéfinis
Inconvénients :
- Nécessite des jeux de données d’entraînement pour une meilleure précision
- Peut avoir un coût initial plus élevé que des outils OCR basiques
Best Practice Tip: Choose AI‑enabled OCR tools when processing receipts from multiple sources with inconsistent designs, especially in global operations.
Validation Human‑in‑the‑Loop (HITL)
Human‑in‑the‑Loop combine l’extraction automatique et une revue humaine pour vérifier l’exactitude, corriger les mauvaises classifications et gérer les cas limites complexes.
Avantages :
- Atteint une précision quasi parfaite
- Détecte les fraudes ou erreurs subtiles que l’automatisation peut manquer
- Apporte de la flexibilité pour des reçus irréguliers ou atypiques
Inconvénients :
- Augmente le temps de traitement par rapport à l’extraction entièrement automatisée
- Nécessite du personnel formé pour la relecture
Astuce : utilisez le HITL pour les workflows critiques où une erreur peut avoir des conséquences financières ou réglementaires, comme les audits fiscaux ou les remboursements sensibles.
Les formats inconsistants, la mauvaise qualité d’image et la variabilité des règles fiscales rendent l’extraction des reçus difficile pour la plupart des entreprises. Pour une efficacité durable, de nombreuses organisations adoptent des approches hybrides : OCR piloté par l’IA en première ligne, soutenu par le Human‑in‑the‑Loop pour les tâches où la précision est critique.
Quelles données peut-on extraire des reçus ?
Les reçus contiennent des détails financiers et transactionnels essentiels pour le suivi des dépenses, la conformité fiscale et l’automatisation comptable. Voici les principaux éléments à capturer :
1. Détails de la transaction
Informations qui vérifient quand et où l’achat a eu lieu.
- Date & heure : Horodatage exact de la transaction.
- ID de transaction : Numéro de référence unique pour le suivi.
- Nom du commerçant : Nom de l’enseigne émettrice.
- Localisation du point de vente : Adresse du magasin ou de l’agence.
2. Informations sur l’achat
Lignes d’articles présentes sur le reçu qui décrivent l’achat.
- Descriptions des articles : Détail des biens ou services achetés.
- Quantité : Nombre d’unités par article.
- Prix unitaire : Coût par unité hors taxes.
- Total par article : Prix final par ligne (quantité × prix unitaire)
3. Récapitulatif financier
Récapitule la structure des coûts de la transaction.
- Sous‑total : Total avant taxes, remises et frais.
- Taxes : TVA, taxe de vente ou autres charges appliquées.
- Remises/Promotions : Réductions, récompenses fidélité ou coupons.
- Montant total payé : Montant final après tous calculs.
- Devise : Devise utilisée pour les montants facturés.
4. Informations de paiement
Identifie le mode de règlement utilisé.
- Mode de paiement : Espèces, carte, wallet mobile ou autre.
- Détails de la carte : Quatre derniers chiffres de la carte utilisée, si présents.
- Monnaie rendue : Pour paiements en espèces, montant rendu au client.
5. Données spécifiques au commerçant
Inclut éléments de marque et données de suivi internes.
- Numéro de reçu : Référence interne assignée par le commerçant.
- ID du caissier : Identifie l’employé ayant traité la vente.
- Logo & éléments de branding : Utilisés pour l’identification et la reconnaissance.
- Messages sur le reçu : Notes personnalisées comme politiques de retour, promotions ou remerciements.
6. Données numériques et lisibles par machine
Informations additionnelles encodées dans les reçus digitaux ou imprimés.
- QR Codes & codes‑barres : Liens vers des reçus numériques ou infos produit.
- Catégories d’articles : Catégorisation pour l’analyse (ex. épicerie, électronique).
- Détails programme de fidélité : Points gagnés ou utilisés durant la transaction.
7. Données transactionnelles additionnelles
Varient selon le type d’achat.
- Numéro de commande : Référence pour le suivi de commande (restauration, e‑commerce).
- Détails de livraison : Instructions d’expédition ou de retrait si applicable.
- Frais de service & pourboires : Charges additionnelles dans l’hôtellerie et la restauration.
Principaux défis de l’extraction des données des reçus
L’extraction des données depuis des reçus peut sembler simple, mais les entreprises rencontrent souvent des limites techniques qui nuisent à la précision et à l’efficacité des solutions semi‑automatisées ou basées sur templates. Voici les principaux défis :
- Formats inconsistants : Les mises en page, polices et structures varient énormément entre commerçants et lieux, nécessitant un parsing IA flexible.
- Types de fichiers mixtes : Les reçus peuvent être imprimés, PDF, reçus par e‑mail ou photographiés, chacun nécessitant des méthodes d’extraction différentes.
- Écritures manuscrites & textes difficiles à lire : Certains petits commerçants utilisent encore des reçus manuscrits, plus complexes pour l’OCR.
- Détérioration ou dommages : Le papier thermique s’efface avec le temps et les impressions de mauvaise qualité nécessitent une amélioration d’image avant extraction.
- Variabilité des taxes & remises : Les différences d’affichage des taxes et remises compliquent la capture financière cohérente.
- Différences de devise & de langue : Les changements de format selon les pays exigent une localisation pour éviter les erreurs d’interprétation.
- Distorsions lors de la capture mobile : Ombres, angles et reflets des photos nécessitent des corrections automatisées pour améliorer la lisibilité.
- Erreurs de validation : Même un OCR précis peut mal classer des champs sans contrôles automatisés ou revue Human‑in‑the‑Loop.
Répondre à ces défis requiert une combinaison d’OCR piloté par l’IA, de classification intelligente des données et d’algorithmes de validation pour garantir une haute précision sur différents types de reçus. Tous ces composants sont disponibles dans des plateformes IDP comme Doxis AI.dp.
Avantages de l’automatisation de l’extraction des reçus
Automatiser l’extraction des données des reçus remplace une saisie lente et sujette aux erreurs par des workflows rapides et précis. Les principaux bénéfices incluent :
- Gain de temps : Traitez de grands volumes de reçus en secondes au lieu d’heures, libérant vos équipes pour des tâches à plus forte valeur.
- Plus grande précision : L’OCR piloté par l’IA réduit les erreurs humaines, assurant des enregistrements financiers fiables et des pistes d’audit plus propres.
- Scalabilité : Gérez facilement des milliers de reçus par mois sans augmenter les effectifs.
- Conformité améliorée : Capture automatique des détails fiscaux et de paiement pour les rapports réglementaires à travers plusieurs juridictions.
- Réduction des coûts : Diminuez les dépenses opérationnelles en supprimant les équipes de saisie et de validation manuelle.
- Intégration prête : Sorties structurées (JSON, CSV, XML, XLSX) se connectant sans couture aux ERP, systèmes comptables et plateformes analytiques.
- Prévention de la fraude : Vérifications intégrées et détection des doublons protègent contre les réclamations frauduleuses et les faux reçus.
L’extraction automatisée améliore la vitesse, la précision et la sécurité tout en réduisant les coûts, que vous utilisiez une appli OCR simple ou une plateforme IDP complète comme Doxis AI.dp.
Comment extraire automatiquement les données des reçus avec Doxis
Des solutions basées sur l’IA comme Doxis AI.dp peuvent automatiser l’ensemble du processus d’extraction des données des reçus, de la soumission au dépôt des informations structurées dans votre système préféré.
Suivons ensemble un processus étape par étape pour extraire des données d’un reçu avec Doxis AI.dp. Pour notre exemple, nous traiterons des reçus PDF depuis Google Drive comme source d’entrée et choisirons JSON comme format de sortie.
Et le meilleur dans tout ça ? Vous pouvez l’essayer gratuitement !
Étape 1 : Inscrivez‑vous sur la plateforme
La première étape consiste à créer gratuitement un compte sur la plateforme AI.dp. Saisissez votre adresse e‑mail et un mot de passe, puis renseignez vos coordonnées : nom complet, nom de l’entreprise, cas d’usage et volume de documents. Une fois inscrit, vous recevrez un crédit gratuit de 25€ pour explorer toutes les fonctionnalités de la plateforme.
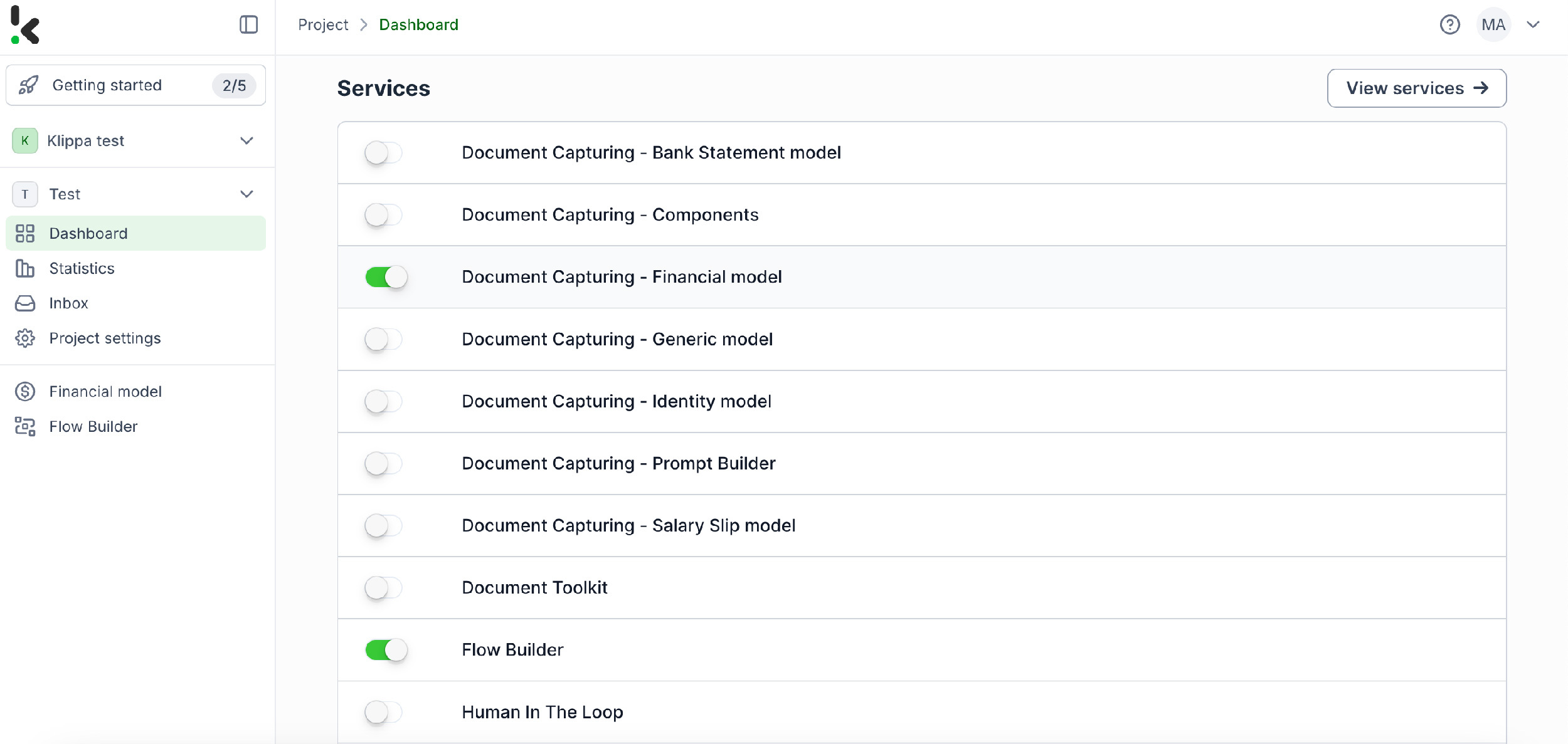
Après connexion, créez une organisation et configurez un projet pour accéder aux services. Pour notre objectif, l’extraction des données des reçus, activez simplement le Financial Model et le Flow Builder. Cette configuration vous garantit d’avoir tout ce dont vous avez besoin dès le départ !
Étape 2 : Créez un preset
Vous vous demandez peut‑être pourquoi activer le Financial Model plutôt qu’une autre option. Le Financial Model est conçu pour simplifier vos workflows financiers en automatisant l’extraction, l’analyse, la validation et la classification des données. Il traite efficacement une large gamme de documents financiers : reçus, factures, bons de commande, relevés bancaires, etc.
Une fois activé, créez un nouveau preset. Nommez‑le par exemple « Extract Data from Receipts ». Ce preset vous permet d’activer les composants nécessaires à votre cas d’usage. Pour cet exemple, activez les composants financiers et les lignes d’articles afin de traiter des champs spécifiques des reçus tels que le numéro de reçu, le commerçant, la date, le montant, la devise et les informations TVA.
Voici un conseil : vous pouvez personnaliser le preset selon vos besoins en activant d’autres composants comme Date Details, Reference Details, Amount Details, Document Language, Payment Details, etc.
Vous y êtes presque ! Cliquez sur « Save » pour finaliser vos paramètres et vous serez prêt pour l’étape suivante dans le Flow Builder.
Étape 3 : Sélectionnez votre source d’entrée
Après avoir créé votre preset et activé le Flow Builder, il est temps de construire votre flow. Un flow est essentiellement une séquence d’étapes définissant comment vos reçus sont traités et transférés vers la destination de sortie. Dans cette étape, nous allons choisir Google Drive comme source d’entrée.
Cliquez sur Nouveau flux → + à partir de zéro et donnez un nom à votre flow. Nous appellerons le flow « Receipt Data Extraction ».
Voici un conseil : la première étape pour construire votre flow est de sélectionner la source d’entrée. Vous avez plusieurs options : uploader des fichiers depuis votre appareil ou connecter plus de 100 sources externes, y compris Dropbox, Outlook, Salesforce, Zapier, OneDrive, la base de données de votre entreprise, ou des solutions de cloud comme Amazon S3 et iCloud. Veillez à placer tous vos reçus dans le même dossier pour qu’ils puissent être traités en masse si nécessaire.
Pour cet exemple, nous travaillerons avec des reçus PDF. Créez un dossier nommé « Input » dans Google Drive et téléversez vos reçus.
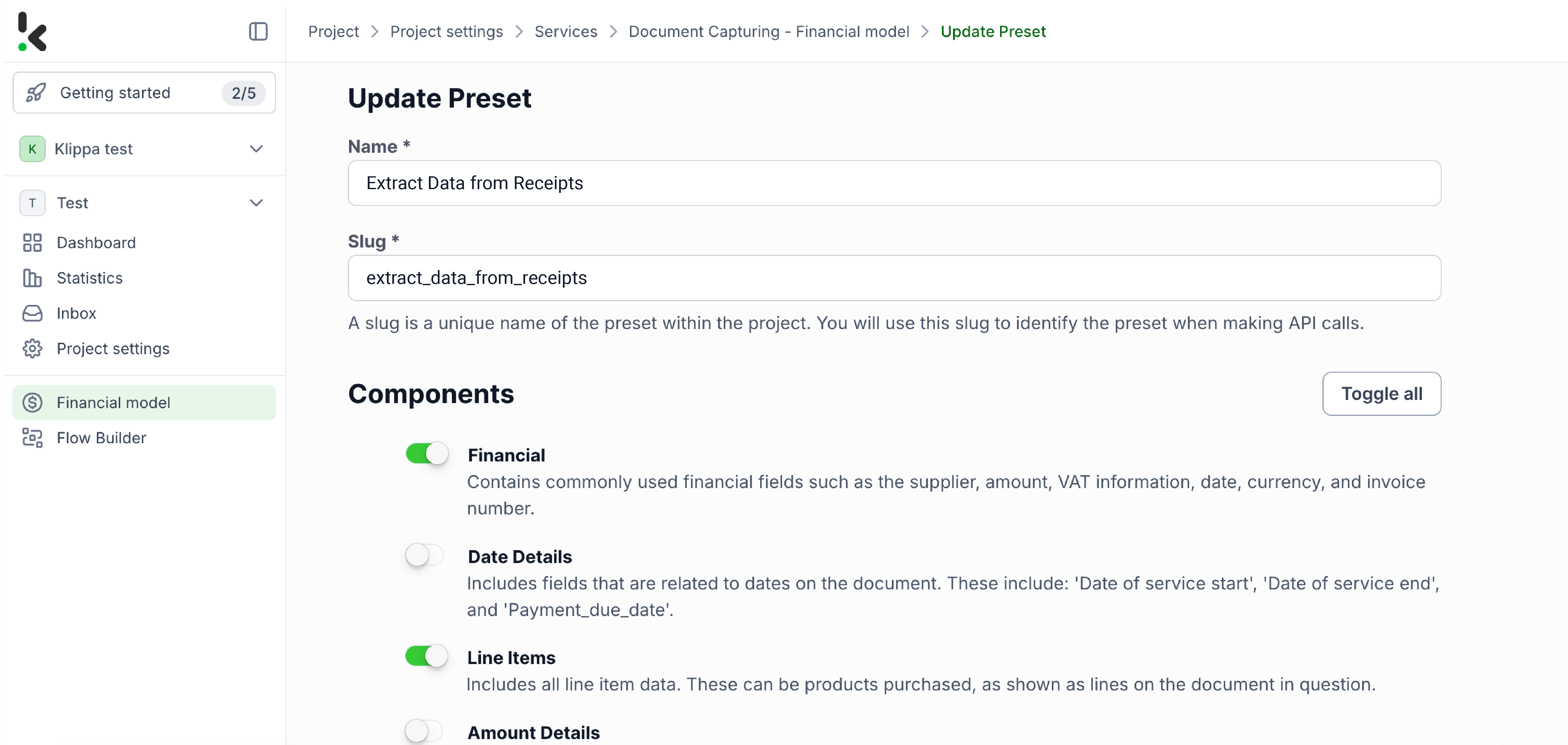
Ensuite, sélectionnez votre source d’entrée en choisissant « Google Drive » puis « Nouveau fichier » comme déclencheur. Cela lancera votre flow. Sur la droite, renseignez les sections suivantes :
- Connexion : Vous pouvez donner n’importe quel nom à la connexion. Par exemple, nous l’avons appelée « google-drive ». Une fois nommée, vous serez demandé de vous authentifier auprès de Google.
- Fichier parents : Entrée
- Inclure le contenu du fichier : Cochez cette case pour garantir que le contenu du fichier soit traité.
Testez cette étape en cliquant sur Charger Sample Data : n’oubliez pas d’avoir au moins un reçu exemple dans votre dossier d’entrée lors de la configuration du flow.
Voici un conseil : la plateforme supporte une large gamme de types de documents pour répondre à tous les besoins métiers ; consultez notre documentation pour en savoir plus.
Étape 4 : Capture et extraction des données
Il est maintenant temps d’extraire les données nécessaires en utilisant le preset créé précédemment pour traiter tous les champs sélectionnés depuis les reçus du dossier d’entrée.
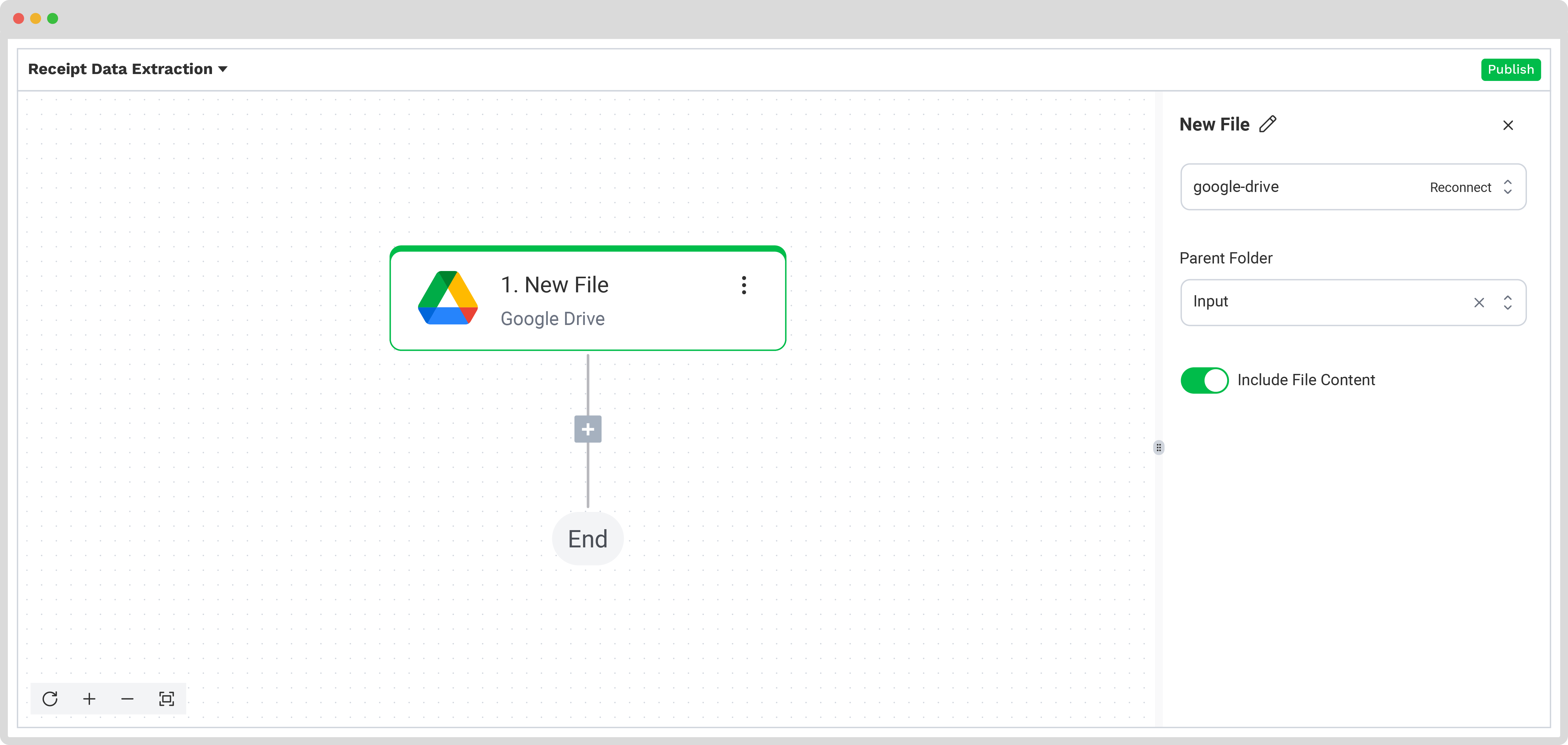
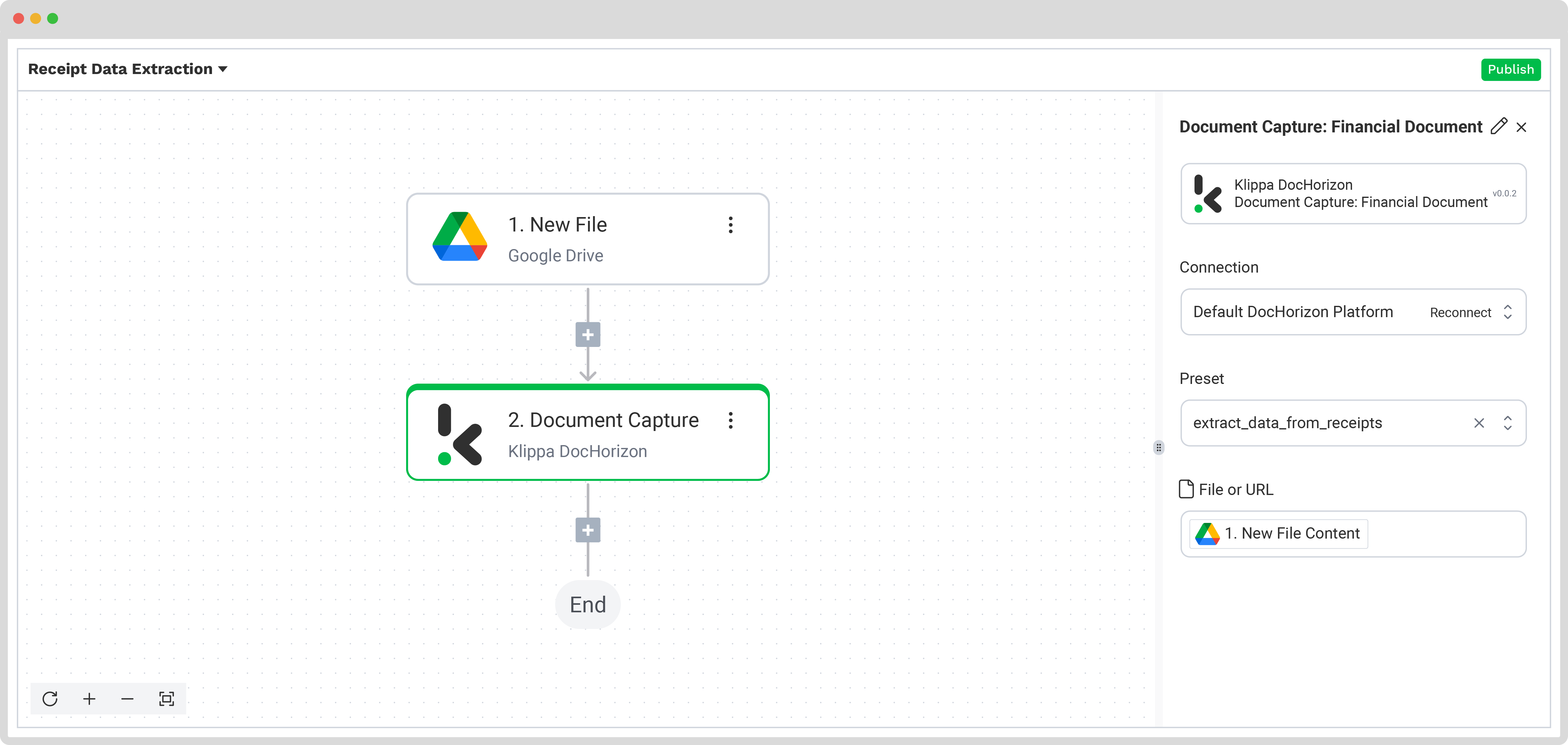
Dans le Flow Builder, appuyez sur le bouton + et choisissez Document Capture : Financial Document.
Pour continuer, configurez les éléments suivants :
- Connexion : Default AI.dp Platform
- Preset : Le nom de votre preset (dans notre cas « extract_data_from_receipts »)
- Fichier ou URL : Nouveau Fichier → Contenu
Puis, testez l’étape pour vous assurer que tout fonctionne correctement. Une fois le test concluant, vous êtes prêt pour l’étape suivante : sauvegarder vos résultats !
Étape 5 : Sauvegardez le fichier
Une fois le reçu traité, l’étape finale consiste à choisir la destination et le format de sortie final. La destination peut être votre base de données, votre ERP, votre logiciel de comptabilité ou toute autre plateforme selon votre workflow. Le format de sortie peut être JSON, XML, CSV, XLSX, UBL, PDF ou TXT.
Pour cet exemple, nous définirons le numéro de reçu comme nom de fichier contenant les données extraites et nous l’enregistrerons au format JSON. Nous créerons un nouveau dossier dans Google Drive, nommé « Output », et le définirons comme destination finale pour le fichier contenant les données extraites.
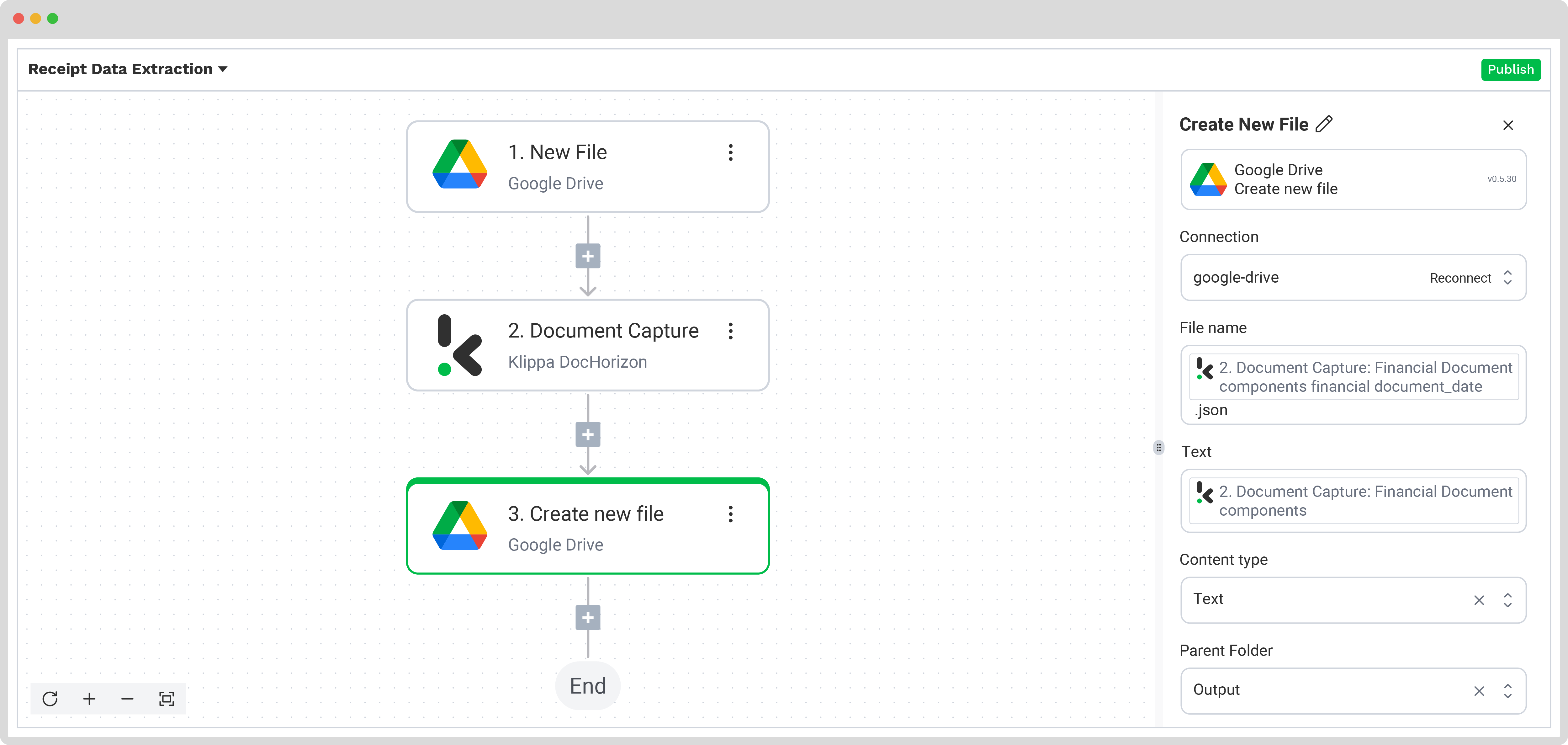
Appuyez sur le bouton + et sélectionnez Créer nouveau fichier→ Google Drive
To proceed, configure the following:
- Connexion : google-drive
- Nom du fichier : Document Capture: Financial Document → components → financial → receipt_number. Ajoutez ensuite .json
- Texte : Document Capture: Financial Document → components
- Voici un conseil : sélectionnez le texte que vous souhaitez inclure dans le nouveau document. En sélectionnant « components » vous incluez tous les éléments extraits.
- Type Contenu : Text
- Fichier parent : Output (nom du dossier de sortie)
Testez cette étape en cliquant sur le bouton en bas à droite, et le tour est joué !
Et voilà ! Toutes les données des reçus sont désormais disponibles dans votre dossier Google Drive. Avec cette configuration en place, vous pouvez publier le flow et tout nouveau reçu ajouté au dossier sera traité automatiquement. Voilà comment vous gagnez du temps tout en garantissant la fiabilité de vos workflows.
En plus des reçus, vous traitez peut‑être aussi des factures. Si c’est le cas, consultez notre guide d’extraction des données de factures.
Sachez que vous n’avez pas à tout faire seul. N’hésitez pas à nous contacter si vous traitez de gros volumes de documents ou si vous avez un cas d’usage particulier. Nous serions ravis de connaître votre projet !
Cas d’usage courants pour l’extraction automatisée des reçus
L’extraction automatisée des données des reçus améliore la rapidité, la précision et la conformité de nombreux workflows métiers. Applications courantes :
Rapport des dépenses
Capture automatique des détails des reçus et liaison aux rapports de frais employés, réduisant la saisie manuelle et améliorant la précision des remboursements.
Déclarations des taxes et conformité
Extraction de la TVA, GST ou autres taxes pour garantir des déclarations précises et l’état d’audit. La catégorisation automatisée simplifie les clôtures annuelles et réduit les risques de non‑conformité.
Remboursements des employés
Fluidifiez les workflows d’approbation en vérifiant les détails des reçus, en contrôlant les règles internes et en accélérant les remboursements.
Détection des fraudes
Identifiez les reçus en double, altérés ou falsifiés grâce à des vérifications et au hachage d’images. Aide à prévenir les réclamations abusives et les pertes financières.
Analyses retails
Analysez les données détaillées des reçus pour suivre les ventes par produit, les préférences clients et la performance par catégorie. Soutient les programmes de fidélité et la mesure des campagnes promotionnelles.
Demandes de remboursement dans l’assurance
Vérifiez les preuves d’achat pour la validation des sinistres, réduisant les délais de traitement et minimisant les paiements frauduleux.
Gestion des dépenses pour subventions
Documentez les dépenses éligibles pour les projets subventionnés, assurant transparence et conformité aux règles de financement.
Automatisez l’extraction des données des reçus avec Doxis AI.dp
Vous souhaitez extraire des données de reçus vers Google Sheets, Excel, JSON et plus encore ? Nous avons la solution. Avec Doxis AI.dp, vous pouvez automatiser tous vos workflows :
- Extraction des données OCR : extraction automatique des données depuis n’importe quel reçu.
- Programme de fidélité : automatisation du clearing pour les programmes de fidélité.
- Human‑in‑the‑Loop : précision proche de 100 % grâce à la validation interne ou au support de l’équipe d’annotation Doxis.
- Conversion de documents : conversion de PDF, images scannées ou documents Word en formats métiers prêts à l’emploi (JSON, XLSX, CSV, TXT, XML, etc.).
- Anonymisation des données : protection des informations sensibles et conformité réglementaire en anonymisant les données personnelles.
- Vérification documentaire : authentification automatique des documents et détection des fraudes.
Chez Doxis, nous attachons une grande importance à la confidentialité ; c’est pourquoi tous nos workflows documentaires sont conformes aux normes HIPAA, GDPR et ISO, garantissant un traitement sécurisé des données. Avec la sécurité assurée, franchissez le pas et optimisez votre extraction des données des reçus.
Si vous souhaitez automatiser votre flux d’extraction des reçus avec la solution IDP de Doxis, n’hésitez pas à contacter nos experts pour plus d’informations ou à réserver une démo gratuite !
FAQ
Utilisez un outil OCR (reconnaissance optique de caractères) capable de scanner et lire des images ou des PDF de reçus, puis de les convertir en données structurées telles que JSON, CSV ou XML. Les solutions basées sur l’IA améliorent la précision en gérant des mises en page variées, des langues et des devises différentes.
L’OCR pour reçus est une technologie qui lit le texte des reçus scannés ou photographiés et le transforme en champs exploitables (nom du commerçant, date, totaux, taxes). Il remplace la saisie manuelle dans les workflows de gestion des dépenses et de comptabilité.
La précision dépend de la qualité de l’image, du format du reçu et du modèle OCR utilisé. Les solutions avancées combinant OCR, ML et NLP atteignent généralement plus de 90 % de précision et peuvent approcher la quasi‑perfection avec une validation Human‑in‑the‑Loop.
Oui. Les modèles modernes peuvent traiter des reçus multilingues et multi‑devise dans un même workflow, en s’adaptant automatiquement aux différentes conventions numériques et termes fiscaux.
Notes de frais, déclarations fiscales, remboursements, détection de fraude, analytics retail, sinistres assurance et suivi de subventions. Ces workflows bénéficient d’un traitement rapide, d’une meilleure précision et de données prêtes pour la conformité.
Capturez des images nettes et en haute résolution. Évitez les ombres, plis et reflets. Utilisez un outil offrant un prétraitement d’image (recadrage, redressement, ajustement du contraste) et des règles de validation pour confirmer l’exactitude des champs.
Choisissez des plateformes conformes au RGPD/HIPAA, qui utilisent le chiffrement, des environnements cloud sécurisés et l’anonymisation des données sensibles.
Oui. Nous proposons un essai gratuit avec 25 € de crédit pour tester vos workflows d’extraction des reçus.
Doxis AI.dp associe OCR, IA, classification avancée, détection de fraude, fonctionnalités de conformité et intégrations flexibles, adapté aux opérations à grand volume, multi‑format et multilingues nécessitant à la fois rapidité et précision.
JSON, CSV, XML, XLSX, PDF/A, TXT et plus, prêts à être intégrés à vos ERP, outils de comptabilité ou plateformes analytiques.