
A digitalização está em ascensão, uma vez que muitas empresas estão à procura de melhores formas de processar e armazenar documentos. Os arquivos tradicionais estão a ser movidos para a nuvem, e mais documentos são processados em fluxos de trabalho digitais.
Embora a digitalização tenha benefícios fantásticos, existem alguns desafios a considerar. O mais importante é cumprir o rigoroso Regulamento Geral de Proteção de Dados (GDPR), imposto em maio de 2018.
Ainda que estes regulamentos melhorem a proteção de dados e clarifiquem as responsabilidades das organizações, não impedem totalmente as violações de dados.
De facto, os custos resultantes das violações de dados aumentaram de 3,86 milhões de dólares para 4,24 milhões de dólares, o que constitui o custo total médio mais elevado registado em 17 anos!
Como os cibercriminosos estão a tornar-se mais sofisticados, as empresas têm de encontrar soluções para proteger melhor os dados armazenados. Uma excelente solução para minimizar os riscos de violação de dados e assegurar a conformidade com a GDPR é a anonimização de dados.
Este blogue irá cobrir o que é a anonimização de dados, como funciona, e como a Klippa pode automatizar a anonimização de dados para a sua empresa.
O que é a anonimização de dados?
Anonimização de dados, também conhecida como mascaramento de dados, ocultação de dados, ou ofuscação de dados, é uma técnica de segurança para anonimizar dados sensíveis. Tais dados são, por exemplo, números da segurança social ou números de cartões de pagamento.
A anonimização de dados é aplicada para evitar comprometer os dados e reduzir os riscos de segurança, cumprindo, ao mesmo tempo, os regulamentos de privacidade de dados.
Por exemplo, muitas organizações precisam de efetuar verificações Conheça Seu Cliente (KYC) dentro dos processos de onboarding de clientes. Ao efetuar estas verificações para validar a identidade dos clientes, as entidades precisam de processar documentos de identidade.
Contudo, algumas informações, como os números da segurança social, não podem ser armazenadas sob o GDPR. Embora haja exceções, a maioria das organizações precisa de anonimizar ou ofuscar os dados para assegurar o cumprimento.
Atualmente, a anonimização de dados está a ganhar mais atração, e estima-se que a indústria cresça de 483,90 milhões de dólares para 1044,93 milhões de dólares em 2026.
Tipos de dados sensíveis
O mascaramento de dados pode ser utilizado para proteger muitos tipos de dados. Os tipos mais comuns incluem:
- Informação Pessoal Identificável (PII)
- Informação de Saúde Protegida (PHI)
- Informação sobre Cartões de Pagamento (PCI-DSS)
- Lei de Portabilidade e Responsabilidade de Seguros de Saúde (HIPAA)
É essencial saber como funciona a anonimização de dados e identificar que tipos e técnicas são adequados para os seus fins empresariais. Só então será mais fácil de utilizar a anonimização de dados para salvaguardar dados sensíveis em termos de privacidade.
Vejamos como funciona a anonimização de dados.
Como funciona a anonimização de dados?
O ponto de partida é identificar todos os dados sensíveis que a sua organização detém ou processa. É essencial ter em mente que os dados podem vir de muitas formas: e-mails, faxes, folhas de excel, informações de bases de dados, e documentos digitalizados, tais como passaportes, para citar alguns.
Uma vez terminada a identificação de dados, devem ser aplicados algoritmos e técnicas de anonimização de dados. As organizações podem remover, colocar uma tira preta, substituir ou encriptar dados sensíveis, dependendo do seu caso de utilização e dos requisitos legais.
Tomemos como exemplo uma folha de excel com dados de clientes, incluindo informações sensíveis, como números de contas bancárias. Ao armazenar este tipo de informação, a anonimização de dados pode ajudar a aumentar a segurança dos seus dados.
Por exemplo, em vez de revelar dados sensíveis, os números das contas bancárias podem ser substituídos por um “x”, e apenas são mostrados os últimos quatro dígitos.
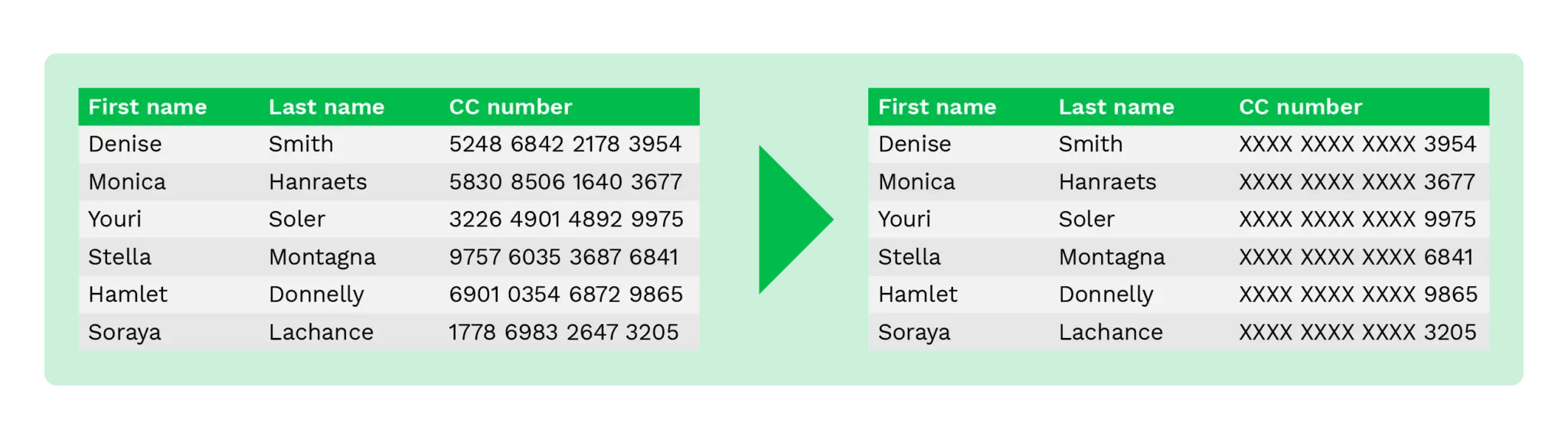
Mesmo que apenas se mostre os últimos quatro dígitos, o seu pessoal de back-office ainda é capaz de verificar a propriedade da conta bancária. Desta forma, os fraudadores não podem utilizar o número da conta bancária, mesmo que obtenham a informação.
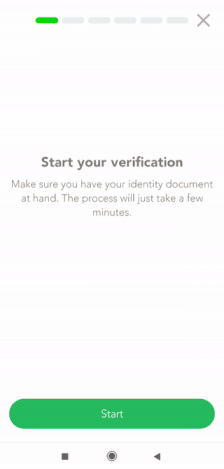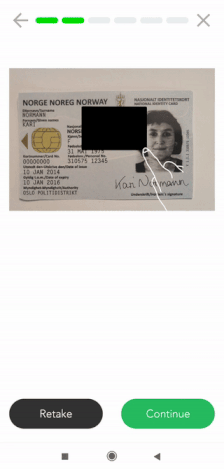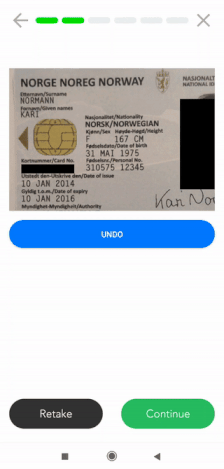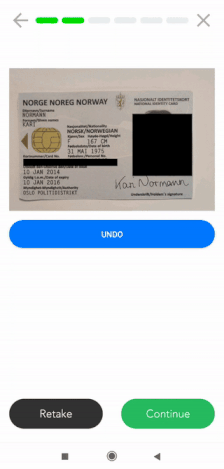
Outro exemplo pode ser o mascaramento de informações na digitalização de um documento de identidade, a partir de um processo KYC. Abaixo pode ver um antes e um depois de um passaporte mascarado para assegurar a conformidade com a GDPR.

Uma abordagem semelhante de anonimização de dados pode ser aplicada a números de seguros, números de cartões de pagamento, ou números da segurança social, para enumerar alguns.
Agora que já explicámos como funciona a anonimização de dados, vejamos dois tipos diferentes.
Tipos de anonimização de dados
Existem vários tipos de anonimização de dados e a utilização depende, principalmente, dos recursos, dos casos de utilização e dos fornecedores. Os dois tipos mais comuns de anonimização de dados são a anonimização estática e a anonimização dinâmica de dados.
Iremos elaborar as suas diferenças nos parágrafos seguintes.
Anonimização estática de dados
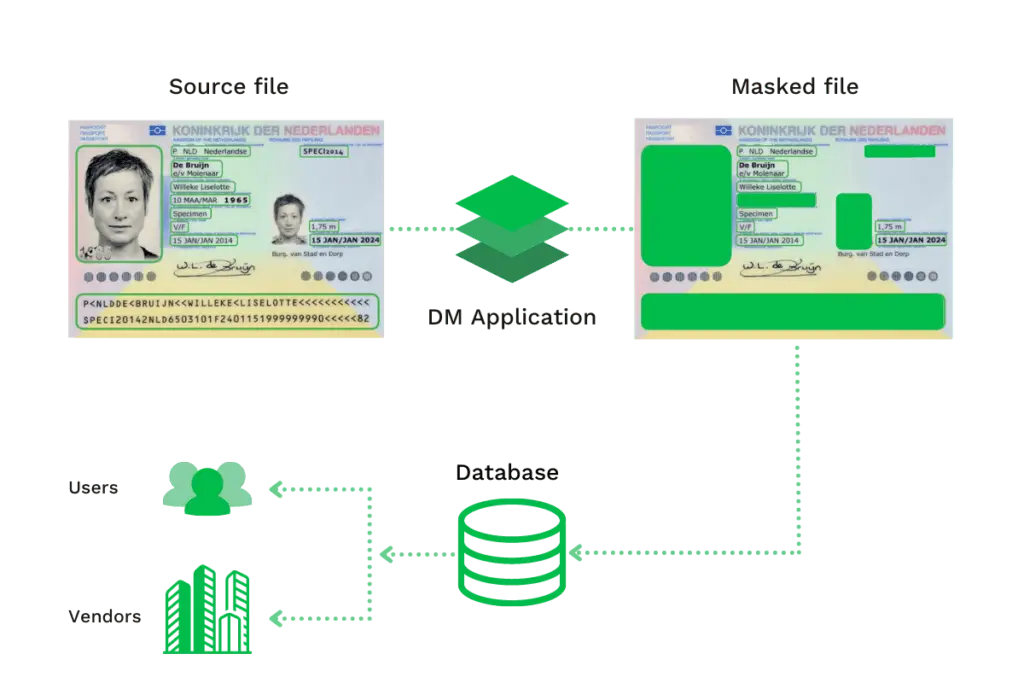
A Anonimização Estática de Dados (SDM, nas siglas em inglês) é frequentemente necessária em testes de software para substituir dados sensíveis, através da alteração de dados que são armazenados num computador portátil, disco rígido, ou em alguma base de dados. Com a anonimização estática de dados, as organizações podem cumprir os regulamentos de dados e privacidade, tais como o GDPR, PCI, PHI, PII, ITAR, e HIPAA.
Esta estrutura de anonimização de dados começa com a cópia original, da qual os dados sensíveis são mascarados antes de serem enviados para processamento posterior (numa base de dados, software, etc.).
Com esta abordagem, a informação sensível é permanentemente substituída, para assegurar o cumprimento dos regulamentos sobre privacidade de dados e proteção contra violações de dados.
Anonimização dinâmica de dados
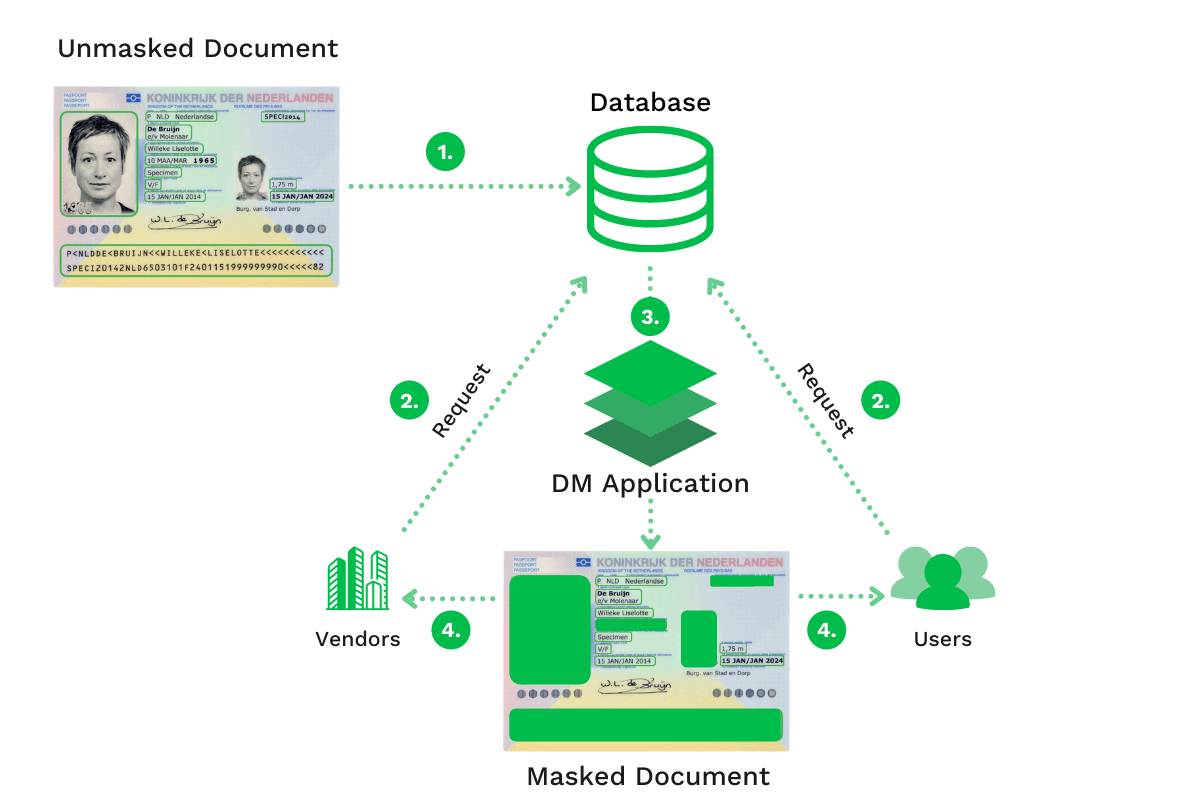
A estrutura da Anonimização Dinâmica de Dados (DDM, nas siglas em inglês) difere da estrutura estática. É utilizada para mascarar dados sensíveis em trânsito (ou seja, utilizados ativamente), deixando a cópia original inalterada. Com esta abordagem, os dados não mascarados são visíveis na base de dados real.
A DDM é utilizada, principalmente, para processar inquéritos de clientes e tratar de registos médicos dentro de aplicações de segurança baseadas em funções. Esconder dados sensíveis de utilizadores específicos é necessário para algumas indústrias.
Com a DDM, as organizações podem utilizar solicitações (queries) modificadas (ou seja, pedidos de dados) que chegam à base de dados original para mascarar dinamicamente os dados e transmiti-los à entidade que os solicita.
Este tipo de anonimização de dados é frequentemente utilizado quando as organizações enviam dados a um fornecedor terceiro ou a stakeholders internos, que não estão autorizados a ver os dados sensíveis. Tais dados podem ser números de Segurança Social (SSN) ou números de cartões de pagamento.
Agora que abordámos os tipos mais comuns de anonimização de dados, vejamos as principais técnicas de anonimização de dados.
Técnicas de anonimização de dados
A anonimização de dados implica uma variedade de técnicas, que são explicadas abaixo.
Substituição
A substituição, também conhecida como pseudonimização, é uma técnica utilizada para substituir os dados originais por dados aleatórios de ficheiros de pesquisa fornecidos ou personalizados. É útil quando as organizações necessitam de preservar o aspeto autêntico dos dados enquanto disfarçam os dados sensíveis.
Esta técnica pode proteger eficazmente os dados contra violações e ajudar a controlar o acesso interno.

Embaralhamento
O embaralhamento (shuffling, em inglês) é uma técnica semelhante à substituição. É também utilizada para substituir dados originais por outros dados que pareçam autênticos. A diferença é que as entidades na mesma coluna são baralhadas aleatoriamente.
Por exemplo, as organizações podem utilizar esta técnica para baralhar aleatoriamente colunas de nomes de empregados de vários registos de empregados. Esta técnica pode ser suscetível a engenharia reversa se alguém conseguir acesso ao algoritmo de embaralhamento.
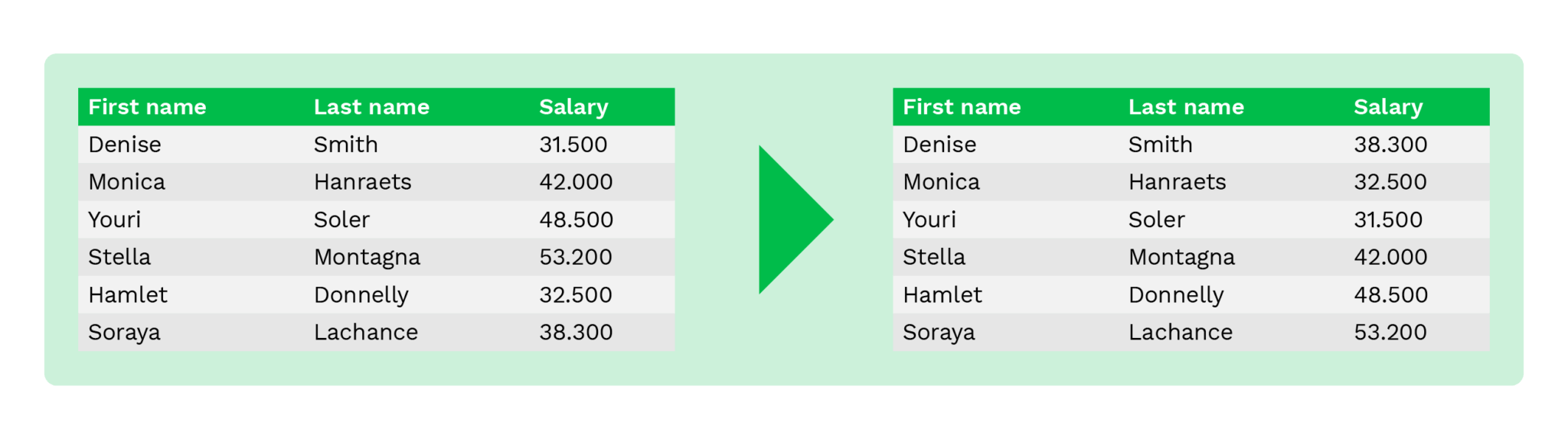
Averaging
A técnica de averaging (cálculo da média) é um método para substituir os valores originais por um valor médio das colunas da tabela. Por exemplo, em vez de mostrar salários ou saldos de contas de indivíduos, o iniciador mostra apenas o valor médio dos salários ou saldos de contas.
Este método ajuda a manter o valor agregado e é normalmente utilizado para fins de análise estatística ou de recolha de dados de instituições financeiras.
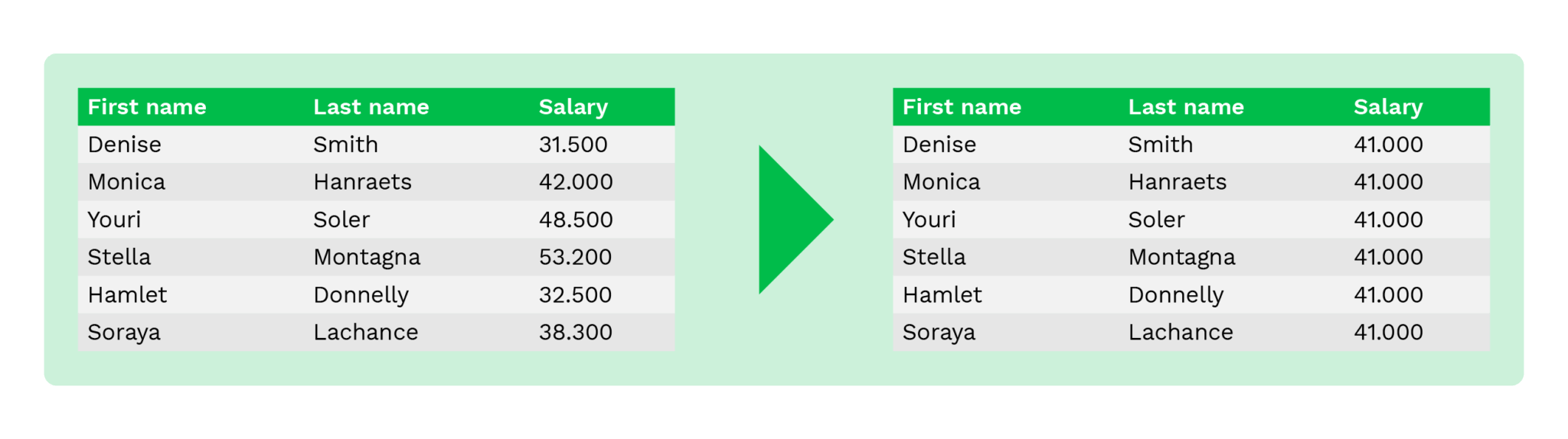
Nulling out
A nulling out (ou eliminação) é uma técnica para substituir dados sensíveis por um valor nulo, evitando que utilizadores não autorizados vejam os dados originais. Significa simplesmente remover a informação ou substituí-la por um valor vazio nos documentos.

Em alguns casos, a informação em certos documentos é completamente omitida, como por exemplo a data de nascimento em currículos. Muitas vezes, isto é feito para eliminar os riscos de práticas de contratação não éticas.

Remoção de dados (blacklining)
A remoção de dados (data redaction, em inglês), também conhecida como “blacklining” (que corresponde à colocação de uma tira preta por cima dos dados a esconder), é um método semelhante ao nulling out, uma vez que apenas parte dos dados originais é mascarada.
Por exemplo, apenas os últimos quatros dígitos do número do cartão de pagamento são mostrados a clientes em compras online, para evitar fraudes.


O mesmo método pode ser aplicado a qualquer documento que contenha informações sensíveis. Abaixo pode ver o exemplo com um passaporte, no qual vários campos são mascarados.
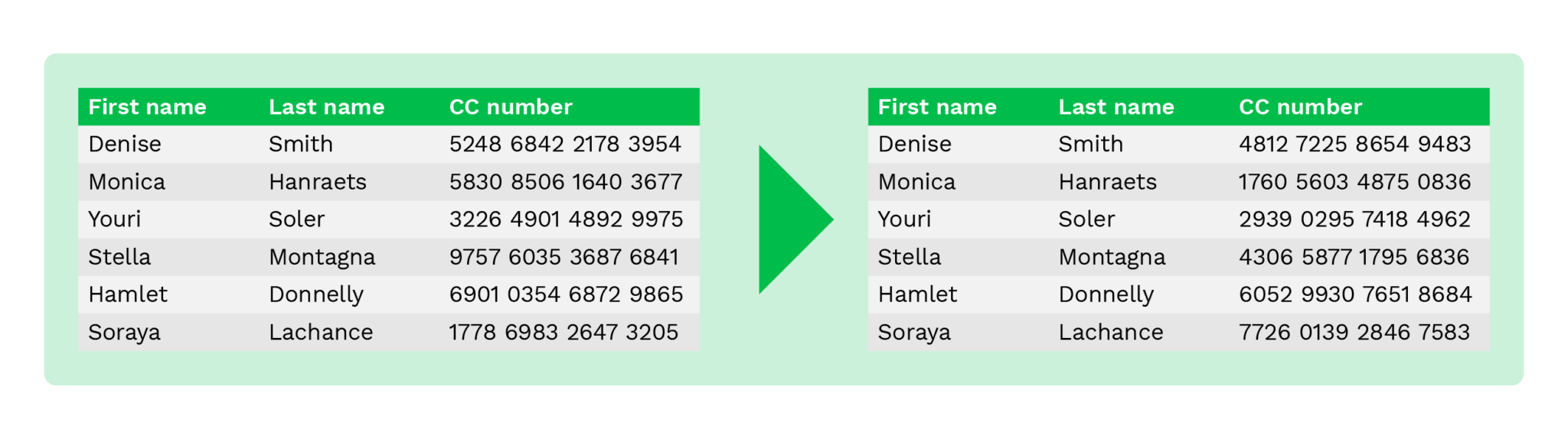
Reorganização de dados
A técnica de reorganização de dados (data scrambling, em inglês) é utilizada para alterar dados através de uma reorganização aleatória da ordem dos caracteres ou de números com um algoritmo específico.
Os dados originais já não podem ser obtidos após a conclusão do processo, uma vez que os dados foram reorganizados.

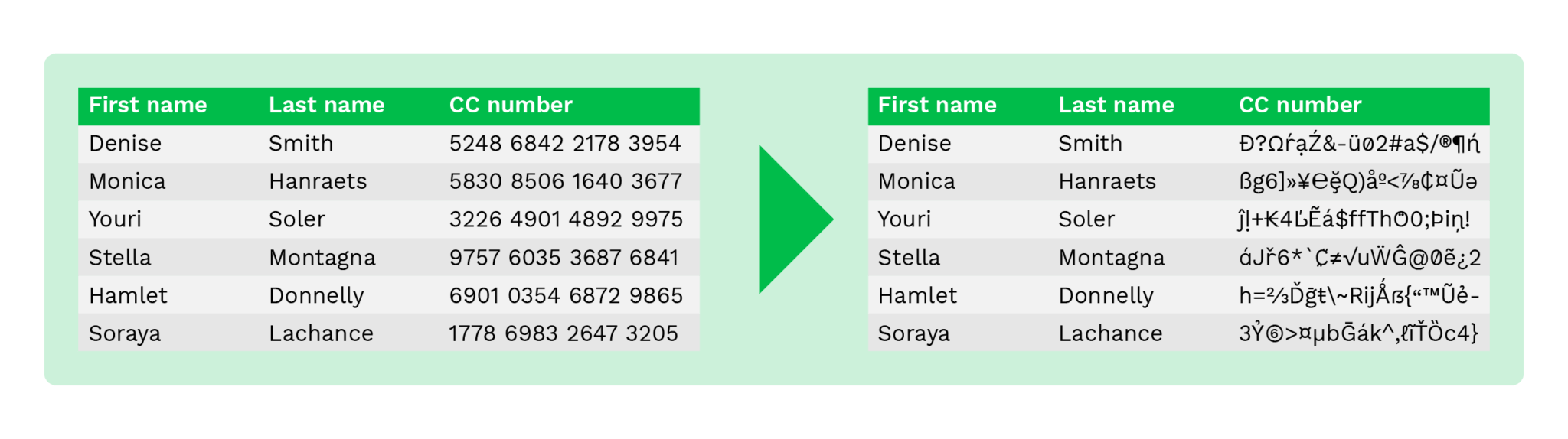
Encriptação de dados
A encriptação de dados é uma técnica que permite o acesso aos dados apenas com a chave de desencriptação.
É o algoritmo de anonimização de dados mais complexo e o mais seguro. Para além da complexidade, requer uma gestão adequada da chave de encriptação para garantir a segurança.

Porque a anonimização de dados é importante?
Desde que o GDPR foi imposto, a proteção de dados tornou-se a principal prioridade para muitas empresas. Como resultado, as organizações consideraram essencial implementar a anonimização de dados como uma das ferramentas para proteção de dados sensíveis.
Então, porque é necessário anonimizar os dados? Em princípio, a anonimização de dados oferece às organizações um caminho seguro para criar versões alternativas de dados utilizáveis e seguros.
Com a anonimização de dados, as organizações podem assegurar os seguintes benefícios.
Anonimização de dados para conformidade com o GDPR
A anonimização (ou mascaramento) de dados ajuda as organizações a cumprir leis e regulamentos sobre privacidade de dados. Com várias técnicas de anonimização de dados disponíveis, várias organizações podem eliminar a exposição de dados sensíveis.
No entanto, nem todas as organizações utilizam a anonimização de dados para cumprir com o GDPR.
Por exemplo, em 2020, o grande retalhista de moda, H&M, foi multado em 35 milhões de euros devido a violações do GDPR. O incidente envolveu o acesso da direção a dados sensíveis, tais como crenças religiosas e questões familiares, através de gravações de reuniões. Estas gravações foram utilizadas como base para avaliar o desempenho de funcionários.
Este incidente poderia ter sido evitado através da remoção de todos os dados sensíveis das gravações documentadas destas reuniões.
Proteção contra violações de dados
Um dos principais benefícios da anonimização de dados é tornar os dados inúteis para ciberataques, preservando simultaneamente a usabilidade para a organização. Mesmo que os dados sejam violados devido a ataques cibernéticos, muitas técnicas de anonimização de dados podem impedir os intrusos de obterem informações sensíveis.
Em 2018, o Panera Bread foi reportado por ter dado origem a uma fuga de pelo menos 37 milhões de registos de clientes, devido à falta de controlo de acesso e de medidas de segurança.
Mais uma vez, este cenário poderia ter sido evitado com várias técnicas de anonimização de dados.
Redução dos riscos de segurança de dados
Muitas empresas trabalham em conjunto com terceiros e fornecedores dentro do seu perímetro, aos quais estão a ser entregues alguns dados. Além disso, os trabalhadores e outros intervenientes internos podem também ter acesso aos dados.
Para simplificar, existe sempre uma ameaça de perda de dados. A anonimização de dados pode fornecer os meios para proteger os dados contra pessoas ou entidades que não estão autorizadas a vê-los.
Apenas dados falsos podem ser vistos, a menos que tenha sido concedida autorização para desmascarar os dados. Assim, a anonimização de dados pode reduzir os riscos internos de segurança de dados e fugas de dados.
Em geral, a ocultação de dados proporciona benefícios impressionantes, que podem ajudar as empresas a obter uma vantagem competitiva. Mas quais são os casos de utilização mais comuns? Vejamos alguns deles.
Casos de utilização da anonimização de dados
Existem muitos casos de utilização para anonimização de dados, incluindo os seguintes:
- “Blacklining” de números de cartões de pagamento
- Anonimização de números da segurança social
- Remoção de dados em currículos
- Mascaramento de dados para arquivo digital
- Remoção ou encriptação de informações pessoais de saúde
- Remoção ou encriptação de dados em documentos governamentais
- Remoção de dados de documentos jurídicos e processos judiciais públicos
- Anonimização de gravações de reuniões
- Controlo de acesso interno
- Encriptação de documentos de propriedade intelectual
- Partilha de dados com fornecedores terceiros
Abaixo, investigamos os quatro primeiros com mais detalhe.
“Blacklining” de números de cartões de pagamento
Em algumas circunstâncias, um membro da sua organização poderá necessitar de acesso a informações sobre um cartão de crédito ou outro cartão de pagamento. Por conseguinte, a utilização da anonimização de dados, para colocar uma tira preta nos últimos quatros dígitos do número do cartão, pode impedir a exposição a componentes sensíveis, tais como números de cartões de pagamento.
É muito comum para bancos e outras instituições financeiras tratarem de informações de pagamento de clientes. Ao tapar o número do cartão de pagamento com uma tira preta, as organizações podem, assim, assegurar a conformidade com o PCI-DSS.

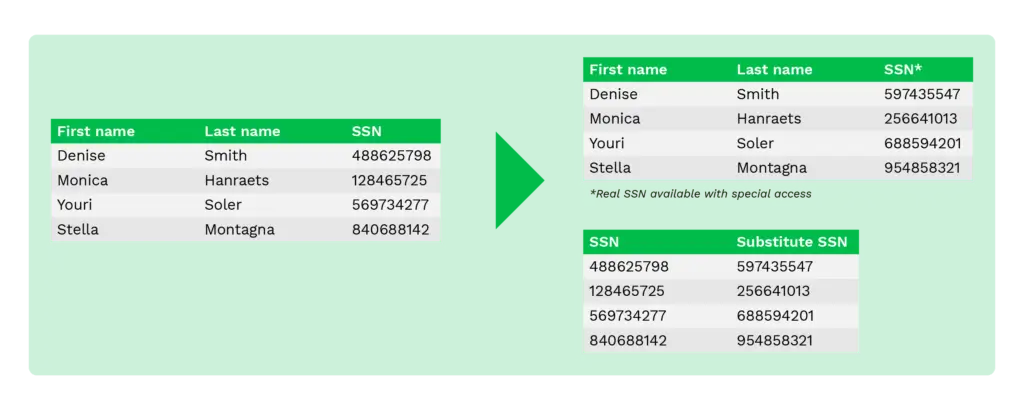
Anonimização de números da segurança social
Informação como a do SSN (número da segurança social) em documentos de identidade, tais como passaportes e cartões de identificação, é altamente sensível. Muitas vezes, organizações fora das instituições governamentais não estão autorizadas a armazenar o SSN na sua base de dados.
Nos Países Baixos, o “burgerservicenummer” (BSN) é o equivalente ao SSN. O BSN é um número único e pessoal para identificar cada cidadão registado. Por exemplo, o BSN é utilizado por instituições governamentais para encontrar dados de cada cidadão, muitas vezes para fins fiscais.
Os SSN e BSN são estritamente proibidos ao abrigo da GDPR, uma vez que pertencem a “categorias especiais de dados pessoais”. Naturalmente, existem casos em que o armazenamento de tais dados é permitido. Mas apenas com uma exceção legal especial ou consentimento da pessoa.
Portanto, é comum a anonimização de números da segurança social ou do BSN, utilizando várias técnicas de mascaramento de dados.

Remoção de dados em currículos
Apesar de toda a formação para reduzir os preconceitos no processo de contratação, uma grande quantidade de recrutadores é culpada de basear as suas decisões em diferentes preconceitos. Infelizmente, ainda é comum que, se dois candidatos tiverem conjuntos de competências e experiência semelhantes, o mais atrativo seja contratado.
Embora seja ilegal discriminar de qualquer forma no processo de recrutamento, muitas empresas ainda o fazem. De facto, 20% das empresas nos EUA são responsáveis por metade dos casos de discriminação.
As organizações começaram a remover dados em currículos para eliminar preconceitos e discriminação na fase inicial do processo de recrutamento. De acordo com o relatório da HRO Today, os campos mais comuns que sejam removidos de currículos incluem:
- Morada de casa
- Nome
- Fotografia (atratividade, género, raça)
Com a anonimização de dados, os recrutadores apenas avaliam os candidatos com base nas suas competências e experiência. É importante notar que os recrutadores são apenas humanos, afinal de contas.

Mascaramento de dados para arquivo digital
Armazenar dados em papel já não é uma opção para muitas organizações. Com o avanço da tecnologia, as razões para empresas avançarem para a digitalização incluem:
- Uma grande acumulação de dados não organizados
- Acesso do controlo interno
- Poupança de tempo e custos
- Processos amigos do ambiente
- Cumprimento com o GDPR
- Fácil acessibilidade a dados
Embora o arquivamento de dados possa ser altamente benéfico, o seu desafio consiste em cumprir as obrigações legais relativas às leis de privacidade de dados. A este respeito, a anonimização de dados é uma solução segura e sólida para assegurar o cumprimento da GDPR.
Antes de arquivar, as empresas podem simplesmente utilizar a anonimização de dados para retocar as partes sensíveis, tais como nomes, números de pacientes, e números da segurança social, de documentos ou substituí-los por dados estruturalmente idênticos (mesma quantidade de números ou caracteres).
As organizações adotaram este método em indústrias como a legal e a da saúde, para citar algumas.
Agora que já cobrimos alguns dos casos de utilização, vejamos a transformação da remoção de dados em documentos.
Transformação da remoção de dados em documentos
Desde que nos lembramos, a redação manual de documentos tem sido largamente utilizada em várias indústrias. É uma tarefa aborrecida de realizar e envolve muitas questões subjacentes. Uma das principais questões é a escalabilidade.
A maioria dos trabalhadores luta para manter a precisão, eficiência e consistência ao longo do tempo. Isto resulta em tempos de rotação lentos, clientes insatisfeitos, e custos elevados.
Tomemos como exemplo a indústria jurídica. Um fluxo de trabalho típico envolve equipas de advogados e paralegais que passam por uma grande pilha de documentos durante centenas de horas.
Em vez de utilizarem os seus conhecimentos e experiência para realizar tarefas significativas, são encarregados de acrescentar, modificar e remover dados de documentos. Para não mencionar os custos de contratação deste tipo de pessoal.
Adicionar mais pessoal à medida que o volume de documentos aumenta rapidamente faz aumentar os custos. Portanto, sejamos francos. Remover dados de documentos manualmente não é uma opção escalável (pelo menos se quiser ser rentável).
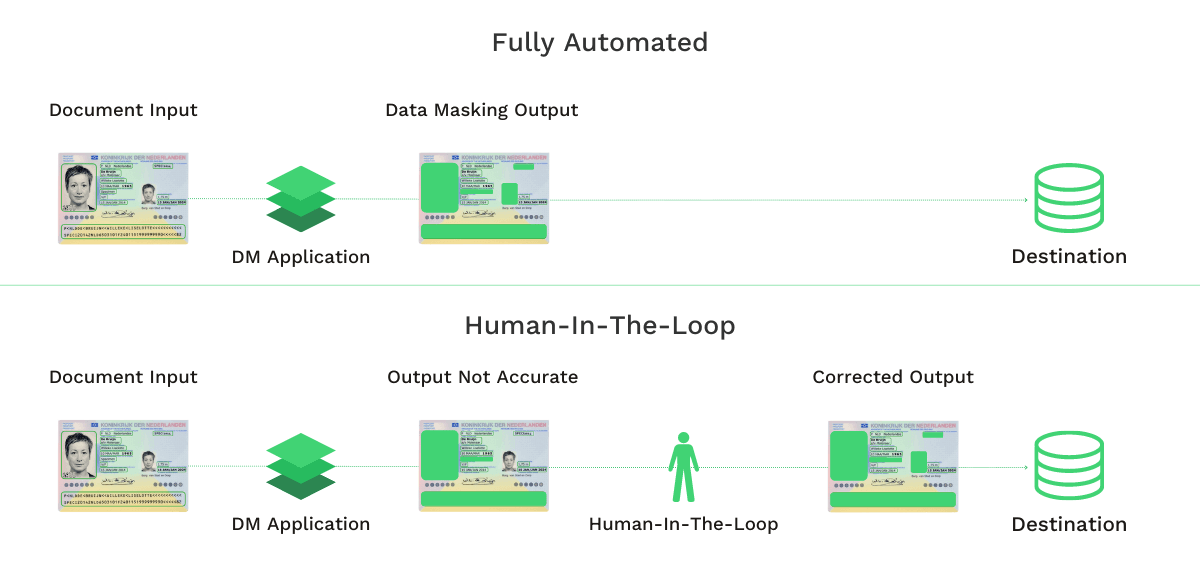
Felizmente, é possível automatizar a remoção de dados de documentos com a tecnologia atual. Existem duas formas que as organizações podem capitalizar: a anonimização de dados totalmente automatizada e a anonimização de dados com assistência humana.
Anonimização de dados totalmente automatizada
Numa solução de anonimização de dados totalmente automatizada, não é necessária intervenção humana. Com tecnologias de Reconhecimento Ótico de Caracteres (OCR), alimentado por IA, é possível reconhecer, localizar e remover automaticamente o campo de informação de documentos que são necessários.
Tudo o que precisa de fazer é alimentar o motor OCR com documentos que precisam de ser mascarados, e ele faz o resto. Esta opção liberta os seus recursos humanos, que pode alocar para tarefas mais complicadas. Desta forma, pode maximizar a eficiência da sua organização.
Anonimização de dados com assistência humana
A outra solução é utilizar a automatização assistida por humanos, por outras palavras, “human-in-the-loop” (HITL). Esta solução utiliza a IA para automatização e permite que o pessoal humano faça verificações finais para analisar a conclusão da anonimização de dados.
A vantagem da automatização “human-in-the-loop” é que permite uma maior precisão na remoção de dados de documentos. Isto não é uma surpresa, uma vez que a solução HITL combina o melhor da inteligência artificial com o melhor da inteligência humana.
Por vezes, pode haver problemas com a tecnologia (qualidade de imagem, qualidade de documentos, etc.), o que a restringe de realizar tarefas de anonimização de dados. Portanto, a revisão da entrada ou saída de dados pode ajudar a reduzir os erros.
Criar qualquer uma destas soluções a partir do zero é difícil, dispendioso e demorado. É por isso que nós na Klippa decidimos combinar a nossa tecnologia OCR com funcionalidades de anonimização de dados, para ajudar várias organizações. Podemos ajudar os nossos clientes a automatizar a anonimização de dados à escala.
Então porque é que a sua organização deve automatizar a anonimização de dados? Aprofundaremos os benefícios que lhe estão associados.
Benefícios de automatizar a anonimização de dados
Embora as organizações possam salvaguardar os dados de fugas e assegurar a conformidade com o GDPR com a anonimização de dados, a automatização acrescenta muitos mais benefícios. Estes benefício incluem:
- Tempos de resposta mais rápidos – A automatização da remoção de dados permite à sua força de trabalho concentrar-se em tarefas mais importantes. Seria necessário menos pessoas para completar estas tarefas tediosas e acelerar o tempo de resposta.
- Precisão – Com uma solução automatizada de anonimização de dados que utiliza IA, as empresas podem obter maior precisão simplesmente porque as máquinas e os computadores não se cansam.
- Velocidade – Com uma solução automatizada, o processo de remoção de dados pode ser até 90 vezes mais rápido. Pode ver um cálculo simplificado na secção seguinte.
- Redução de custos – Com maior eficiência e precisão, conseguida através da IA, as organizações podem poupar dinheiro significativamente (horas de trabalho, redução de erros, etc.).
- Escalabilidade – Existe um limite para a quantidade de documentos que um funcionário médio pode anonimizar. A automatização do mascaramento de dados oferece às empresas uma forma de remover dados de documentos à escala, sem aumentar os custos operacionais.
Parece que há muitos benefícios que as organizações podem usufruir provenientes de uma solução automatizada de anonimização de dados. Mas o que isso significa para si em termos do seu negócio?
Para o tornar tangível para si, fornecemos um exemplo de cálculo de um potencial retorno sobre o investimento (ROI) na secção seguinte.
O ROI da solução de anonimização automatizada de dados
Digamos que tem 100,000 documentos de identidade, dos quais precisa de remover os números da segurança social. Vamos também presumir que, em média, um funcionário experiente pode anonimizar, manualmente, dois documentos de identidade a cada minuto. Isto perfaz 120 documentos de identidade em uma hora. Vamos estimar o custo para contratar um funcionário experiente (incluindo seguros, salário por hora, e outros custos) em 25,00 euros por hora.
Para assegurar que a anonimização seja feita corretamente, seria necessário contratar outro funcionário para verificar novamente os documentos anonimizados. Vamos supor que um escriturário idêntico pode verificar a exatidão de cada anonimização ao ritmo de 360 documentos de identidade por hora.
O custo total de anonimizar manualmente 100,000 documentos de identidade ultrapassaria os 27,700 euros. As horas de trabalho que seriam necessárias para completar o projeto são superiores a 1,100.
Comparando com a solução da Klippa, que pode anonimizar 10,000 documentos por hora, seria possível concluir o projeto em 10 horas. Isso representa quase 1,100 horas de trabalho poupadas.
Como estimativa, custaria à sua organização 4,000 euros para completar este projeto com a nossa solução (dependendo do volume e do tipo de documento). Conseguiria completar o projeto mais de 90 vezes mais depressa e com um ROI de 6.9.

Experimente você mesmo a nossa calculadora ROI de anonimização de dados!
Anonimizar os seus dados com a Klippa
A Klippa foi fundada em 2015, com o propósito de ajudar as empresas a digitalizar e automatizar o processamento de documentos à escala, utilizando tecnologias de ponta. Com tecnologias como a Machine Learning, IA, e OCR, somos capazes de ajudar os nossos clientes de várias indústrias em todo o mundo.
A nossa solução de Processamento Inteligente de Documentos (IDP), a Klippa DocHorizon, foi concebida para ajudar as organizações a automatizar de forma inteligente o processamento de documentos, digitalizar, extrair, classificar, verificar e anonimizar os dados de vários documentos.
Com a Klippa DocHorizon, a sua organização pode reduzir os tempos de resposta, os custos, e os erros humanos, salvaguardando ao mesmo tempo os dados sensíveis.
Embora o nosso software OCR baseado em IA inclua características de mascaramento de dados, desenvolvemos uma API de anonimização de dados para permitir integrações com os sistemas existentes de gestão documental, planeamento de recursos empresariais (ERP) ou registos de saúde eletrónicos (EHR) dos nossos clientes.
Para além do API, desenvolvemos um SDK de anonimização de dados para permitir às empresas alavancar a nossa tecnologia dentro do seu sistema.
API de anonimização de dados
Para ajudar os nossos clientes a livrarem-se do trabalho repetitivo nos processos administrativos, desenvolvemos um OCR API de mascaramento de dados. Permite que os nossos clientes possam anonimizar certos campos e imagens de documentos.
O nosso motor de Parsing pode ser treinado para reconhecer campos específicos que precisam de ser ocultados. Processamos inúmeros campos “out-of-the-box”, mas os campos personalizados podem ser acrescentados ou removidos a pedido.
Várias entradas podem ser fornecidas ao motor Parsing, tais como JPG, PNG, e PDF. A saída padrão que os nossos clientes recebem é um ficheiro JSON, que pode ser encaminhado para os destinos desejados, tais como sistemas de Planeamento de Recursos Empresariais (ERP). Contudo, os resultados podem ser personalizados para, por exemplo, CSV, XLSX, ou XML, se necessário. Para além do JSON estruturado, é também possível obter os documentos anonimizados em JPG, PDF, ou tipos de ficheiros semelhantes.
O nosso OCR API de anonimização de dados é atualmente disponibilizado através de uma API RESTful, permitindo aos nossos clientes integrá-la em aplicações baseadas na web. Para ajudar os nossos clientes, fornecemos documentação clara.
Anonimização móvel de dados
Se precisar de uma solução móvel de anonimização de dados, a Klippa pode também apoiá-lo. Oferecemos um scanner móvel SDK que inclui funcionalidades de mascaramento de dados. Os clientes utilizam este scanner SDK para ocultar certas informações em documentos de identidade, recibos, faturas e muitos outros tipos de documentos.
Atualmente, o nosso scanner SDK está disponível tanto para Android como para IOS. Além disso, oferecemos wrappers para linguagens de plataforma cruzada, como ReactNative, Flutter, Cordova, e Nativescript. Geralmente, pode ser integrado em qualquer solução móvel.
Documentos com marca de água
No caso de uma das abordagens de anonimização de dados não seja possível para si, a Klippa oferece também a marcação de água digital de documentos, como alternativa. Desta forma, pode proteger os direitos de autor dos seus documentos, permitir aos seus clientes partilhar dados de forma mais segura e reduzir os riscos de segurança enquanto armazena dados sensíveis.
Basta introduzir um documento na Klippa DocHorizon, e será devolvido o mesmo documento com uma marca de água. Essa marca de água contém algo de acordo com as suas necessidades – por exemplo, o nome da sua empresa + a data de digitalização.

Quer esteja à procura de uma solução ponta a ponta ou de uma integração API / SDK para automatizar o seu processamento de documentos, a Klippa está aqui para o ajudar. Preencha o formulário abaixo para uma demonstração gratuita, ou contacte os nossos especialistas para saber como a Klippa o pode apoiar.