
O uso da extração automatizada de dados de documentos pode transformar o seu negócio de formas incríveis. É bastante fácil de começar, mas perceber o que pode fazer por si pode ainda levar algum tempo.
Você ou os seus funcionários têm que processar centenas, milhares ou até mesmo milhões de documentos por mês manualmente? Gostaria de poder livrar-se deste processo? Felizmente, existe a solução perfeita para este problema: extrair automaticamente os dados de documentos.
Tem curiosidade em saber como isto funciona? Ou quer saber mais sobre a extração de dados? Então continue então a ler!
Neste blogue, vai adquirir uma melhor compreensão do significado, das técnicas, do processo, da importância e obterá a resposta à pergunta: “O que é a extração de dados?”.
O significado da extração de dados
Então, qual é o significado de extrair os dados de um documento? Basicamente, resume-se em recuperar vários tipos de dados a partir de uma ou várias fontes. Estas fontes são geralmente mal organizadas e completamente não estruturadas.
A extração dos dados permite-lhe processar, armazenar e analisar os dados. Estes tipos de dados são geralmente usados para melhorar as operações da empresa. É a base para a realização de uma análise crítica no processo de tomada de decisão.
Existem três formas de extração de dados: manual, automatizada e humana (que é uma combinação das duas primeiras).
Agora que já sabemos o que é a extração de dados, vamos continuar com a importância do processo.
Porque é que a extração de dados é importante?
Imagine que é um banco, que oferece hipotecas a compradores de casas. Por lei, é obrigatório fazer verificações KYC, registar o rendimento do comprador e provavelmente mais.
Para tal, os clientes enviam documentos contendo esta informação. Esta informação tem de chegar à sua base de dados, ou ao seu sistema de tomada de decisões.
Infelizmente, os dados não estão estruturados, resultando no facto de ser necessária uma equipa de backoffice para identificar a presença de informações sobre documentos, tais como o salário na folha de pagamento. Para além disso, a informação precisa de ser introduzida nos seus sistemas digitais.
Trata-se de uma tarefa dispendiosa, desgastante e enfadonha, mas não tem necessariamente de o ser! De facto, muitas empresas estão a tirar partido de soluções e técnicas de extração automatizadas, em que é utilizado a IA, para gerir o processo de extração de dados desde o início até ao fim.
As principais vantagens da utilização de uma solução de extração automatizada são:
- Precisão melhorada
- Aumento da produtividade dos empregados
- Redução de custos
- Poupança de tempo
- Escalabilidade
- Tempo de resposta mais rápido
Precisão melhorada
A substituição da extração manual – por extração de dados automatizada diminui drasticamente a possibilidade de erros humanos. Por conseguinte, resulta numa maior precisão.
Caso esteja a processar grandes quantidades de dados, as probabilidades são altas de que possa haver algumas imprecisões e erros devido a erros humanos. Sem qualquer tipo de verificação, a introdução de dados manual tem uma taxa de erro de 4%.
A automatização do processo da extração de dados de documentos, levará a dados mais precisos em geral. Uma maior precisão não só conduz a melhores decisões empresariais, como também é muito vantajosa para os funcionários. Isto leva-nos à vantagem seguinte.
Aumento da produtividade dos empregados

Ao acabar com a extração manual de dados e substituí-la por uma ferramenta automatizada, os funcionários podem gastar mais tempo em tarefas importantes. Algumas tarefas só podem ser feitas por humanos. Assim, permita que os seus empregados façam essas e as tarefas que podem ser automatizadas por uma ferramenta de extração de dados automatizada.
A satisfação dos seus funcionários não só vai aumentar porque os empregados são dispensados de tarefas entediantes, como também os empregados podem concentrar-se em tarefas mais importantes. Isto levará a uma maior satisfação, o que (a longo prazo) levará a uma maior produtividade.
Redução de custos
Ao escolher uma ferramenta de extração de dados, o seu negócio pode tanto poupar dinheiro a curto como a longo prazo.
A curto prazo, a sua empresa pode poupar muito dinheiro, reduzindo erros de introdução manual de dados. A longo prazo, a sua empresa não precisa de se preocupar em dimensionar e financiar uma grande equipa para atender às necessidades de dados da sua empresa. Assim, os sistemas automatizados de introdução e extração de dados têm vindo a aumentar.
Redução de tempo
Estudos revelam que a automatização inteligente resulta geralmente em economias de custos de 40 a 75%. Tempo é dinheiro, e por isso pode ser um dos maiores pontos de venda de uma ferramenta de extração de dados.
Escalabilidade
Quando uma empresa está a crescer, a quantidade de documentos recebidos também está a crescer. Se a extração de dados de documentos ainda é feita manualmente, a quantidade de documentos vai-se amontoando.
Isto pode ser evitado através da mudança para um sistema automatizado. Como resultado, a empresa pode crescer sem ter de se preocupar com grandes volumes de dados espalhados por aí, ou ter de contratar uma mão-de-obra imensa.
Tempo de resposta mais rápido
Devido à extração automatizada de dados, os tempos de retorno podem ir de dias ou semanas a segundos. Se um humano tem de verificar manualmente um documento, apenas um documento pode ser feito processado de cada vez. Além disso, as pessoas só podem trabalhar 8 horas por dia.
Desafios
Se há vantagens, deve haver também alguns desafios em relação à extração de dados. Estes são os dois desafios:
- A proteção dos dados confidenciais pode ser desafiante. Um exemplo de dados confidenciais são os dados financeiros. Portanto, a segurança na extração de dados deve ser garantida. É importante trabalhar com soluções de software que possam provar que sua segurança é testada regularmente e que podem cumprir com a GDPR e outras legislações.
- Outro desafio é a coerência dos dados extraídos de várias fontes. O desafio é ainda maior se essas fontes não estiverem estruturadas, uma vez que ainda é preciso garantir que estas funcionem em conjunto. Os sistemas com IA podem ser treinados para combinar os dados e torná-los adequados para as operações após o processamento.
Felizmente, a maioria das soluções de extração de dados são acompanhadas por uma equipa de assistência técnica para o ajudar com estes desafios. Agora, vamos avançar com os tipos de dados que podem ser extraídos.
Tipos de dados
Os dados podem ser classificados de acordo com a estrutura da fonte:
- Dados estruturados: A fonte de dados tem uma estrutura lógica. Por conseguinte, já é bastante conveniente para extração. Não é necessário trabalhar ou manipular os dados antes do processo de extração de dados. Exemplos disso são os ficheiros CSV e XML.
- Dados não estruturados: A maioria dos dados existe de uma forma não estruturada. As fontes de dados não estruturados poderiam ser, por exemplo, PDFs, textos digitalizados, páginas web, e-mails ou imagens. Os dados não estruturados têm de ser filtrados para uma extração de dados. Exemplos poderiam ser a remoção de espaços brancos, resultados duplicados e outros “ruídos” que têm de ser limpos do documento.

Tipos de técnicas de extração de dados
Existem duas técnicas diferentes relativamente à extração de dados: a extração lógica e a extração física.
Extração lógica
A extração lógica é a técnica mais utilizada e pode ser dividida em dois tipos:
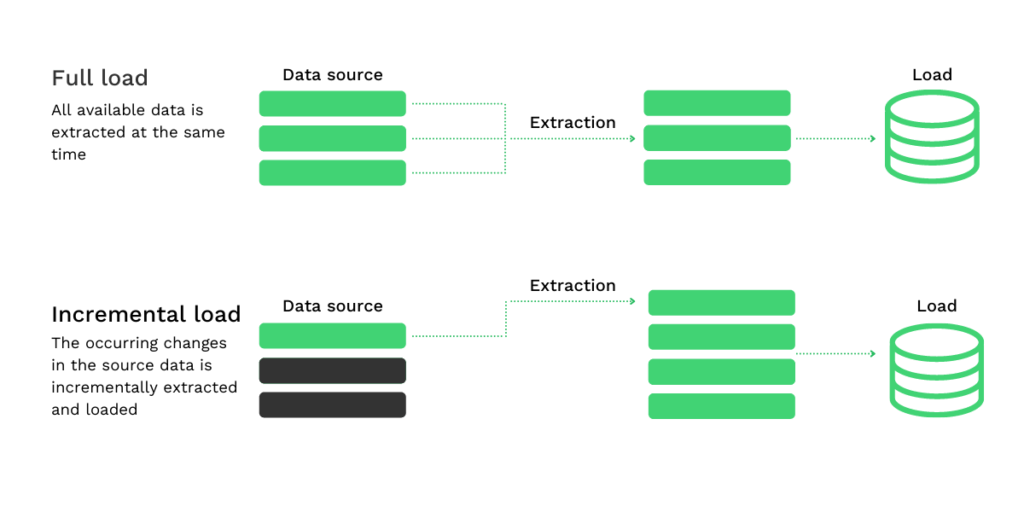
- Extração completa: Todos os dados são totalmente extraídos. A extração completa é um método utilizado quando os dados têm de ser extraídos e carregados pela primeira vez. Reflecte os dados que estão disponíveis nesse momento no respectivo sistema.
- Extração incremental: Desde a última extração de dados bem sucedida (dada por um carimbo de data/hora), as alterações ocorridas nos dados de origem são seguidas. Estas alterações são então extraídas e carregadas de forma incremental.
Extração física
Se for difícil extrair dados de sistemas de armazenamento de dados expirados ou restritos utilizando a extração lógica, a aplicação de técnicas de extração física é a única forma de obter estes dados. A extração física pode ser dividida em dois tipos, que são os seguintes:
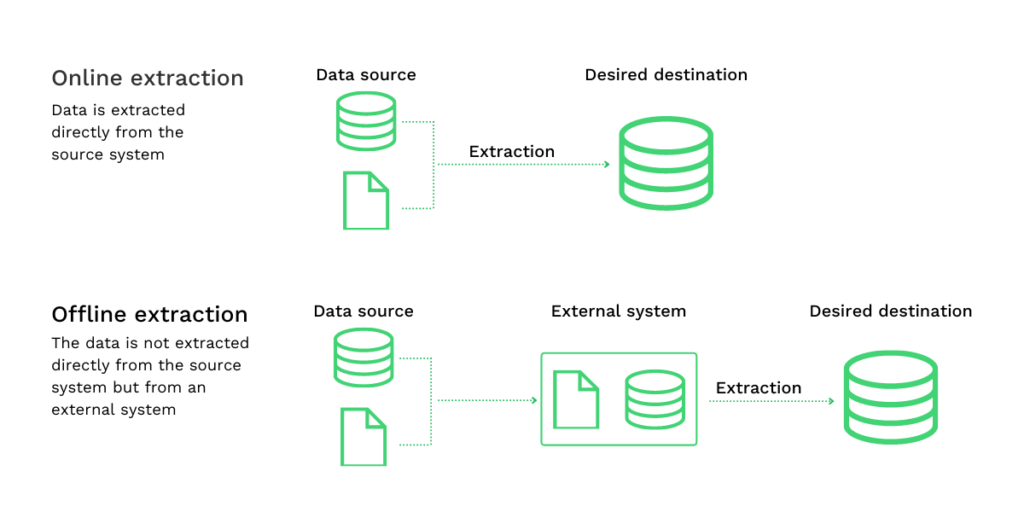
- Extração online: Existe uma ligação direta entre o sistema fonte e o arquivo final. Com o método de extração online, os dados extraídos são mais estruturados do que os dados da fonte.
- Extração offline: A extração de dados efectiva tem lugar fora do sistema de origem. Em processos de extração offline, os dados ou são estruturados por si mesmos ou serão estruturados através de rotinas de extração.
Exemplo de extração de dados
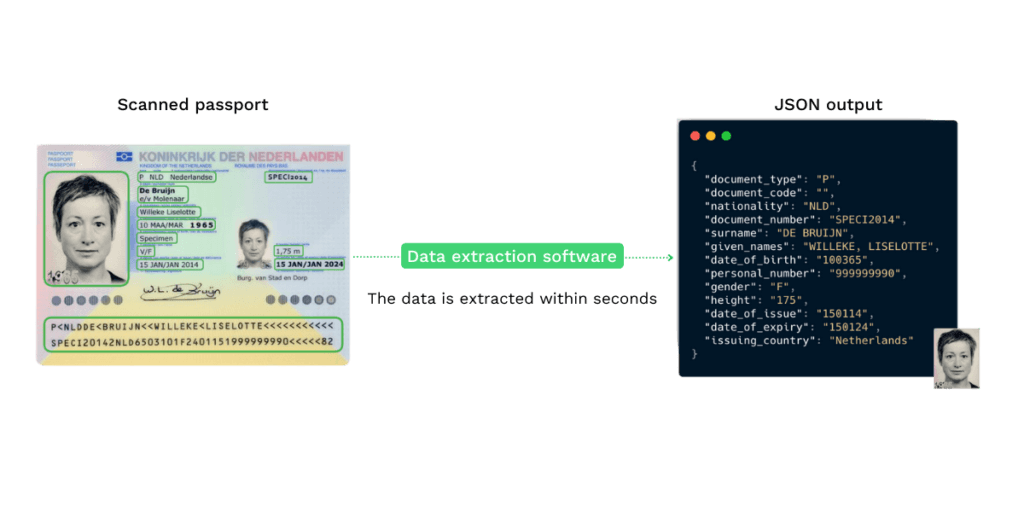
Vamos então ver o que uma solução de extração pode fazer por si. Vamos dar o exemplo de um passaporte.
Digamos que o seu cliente carregou este passaporte à esquerda num processo KYC e utiliza uma ferramenta de extração de dados para obter a informação de que necessita. Por exemplo, o nome completo, o número do documento e o MRZ.
Dentro de 3 segundos o sistema é capaz de transformar a imagem não estruturada nos dados estruturados como pode ver na imagem à direita abaixo.
A solução de extração na nuvem da Klippa
A Klippa é uma empresa de Processamento Inteligente de Documentos. O software que construímos é feito para automatizar processos empresariais que envolvem documentos. As nossas soluções ajudam a aumentar a produtividade, eficiência, reduzir custos e erros humanos.
A Klippa oferece uma solução completa de extração de dados documentais na nuvem, que ajuda as empresas a processar automaticamente qualquer tipo de documento numa questão de segundos.
Como funciona o processo de extração de documentos não estruturados?
Mas como é feita a extração de dados? O processo de extração de dados de um documento pode ser explicado brevemente em algumas etapas, que são as seguintes:
1. Upload do documento
Em primeiro lugar, o documento em papel tem de se transformar num documento digital. Normalmente, isto é feito através da digitalização do documento com um telemóvel. Também pode ser feito através do upload de um ficheiro para o sistema. A entrada pode ser em múltiplos formatos, tais como JPG, PDF, PNG, TXT e muito mais.
2. Imagem para TXT
Assim que upload está terminado, a extração de dados propriamente dita pode começar. O único problema é que o computador não consegue ler o que está no documento ou na imagem. Por conseguinte, tem de ser transformado num ficheiro TXT. Para esse efeito, entra em jogo o Reconhecimento Ótico de Caracteres (OCR). Esta tecnologia extrai todos os dados do documento, mas ainda não está estruturado.
3. Análise JSON
Na etapa final, é necessário um analisador para ler e compreender o texto do ficheiro. O analisador converte o ficheiro TXT para um ficheiro JSON estruturado. Uma vez terminada a conversão, os dados podem ser facilmente processados na base de dados. Além do JSON, outros resultados como XML, XLSX e CSV também são possíveis. O nosso OCR API é muito versátil.
4. Verificar os dados extraídos com fontes de terceiros
Opcionalmente, podemos também verificar os dados extraídos com fontes de terceiros. Esta pode ser a sua própria base de dados, mas também as bases de dados da Câmara de Comércio. Isto assegura a boa qualidade dos dados e está em conformidade com os regulamentos.
API de extração de dados
A solução de extração de dados acima referida está a ser utilizada por empresas em todo o mundo e em diversas indústrias. Exemplos de indústrias são os serviços financeiros (por exemplo, nos processos KYC), retalho (por exemplo, campanhas de fidelidade), contabilidade, alfândegas e cuidados de saúde.
A implementação de uma API de terceiros para a extração de dados em documentos é uma excelente opção. Através da nossa API, a solução pode ser integrada em qualquer software existente. Assim, os dados podem ser extraídos diretamente para o software.
Entre em contacto com os nossos especialistas
Se procura uma forma de aumentar a produtividade, melhorar a precisão, poupar tempo, permitir a escalabilidade e reduzir os custos, a solução de extração da Klippa é a escolha certa para si.
Gostaria de saber mais sobre o processo da extração e do método que utilizamos? Entre em contacto com um dos nossos especialistas, ou agende uma demonstração online gratuita através do formulário de demonstração abaixo.