Extraer información valiosa de los datos puede ser una tarea ardua y a menudo requiere un primer paso crucial: la preparación de datos. También conocida como preprocesamiento de datos, la preparación de datos sienta las bases para el éxito del análisis y la toma de decisiones. Al limpiar, transformar y organizar los datos en bruto, éstos se convierten en un recurso valioso que proporciona la energía necesaria para impulsar estrategias empresariales precisas e influyentes.
Pero, ¿qué es exactamente la preparación de datos? En pocas palabras, es el proceso de recolectar, limpiar y estructurar los datos para garantizar su calidad, coherencia y relevancia. Este proceso de transformación permite que las empresas aprovechen todo el potencial de sus datos mediante la eliminación de redundancias, errores e incoherencias, lo que da como resultado un conjunto de datos limpio y coherente listo para el análisis.
En este blog, exploraremos el proceso de preparación de datos, su función respecto al machine learning y analizaremos diversos métodos y mejores prácticas. Tanto si eres un científico de datos experimentado como si eres nuevo en el mundo de la analítica, este artículo te ayudará a liberar el potencial de tus datos e impulsar el éxito de tu organización basado en datos.
Empecemos por entender por qué la preparación de datos es tan importante.
¿Por Qué es Importante la Preparación de Datos?
La preparación de datos es crucial por dos razones principales: garantizar la calidad de los datos y facilitar su integración perfecta.
Calidad de los datos: Los grandes conjuntos de datos recogidos de diversas fuentes pueden contener errores, incoherencias y valores omitidos. Al eliminar estas discrepancias, las organizaciones pueden garantizar que sus análisis se basan en datos fiables y precisos.
Integración de datos: Las organizaciones suelen tener datos almacenados en diferentes formatos y a través de múltiples sistemas. La preparación de datos permite la integración de fuentes de datos dispares, lo que posibilita una perspectiva general de la empresa. Este panorama de datos unificado facilita un mejor análisis y una comprensión holística de las operaciones de la organización, los clientes y las tendencias del mercado.
La preparación de datos es especialmente crítica en los casos en que los conjuntos de datos son masivos. Cuando se trata de grandes volúmenes de datos, los retos se multiplican. Las incoherencias y los errores en los datos pueden ser más frecuentes, y los datos pueden ser demasiado complejos para analizarlos directamente. Al preparar los datos, las organizaciones pueden agilizar el proceso de análisis, haciéndolo más manejable y eficiente. Esto, a su vez, ahorra tiempo y recursos, lo que permite obtener información y tomar decisiones con mayor rapidez.
Además, la preparación de los datos es necesaria cuando se trata de datos no estructurados o semiestructurados. Con las redes sociales, los datos de sensores y el contenido basado en texto como ejemplos, las organizaciones tienen acceso a grandes cantidades de datos no estructurados. Sin embargo, estos datos deben procesarse y organizarse para extraer información significativa. Las técnicas de preparación de datos, como el procesamiento de textos, el análisis de sentimientos y el reconocimiento de entidades, ayudan a transformar los datos no estructurados en formatos estructurados para su análisis.
La preparación de datos también es crucial cuando se trata de cumplir requisitos reglamentarios. Muchos sectores, como el financiero y el sanitario, tienen estrictas normas de privacidad y seguridad de los datos. Al preparar los conjuntos de datos y garantizar el cumplimiento de estas normativas, las organizaciones pueden evitar riesgos legales y de reputación.
Una vez entendida la importancia de la preparación de datos y su relevancia en grandes conjuntos de datos, veamos ahora el proceso en sí y exploremos cómo se lleva a cabo la preparación de datos.
¿Cual es el Proceso de Preparación de Datos?
En los procesos de preparación de datos, cada paso desempeña un papel crucial a la hora de garantizar la calidad, fiabilidad y utilidad de los datos para el análisis y la toma de decisiones. Siguiendo estos pasos, las organizaciones pueden preparar sus datos de forma eficaz para obtener información precisa y tomar decisiones informadas.
- Adquisición de Datos
- Exploración de Datos
- Limpieza de Datos
- Transformación de Datos
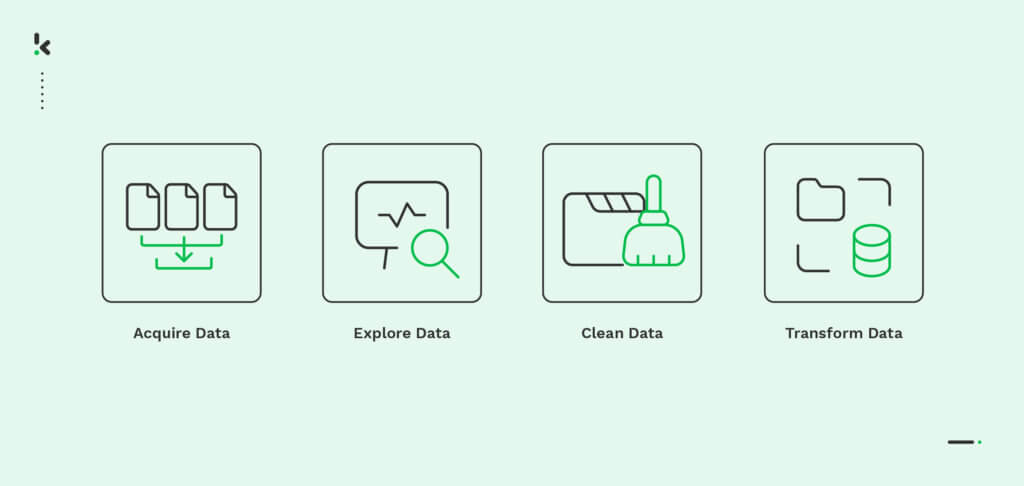
¡Veamos cada uno de estos pasos con más detalle!
Adquisición de Datos
El primer paso en el proceso de preparación de datos es la adquisición de los datos necesarios. Esto implica identificar las fuentes de datos pertinentes, como bases de datos, APIs, archivos o extracción web, y recuperar los datos de estas fuentes. Es fundamental recolectar datos completos y precisos que se ajusten a los objetivos del análisis o proyecto. Una correcta adquisición de datos sienta las bases para los pasos posteriores del proceso de preparación de datos.
Exploración de Datos
Una vez adquiridos los datos, el siguiente paso es explorarlos. La exploración de datos implica comprender la estructura y el contenido de los datos para obtener información e identificar posibles problemas o patrones. Este proceso incluye tareas como el examen de las propiedades estadísticas de los datos, su visualización mediante gráficos o diagramas y la realización de análisis preliminares. La exploración de los datos ayuda a identificar los valores que faltan, los valores atípicos, las incoherencias o cualquier otro problema de calidad de los datos que deba abordarse antes de continuar con el análisis.
Limpieza de Datos
La limpieza de los datos es un paso fundamental para garantizar su calidad y fiabilidad. La limpieza de datos implica la identificación y corrección de errores, incoherencias e imprecisiones en el conjunto de datos. Este proceso puede incluir la gestión de valores que faltan, la eliminación de duplicados, la estandarización de formatos y la resolución de discrepancias. Al limpiar los datos, los analistas pueden asegurarse de que son coherentes, precisos y fiables, minimizando así el riesgo de análisis engañosos o sesgados.
Transformación de Datos
La transformación de datos es el proceso de convertir los datos en bruto a un formato adecuado para su análisis o procesamiento. Este paso suele consistir en manipular los datos para crear nuevas variables, agregar o resumir datos, o realizar cálculos. Las técnicas de transformación pueden incluir la estandarización de datos, el escalado, la codificación de variables categóricas o la aplicación de operaciones matemáticas y estadísticas. Al transformar los datos, los analistas pueden mejorar su usabilidad, compatibilidad y relevancia para el análisis o aplicación específicos.
En conclusión, un proceso de preparación de datos bien ejecutado es vital para que las organizaciones extraigan información significativa de sus datos. Adquiriendo datos relevantes, explorando sus características, eliminando errores e incoherencias y transformándolos en un formato adecuado, las empresas pueden garantizar la fiabilidad y calidad de sus datos.
A continuación, nos centraremos específicamente en la preparación de datos para machine learning. Así que, ¡sigue leyendo!
Preparación de Datos para Machine Learning
En machine learning, la preparación de los datos desempeña un papel crucial a la hora de determinar el éxito y la precisión de tus modelos. Al conservar y transformar cuidadosamente los datos, se pueden mitigar los sesgos, manejar los valores que faltan y optimizar la selección de características, lo cual, en última instancia, prepara el camino para modelos de machine learning más fiables y eficaces.
Nos adentraremos en los aspectos específicos de la preparación de datos que son esenciales para las tareas de machine learning, entre los que se incluyen:
- Manejo de datos faltantes
- Escalado y normalización de características
- Codificación de variables categóricas
- Manejo de valores atípicos
- Selección de características y reducción de la dimensionalidad
- Manejo de desequilibrios de clase
Manejo de Datos Faltantes
Cuando hay valores que faltan, se pueden emplear varias estrategias para garantizar la integridad y eficacia del modelo. Una de ellas consiste en eliminar por completo los casos en los que faltan datos, pero esto puede suponer una pérdida significativa de información valiosa.
Como alternativa, los valores que faltan pueden imputarse estimando sus valores a partir de métodos estadísticos, como la imputación de la media o la mediana, o técnicas más avanzadas como la imputación por regresión o las imputaciones múltiples. La elección del método de imputación depende de la naturaleza y la distribución de los datos que faltan, así como de las características del conjunto de datos.
Escalado y Normalización de Características
El escalado y la normalización de las características son cruciales para preparar los datos para el machine learning. Estas técnicas llevan las características a una escala común, evitando el predominio de variables de mayor magnitud. Los métodos de escalado, como la estandarización, garantizan una media de cero y una varianzia unitaria, mientras que las técnicas de normalización, como el escalado mín-máx, asignan las características a un rango específico.
Codificación de Variables Categóricas
En la preparación de datos para machine learning, las variables categóricas (que representan datos cualitativos o nominales) deben convertirse en representaciones numéricas que los algoritmos puedan entender.
Para ello, existen dos métodos habituales: la codificación one-hot y la codificación de etiquetas. La codificación one-hot crea vectores binarios, en los que cada elemento representa la presencia o ausencia de una categoría específica. En cambio, la codificación por etiquetas asigna valores numéricos únicos a cada categoría.
Manejo de Valores Atípicos
Los valores atípicos son puntos de datos que se desvían significativamente de la mayoría del conjunto de datos y pueden tener un impacto desproporcionado en el entrenamiento y las predicciones del modelo. Existen varias estrategias para tratar los valores atípicos. Una de ellas consiste en eliminarlos del conjunto de datos si se consideran erróneos o poco probables en el mundo real.
Como alternativa, los valores atípicos pueden sustituirse o imputarse mediante técnicas como la imputación de la media, la mediana o la regresión. Otro método consiste en transformar el espacio de características, por ejemplo mediante transformaciones logarítmicas o de poder, para reducir la influencia de los valores extremos.
Selección de Características y Reducción de la Dimensionalidad
La selección de características ayuda a identificar las más importantes que contribuyen a realizar predicciones precisas, mientras que la reducción de la dimensionalidad reduce el número de características conservando la información más relevante. Estas técnicas mejoran el rendimiento del modelo, la interpretabilidad y la eficiencia computacional al centrarse en las características más informativas y reducir la complejidad del conjunto de datos.
Manejo de Desequilibrios de Clase
Los desequilibrios de clase se producen cuando la distribución de las muestras entre las diferentes clases es desigual, con una o más clases significativamente menos representadas que otras. Esto puede dar lugar a modelos sesgados que funcionan mal en clases minoritarias. Existen varias técnicas para corregir los desequilibrios de clase, como los métodos de remuestreo, que permiten sobremuestrear la clase minoritaria o submuestrear la clase mayoritaria.
Además, se pueden emplear enfoques algorítmicos como el aprendizaje sensible a los costos o los métodos de conjunto para dar más peso o enfoque a la clase minoritaria durante el entrenamiento del modelo. Para sacar el mayor provecho de tu modelo de machine learning, sigue leyendo para explorar varios métodos de preparación de datos, que abarcan herramientas comunes y estrategias efectivas.
Métodos de Preparación de Datos
Cuando nos enfrentamos a la tarea de seleccionar la herramienta o estrategia adecuada, comprendemos que la abundancia de opciones puede resultar abrumadora. Con tantas opciones disponibles, tomar una decisión puede ser todo un reto. Para ayudarte en este proceso, hemos preparado un resumen conciso de herramientas y estrategias para los siguientes aspectos:
- Limpieza de datos
- Transformación de datos
- Ingeniería de características
- Integración de datos
- Muestreo de datos
Limpieza de Datos
Existen varios métodos y herramientas para ayudar a realizar esta tarea. Una técnica comúnmente utilizada es la imputación, que consiste en rellenar los valores que faltan utilizando enfoques estadísticos como la media, la mediana o la imputación basada en la regresión. Herramientas como Pandas, una potente biblioteca de manipulación de datos en Python, ofrecen funciones para imputar eficazmente los valores que faltan.
Además, los métodos de detección de valores atípicos, como el uso de puntuaciones z o técnicas de agrupación, pueden identificar y manejar puntos de datos anómalos que pueden distorsionar los resultados del análisis.
Transformación de Datos
Una técnica de transformación popular es la normalización, que escala los datos numéricos a un rango estándar, a menudo entre 0 y 1, para garantizar que todas las variables contribuyen por igual al análisis. La normalización es otro método de transformación que ajusta los datos para que tengan media cero y varianza unitaria. Ambas técnicas se emplean con frecuencia en algoritmos de machine learning. Bibliotecas como Scikit-learn ofrecen funciones fáciles de usar para realizar estas transformaciones.
Ingeniería de Características
La ingeniería de características es el proceso de crear características nuevas o modificar las existentes para mejorar el poder predictivo de los modelos de machine learning. Este método puede consistir en extraer información significativa de los datos brutos, como derivar nuevas variables a partir de las existentes, codificar variables categóricas o crear términos de interacción.
La ingeniería de características requiere una combinación de conocimiento del dominio, creatividad y técnicas estadísticas. Herramientas como TensorFlow y PyTorch proporcionan bibliotecas para la extracción y transformación de características, permitiendo una implementación eficiente de estos métodos.
Integración de Datos
La integración de datos implica la combinación de datos de múltiples fuentes, que a menudo vienen en diferentes formatos o estructuras. Este proceso es esencial para crear un conjunto de datos completo y unificado para el análisis. Hay varias herramientas y estrategias que pueden ayudar en la integración de datos. Las herramientas de Extracción, Transformación y Carga (ETL) como Apache Spark y Talend facilitan la extracción y transformación de datos de fuentes dispares.
Además, las plataformas de integración de datos como Informatica e IBM InfoSphere ofrecen soluciones completas para integrar y armonizar los datos de distintos sistemas y formatos.
Muestreo de Datos
El muestreo de datos es una técnica utilizada para seleccionar un subconjunto de datos de un conjunto de datos mayor para su análisis. Este método es especialmente útil cuando se trata de grandes conjuntos de datos o clases desequilibradas. El muestreo aleatorio, el muestreo estratificado y el sobremuestreo son algunas de las estrategias de muestreo más comunes. Herramientas como Scikit-learn y el paquete caret de R ofrecen funciones para aplicar estas técnicas de muestreo.
Si aún no estás seguro o te faltan recursos para llevar a cabo un proceso de preparación de datos adecuado, no tienes por qué preocuparte. Klippa DataNorth está especializada en la preparación de datos y puede ayudarte con tus necesidades.
Consultoría de Preparación de Datos
En DataNorth somos conscientes de que la clave para liberar el verdadero potencial de los datos reside en una preparación eficaz de los mismos. Por eso ofrecemos servicios de consultoría de preparación de datos adaptados para ayudar a las empresas a preparar sus datos para el éxito. Con nuestra experiencia y soluciones de última generación, podemos ayudar a tu organización a extraer información valiosa y tomar decisiones basadas en datos con confianza.
Si tienes alguna pregunta o quieres saber más sobre nuestros servicios, no dudes en ponerte en contacto con nosotros. Nuestro equipo de expertos está a tu disposición para ayudarte a optimizar tus datos y alcanzar tus objetivos empresariales.
