Nous comprenons les difficultés auxquelles sont confrontées les entreprises d’aujourd’hui pour gérer et traiter un grand nombre de documents, qu’il s’agisse de reçus, de factures ou d’autres documents internes. Le traitement manuel de ces documents ouvre la porte aux erreurs d’extraction de données et à la fraude documentaire qui passe à travers les mailles du filet. En effet, une étude de Gartner suggère que le coût annuel des erreurs de saisie humaine s’élève à près d’un million de dollars.
C’est pourquoi la technologie de reconnaissance optique des caractères (OCR), alimentée par l’IA, a changé la donne pour les entreprises qui extraient des données de documents tels que des reçus, des factures ou des bons de commande. L’utilisation de l’OCR pour l’extraction et la reconnaissance des lignes offre une approche rationalisée du traitement de grandes quantités de données dans toute une série d’industries telles que la finance, la vente au détail, etc.
Dans ce blog, nous allons nous pencher sur les détails de l’extraction et de la reconnaissance des lignes d’articles, et sur la façon dont vous pouvez extraire les données des lignes d’articles à partir de reçus ou de factures avec Klippa. Plongeons dans le vif du sujet !
Pourquoi la reconnaissance et le traitement des données par ligne sont-ils utiles aux entreprises ?
À mesure que le monde progresse vers l’automatisation et l’IA, les entreprises ont de plus en plus de raisons de se demander comment l’automatisation peut les aider. Mais comment les entreprises peuvent-elles tirer parti de l’OCR pour l’extraction d’éléments de ligne ? Voici quelques cas d’utilisation pour examiner comment cela peut se faire.
Cas d’utilisation
Il existe de nombreux cas d’utilisation pour l’extraction et le traitement des lignes de reçus et de factures. Voici toutefois quelques-uns des cas d’utilisation que nous rencontrons fréquemment :
- Automatisation des comptes fournisseurs : La reconnaissance des articles simplifie l’extraction des détails, des quantités et des prix des produits, afin d’accélérer les processus de comptabilité fournisseurs et clients.
- Automatisation des rapports de dépenses : Les entreprises peuvent automatiser la gestion des dépenses, en réduisant les saisies manuelles et en garantissant l’exactitude des remboursements grâce à l’OCR pour l’extraction des données par ligne.
- Procurement and Supplier Management: Line item extraction can be used to streamline data extraction to enhance the efficiency of tracking orders, managing suppliers, and ensuring compliance. Invoices or purchase orders can be scanned for swift extraction and processing.
- Numérisation des reçus pour les programmes de fidélisation : L’extraction des lignes de produits peut être utilisée pour identifier les articles fréquemment achetés par les clients inscrits à des programmes de fidélisation. Ces informations peuvent aider les entreprises à adapter les récompenses et les offres de fidélisation aux préférences individuelles des clients, améliorant ainsi la fidélisation et l’engagement de ces derniers.
- Compensation des reçus pour les campagnes de fidélisation : L’extraction de lignes peut être utilisée par les entreprises qui organisent des campagnes de fidélisation dans le cadre desquelles les clients doivent présenter des reçus pour obtenir des récompenses ou des points. La reconnaissance des postes permet une validation automatisée des reçus, ce qui garantit que les clients sont correctement crédités pour leurs achats.
Comment fonctionne l’extraction de lignes avec l’OCR ?
Il existe deux approches principales de l’OCR : l’OCR basée sur des modèles et l’OCR basée sur le Machine Learning, qui se distinguent par leur capacité à extraire et à traiter les lignes de manière efficace. L’OCR par modèle est basée sur des modèles prédéterminés. Un modèle basé sur des modèles nécessite souvent une intervention manuelle, ce qui peut être long et inefficace lorsqu’il s’agit de traiter différents formats de documents.
Il existe deux approches principales de l’OCR : l’OCR basée sur des modèles et l’OCR basée sur le Machine Learning (ou apprentissage automatique), qui se distinguent par leur capacité à extraire et à traiter les lignes de manière efficace. L’OCR par modèle est basée sur des modèles prédéterminés. Un modèle basé sur des modèles nécessite souvent une intervention manuelle, ce qui peut être long et inefficace lorsqu’il s’agit de traiter différents formats de documents.
Un OCR basé sur l’IA, comme l’OCR basé sur l’apprentissage automatique, est en revanche une solution plus efficace pour l’extraction des postes individuels. L’OCR basé sur l’IA exploite les capacités d’apprentissage pour non seulement reconnaître différents types de documents et de champs de données, mais aussi pour s’adapter et apprendre à partir de divers formats de documents, ce qui en fait le choix idéal pour les entreprises qui cherchent à automatiser l’extraction des données par lignes.
Lorsqu’il s’agit de traiter un large éventail de factures et de documents provenant d’un éventail encore plus large de fournisseurs et de prestataires de services, l’efficacité et l’optimisation sont très importantes. Avec l’apprentissage automatique et l’OCR basé sur l’IA comme Klippa DocHorizon, cela peut être mieux réalisé.
Voyons comment Klippa extrait les lignes des reçus et des factures.
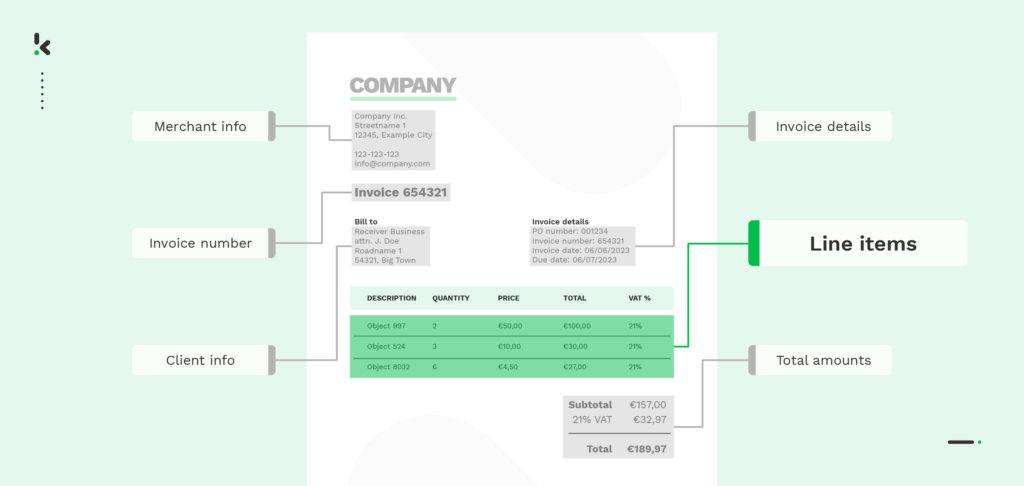
Extraction des lignes des reçus
L’extraction de postes individuels pour les reçus est généralement utilisée par les entreprises et les organisations du secteur de la vente au détail et de l’administration financière. Par exemple, en tant qu’entreprise du secteur de la fidélisation, vous pouvez demander à vos clients de présenter des reçus pour obtenir des récompenses ou des points. L’extraction et le traitement des postes individuels permettent une validation automatisée des reçus, ce qui garantit que les clients qui gagnent des récompenses effectuent des achats valides et exacts.
Voici comment fonctionne le processus. Vous avez d’abord besoin d’une photo ou d’une copie du reçu pour le traitement. Une fois que vous avez la photo d’un reçu, elle peut être téléchargée vers l’API OCR via un téléphone portable, un site Web, un FTP ou même un courrier électronique. Une fois que les reçus ont été reçus par le moteur OCR de Klippa, celui-ci commence à effectuer une reconnaissance des formes et une analyse de la mise en page, et identifie que l’image est un reçu. Ensuite, le logiciel OCR de Klippa identifie et extrait le texte des différentes sections du reçu, y compris les lignes individuelles, les dates et les informations sur le commerçant.
Il sépare ensuite les différentes lignes du ticket de caisse, y compris les noms des produits, les quantités, les prix et les montants totaux. Les données extraites sont converties dans un format lisible par une machine (JSON, CSV, XML, etc.) à l’aide d’algorithmes de machine learning. Elles sont ensuite renvoyées en tant que sortie de l’API pour faciliter le traitement du reçu dans votre base de données ou dans votre système logiciel existant.
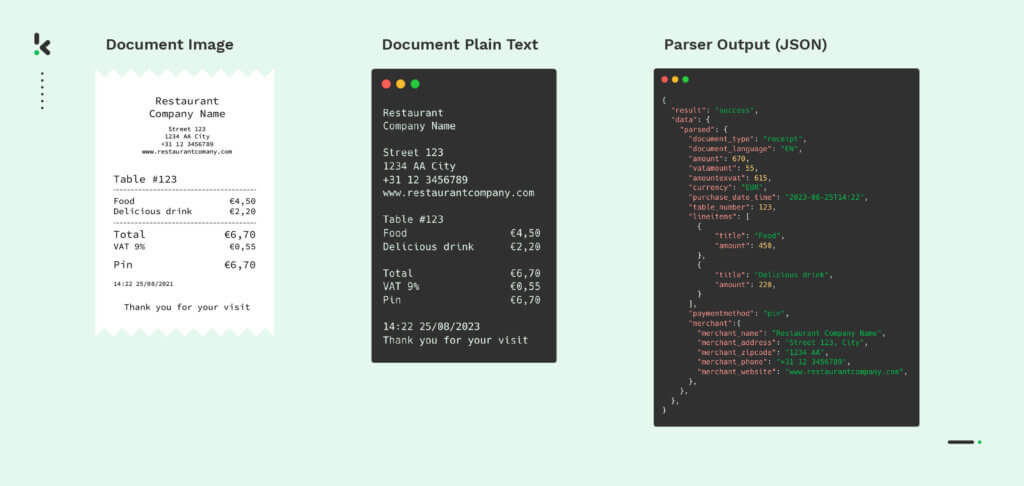
Les données structurées sont alors prêtes pour l’analyse des données, la fidélisation, la gestion des dépenses et la comptabilité. Grâce à ces étapes, le processus d’extraction et de traitement des lignes est plus rapide, plus efficace et moins sujet aux erreurs que l’alternative manuelle.
Extraction des lignes des factures
Ce sont les secteurs financiers et les professionnels qui tirent le plus d’avantages de l’extraction des lignes de facture. Par exemple, l’extraction précise des postes est cruciale pour le suivi des dépenses, la validation des factures et la gestion des comptes fournisseurs et clients. En automatisant cette opération, vous pouvez rendre le processus plus efficace, en réduisant le recours à l’intervention humaine et en protégeant votre entreprise contre la fraude.
La bonne nouvelle, c’est que le processus de numérisation et d’extraction est assez similaire au processus de numérisation des reçus. Une fois que vous avez numérisé l’image ou le document, celui-ci est scanné et identifié comme une facture. Une fois que l’API OCR a scanné le document, les informations pertinentes, notamment les noms des entreprises, les montants, les numéros de téléphone et les valeurs de TVA, sont mises en évidence et extraites.
Ces informations sont extraites et converties dans un format lisible par une machine (JSON, CSV, XML, etc.), prêt à être utilisé. À ce stade, vous pouvez facilement traiter les factures pour vérifier s’il n’y a pas de fraude documentaire, par exemple en procédant à une correspondance bidirectionnelle (Two-way matching). Klippa DocHorizon, par exemple, est doté d’une technologie OCR qui lui permet d’effectuer ces tâches et bien d’autres encore.
Ces technologies permettent non seulement de gagner du temps, mais aussi d’améliorer considérablement la précision, ce qui les rend indispensables pour les entreprises qui gèrent diverses factures de fournisseurs.
Les avantages du traitement automatisé des lignes de produits
Après avoir présenté le processus d’extraction des lignes et son fonctionnement, passons aux avantages de l’automatisation du traitement des lignes.
- Précision : Réduire les erreurs de saisie manuelle des données grâce à l’extraction et à la reconnaissance automatisées, ce qui permet d’obtenir des données plus précises et plus fiables.
- Efficacité temporelle : Gagnez du temps et des ressources en automatisant l’extraction des lignes des documents, ce qui permet aux employés de se concentrer sur des tâches à plus forte valeur ajoutée.
- Réduction des coûts : Diminuez les coûts opérationnels associés à la saisie manuelle des données et améliorez l’efficacité globale.
- Gain de temps : Gagnez du temps en utilisant le traitement automatisé des documents, alimenté par la technologie OCR de Klippa, et éliminez la saisie manuelle et le traitement des documents.
- Évolutivité : Augmentez ou réduisez facilement vos capacités en fonction des besoins de l’entreprise sans avoir besoin de personnel supplémentaire.
- Amélioration de l’expérience client : Fournissez des réponses plus rapides et plus précises aux questions et aux demandes des clients.
Extraire de manière fluide des lignes de produits à l’aide de Klippa DocHorizon
Que vous cherchiez à automatiser la gestion des dépenses, le traitement des factures, les processus de comptabilité fournisseurs ou la validation des reçus pour les campagnes de fidélisation, Klippa DocHorizon vous accompagne. DocHorizon est une solution de traitement intelligent des documents (IDP) qui exploite la puissance de l’OCR et de diverses technologies d’IA pour traiter un large éventail de documents.
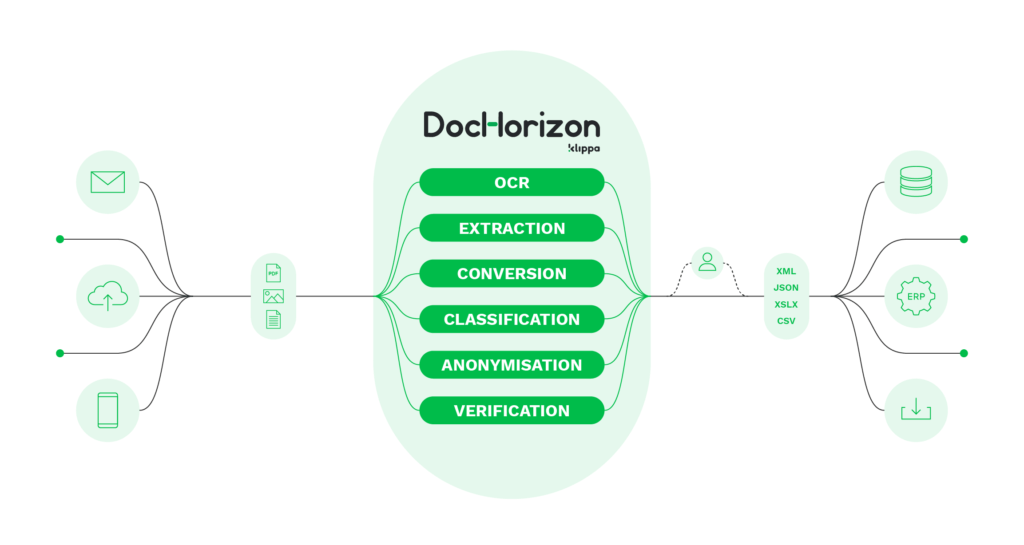
Voici les avantages de l’utilisation de DocHorizon :
- Traitement multilingue : Klippa DocHorizon est capable de traiter des documents dans toutes les langues latines. Cela garantit la flexibilité et l’accessibilité, ce qui en fait un choix idéal pour les entreprises ayant des besoins linguistiques divers.
- Précision et efficacité : La technologie avancée d’OCR de DocHorizon garantit la précision de l’extraction des lignes et du traitement des documents. Klippa minimise les erreurs, fait gagner du temps et améliore l’efficacité globale.
- Automatisation du processus de traitement des documents : Avec la plateforme DocHorizon, il est facile de mettre en place des flux de travail et d’automatiser les processus métier liés aux documents.
- Intégration simplifiée : Intégrez DocHorizon à vos systèmes, bases de données et solutions ERP existants afin d’améliorer votre flux de travail et de maximiser les avantages de l’automatisation.
- Détection des fraudes : Détectez la fraude documentaire grâce à l’analyse EXIF et à l’analyse des mouvements de copie à l’aide d’algorithmes d’IA intelligents.
Curieux de découvrir comment la solution Klippa peut vous aider à améliorer le traitement des reçus et des factures grâce à la reconnaissance et à l’extraction des lignes de produits ? Réservez une démonstration gratuite en ligne ci-dessous !