Les entreprises stockent plus que jamais des données dans des bases de données et des environnements en ligne. En fait, 60% des données des entreprises dans le monde se trouvent dans le Cloud. Mais ces entreprises possèdent-elles les bons outils pour protéger les données sensibles en matière de confidentialité? Bien qu’il existe de nombreuses réglementations en matière de confidentialité des données auxquelles les entreprises doivent se conformer, comme le GDPR en Europe, elles ne protègent pas toujours les données contre les violations.
Selon Verizon, la plupart des violations concernent des données personnelles identifiables (PII) et des données de cartes de paiement. Chaque fois qu’une entreprise subit une violation de données, il peut s’avérer coûteux de prendre les mesures appropriées pour minimiser les dommages et informer les différentes parties prenantes que les données sont concernées.
En outre, cela peut avoir un impact négatif sur la réputation de l’entreprise, ce qui peut entraîner des pertes financières à long terme. C’est pourquoi les organisations doivent trouver des mesures préventives telles que l’anonymisation des données pour protéger les données sensibles qu’elles stockent et traitent.
Dans ce blog, nous verrons à quoi ressemblent ces mesures préventives, quelles techniques peuvent être utilisées et comment automatiser l’anonymisation des données à l’aide de solutions modernes d’IA. Commençons!
Point Clés :
- Anonymisation des données – Méthode visant à protéger les informations sensibles en modifiant ou supprimant les données personnellement identifiables (PII) afin de garantir la confidentialité et la conformité aux réglementations, telles que le GDPR.
- Techniques d’anonymisation – Masquage des données, pseudonymisation, généralisation, permutation, perturbation des données et données synthétiques. Chaque technique a ses avantages pour rendre les données moins identifiables tout en conservant leur utilité.
- Cas d’utilisation courants – L’anonymisation des données est cruciale pour les secteurs qui traitent des informations sensibles, comme l’intégration à distance des clients (KYC), le traitement d’informations financières, et le développement de produits logiciels.
- Avantages de l’anonymisation – Protection contre l’utilisation abusive des données, conformité aux réglementations sur la confidentialité des données, et possibilité de partager des données anonymisées pour la recherche ou l’amélioration des produits.
Qu’est-ce que l’anonymisation des données ?
L’anonymisation des données est une méthode permettant de protéger les informations confidentielles ou personnelles en supprimant ou en modifiant les données personnellement identifiables qui sont stockées dans un ensemble de données. L’objectif de l’anonymisation des données est de préserver la crédibilité des données stockées ou échangées et de garantir le respect de réglementations strictes en matière de confidentialité des données.
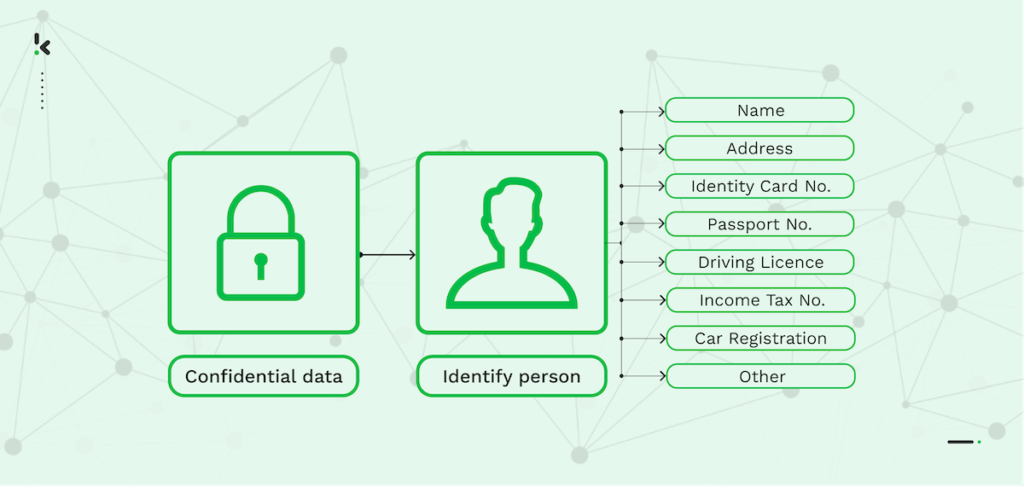
Selon la norme ISO (ISO 29100:2011), le principal critère de l’anonymisation est que les informations personnelles identifiables (PII) soient modifiées de manière irréversible de sorte que la personne ne puisse plus être identifiée directement ou indirectement. Par conséquent, les informations financières, les coordonnées, les rapports médicaux et les données de paiement qui contiennent des PII doivent être bien protégées afin d’adhérer aux réglementations strictes en matière de confidentialité des données.
Maintenant que vous savez ce qu’est l’anonymisation des données, voyons comment anonymiser les données.
Comment anonymiser les données
Pour rendre les données anonymes, il faut d’abord identifier les PII dans l’ensemble de données, puis déterminer la bonne technique d’anonymisation en fonction du risque potentiel d’atteinte à la vie privée. Il existe plusieurs solutions logicielles qui peuvent répondre à votre cas d’utilisation et à vos exigences, par exemple:
- Logiciel de masquage des données
- Logiciel de cryptage des données
- Logiciel d’anonymisation des données
- Logiciel de gouvernance des données
- Logiciel de traitement intelligent des documents
Chacun de ces logiciels utilise un ensemble différent de techniques d’anonymisation des données, que nous examinerons plus en détail dans la section suivante.
Techniques d’anonymisation des données
La liste suivante présente les techniques les plus couramment utilisées pour anonymiser des données sensibles :
- Masquage des données
- Pseudonymisation
- Généralisation
- Échange de données
- Perturbation des données
- Données synthétiques
Masquage des données
Le masquage des données consiste à rendre les données accessibles avec des valeurs modifiées. Le masquage des données peut se faire en modifiant les données en temps réel (masquage dynamique des données) ou en créant une image miroir d’une base de données basée sur des données modifiées (masquage statique des données). L’anonymisation peut être réalisée à l’aide d’une série de techniques de masquage des données telles que le cryptage, le caviardage des données, le mélange de caractères, la substitution de valeurs, le brouillage, etc.
Pseudonymisation
La pseudonymisation est une méthode de dépersonnalisation des données qui consiste à remplacer les identifiants privés par des pseudonymes (faux identifiants). Un exemple pourrait être le remplacement du nom « Jane Smith » par « Janet Doe ». La pseudonymisation garantit la précision statistique tout en assurant la confidentialité des données. Cela signifie que les données peuvent toujours être utilisées à des fins de formation, de test et d’analyse.
Généralisation
La généralisation est une technique qui consiste à exclure volontairement certaines parties des données pour les rendre moins identifiables tout en conservant l’exactitude des données. Avec cette technique, les données peuvent être modifiées en une gamme de valeurs avec des limites logiques. Par exemple, une adresse spécifique peut être révélée sans numéro de maison, ou le numéro est remplacé dans une fourchette de 140 numéros de maison par rapport à l’adresse d’origine.
Permutation de données
La permutation des données, également connue sous le nom de mélange, est une technique qui permute et réarrange les valeurs des attributs d’un ensemble de données, de sorte que les données ne correspondent pas aux informations initiales. L’échange d’attributs comprenant des valeurs identifiables, telles que le numéro de sécurité sociale ou la date de naissance, peut influencer de manière significative l’anonymisation.
La permutation des données est souvent utilisée lorsqu’il s’agit de données identifiables contenues dans des colonnes stockées dans des fichiers Excel, par exemple des enregistrements de clients ou d’employés.
Perturbation des données
La perturbation des données est une technique qui modifie légèrement l’ensemble des données initiales en ajoutant un bruit aléatoire et en utilisant des méthodes d’arrondissement des valeurs. Les valeurs doivent être proportionnelles à la perturbation employée pour que les données restent utilisables. Par exemple, si la base utilisée pour modifier les valeurs originales est trop petite, les données ne peuvent pas être suffisamment anonymisées. Et si la base est trop grande, les données risquent de ne pas être reconnaissables ou utilisables.
Par exemple, une base de 5 est souvent utilisée pour arrondir des valeurs telles que l’âge.
Données synthétiques
Les données synthétiques sont des ensembles de données artificielles générées par des algorithmes et n’ayant aucun rapport avec le cas d’origine. Cette méthode est rendue possible par l’utilisation de modèles mathématiques basés sur des schémas résidant dans l’ensemble de données original. Ces modèles comprennent des régressions linéaires, des écarts types, des médianes ou d’autres modèles statistiques utiles pour créer des résultats synthétiques.
L’utilisation d’ensembles de données artificielles ne risque pas de compromettre la protection des données et de la vie privée, car ils ne contiennent pas d’informations personnelles identifiables.
Certaines de ces techniques ont peut-être déjà croisé votre chemin si votre organisation travaille avec des données sensibles en matière de protection de la vie privée. Si ce n’est pas le cas, nous espérons vous éclairer dans le paragraphe suivant sur la pertinence de ces techniques pour vous en présentant divers cas d’utilisation de l’anonymisation des données.
Comment automatiser l’anonymisation des données ?
À mesure que les préoccupations liées à la confidentialité des données augmentent, les entreprises cherchent des solutions fiables pour protéger leurs informations ainsi que celles de leurs clients. Mais comment éviter un scénario cauchemardesque, comme une violation de données ?
Voyons ce qu’en disent les professionnels. Selon une étude du Ponemon Institute, pas moins de 70 % des experts en cybersécurité affirment que l’IA est très efficace pour détecter des menaces qui, auparavant, passaient inaperçues. Une excellente nouvelle ! Enfin, une solution validée par des spécialistes, capable de vous aider.
Cependant, il y a un bémol. Sans plan concret, l’adoption d’une technologie aussi complexe risque de prendre du temps et de mobiliser des ressources que vous n’avez peut-être pas. Pour vous simplifier la tâche, nous avons élaboré un guide étape par étape pour automatiser le processus d’anonymisation des données. Vous n’avez qu’à le suivre pour démarrer sereinement.
- Identifier et classifier les données sensibles grâce à des outils de détection basés sur l’IA – La première étape consiste à localiser et comprendre quelles données sont considérées comme sensibles. Les outils basés sur l’intelligence artificielle peuvent analyser vos sources de données pour détecter les informations personnelles (PII) telles que noms, adresses, données financières, etc. Ils utilisent la reconnaissance de motifs, le traitement du langage naturel (NLP) et l’apprentissage automatique pour classer automatiquement les données en fonction du niveau de risque et de sensibilité.
- Choisir la bonne technique d’anonymisation en fonction des capacités d’automatisation – Selon votre cas d’usage, vous pouvez opter pour des techniques telles que le masquage, la pseudonymisation, la généralisation ou la génération de données synthétiques. Les plateformes automatisées identifient la méthode la plus appropriée en fonction du type de données et du contexte d’utilisation.
- Mettre en œuvre l’anonymisation via un logiciel ou des API – Une fois la méthode choisie, le processus d’anonymisation peut être appliqué grâce à des plateformes spécialisées ou via des API intégrées à votre système existant. Nombre d’entre elles prennent en charge le traitement en temps réel et anonymisent automatiquement les données lors de leur entrée ou sortie de vos systèmes.
- Tester et valider les données anonymisées grâce à des vérifications automatisées de conformité – Il est essentiel de vérifier si les données anonymisées ne contiennent plus d’informations identifiables. Les outils automatisés peuvent analyser les ensembles de données pour détecter des PII résiduelles. Certains proposent même des systèmes de scoring de conformité ou des alertes en cas d’anomalie, garantissant le respect des exigences légales et internes.
- Garantir la conformité aux réglementations grâce à une surveillance automatisée – Le traitement et l’anonymisation des données sont strictement encadrés par des lois telles que le RGPD en Europe, le HIPAA pour les données médicales ou le CCPA en Californie. Les outils automatisés propulsés par l’IA permettent de rester conforme en réduisant les erreurs humaines grâce à la surveillance de l’utilisation des données anonymisées, à la génération de journaux d’audit et à des notifications en cas de violations potentielles.
- Mettre à jour en continu les techniques d’anonymisation grâce à des solutions pilotées par l’IA – Les menaces liées à la confidentialité évoluent, et les processus d’anonymisation doivent évoluer en parallèle. Les outils d’IA peuvent apprendre des modèles de données et des risques au fil du temps, améliorant ainsi constamment la précision et l’efficacité de l’anonymisation. Mettre régulièrement à jour les algorithmes de détection, les règles de sécurité et les logiques d’anonymisation est indispensable pour garantir que la solution reste efficace face aux nouvelles menaces et aux changements réglementaires.
Et voilà ! Un plan simple mais efficace pour protéger vos informations sensibles et rester en conformité avec les réglementations sur la protection des données. La prochaine question sera : est-ce pertinent pour votre entreprise ? Nous allons vous faciliter la réflexion dans la section suivante en présentant les meilleurs cas d’usage de l’anonymisation des données.
Anonymisation des données: Cas d’utilisation
Pour que ce blog reste lisible, nous ne couvrons que les cas d’utilisation de l’anonymisation des données que nous rencontrons le plus souvent. La liste suivante n’est pas exhaustive:
- Embarquement des clients à distance
- Traitement de l’information financière
- Développement de logiciels et de produits
Enregistrement des clients à distance
Les organisations qui ont besoin de vérifier et de stocker les informations relatives à leurs clients au cours des processus d’intégration à distance sont soumises à diverses réglementations telles que KYC, GDPR et AML, pour n’en citer que quelques-unes. Souvent, les clients doivent scanner leurs documents d’identité pour que l’entreprise puisse vérifier leur identité ou effectuer une vérification préalable de la clientèle.
Pour protéger les PII, tels que les numéros de sécurité sociale (SSN) ou la date de naissance, d’une utilisation abusive, les organisations peuvent appliquer l’anonymisation des données par le biais de diverses techniques de masquage.
Traitement des informations financières
Les institutions financières doivent protéger la vie privée de leurs clients lorsqu’elles traitent des informations financières. Souvent, elles peuvent y parvenir en supprimant ou en masquant les PII des ensembles de données à l’aide de techniques d’anonymisation des données, telles que le masquage ou la généralisation des données.
Ces techniques peuvent être appliquées à différents types d’informations financières, telles que les rapports de transaction, les rapports de crédit, les informations de paiement, les factures, les relevés bancaires et les demandes de prêt.

Développement de logiciels et de produits
Les développeurs ont besoin d’utiliser des données réelles lorsqu’ils développent des logiciels et des outils pour résoudre des problèmes réels, effectuer des tests et améliorer les solutions existantes. La raison pour laquelle les données sont souvent rendues anonymes est que l’environnement de développement peut être vulnérable à des violations dues à des fuites ou à des données partagées entre plusieurs équipes. Cela peut finalement conduire à la compromission de données sensibles.
Pourquoi anonymiser les données
Il existe plusieurs raisons de rendre les données anonymes. Les raisons les plus importantes peuvent être les suivantes:
- Protection contre l’utilisation abusive des données: L’anonymisation des données garantit que les parties prenantes internes ne peuvent pas utiliser les données à mauvais escient et minimise le risque d’exploitation des données en cas de violation de l’organisation par des auteurs externes.
- Se conformer aux réglementations sur la confidentialité des données: Le règlement général sur la protection des données (GDPR) dans l’Union Européenne et le California Consumer Privacy Act (CCPA) aux États-Unis exigent des entreprises qu’elles protègent les données personnelles des individus et qu’elles fournissent certains droits aux personnes concernées. L’anonymisation des données aide les entreprises à répondre à ces exigences et à éviter les amendes pour non-respect des réglementations.
- Possibilités de partage des données: Les données contenant des informations personnellement identifiables ne peuvent pas être partagées avec des entreprises tierces, ce qui limite la recherche de nouvelles opportunités commerciales. Cependant, grâce à l’anonymisation des données, les entreprises peuvent partager des données avec des partenaires ou des enquêteurs afin d’obtenir de nouvelles informations et de développer de nouveaux produits. Par exemple, les données anonymes peuvent être utilisées pour former des modèles d’apprentissage automatique afin d’améliorer les produits et les services.
Bien qu’il soit important et bénéfique pour votre organisation de rendre les données anonymes, il existe certains inconvénients que vous devriez prendre en considération.
Inconvénients de l’anonymisation des données
Voici quelques-uns des inconvénients de l’anonymisation des données:
- Perte de l’utilitaire de données: La réglementation exige que les sites web obtiennent l’autorisation des visiteurs pour collecter des informations personnelles telles que les cookies et les adresses IP. Toutefois, la suppression des identifiants et l’anonymisation des données peuvent restreindre la possibilité d’utiliser les données dans les résultats. Par exemple, les données anonymes des utilisateurs ne peuvent pas être utilisées à des fins de marketing personnalisé ou de ciblage.
- Elle repose sur des ressources techniques: L’anonymisation des données peut être un processus exigeant sur le plan technique et en termes de ressources. Les organisations doivent disposer de connaissances et d’une expertise spécialisées pour le mettre en œuvre. En outre, sa maintenance peut être longue et coûteuse. En raison de la sophistication des pirates informatiques et des méthodes de violation des données, les entreprises doivent constamment mettre à jour leurs techniques d’anonymisation pour s’assurer que les données restent réellement anonymes.
Maintenant que vous avez une idée des avantages et des inconvénients de l’anonymisation des données, nous allons vous expliquer comment vous pouvez anonymiser les données.
Anonymiser vos données avec Doxis AI.dp
Si vous souhaitez anonymiser les données des documents que vous collectez, numérisez et extrayez, Doxis peut vous aider. Notre logiciel de traitement intelligent de documents AI.dp utilise la reconnaissance optique de caractères (OCR) pour extraire le texte des images et des modèles d’intelligence artificielle pour reconnaître, classer et anonymiser les données en fonction de vos besoins. Comment?
Le logiciel d’anonymisation des données AI.dp peut être entraîné à noircir et à masquer certains champs et textes des documents qui sont envoyés au moteur d’analyse. Ces documents peuvent être envoyés par courrier électronique, par Internet ou par une application mobile sous la forme de fichiers JPG, PNG et PDF, par exemple. Une fois l’anonymisation des données appliquée, vous pouvez recevoir les données anonymisées sous la forme de votre choix, notamment JSON, XLSX, XML ou CSV.
La mise en œuvre de notre solution d’anonymisation des données est très facile grâce à la documentation appropriée disponible et peut être effectuée via l’API ou le SDK. Notre API vous sera utile si vous souhaitez construire votre propre système d’anonymisation et d’extraction des informations et le connecter à vos systèmes logiciels existants.
Notre SDK, par contre, vous permet de transformer vos appareils mobiles en dispositifs de capture de données avec la possibilité de masquer les données de manière sélective. Ceci est utile si vous souhaitez ajouter des fonctions d’anonymisation des données à votre application mobile existante ou à venir.
Avec AI.dp, vous pouvez bénéficier des avantages suivants:
- Maintien de l’utilité des données tout en les extrayant automatiquement et en les rendant anonymes
- Amélioration de la conformité aux réglementations et exigences en matière de confidentialité des données
- Réduction des coûts car vous n’avez pas besoin d’acheter plusieurs solutions pour créer votre système d’anonymisation des données
- Délais d’exécution plus courts pour l’anonymisation et le traitement des données grâce à l’automatisation
- Évolutivité possible grâce à une faible dépendance vis-à-vis des ressources humaines
Prêt à automatiser l’extraction et l’anonymisation des données? Remplissez simplement le formulaire ci-dessous pour obtenir une démonstration gratuite de notre logiciel. Si vous avez d’autres questions, contactez nos experts pour plus d’informations.
FAQ
L’anonymisation des données est le processus de transformation d’informations personnelles afin qu’elles ne puissent plus être liées à un individu. Doxis utilise des techniques avancées pour supprimer ou masquer les identifiants sensibles dans vos documents.
Les données pouvant être anonymisées incluent les noms, adresses, numéros de téléphone, identifiants, et informations financières. La solution Doxis traite textes, images et documents scannés grâce à l’OCR et à l’IA.
Oui, des systèmes automatisés permettent d’anonymiser des milliers de documents rapidement. Doxis offre un traitement par lot et des API adaptées aux environnements à grande échelle.
Les outils d’anonymisation peuvent être connectés à des systèmes ERP, CRM ou de gestion documentaire via API. Doxis s’intègre directement dans vos processus pour préserver la continuité des opérations.
L’anonymisation protège les données personnelles contre l’utilisation abusive en cas de violation de sécurité et permet aux entreprises de se conformer à des réglementations strictes comme le GDPR, tout en facilitant le partage de données anonymisées pour la recherche et l’amélioration des produits.