
L’utilisation de l’extraction de données automatisée pour les documents donne un vrai coup de pouce à votre entreprise. Il est assez facile de s’y mettre, mais réaliser les bénéfices qu’elle peut apporter à votre organisation peut prendre un certain temps.
Vous ou vos employés devez traiter manuellement des centaines, des milliers, voire des millions de documents par mois ? Vous aimeriez vous débarrasser de ce processus ? Vous n’êtes pas seul. Heureusement, il existe une solution : l’extraction automatique des données des documents. Cela accélère l’ensemble du processus.
Envie de savoir comment cela fonctionne ? Ou voulez-vous vous familiariser avec une meilleure compréhension globale de l’extraction de données ? Continuez donc à lire.
Dans cet article, vous comprendrez mieux la signification, les techniques, le processus et l’importance de cette solution d’automatisation.
Vous obtiendrez un exemple et une réponse claire à la question : Qu’est-ce que l’extraction de données ?
La signification de l’extraction de données
Alors, que signifie l’extraction de données à partir de documents ? Il s’agit essentiellement d’extraire différentes informations d’une ou plusieurs sources. Ces sources sont généralement peu ou pas organisées et totalement non structurées.
L’extraction des données vous permet de les traiter, de les stocker et de les analyser plus en amont. Ces types de données sont souvent utilisés pour améliorer les opérations de l’entreprise. C’est la base pour faire une analyse critique dans le processus de prise de décision.
Il existe trois formes d’extraction de données : manuelle, automatisée et une intermédiaire appelée Human-in-the-Loop (combinaison des deux premières utilisant l’intervention d’un employé).
Maintenant que la définition de l’extraction de données est claire, poursuivons avec l’importance du processus.
Pourquoi l’extraction de données est-elle importante ?
Imaginez que vous êtes une banque et que vous accordez des prêts hypothécaires à des acheteurs de maison. La loi vous oblige à effectuer des contrôles KYC, à enregistrer les revenus de l’acheteur et probablement plus de vérifications.
Pour ce faire, les clients envoient des documents contenant ces informations. Ces informations doivent atterrir dans votre base de données, ou système de prise de décision.
Malheureusement, les données ne sont pas structurées. Vous avez donc besoin d’une équipe de back-office pour identifier et isoler la présence d’informations sur les documents, comme le salaire figurant sur la fiche de paie. En outre, les informations doivent être saisies dans vos systèmes numériques.
Il s’agit d’une tâche coûteuse, longue, ennuyeuse et fastidieuse, mais ce n’est pas forcément le cas. En fait, de nombreuses entreprises tirent parti de solutions et de techniques d’extraction automatisées, alimentées par l’IA, pour gérer le processus d’extraction des données du début à la fin.
Les principaux avantages de l’utilisation d’une solution d’extraction automatisée sont les suivants :
- Amélioration de la précision
- Augmentation de la productivité des employés
- Réduction des coûts
- Gain de temps
- Évolutivité
- Délai d’exécution plus rapides
Amélioration de la précision
Le remplacement de l’extraction manuelle par l’extraction automatique des données réduit considérablement le risque d’erreurs humaines. Il en résulte donc une amélioration globale de la précision.
Si la saisie de grandes quantités de données est une tâche quotidienne pour la plupart de vos employés, il y a de fortes chances qu’il y ait quelques inexactitudes et erreurs dues à des erreurs humaines. Sans aucune étape de vérification, la saisie de données a un taux d’erreur de 4 %.
En automatisant le processus d’extraction des données des documents, vous obtiendrez des données globalement plus précises. Une plus grande précision ne conduit pas seulement à de meilleures décisions commerciales, mais elle est également très bénéfique pour les employés. Cela nous amène à l’avantage suivant.
Augmentation de la productivité des employés

En supprimant l’extraction manuelle des données et en la remplaçant par un outil automatisé, les employés peuvent consacrer plus de temps aux tâches importantes. Certaines tâches ne peuvent être effectuées que par des employés. Laissez-les s’en charger et utiliser un outil d’extraction de données automatisé pour les tâches automatisables.
Non seulement la satisfaction augmentera parce que les employés sont libérés des tâches fastidieuses, mais ils pourront également se concentrer sur des tâches plus significatives. Cela conduira à nouveau à une amélioration de la satisfaction, qui conduira (à long terme) à une amélioration de la productivité.
Réduction des coûts
En choisissant un outil d’extraction de données, votre entreprise peut réaliser des économies à court et à long terme.
À court terme, votre entreprise peut déjà économiser beaucoup d’argent en réduisant les erreurs de saisie manuelle des données. À long terme, votre entreprise n’a pas besoin de s’inquiéter du dimensionnement et du financement d’une grande équipe pour gérer les besoins en données de votre entreprise. Les systèmes automatisés de saisie et d’extraction de données ont donc le vent en poupe.
Gain de temps
Des études montrent que l’automatisation intelligente permet généralement de réaliser des économies de 40 à 75 %. Le temps, c’est de l’argent, et c’est donc l’un des principaux arguments de vente d’un outil d’extraction de données.
Évolutivité
Lorsqu’une entreprise se développe, la quantité de documents entrants et sortants augmente également. Si l’extraction des données des documents se fait encore manuellement, la quantité de documents s’accumule.
Ce problème peut être évité en passant à un système automatisé. L’entreprise peut ainsi se développer sans avoir à se préoccuper de gros volumes de données qui traînent ou à embaucher une main-d’œuvre importante.
Délai d’exécution plus rapide
Grâce à l’extraction automatisée des données, les délais d’exécution peuvent passer de plusieurs jours ou semaines à quelques secondes. Si un de vos employés doit vérifier manuellement un document, il ne peut le faire qu’une seule fois. En outre, les personnes ne peuvent travailler que 8 heures par jour.
Défis
S’il y a des avantages, il doit aussi y avoir des défis concernant l’extraction de données.
- La sécurité des données sensibles peut être très difficile. Un exemple de données sensibles est celui des données financières. Par conséquent, la sécurité de l’extraction de données doit être assurée. Il est important de ne travailler qu’avec des solutions logicielles qui peuvent prouver que leur sécurité est testée régulièrement, et qu’elles peuvent se conformer à la RGPD et à d’autres législations.
- Un autre défi est la cohérence des données extraites de plusieurs sources.Le défi est encore plus grand si ces sources sont à la fois non structurées et structurées, car vous devez encore vous assurer qu’elles fonctionnent bien ensemble. Les systèmes alimentés par l’IA peuvent être formés pour combiner les données et les rendre aptes à être exploitées après traitement.
Heureusement, la plupart des solutions d’extraction de données sont accompagnées d’une équipe d’assistance technique étendue pour vous aider à surmonter ces difficultés. Poursuivons maintenant avec les types de données qui peuvent être extraites.
Types de données
Les données peuvent être classées en fonction de la structure de la source :
- Les données structurées : La source de données possède déjà une structure logique. Par conséquent, elle est déjà très pratique pour l’extraction. Vous n’avez pas besoin de la travailler ou de la manipuler avant le processus d’extraction des données. Les fichiers CSV et XML en sont des exemples.
- Données non structurées : La plupart des données existent sous une forme non structurée. Les sources de données non structurées peuvent être par exemple des PDF, des textes scannés, des pages web, des e-mails ou des images. Les données non structurées doivent être filtrées pour permettre une extraction judicieuse des données. Il peut s’agir par exemple de supprimer les espaces blancs, les résultats en double et d’autres “bruits” qui doivent être nettoyés du document.

Types de techniques d’extraction de données
Il existe deux techniques différentes d’extraction des données : l’extraction logique et l’extraction physique.
Extraction logique
L’extraction logique est la technique la plus largement utilisée. Elle peut être divisée en deux sous-types :
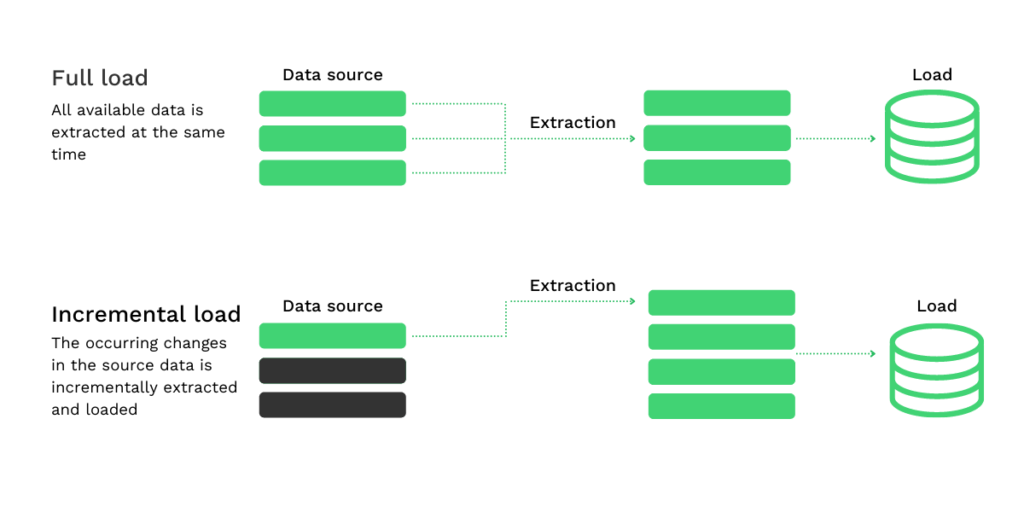
- L’extraction complète : Toutes les données sont entièrement extraites en même temps, sans avoir besoin d’informations (techno)logiques supplémentaires. L’extraction complète est une méthode utilisée lorsque les données doivent être extraites et chargées pour la première fois. Elle reflète les données qui sont disponibles à ce moment-là dans le système source.
- Extraction incrémentale : Depuis la dernière extraction de données réussie (indiquée par un horodatage), les changements survenus dans les données sources sont suivis. Ces modifications sont ensuite extraites et chargées de manière incrémentielle.
Extraction physique
S’il est difficile d’extraire des données de systèmes de stockage de données périmés ou restreints en utilisant l’extraction logique, l’application de techniques d’extraction physique est le seul moyen d’obtenir ces données. L’extraction physique peut être divisée en deux types :
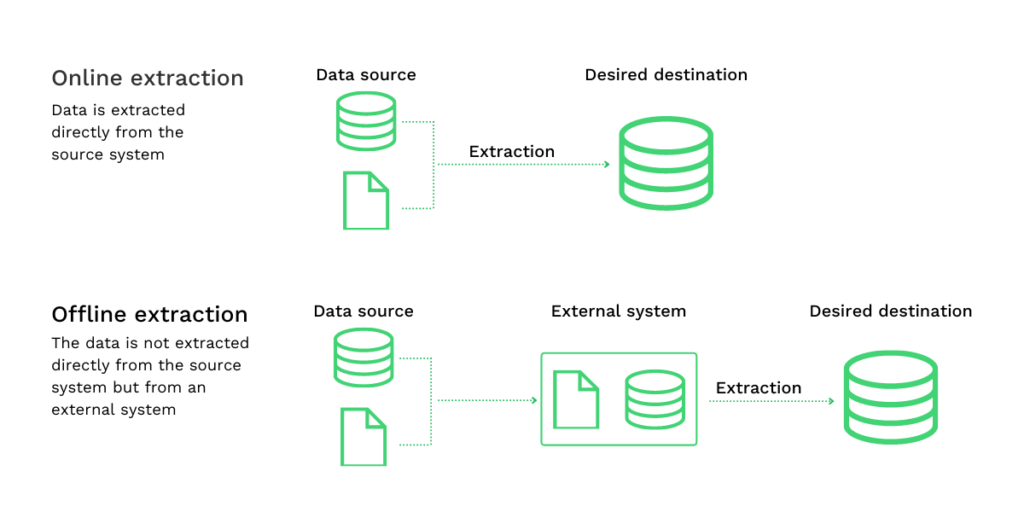
- L’extraction en ligne : Il existe une connexion directe entre le système source et l’archive finale. Avec la méthode d’extraction en ligne, les données extraites sont plus structurées que les données sources.
- L’extraction hors ligne : L’extraction réelle des données a lieu en dehors du système source. Dans les processus d’extraction hors ligne, les données sont soit structurées par elles-mêmes, soit structurées par des routines d’extraction.
Catégories d’outils d’extraction
Les outils d’extraction de données extraient automatiquement les données de la source. Le type de service et l’objectif sont des paramètres très importants. Afin de comprendre quelle catégorie d’outils conviendrait le mieux à votre entreprise, vous devez comprendre la différence entre les trois :
- Les outils de traitement par lots : Peut être intéressant pour les entreprises qui ont besoin de transférer des données d’un endroit à un autre, mais des défis se présentent. Il peut s’agir de données stockées dans des formulaires obsolètes ou de données héritées. Le traitement par lots peut également être utile aux entreprises qui souhaitent transférer des données sur site ou dans un environnement fermé.
- Les outils open source : Sont privilégiés pour les entreprises disposant d’un budget limité. Elles peuvent acquérir des logiciels open source pour reproduire les données fournies, ou extraire des données. Les outils open source sont généralement suffisants pour les entreprises de petite taille.
- Outils basés sur le cloud : la majorité des outils d’extraction disponibles aujourd’hui sont basés sur le cloud. Les outils basés sur le cloud computing excellent dans l’extraction rapide et fiable de données. En utilisant des outils basés sur le cloud, les entreprises n’ont plus à se soucier des questions de conformité et de sécurité en interne. En outre, ils éliminent les retards causés par le traitement par lots.
Il existe aujourd’hui sur le marché de nombreuses solutions basées sur le cloud. L’une d’entre elles est Klippa. Klippa est spécialisée dans l’extraction de données à partir de documents non structurés et peut vous aider à transformer des documents non structurés en données structurées.
Exemple d’extraction de données
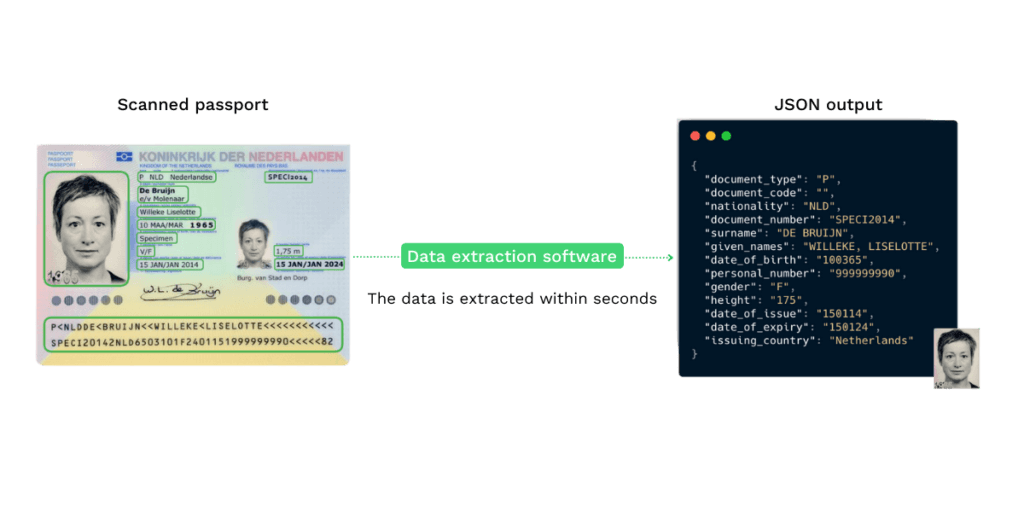
Voyons donc ce qu’une solution d’extraction peut faire pour vous. Nous prenons l’exemple d’un passeport.
Disons que votre client a téléchargé ce passeport à gauche dans le cadre d’un processus KYC et que vous utilisez un logiciel d’extraction de données pour obtenir les informations dont vous avez besoin. Par exemple, le nom complet, le numéro du document et le MRZ.
En 3 secondes, le système est capable de transformer l’image non structurée en données structurées comme le montre l’image de droite ci-dessous.
La solution d’extraction dans le cloud de Klippa
Klippa est une société de traitement intelligent de documents. Les logiciels que nous construisons sont faits pour automatiser les processus d’affaires qui impliquent des documents. Nos solutions permettent d’augmenter la productivité, l’efficacité, de réduire les coûts et les erreurs humaines.
Klippa offre une solution complète d’extraction de données documentaires basée sur le cloud, qui aide les entreprises à traiter automatiquement tout type de document en quelques secondes.
Comment fonctionne le processus d’extraction de documents non structurés ?
Mais comment se fait l’extraction de données ? Le processus d’extraction de données d’un document peut être expliqué brièvement en quelques étapes. Le processus décrit est la façon dont le processus d’extraction fonctionne chez Klippa.
1. Téléchargement du document
Tout d’abord, le document papier doit être transformé en un document numérique. Habituellement, cela se fait en scannant le document avec un téléphone portable. Cela peut également se faire en téléchargeant un fichier dans le système. L’entrée peut être dans plusieurs formats, tels que JPG, PDF, PNG, TXT et plus encore.
2. L’image en TXT
Maintenant que le téléchargement est terminé, l’extraction des données peut commencer. Le seul problème est que l’ordinateur ne peut pas encore lire ce qui se trouve sur le document ou l’image. Il faut donc le transformer en fichier TXT. Pour ce faire, la technologie OCR (reconnaissance optique de caractères) entre en jeu. Cette technologie extrait toutes les données du document, mais elles ne sont pas encore structurées.
3. Analyse syntaxique en JSON
Dans la dernière étape, un analyseur syntaxique est nécessaire pour lire et comprendre le texte du fichier. L’analyseur convertit le fichier TXT en un fichier JSON structuré. Une fois la conversion terminée, les données peuvent facilement être traitées dans la base de données. Outre JSON, d’autres sorties telles que XML, XLSX et CSV sont également possibles. Notre API OCR est très flexible.
4. Vérifier les données extraites avec des sources tierces
En option, nous pouvons vérifier les données extraites avec des sources tierces. Il peut s’agir de votre propre base de données, mais aussi des bases de données des chambres de commerce et des listes de lutte contre le blanchiment d’argent. Cela permet de s’assurer que les données sont de bonne qualité et conformes à la réglementation.
API d’extraction de données
La solution d’extraction de données ci-dessus est utilisée par des entreprises du monde entier, dans des secteurs variés. Les services financiers (par exemple, dans les processus KYC), le commerce de détail (par exemple, les campagnes de fidélisation), la comptabilité, les douanes et les soins de santé en sont des exemples.
Bien sûr, vous pouvez essayer de construire vous-même un pipeline d’extraction complet, mais cela est compliqué et prend du temps. La maintenance est également coûteuse et le retour sur investissement est souvent très mauvais par rapport à l’utilisation d’un service existant.
Par conséquent, la mise en œuvre d’une API tierce pour l’extraction de données sur des documents est un bon choix. Grâce à notre API, la solution peut être intégrée à tout logiciel existant. Ainsi, les données peuvent être extraites directement dans le logiciel.
Prenez contact avec nos spécialistes
Si vous cherchez un moyen d’augmenter la productivité, d’améliorer la précision, de gagner beaucoup de temps, de permettre l’évolutivité et de réduire les coûts, la solution d’extraction de Klippa est le bon choix pour vous.
Vous souhaitez en savoir plus sur le processus d’extraction, la technique et la méthode que nous utilisons ? Prenez contact avec l’un de nos experts, ou planifiez une démonstration gratuite en ligne via le formulaire de démonstration ci-dessous.